
Joined August 2019
- Tweets 232
- Following 3
- Followers 5,014
- Likes 726
28 Photos and videos












May 8
Hey devs and tech product folks! This is the second and last day of @devworld_conf in Amsterdam!
There's a lot happening on each stage today, but if you're here – make sure to stop by our Booth T007 and chat with our team!


1
2
559
May 5
Your AI coding agent keeps failing to scrape dynamic pages?
Give it eyes.
ScrapingBee CLI handles the JS rendering, anti-bot defenses, and messy HTML so your LLM can actually get the data.
pip install scrapingbee-cli
1
442
May 4
3 days until @devworld_conf !
Amsterdam is officially the AI capital this week. 🇳🇱 Our team is buzzing to talk web data and building AI products. 🐝
Will you be there? Come find us at Booth T007!
1
216
Apr 27
Heads up, devs! ScrapingBee just achieved SOC 2 Type 2 compliance.
Secure data handling for your web scraping projects, validated. Long story short - focus on your code, devs, we've got the compliance. 🐝
1
232
Apr 22
Your terminal just got superpowers.
ScrapingBee CLI is live: → Batch process thousands of URLs → Schedule recurring scrapes with cron → Extract data with plain English AI rules → Export RAG-ready chunks for your LLMs
Docs: scrapingbee.com/documentatio…
4
765
Mar 9
Picking a web scraping tool in 2026? You know the pain: dozens of options, endless promises, pricing mazes, trial-and-error loops. All while you need data yesterday.
We did the heavy lifting. 45-min godzilla guide, everything you need to know. #bestwebscrapingtools #webscraping
1
2
674
Feb 17
Your search pipeline shouldn’t be a bottleneck. 🚫
Unlock our Fast Search API for: ✅ Fintech: Live market & regulatory data for grounded answers ✅ AI Training: Fresh SERP streams daily for better models ✅ Research: Instant trend & competitor tracking
All in <1s per query.
1
3
912
Feb 17
And here's everything you need to know to get Fast Search API up and running tinyurl.com/556f745z #AIModels
396
Feb 12
Ship answer engines that actually know what’s happening right now.
Our new Fast Search API gives your AI agents real-time organic results top news stories in milliseconds, fully structured and ready for LLMs - with zero data retention.
#scraping #serpscraping
2
1
474
Feb 10
Search results in milliseconds! We just rolled out our new feature - Fast Search API! Here’s what it does:
👉 Real-time organic search results top news stories in <1 second
👉Clean, structured SERP data ready for LLMs and analytics
👉Scales for high-traffic workloads #scraping
2
1
12
832
ScrapingBee retweeted

10 May 2024
🗺️Which Countries Joke The Most?
We analyzed a year's worth of Reddit threads from around the globe using @MistralAI!
352,686 comments and 9,969 threads across country subreddits to see who's joking and who's not.
The results? 👇
scrapingbee.com/blog/global-…
9
8
51
48,967
ScrapingBee retweeted
21 Apr 2023
🎥 First YouTube sponsor ever for @ScrapingBee!
We worked with @colbyfayock on amazing coding tutorials.
I’ve always been an advocate on "focus 100% on SEO".
But we wanted to expand "top of the funnel" channels a bit.
Excited to see how it goes.
youtu.be/ascZiP2pMk8
4
3
26
37,086
ScrapingBee retweeted
13 Mar 2023
The 🐝 is growing.
We worked hard on making support as efficient as possible by investing a lot in custom tools and documentation.
But we've just outgrown our current capacity.
We need help making the ScrapingBee user experience as 🔥 as possible!
weworkremotely.com/remote-jo…

9
2
22
16,663
ScrapingBee retweeted
26 Sep 2022
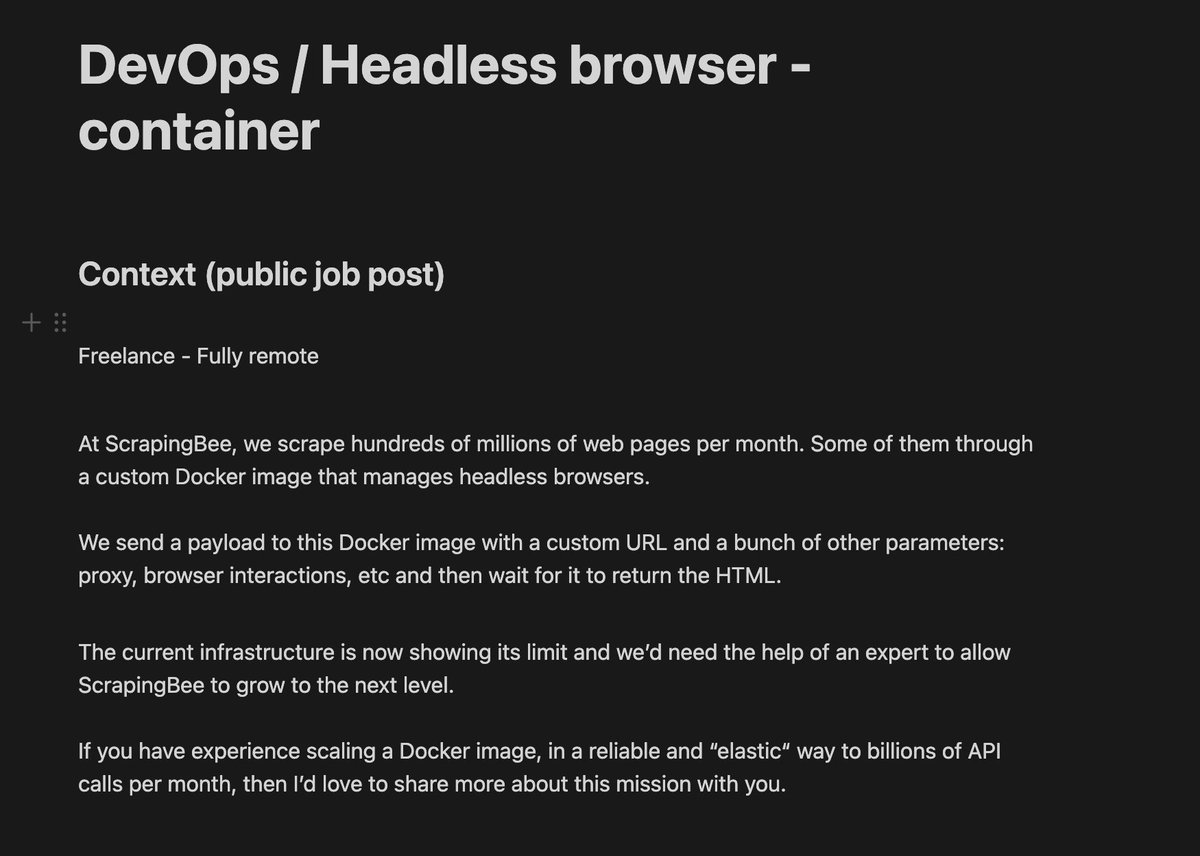
⚙️ Hey DevOps twitter!
If you:
- have experience scaling a Docker image to billions of API calls/mo
- efficiently and scalably
- are available for work
✉️ Please reach out pierre@scrapingbee.com
PS: I have a much more detailed job description to share if there's a fit😉
3
10
39
ScrapingBee retweeted
22 Jun 2022
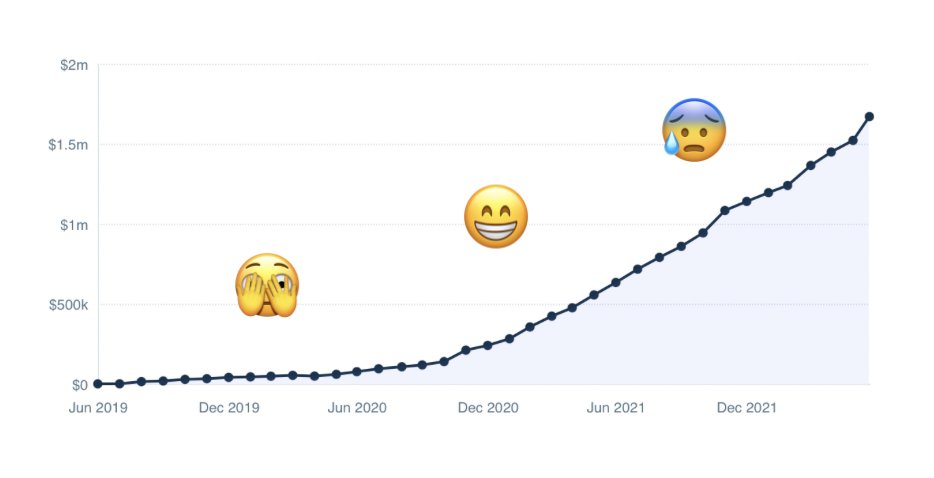
📣 Today, @ScrapingBee is 3️⃣, and just reached $1,500,000 ARR!
Year 1️⃣ was sweaty: we tried everything to go from 0 to 1. We loved it.
Year 2️⃣ was magical: we had traction for the first time ever and reached a mythic milestone: $10k MRR.
Now, let’s talk about Year 3️⃣ 👇
42
21
442
ScrapingBee retweeted
6 May 2022
We're trying something new! 🐝
We've grown @ScrapingBee to $1m ARR, 99% thanks to SEO.
But now feels like a good time to expand and explore new things!
If you think you can help us do so, you'll be interested in our new position 👇
weworkremotely.com/listings/…
🔁 appreciated 🙏
12
17
77
1 Apr 2022
Whatever you might hear, Java is still one of the most used programming language.
This guide is the perfect introduction if you want to learn web scraping in ☕️!
scrapingbee.com/blog/introdu…
9
ScrapingBee retweeted

9 Feb 2022
I had a ton of fun working through the data for my latest post for the folks at @scrapingbee!
scrapingbee.com/blog/product…
2
3
12