
Plant Pathology PhD student studying Ralstonia in the Lowe-Power lab at UC Davis. If I'm not in lab, I'm probably cooking, camping, or playing the piano/guitar.
Joined July 2021
- Tweets 18
- Following 68
- Followers 93
- Likes 10
8 Photos and videos


7 Sep 2023
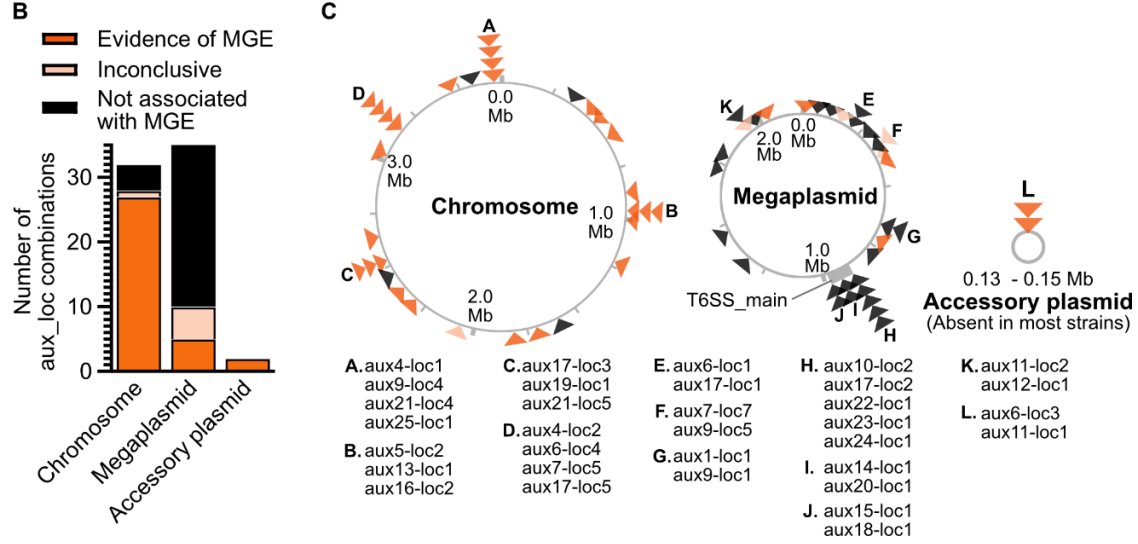
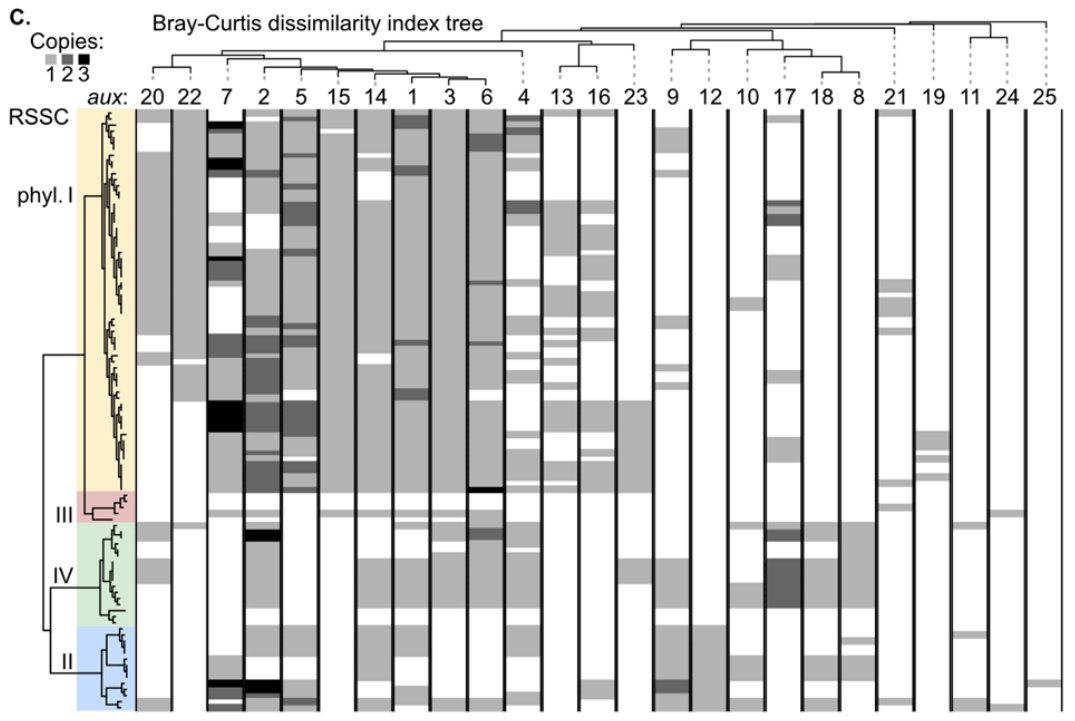
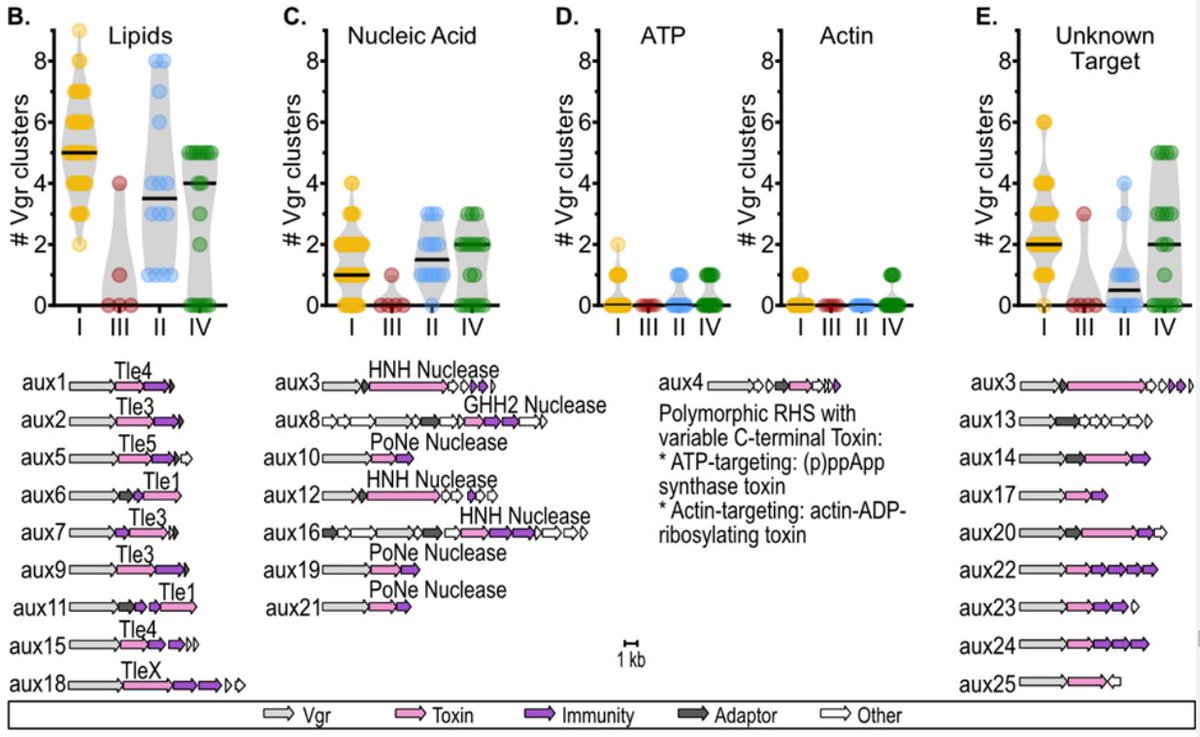
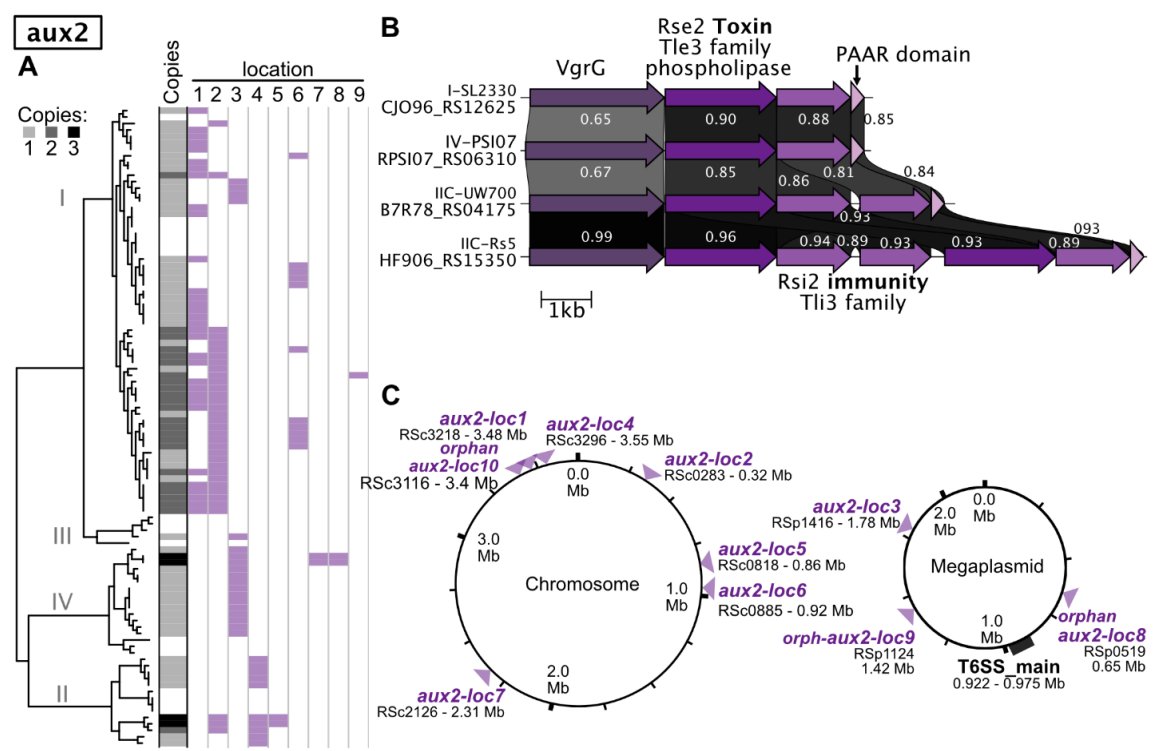
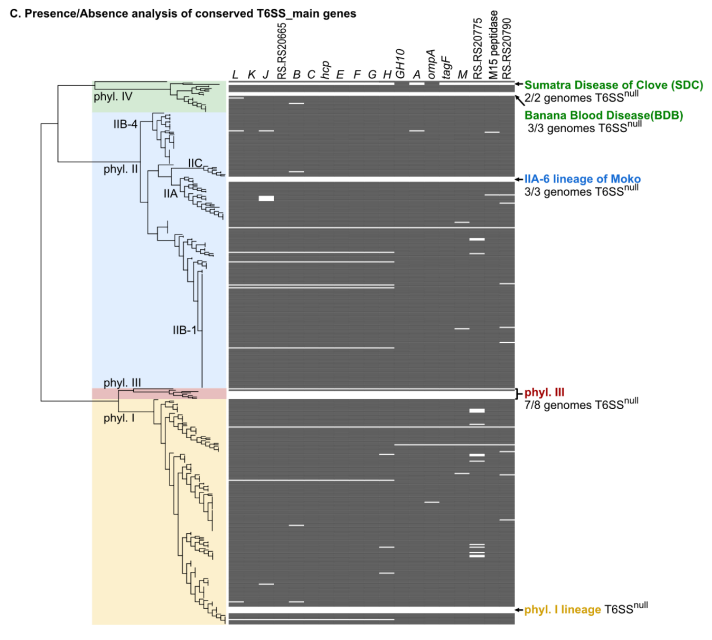
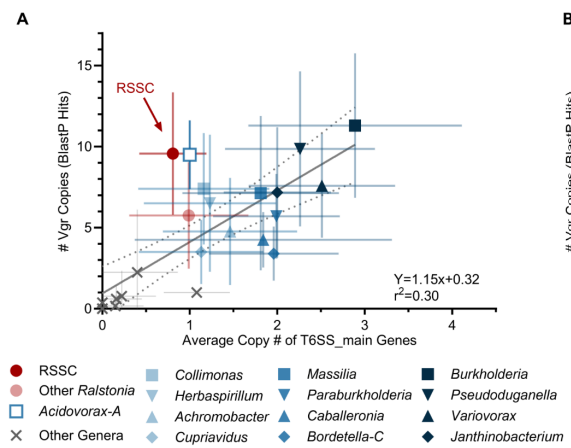
#Ralstonia #T6SS #genomics paper up now on bioRxiv! Co-first author @Nat_Aoun and I explore type VI secretion system gene content in plant-pathogenic Ralstonia. We found xylem pathogens'🌱☠️lifestyles associated with robust, rapidly-evolving arsenals of T6SS effector toxins🧵⬇️
1
12
24
6,733
8 Sep 2023
Overall, our T6SS pangenomic atlas🗺️paints a picture of Ralstonia as a bully🗡️that aggressively attacks all sorts of microbial targets with its T6SS.
biorxiv.org/content/10.1101/…
1
1
2
464
8 Sep 2023
I had a BLAST (🥁!) working w/ co-first author @Nat_Aoun , Jason Avalos, Kimberly Grulla, Kasey Miqueo, Cloe Tom, and @TLowePower. With many questions left to answer about T6SS in Ralstonia, hoping this work inspires many more enthusiastic eco-evo-bacteriological conversations!
209
21 Apr 2022
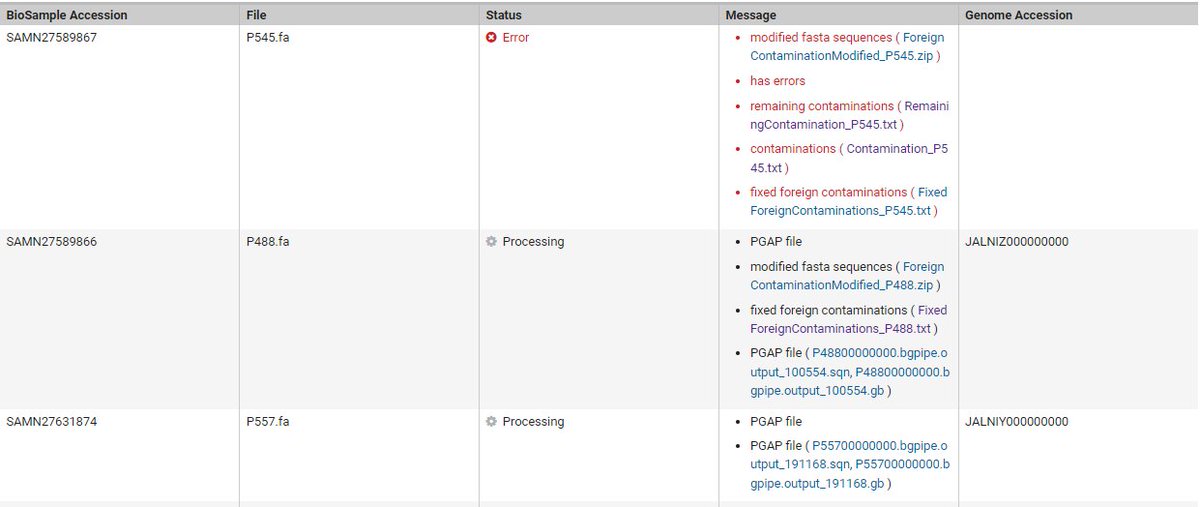
First time submitting bacterial genome assemblies to NCBI and ran into an error with one of the twelve genomes in the batch. I'm stumped, maybe someone out there has dealt with similar issues before and has advice?
1
1
4
21 Apr 2022
NCBI's recommendation is splitting the sequence on either side of the detected contamination, removing the contamination sequence from the end, and resubmitting. But I'm not sure how much I trust NCBI that there was only a single instance of adapter contamination in 12 genomes
1
1
21 Apr 2022
Could this be an issue with how I trimmed the reads before assembly? Or an issue with NCBI's automated QC? Is it best to manually remove the offending sequence from the assembly? Really appreciate any and all pointers🙂
1
1