
Joined April 2025
- Tweets 175
- Following 1
- Followers 867
- Likes 696
81 Photos and videos



Pinned Tweet

Apr 24
Yesterday, we reached our first million downloads 🎉
We went from 200k to 1M in exactly two months! The first 200k was reached in a year!
Thanks to all the contributors and the community support that got us here ❤️🔥
Expect a very insane update soon 🚀
3
1
8
1,110
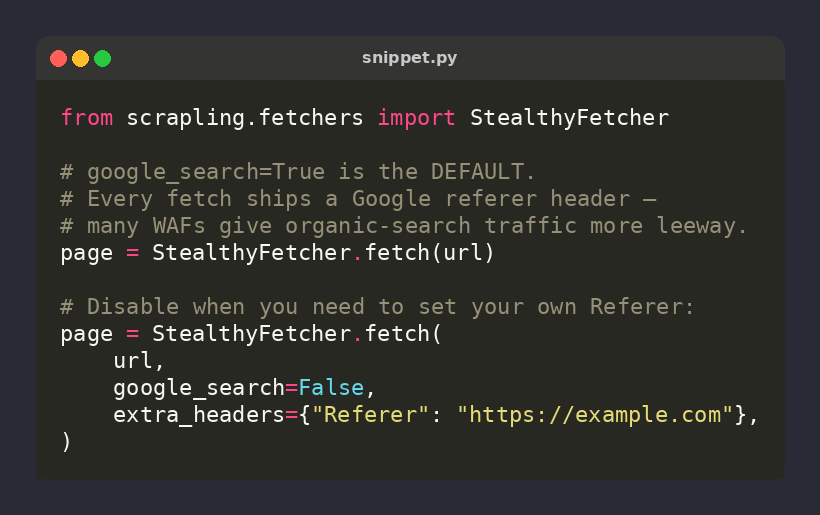
🕷️ Scrapling tip: google_search=True is the DEFAULT on StealthyFetcher/DynamicFetcher — every fetch ships with a Google referer header
Mimics organic search traffic many WAFs give more leeway to
Set google_search=False to drop it (or set your own Referer) ⚡
32
Jun 16
🕷️ Scrapling tip: http3=True flips Fetcher to HTTP/3 (QUIC over UDP)
page = Fetcher.get(url, http3=True)
Most scrapers still send HTTP/1.1 — going HTTP/3 blends in with modern browser traffic. Gotcha: may conflict with impersonate= ⚡
1
37
Jun 15
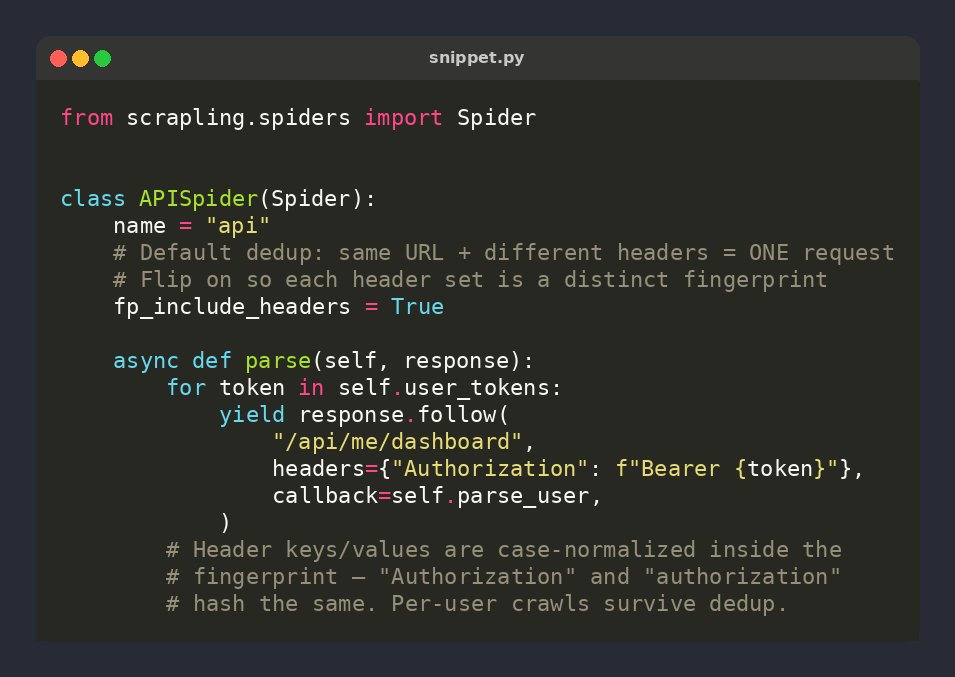
🕷️ Scrapling tip: spider dedup ignores headers by default — same URL with different Authorization / X-API-Key tokens silently collapses to one
class MySpider(Spider):
fp_include_headers = True
Header keys are case-normalized in the fingerprint ⚡
2
65
Jun 12
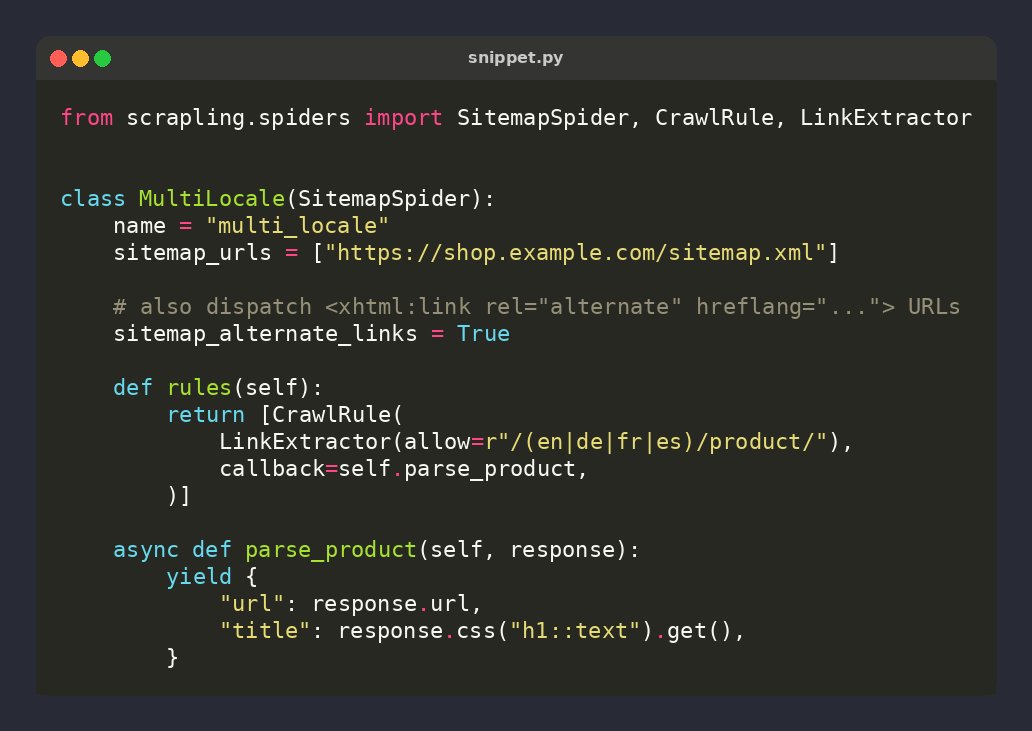
🕷️ Scrapling tip: SitemapSpider IGNORES hreflang URLs by default
Flip sitemap_alternate_links=True to also dispatch every <xhtml:link rel="alternate"> URL through your rules — crawl every locale of a multilingual site in one go ⚡
3
1
78
Jun 11
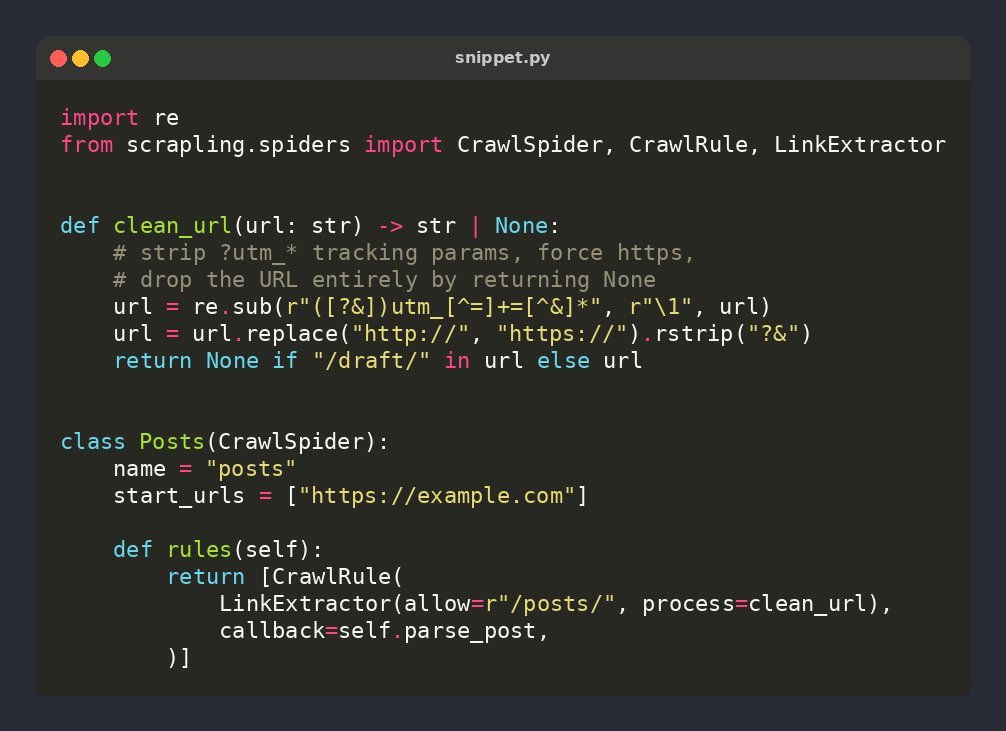
🕷️ Scrapling tip: pass process=fn to LinkExtractor
Runs a callable on every extracted URL BEFORE allow/deny filters & dedup. Return None to drop, or a rewritten URL (strip utm_*, force https, canonicalize).
Pairs with allow=/deny= for tight URL cleanup ⚡
1
1
3
94
Jun 10
🕷️ Scrapling tip: a <sitemapindex> can point to dozens of child sitemaps — SitemapSpider descends them ALL by default
Set sitemap_follow to a LinkExtractor and only matching child sitemaps get crawled. Skip the ones you don't care about ⚡
1
1
4
90
Scrapling 🕷️ retweeted

Jun 9
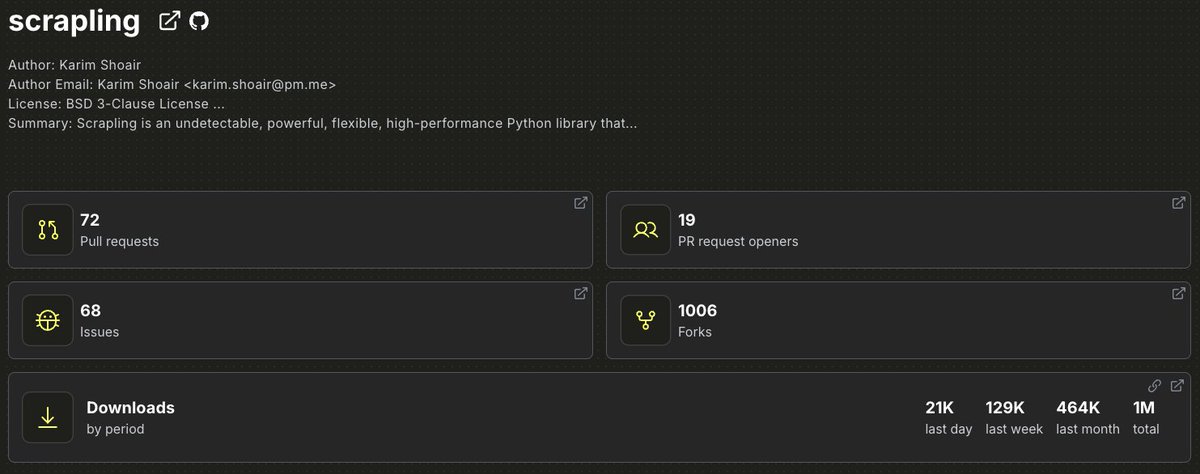
Today, Scrapling has surpassed Scrapy on Github, which made Scrapling the 2nd top Python repo in Web Scraping after Crawl4ai in terms of Github stars 🎉
That comes after staying at the top of GitHub's trends for 4 consecutive days and making another million downloads in exactly 34 days!
Thanks to everyone who helped us come so far ❤️🔥

1
1
7
157
Jun 9
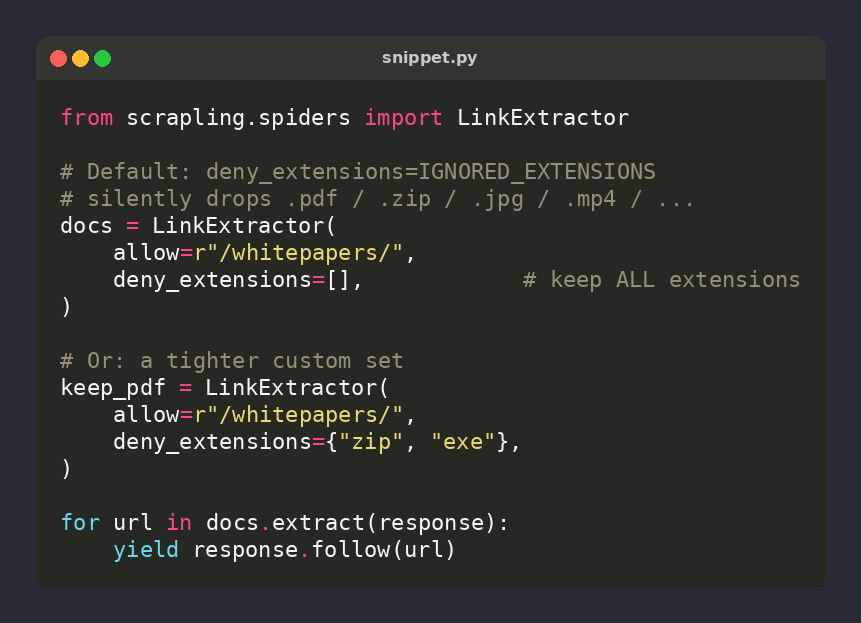
🕷️ Scrapling tip: LinkExtractor SILENTLY drops PDF/zip/image/video links — deny_extensions defaults to IGNORED_EXTENSIONS
Scraping a docs portal? You'd be missing every download link. Pass deny_extensions=[] (or your own set) to keep them ⚡
1
3
78
Jun 8
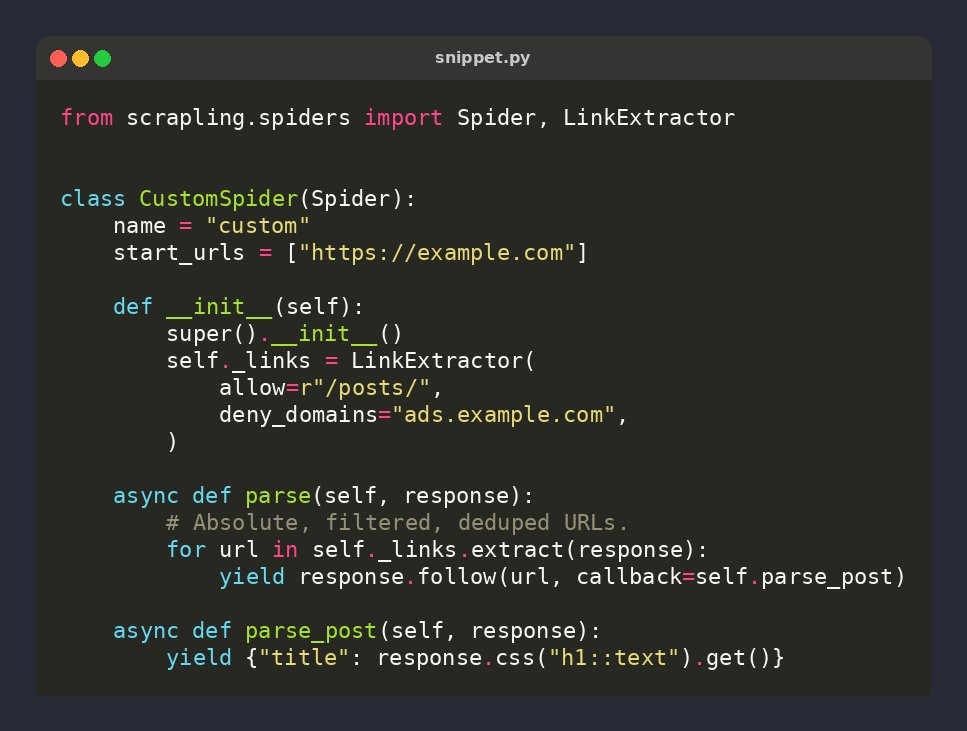
🕷️ Scrapling tip: LinkExtractor works in ANY plain Spider — not just CrawlSpider
links = LinkExtractor(allow=r"/posts/")
for url in links.extract(response):
yield response.follow(url)
Absolute, filtered, deduped URLs in one call ⚡
1
4
4
161
Jun 7
Scrapling v0.4.9 is out 🛠️
→ Fixed session-level proxies being silently ignored in HTTP sessions (could leak your real IP, update now)
→ Updated all browsers & fingerprints
→ New --version CLI flag
→ More fixes for Windows, encoding, and adaptive parsing
Check it out!
1
4
170
Jun 7
🕷️ Scrapling tip: CrawlRule(process_request=fn) mutates each Request a rule yields before dispatch
def to_stealth(self, req, resp):
req.sid = "stealth" # cheap HTTP → stealth
return req
Wire as process_request= on any rule ⚡
1
1
4
138
Jun 6
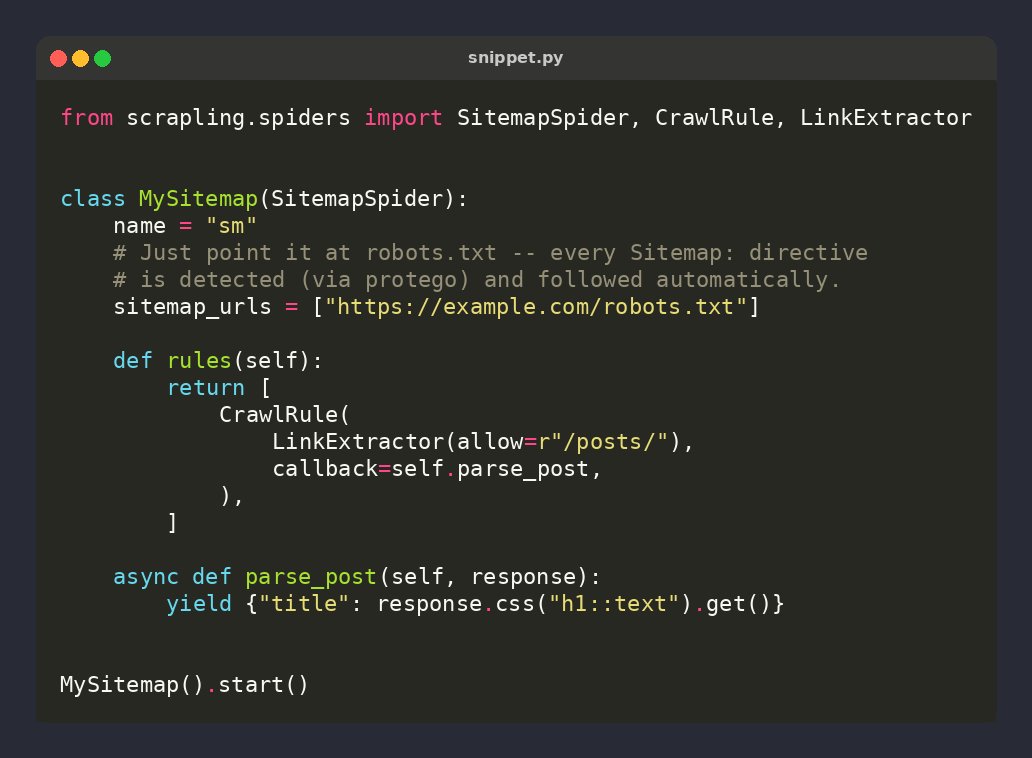
🕷️ Scrapling tip: drop a robots.txt URL into SitemapSpider — every Sitemap: directive is auto-extracted & crawled
class MySitemap(SitemapSpider):
sitemap_urls = ["site.com/robots.txt"]
No need to hunt for the sitemap URL yourself ⚡
1
1
3
119
Jun 5
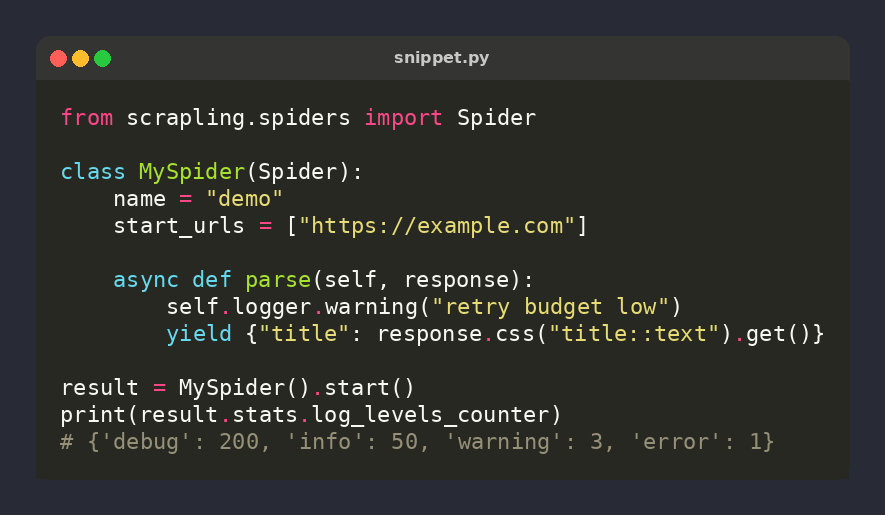
🕷️ Scrapling tip: stats.log_levels_counter — every self.logger.* call in your spider is bucketed by level into the final CrawlStats
result = MySpider().start()
print(result.stats.log_levels_counter)
# {'debug': 200, 'warning': 3, 'error': 1}
Free CI health signal 🎯
3
90
Scrapling 🕷️ retweeted
Jun 5
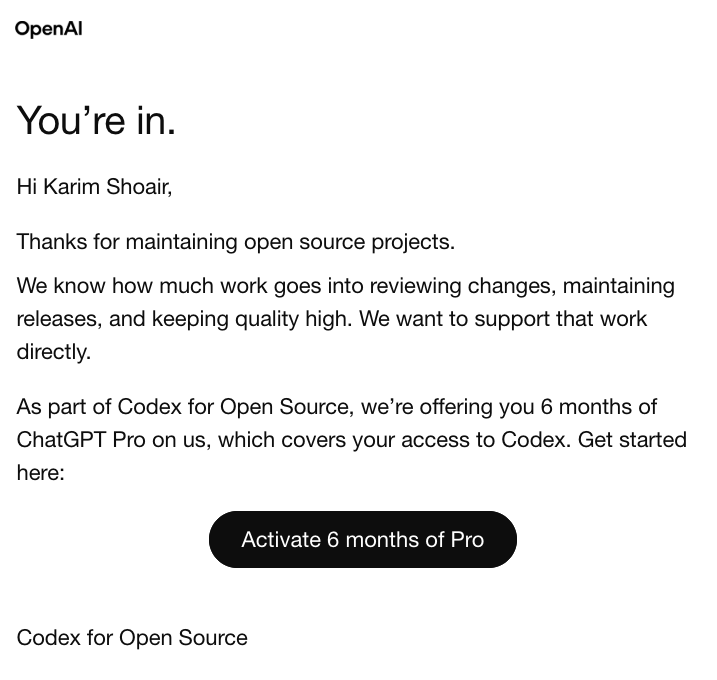
Thanks @OpenAI for this gift! 🎉
We are going to hugely benefit from it in @Scrapling_dev
1
6
189
Jun 4
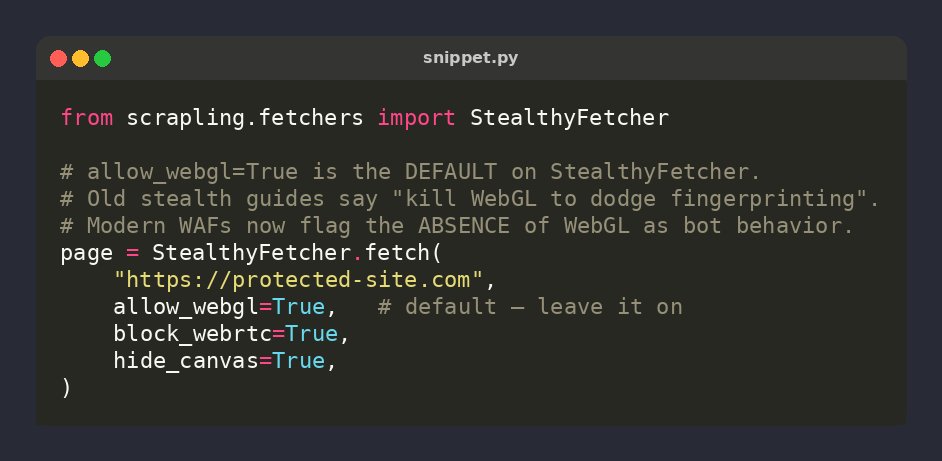
🕷️ Scrapling tip: old guides say "disable WebGL to dodge fingerprinting" — modern WAFs now flag the ABSENCE of WebGL as bot behavior
allow_webgl=True is StealthyFetcher's DEFAULT. Keep it on; the missing canvas is what gets you caught 🎯
2
4
84
Jun 3
🕷️ Scrapling tip: response.follow() INHERITS the original request kwargs — headers, proxy, impersonate carry over
yield response.follow(
'/next',
headers={'X-Trace': '1'},
)
New kwargs MERGE over old. Configure once on the seed, every follow inherits ⚡
2
87
Jun 1
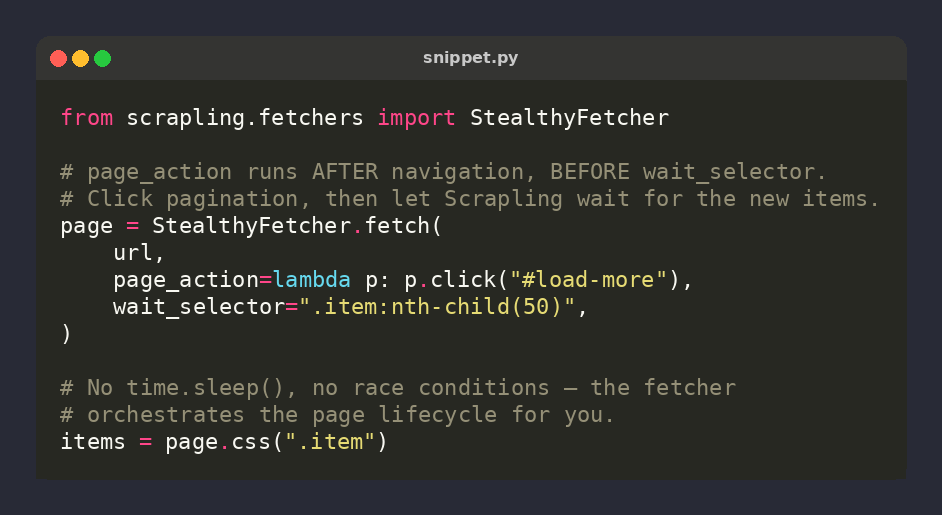
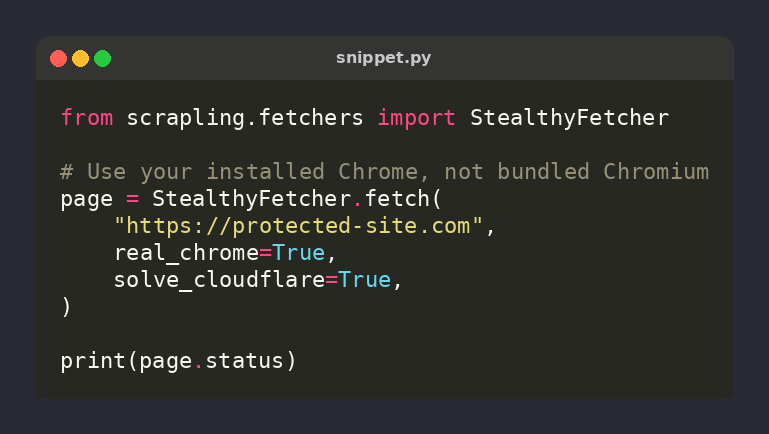
🕷️ Scrapling tip: real_chrome=True uses your installed Chrome instead of bundled Chromium
page = StealthyFetcher.fetch(
url,
real_chrome=True,
)
Vanilla Chromium lacks Chrome's proprietary codecs — WAFs notice. Real Chrome = authentic fingerprint ⚡
1
2
108
May 31
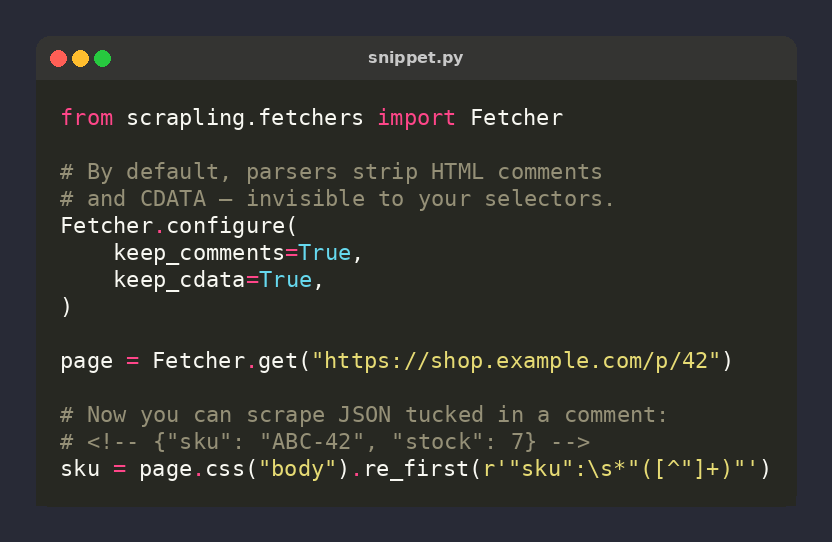
🕷️ Scrapling tip: parsers STRIP HTML comments & CDATA by default — anything inside <!-- --> or <![CDATA[]]> is invisible to your selectors
Fetcher.configure(
keep_comments=True,
keep_cdata=True,
)
Flip both on for templates, JSX, or JSON tucked in comments ⚡
2
120
May 30
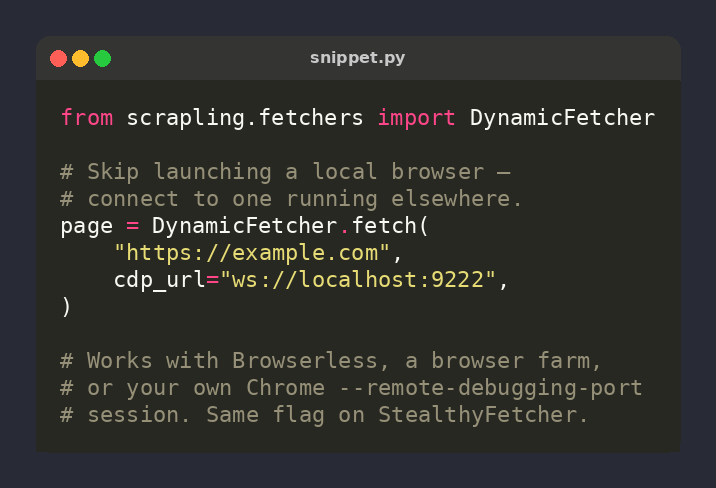
🕷️ Scrapling tip: skip launching Chromium — connect to a remote browser via CDP
page = DynamicFetcher.fetch(
url,
cdp_url='ws://localhost:9222',
)
Talk to Browserless, a browser farm, or your own Chrome --remote-debugging-port session ⚡
4
138