
Joined November 2018
- Tweets 1,337
- Following 793
- Followers 1,062
- Likes 1,062
37 Photos and videos









Pinned Tweet

28 Oct 2024
7 reasons why Lambda Live Debugger is completely transforming serverless development.
⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐
lldebugger.com/
#lambda #serverless #aws
1
1
357
😱How to lose data using AWS serverless without even knowing it
youtu.be/lw5XYXGtk0k
55
Marko - ServerlessLife.com retweeted

24 Dec 2025
TBH one of my bigger fears around AI is that it will lock in the median of today’s practices and quietly turn it into tomorrow’s “best practice.”
When a model is trained on the whole internet, it doesn’t learn the right way. It learns what’s most common, and the most common code and architecture patterns out there are…mixed at best. The model’s incentives reward likely and familiar, not better or novel, so it becomes a kind of gravity well that pulls teams back toward whatever already dominates the training mix.
And then there’s the feedback loop: AI-generated output gets shipped, copied into docs, pasted into blogs, merged into repos, and fed back into the next generation of training. That doesn’t just preserve the mess, it can compound it, creating a self-reinforcing layer of confidently explained mediocrity.
The scariest part is that real progress often starts out-of-distribution. New paradigms, emerging best practices, and the hard-won lessons from great teams are underrepresented, so they get drowned out by the volume of the average or even the sub-par. If AI becomes the default author/reviewer/teacher, we might get faster at producing more of what we already do and slower at evolving what “good” looks like.
If we’re not careful, we’ll end up with an industry that can autocomplete the past perfectly while struggling to invent the future.
24 Dec 2025

can we really teach AIs if they're controlled by companies that ingest the whole internet?
Any guidance tools we currently have are limited to ones own usage of the AI.
I don't really feel like anything can change here unless we train a frontend-focused model.
5
28
2,268
Marko - ServerlessLife.com retweeted
8 Dec 2025
I heard some folks missed my recent Web Component Engineering course sale, so I’m running one more:
✅ 25% off w/ code GOODTIDINGS25
✅ Through the 1st week of 2026
Web Components, DOM APIs, modern CSS, a11y, forms, design systems, tools, and more!
bluespire.com/course/web-com…

ALT A festive red and green banner advertising the Good Tidings Sale with 25% Off the Web Component Engineering course.
3
3
1,981
Marko - ServerlessLife.com retweeted

21 Nov 2025
Tis the season of AWS pre:Invent. Here is a quick lineup (so far) of the AWS releases that caught my eye:
- AWS Lambda Networking Over IPv6 aws.amazon.com/blogs/compute…
- AWS Lambda Enhances SQS Processing With New Provisioned Mode aws.amazon.com/blogs/aws/aws…
- Amazon ECS Service Availability Rolling Deployments aws.amazon.com/about-aws/wha…
- Application Load Balancer JWT Verification aws.amazon.com/about-aws/wha…
- Amazon API Gateway Portal for API Discoverability aws.amazon.com/blogs/compute…
- AWS IAM Outbound Identity Federation aws.amazon.com/blogs/aws/sim…
- Amazon API Gateway Response Streaming aws.amazon.com/blogs/compute…
- AWS Login for Simplified Developer Access aws.amazon.com/blogs/securit…
- DynamoDB Multi-Key Support for Global Secondary Indexes aws.amazon.com/blogs/databas…
- Amazon CloudFront 3 Functions Capabilities aws.amazon.com/about-aws/wha…
- Flat-Rate Pricing Plans With No Overages aws.amazon.com/blogs/network…
- Build scalable IPv4 addressing with AWS NAT gateway in regional availability mode, Amazon VPC IPAM policies and Prefix Lists aws.amazon.com/blogs/network…
- AWS Secrets Manager Managed External Secrets aws.amazon.com/about-aws/wha…
- Tenant Isolation Mode in AWS Lambda aws.amazon.com/blogs/aws/str…
- Accelerate Infrastructure Development With CloudFormation Validation aws.amazon.com/blogs/devops/…[…]ion-pre-deployment-validation-and-simplified-troubleshooting/
- CloudFormation Configuration Drift Enhanced Sets aws.amazon.com/about-aws/wha…
- Amazon ECS Built-In Linear Canary Deployments aws.amazon.com/about-aws/wha…
1
8
56
4,837
Marko - ServerlessLife.com retweeted

28 Oct 2025
⚡ IT’S ALIVE! ⚡
Web Awesome has escaped the lab — and it’s alive, fast, and open-source.
💼 Projects
🎨 Figma Design Kit
⚙️ Lightning-fast components
🔬 Launch Special: 20% OFF FOR LIFE on Web Awesome Pro
(Seriously. Last chance ever.)
Ends Nov 19 → webawesome.com/?utm_source=x…

4
16
35
4,884


23 Oct 2025
On Monday, AWS showed you how they can mess up your system. In this lecture, I will teach you how to do it yourself. 😜
Title: How to lose data using AWS serverless without even knowing it
from Serverless Days Milano
youtube.com/live/H2dZO9fqwGs…
Scroll to: 4:05:58
62
Marko - ServerlessLife.com retweeted
13 Oct 2025
I applaud Remix 3 for swinging the spotlight back to the Web Platform. If last week’s reveal showed anything, it’s how defaults, docs, and incentives can fence off core browser knowledge.
Framework-first norms didn’t mean to, but they *did* turn basics into trivia. So, the surprise around things like CustomEvent or listening on a parent to handle child interactions tells a story: the community has been standing next to power it wasn't taught to use.
Facts:
* CustomEvent has been baseline across modern browsers since 2015 (~10 years).
* Event delegation (via bubbling/capturing) is part of the DOM event model standardized in 2000 and used since the late ’90s (~25 years).
This isn’t an anti-framework post; it’s anti-amnesia.
Reach for what ships in the box: addEventListener delegation, CustomEvent, FormData, URLSearchParams, <template>, fetch, AbortController/signal, MutationObserver, IntersectionObserver, and more.
Remix 3 reminding people of this is a gift.
Don’t let anyone tell you the browser can’t do something. Try it yourself and see. The gate isn’t locked; it’s just been draped in velvet ropes and a “staff only” sign.
Walk through.
Use the platform first; add libraries when they clearly earn their keep.
Kudos to the @remix_run team for cracking the window and letting light back in. The web is strong medicine. Take it neat.
13
23
222
32,961
6 Oct 2025
Lambda Live Debugger v1.10 has been released with support for nested stacks 🎉
This update is largely thanks to Hugo Lewenhaupt — thank you, Hugo, for your hard work and for your contributions to Serverless Spy as well.
👉 lldebugger.com/
37
24 Sep 2025
Thank you for mentioning CDK Booster - a tool for speeding up bundling of TypeScript/JavaScript Lambda handlers.
cdkbooster.com/
24 Sep 2025

Issue #337 of Off-by-none is out! In this issue, Amazon Nova Act brings AI agents to your IDE, @Cloudflare backs Ladybird to push the open web forward, and @PlanetScale for Postgres goes GA. #offbynone offbynone.io/issues/337/
1
83
22 Sep 2025
Come and join me at #ServerlessDays Milan! 🇮🇹✨
My talk:
👉 “How to lose data using AWS Serverless without even knowing it”
🎟️ Tickets: milan.serverlessdays.io/
💸 50% off with SPEAKER50
🙌 Thanks @ServerlessItaly
75
15 Sep 2025
Presenting my new tool: CDK Booster 🚀
Speed up AWS CDK bundling of TypeScript/JavaScript Lambdas — no code changes needed.
👉 cdkbooster.com
#serverless #lambda #aws #cdk
2
125
9 Sep 2025
🔥 I’m speaking at ServerlessDays Milano on Oct 21, 2025!
My talk: “How to Lose Data Using AWS Serverless Without Even Knowing It” ⚡
⏳ Early bird tickets are still available → milan.serverlessdays.io/
39
1 Sep 2025
🎉 Lambda Live Debugger 1.9 is now available!
Optimized performance for large projects. 🚀
lldebugger.com/
1
54
22 Jul 2025
AWS finally recognizes that remote debugging is essential for fast serverless development. 💪
Here’s why this is great news for Lambda Live Debugger — which remains the most flexible and powerful tool for serverless debugging.
serverlesslife.com/Lambda_Li…
17 Jul 2025

NEW: Lambda adds remote debugging via a VS Code integration.
You can now set breakpoints in live lambda functions and debug them straight in your editor!
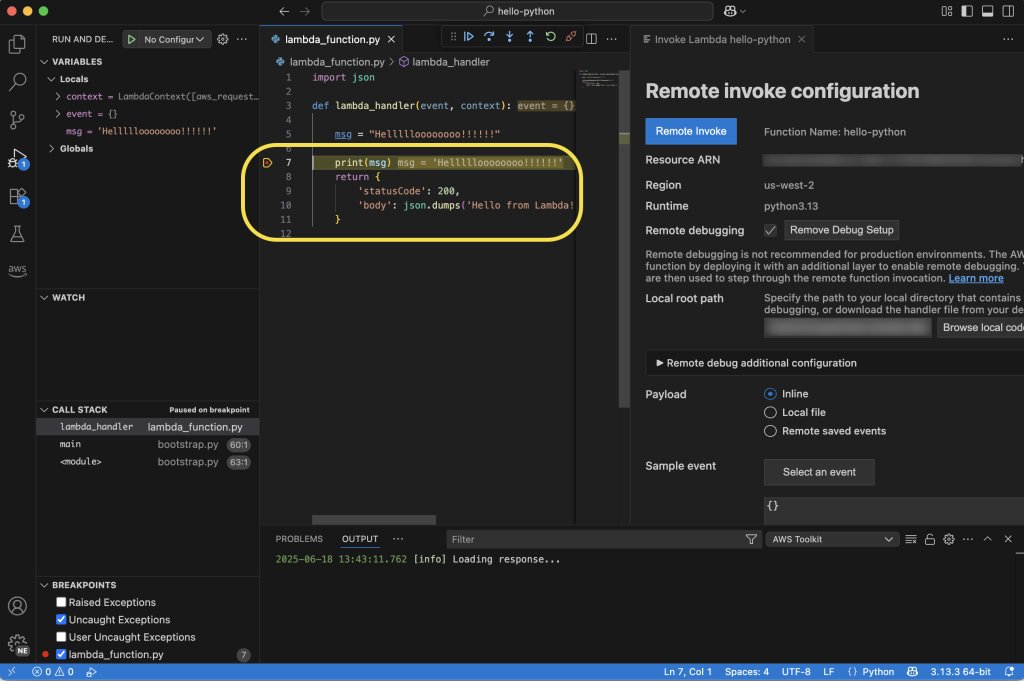
5
206
22 Jul 2025
How does Lambda Live Debugger compare with the new official remote debugging for Lambda?
serverlesslife.com/Lambda_Li…
1
3
116
Marko - ServerlessLife.com retweeted
31 May 2025
Oh, I'm not holding my breath for anything like that. 🤣
Full disclosure:
I don't see myself using Remix 3, whatever it is, because I've got my own full stack, standards-based framework based on 20 years of experience building server and client apps. (I'm trying to find a way to open source it, as I do think a lot of people would be interested, but I need to figure out the "funding" problem first.)
That said...
I am pretty exhausted, as a consultant and engineering leader, coming into companies where they have adopted various trendy JavaScript solutions, only to create a real disaster. Sure, I get paid very well to dig companies out of those holes, but I'd really rather not have to do that. There are so many more interesting things to focus on.
2
1
14
1,526
Marko - ServerlessLife.com retweeted
13 Jun 2025
Once again, I feel compelled to state what I thought was obvious:
There is no one size fits all software architecture.
Stop trying to build it.
Your job as an engineer/architect is to deeply understand the specific problem at hand and then work towards the best fit solution.
2
15
108
5,169
5 Jun 2025
Debug faster 🚀, debug smarter🧠
Live serverless debugging with Lambda Live Debugger 🤩
#serverless #lambda #aws
52
Marko - ServerlessLife.com retweeted
4 Jun 2025
I don't know @maxifirtman and I haven't taken his course, but I approve of content creators publishing more of this type of material:
frontendmasters.com/courses/…
1
2
13
1,839