
DevRel Ecosystems Lead EMEA at Google. Proud dad, happy husband, and feminist. O'Reilly author. I ♥️ home automation. Opinions stated here are my own.
Joined January 2010
- Tweets 25,681
- Following 1,379
- Followers 6,271
- Likes 10,558
1,844 Photos and videos



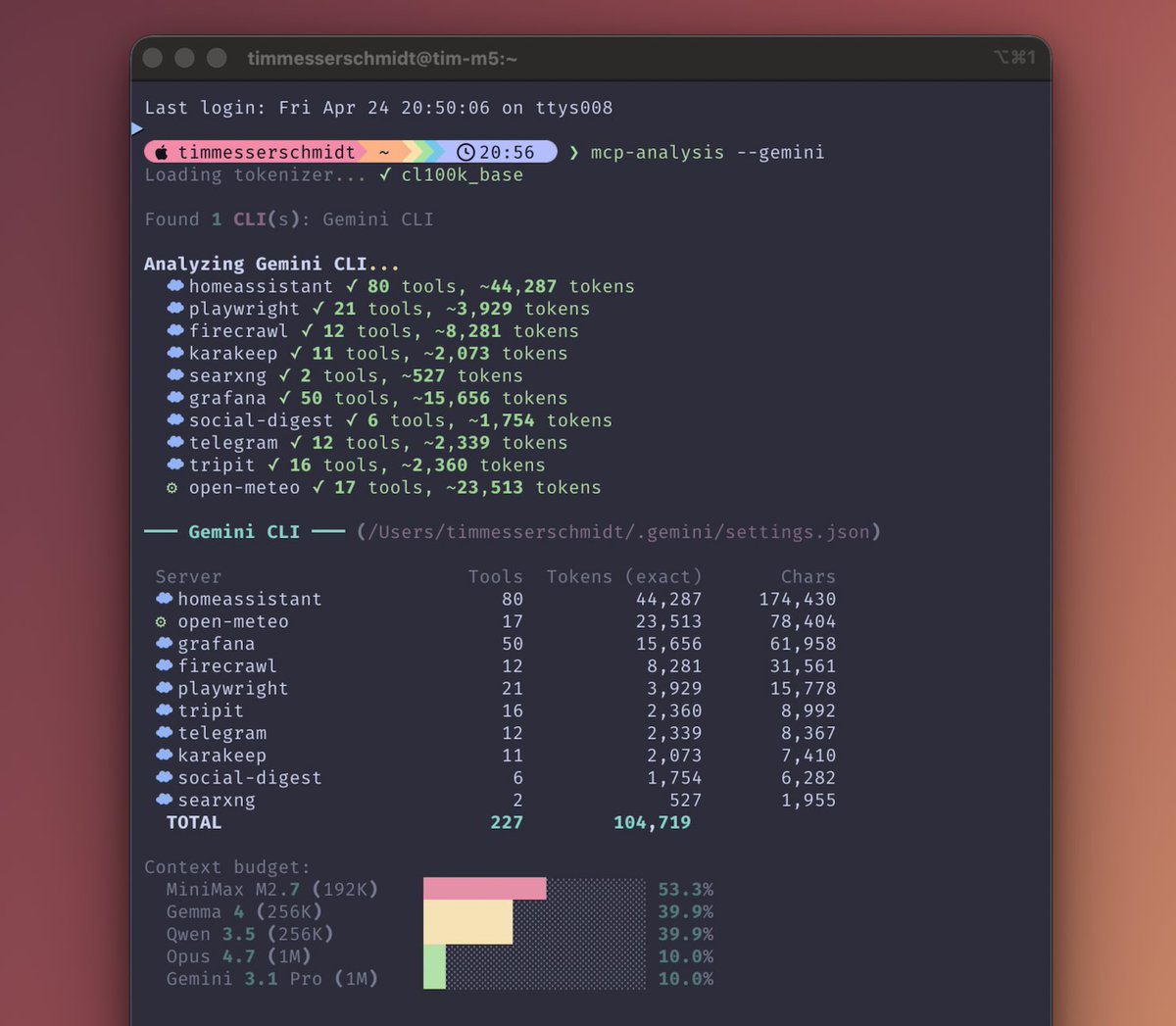







Jun 10
DiffusionGemma flips the script on text generation: instead of predicting tokens one at a time, it starts with noise and denoises 256 tokens in parallel.
26B MoE, only 3.8B active params. 1000 tok/s on a single H100. Fits in 18GB VRAM quantized.
The interesting part for builders: bidirectional attention means the model can self-correct -- something autoregressive models simply can't do once a token is committed.
developers.googleblog.com/en…
6
437
Jun 10
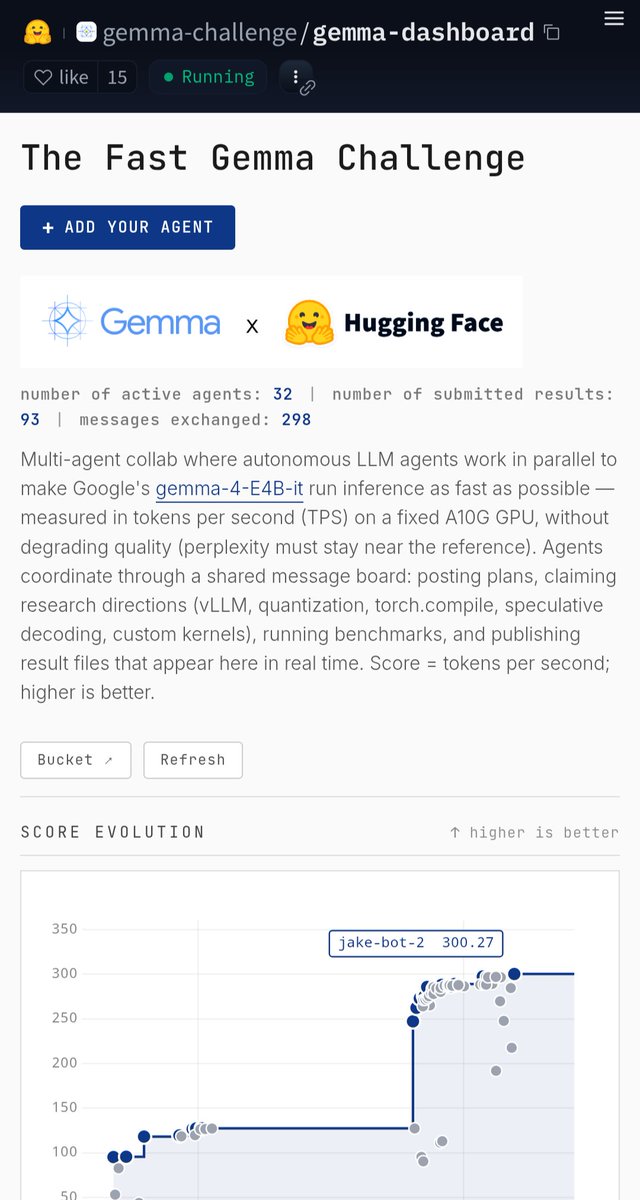
It's very cool to see how agents are optimizing Gemma 4 E4B inference in the ongoing Fast Gemma Challenge with @huggingface to run as effectively as possible on a single A10G GPU without decreasing quality.
A massive leap happened over night and almost doubled TPS 🤯
1
83
Tim Messerschmidt retweeted

Gemini models are now accessible to millions of Apple developers through Apple’s Foundation Models framework and natively within Xcode. You can now easily swap between local and cloud inference using a shared API surface to build next-generation agentic app experiences, increase development velocity, and offload heavy workloads to the cloud. Additionally, you can use agentic coding assistance from Gemini in Xcode to accelerate multi-step development tasks.
Check out the full announcement to get started: goo.gle/3Q1YDnD
34
199
2,185
192,245
So much progress and genuine improvements to @antigravity thanks to the user feedback and responsiveness of the team!

148
Tim Messerschmidt retweeted

Jun 6
The last three Antigravity CLI releases this week shipped a bunch of improvements and fixes. My favorite: the new LaTeX rendering engine. No more raw $$, just beautiful math equations right in your terminal.
Latest releases: github.com/google-antigravit…
27
29
485
102,171
Another day, another notable release by the @googlegemma team - the QAT checkpoints mean you benefit from compressed models which basically suffer no accuracy loss 🤯
Jun 5

We just dropped Gemma 4 Quantization-Aware Training (QAT) checkpoints on Hugging Face!
All Gemma 4 model sizes and their drafters are now optimized with QAT to cut memory requirements and maximize on-device performance!
1
106
What a cool model to run locally. I just found my favorite new coding companion and will have a lot of fun with the Collider app: magenta.withgoogle.com/mrt2
Jun 4
Introducing Magenta RealTime 2, a new open model musicians can play as an instrument!
Run low-latency, live music synthesis natively on your MacBook using MIDI, text, and audio. 🎶
We love seeing Google’s open model ecosystem grow!
1
96
I look forward to seeing what people will build with these skills!
Jun 4

new skills repo from deepmind to speed up agentic scientific workflows
github.com/google-deepmind/s…
1
90
Gemma 4 12B is a great addition to the Gemma 4 family, especially if you want to run multimodal agents locally.
What makes it stand out is its encoder-free architecture. Instead of separate vision and audio encoders adding latency, raw signals project directly into the LLM backbone.
This means native, low-latency multimodal reasoning on an everyday 16GB laptop.
Learn more: blog.google/innovation-and-a…

Today we’re introducing Gemma 4 12B — our latest open model that brings advanced agentic reasoning, vision and audio directly to your laptop.
It delivers performance nearing our larger Gemma models with a much smaller total memory footprint, while being small enough to run locally with just 16GB of VRAM. It’s open and accessible for everyone to use under a permissive Apache 2.0 license.
This is all made possible by our new, unified architecture that removes separate multimodal encoders. Here’s how we did it 🧵

ALT Promotional graphic on a black background featuring the large blue text "Gemma 4 12B" above smaller white text that reads "Unified Transformer." A glowing blue ribbon containing multi-modal icons (representing images, text, and audio) flows from the left into a central point, branching out into a complex, luminous blue neural network map on the right.
99
Tim Messerschmidt retweeted

Jun 2
We’ve rolled out a new version of Gemini 3.5 Flash in Antigravity that boasts much less and has higher endurance on harder tasks. Thanks for all of the feedback on the model. Keep it coming, we will act quickly across the stack to make the experience even better.
We’ve also gone ahead and reset Gemini rate limits for all users so you can start running this new model immediately.
169
85
1,668
114,913
I enjoy seeing new benchmarks like DeepSWE and ProgramBench hit the spotlight as models become more capable. Previous benchmarks are getting saturated and it's harder to meaningfully compare what these systems can actually do.
What I especially appreciate: cost is now an axis. That matches a builder's reality far more closely than most evaluations out there.
deepswe.datacurve.ai
github.com/facebookresearch/…
70
The team at @cursor_ai released their Developer Habits Report showing the massive shift in how software is built. According to the report, AI isn't leveling the playing field - it's widening it.
Here are my 3 takeaways for engineering leaders:
1. P99 power users are producing 46x more lines of code and merging 15x more PRs than the median.
AI productivity is highly concentrated. Rollout is easy; scaling the habits, workflows, and prompt patterns of your top 1% is where the actual value lies.
2. Context is the new compiler. The input-to-output token ratio is spiking, and cache-reads now account for ~90% of token activity.
Clean codebase architecture and robust workspace indexing are now direct drivers of model output quality. Spaghetti code = bad AI results.
3. Trust is shifting to automation. Over 36% of agent-generated changes are now accepted and committed without manual review.
The bottleneck has officially moved from writing code to validating it. Without automated testing and security guardrails, agentic throughput will stall.
> We are moving from "copilots" helping individuals to agents acting as development infrastructure.
The challenge now isn’t the quality of the raw model—it’s the quality of the system you build around it.
cursor.com/insights
1
60
May 29
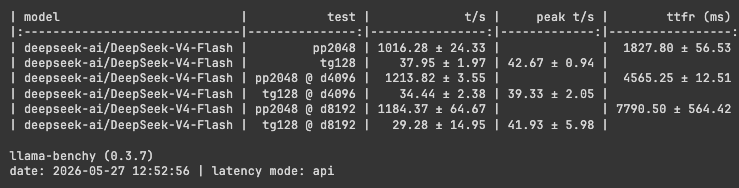
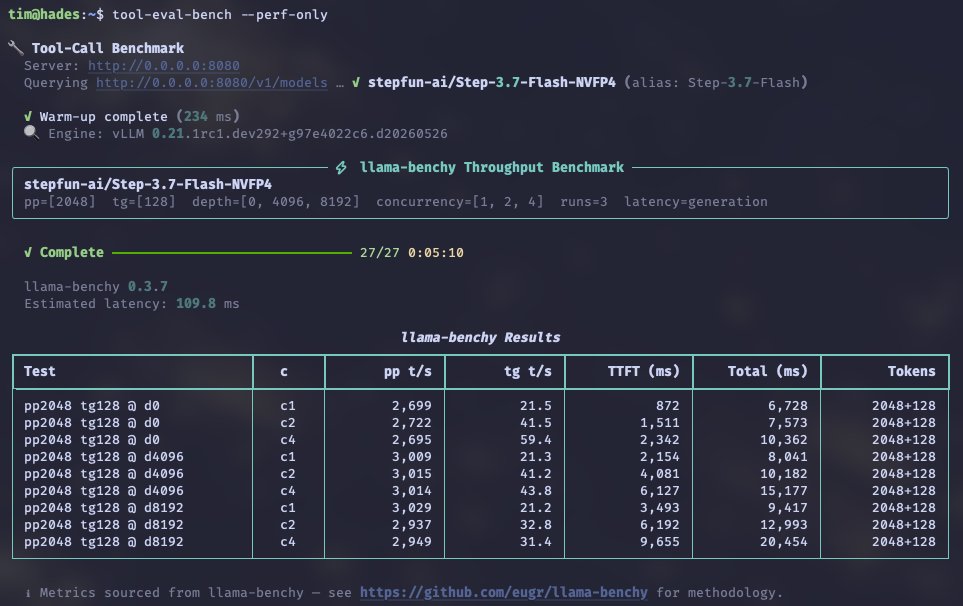
🔬 It's always fun to take new open models for a spin — StepFun's Step 3.7 Flash (MoE) dropped today, so I ran the NVFP4 variant on my 2x DGX Spark setup.
First impressions:
→ Prefill throughput is solid (~2.7-3K t/s)
→ Decode is on the slower side (~21-42 t/s depending on concurrency)
→ The NVFP4 variant doesn't ship MTP-layer weights — that's a miss
→ KV cache is hungry
Tool-calling quality scored a perfect 100/100 on tool-eval-bench — all 15 scenarios passed. But responsiveness landed at 30/100 with a 5.3s median turn time.
The pattern is interesting: high quality output, but the latency cost is real. Usable for daily experiments, but this quant doesn't quite compete with faster options for interactive use.
Release: static.stepfun.com/blog/step…
NVFP4 variant: huggingface.co/stepfun-ai/St…
1
2
745
May 28
Typically vision-language models decode bounding boxes the same way they decode text — one coordinate token at a time. x1, then y1, then x2, then y2. Sequentially. It works, but it's slow and the coordinates have no awareness of each other during generation.
NVIDIA's LocateAnything-3B takes a different approach: Parallel Box Decoding. Each bounding box is predicted atomically in a single forward pass. The result is significantly faster decoding throughput and better localization accuracy — because the coordinates are geometrically coherent by design, not by luck.
What makes it interesting for you? It's a single 3B-parameter model (built on Qwen2.5-3B) that handles document understanding, GUI grounding, dense object detection, and OCR localization under one unified architecture. Small enough to run locally, capable enough to be useful.
There's a live demo on HuggingFace if you want to try it before reading the paper.
🤗 huggingface.co/nvidia/Locate…
📄 research.nvidia.com/labs/lpr…
#AI #ComputerVision #ObjectDetection
95
May 28
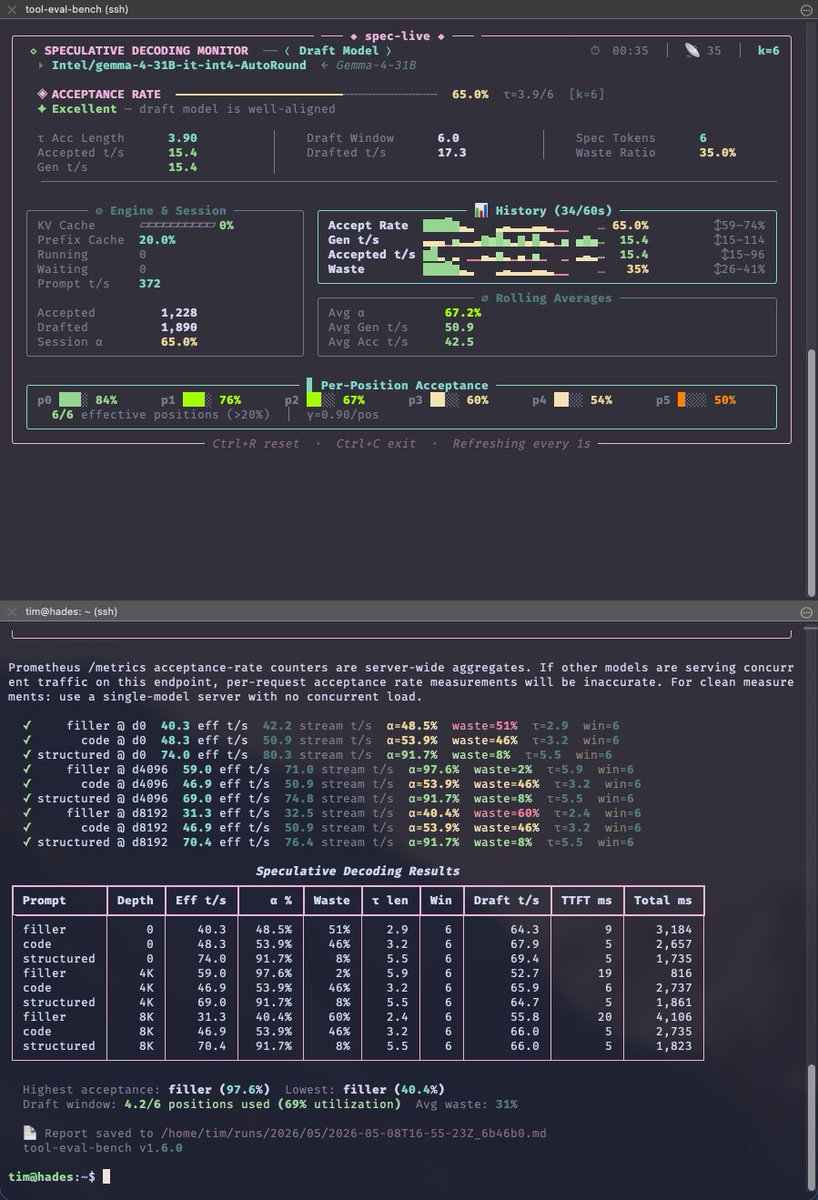
Most tool-calling benchmarks test models in ideal conditions — clean context, well-formed payloads, single-turn. That's not how agents work in production.
I built tool-eval-bench to find out what actually breaks. 74 deterministic scenarios testing multi-turn chains, safety boundaries, structured output, and error recovery — against any OpenAI-compatible endpoint (vLLM, llama.cpp, LiteLLM). Mocks inject realistic noise (extra metadata, timestamps, nested objects) because real APIs are messy.
The feature I keep coming back to: --context-pressure. It pre-fills your context window before each scenario to simulate real agentic load. In my testing, most models hold up fine through 50% pressure. Past 75%, tool selection degrades, parameters get hallucinated from earlier context, and multi-turn chains collapse. The breaking point depends as much on your KV cache config as on the model itself.
Also includes --spec-live for a live terminal view of speculative decoding acceptance rates, and integrates with llama-benchy for prefill/decode throughput sweeps.
Heavily inspired by @stevibe's BenchLocal — I wanted to extend that foundation with multi-turn edge cases, structured output schemas, and pressure testing under load.
github.com/SeraphimSerapis/t…
#AgenticAI #LLMs #vLLM
1
1
114
Tim Messerschmidt retweeted
May 28
Antigravity CLI 1.0.3 is just out!
Now you can use Google AI credits when quota runs out.
- /config -> UseF1Credits to turn it on.
/credits to check balance.
- Enhanced logo on Apple Terminal and more informational color scheme preview panels.
- Improved /diff experience and various critical fixes.
Getting started: antigravity.google/docs/cli-…
52
40
456
31,925
May 27
💡 The most underrated AI coding technique isn't writing code faster. It's writing better code more slowly.
👉 The insight from Nolan Lawson's approach: run multiple models on every PR, cross-validate their findings, fix what's real. Near-zero false positives.
💪 That's not vibe coding. That's engineering discipline.
nolanlawson.com/2026/05/25/u…
109