
Joined November 2011
- Tweets 51
- Following 290
- Followers 189
- Likes 407
2 Photos and videos


Pinned Tweet

Feb 12
Hosting an event with YC founders and applied researchers/res. engineers in Boston / Cambridge.
Join us to talk about hard research problems and startups!
2
2
8
763
May 13
Proud to be building 🇨🇦 Thanks for supporting!
May 12

AI is already helping Canadian companies solve real problems, improve services and compete globally.
Today in Vancouver, we announced $66 million in support for 44 Canadian companies through the AI Compute Access Fund to help them access the compute power they need to scale and grow here in Canada.
Canadian talent.
Canadian innovation.
Building Canada strong for all Canadians.
🇨🇦
L’IA aide déjà les entreprises canadiennes à résoudre des problèmes concrets, à améliorer leurs services et à être compétitives à l’échelle mondiale.
Aujourd’hui, à Vancouver, nous avons annoncé un soutien de 66 millions de dollars par l’intermédiaire du Fonds d’accès à une capacité de calcul pour l’IA à 44 entreprises canadiennes, afin de les aider à accéder à la puissance de calcul dont elles ont besoin pour se développer et croître ici, au Canada.
Talents canadiens.
Innovation canadienne.
Bâtir un Canada fort pour tous les Canadiens.




3
63
Apr 18
Many well written arguments. And the thesis itself is what I’ve been a fervent believer of since the so-called “plateaus” hit in late 2024.
Overparametrized models have a lot more secrets we can unlock.

5
77
Sepand Dyanatkar retweeted

Apr 4
This is an interesting result and we found something complementary. SSD is the clean case where SFT is on unfiltered samples. Our work, Compute as Teacher (CaT), asks what additional signal you can extract when you have multiple rollouts that disagree with each other. CaT exploits disagreement across multiple rollouts and synthesizes them into a better pseudo-reference answer, decomposing it into binary rubrics for scoring in RL. Interestingly, RL on these synthetic rewards consistently outperforms SFT on the same synthetic targets.

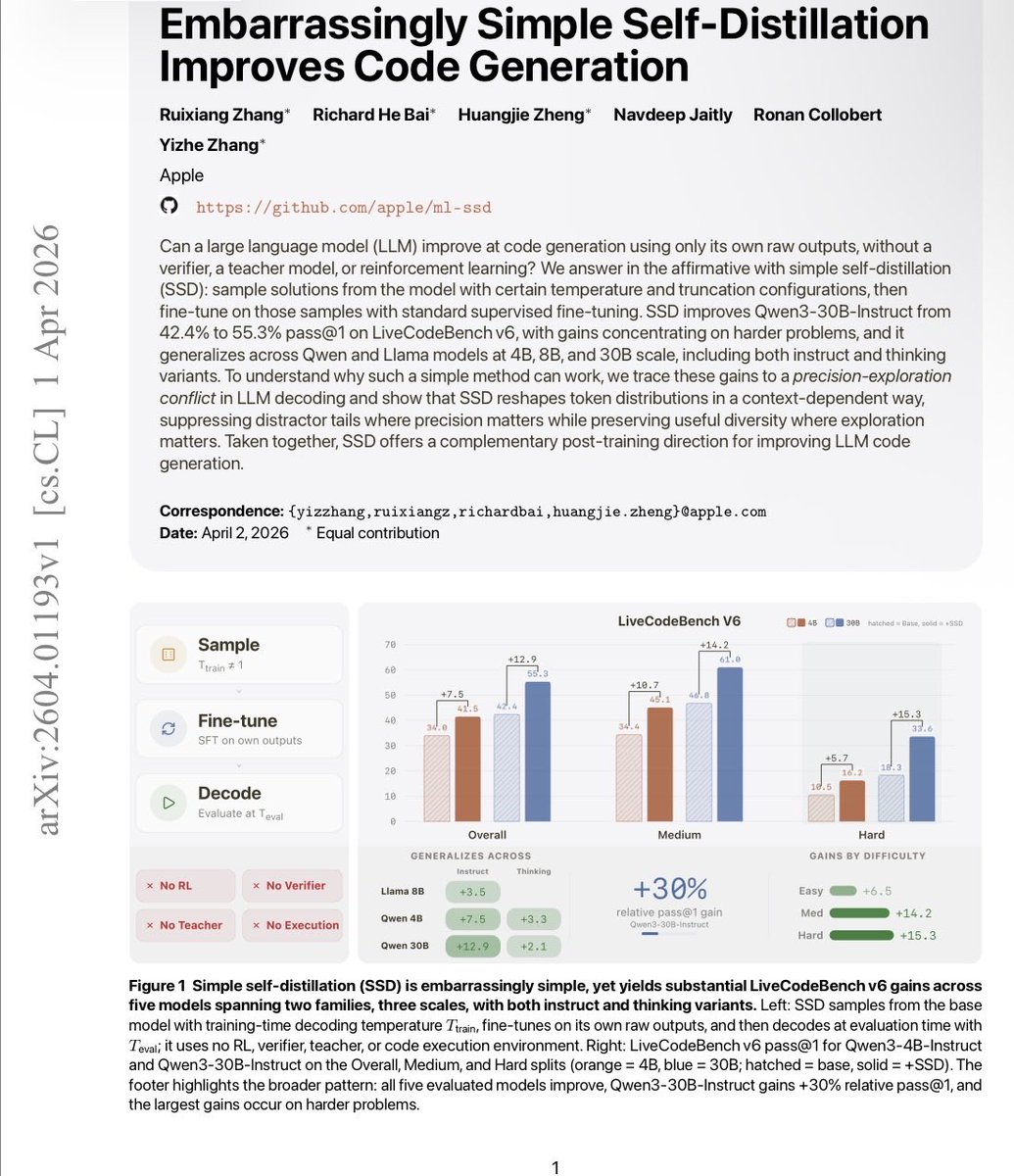
Apple Research just published something really interesting about post-training of coding models.
You don't need a better teacher. You don't need a verifier. You don't need RL.
A model can just… train on its own outputs. And get dramatically better.
Simple Self-Distillation (SSD): sample solutions from your model, don't filter them for correctness at all, fine-tune on the raw outputs. That's it.
Qwen3-30B-Instruct: 42.4% → 55.3% pass@1 on LiveCodeBench. 30% relative. On hard problems specifically, pass@5 goes from 31.1% → 54.1%.
Works across Qwen and Llama, at 4B, 8B, and 30B. One sample per prompt is enough. No execution environment. No reward model. No labels.
SSD sidesteps this by reshaping distributions in a context-dependent way — suppressing distractors at locks while keeping diversity alive at forks. The capability was already in the model. Fixed decoding just couldn't access it.
The implication: a lot of coding models are underperforming their own weights. Post-training on self-generated data isn't just a cheap trick — it's recovering latent capacity that greedy decoding leaves on the table.
paper: arxiv.org/abs/2604.01193
code: github.com/apple/ml-ssd
2
2
47
7,830

Mar 26
The tree-of-possibilities idea is exactly what I’ve been looking for as I build our internal auto research engineering system. I’d bet a lot from systems research applies here. It feels adjacent to model checking, state-space exploration, and symbolic execution.
Mar 25

The AI Scientist: Towards Fully Automated AI Research, Now Published in Nature
Nature: nature.com/articles/s41586-0…
Blog: sakana.ai/ai-scientist-natur…
When we first introduced The AI Scientist, we shared an ambitious vision of an agent powered by foundation models capable of executing the entire machine learning research lifecycle.
From inventing ideas and writing code to executing experiments and drafting the manuscript, the system demonstrated that end-to-end automation of the scientific process is possible.
Soon after, we shared a historic update: the improved AI Scientist-v2 produced the first fully AI-generated paper to pass a rigorous human peer-review process.
Today, we are happy to announce that “The AI Scientist: Towards Fully Automated AI Research,” our paper describing all of this work, along with fresh new insights, has been published in @Nature!
This Nature publication consolidates these milestones and details the underlying foundation model orchestration. It also introduces our Automated Reviewer, which matches human review judgments and actually exceeds standard inter-human agreement.
Crucially, by using this reviewer to grade papers generated by different foundation models, we discovered a clear scaling law of science. As the underlying foundation models improve, the quality of the generated scientific papers increases correspondingly. This implies that as compute costs decrease and model capabilities continue to exponentially increase, future versions of The AI Scientist will be substantially more capable.
Building upon our previous open-source releases (github.com/SakanaAI/AI-Scien…), this open-access Nature publication comprehensively details our system's architecture, outlines several new scaling results, and discusses the promise and challenges of AI-generated science.
This substantial milestone is the result of a close and fruitful collaboration between researchers at Sakana AI, the University of British Columbia (UBC) and the Vector Institute, and the University of Oxford. Congrats to the team!
@_chris_lu_ @cong_ml @RobertTLange @_yutaroyamada @shengranhu @j_foerst @hardmaru @jeffclune
3
103
Feb 25
Agreed. Part of OnDeck and my thesis is that:
- systems will prevail in performance,
- todays models are severely underutilized. And tomorrow’s too, leaving a gap.
- multi-step reasoning can close the gap, and do so faster than base model improvements or tuning on every single domain will
Feb 25
Haven't gotten around to writing in a bit, here's a short blog on my thoughts since releasing RLMs on the state of AI research.
A stronger belief I hold is that future LMs will be scaffolds, and that current LMs are already far more capable than we use them for!

1
163
Feb 17
1. Overlaps with our reasoning for building the applied research startup that is solving visual reasoning.

1
1
225
Feb 12
Hosting an event with YC founders and applied researchers/res. engineers in Boston / Cambridge.
Join us to talk about hard research problems and startups!
2
2
8
763
Feb 12
Personally very excited to discuss VLMs and long-context reasoning!
2
71
Feb 5
✅
Thanks for listening! 🫶
Big shoutout to @AJDungate, very proud of you constructively standing up.
YC, 🇨🇦 appreciates you a lot.
Feb 5

After hearing feedback from Canadian founders in our network, we’ve decided to add Canada back to our list of accepted countries of incorporation.
Going forward, YC will once again invest in US, Canada, Cayman, and Singapore corporations.
ycombinator.com/blog/adding-…
3
260
Jan 29
Interesting perspective. Reminds me vaguely of GNN analysis. I wonder if there are challenges similar to over-smoothing, over-squashing, etc
Jan 28

SFT→RL is the default recipe for reasoning LLMs… but why does it work mechanistically? 👀
Matsutani et al. analyze reasoning paths at 1/ trajectory-level and 2/ step-level

3
113
Jan 27
I think the answer is going to be markdown. All of our systems will just end up being markdown files, whether or not they are hosted on some fancy platform like Notion.
Markdown from top to bottom, and claude can touch everything.
1
3
59
Jan 27
Things like this make it more and more practical github.com/tobi/qmd
No more fragmentation across 10 different platforms!
3
56
5 Sep 2025
Excited to be featured in a Forbes article with some other fantastic companies!
4 Sep 2025

Want to have a closer look at @ycombinator Summer Batch 2025?
Check my latest article for @Forbes.
You won’t be disappointed.
forbes.com/sites/dariashunin…
@stake_jevens @joefioti @alessiapacca @carlosjc__ @michwirantono @Neha_Suresh_M @pederzh @SepandD @adithreddi @grx_xce @neil_nie_ @ethanmgibbs
1
10
412
Sepand Dyanatkar retweeted

4 Sep 2025
Want to have a closer look at @ycombinator Summer Batch 2025?
Check my latest article for @Forbes.
You won’t be disappointed.
forbes.com/sites/dariashunin…
@stake_jevens @joefioti @alessiapacca @carlosjc__ @michwirantono @Neha_Suresh_M @pederzh @SepandD @adithreddi @grx_xce @neil_nie_ @ethanmgibbs
10
18
67
28,806
Sepand Dyanatkar retweeted

21 Aug 2025
📹@OnDeckAI is the fastest way for companies to analyze video.
No more building models or labelling data - they instantly find any behaviour, object, or event in any footage.
ycombinator.com/launches/OEm…
Congrats on the launch, @AJDungate @sepandD!
8
15
87
13,903
9 Aug 2025
Thanks for the group selfie Angel!
@paulg is genuinely excited and helpful towards each person he talks to.
Halfway done @ycombinator S25 now.
This is a pretty cool experience.
6 Aug 2025

Day 37 of @ycombinator: If you ever get the chance to spend an evening with @paulg, you'll understand exactly how YC became the best accelerator program in the world.
What a guy!

6
459