
Ph.D. student at @MITEECS. Previous RA at @Oxford_VGG.
Joined August 2022
- Tweets 10
- Following 526
- Followers 535
- Likes 99
7 Photos and videos




Mar 24
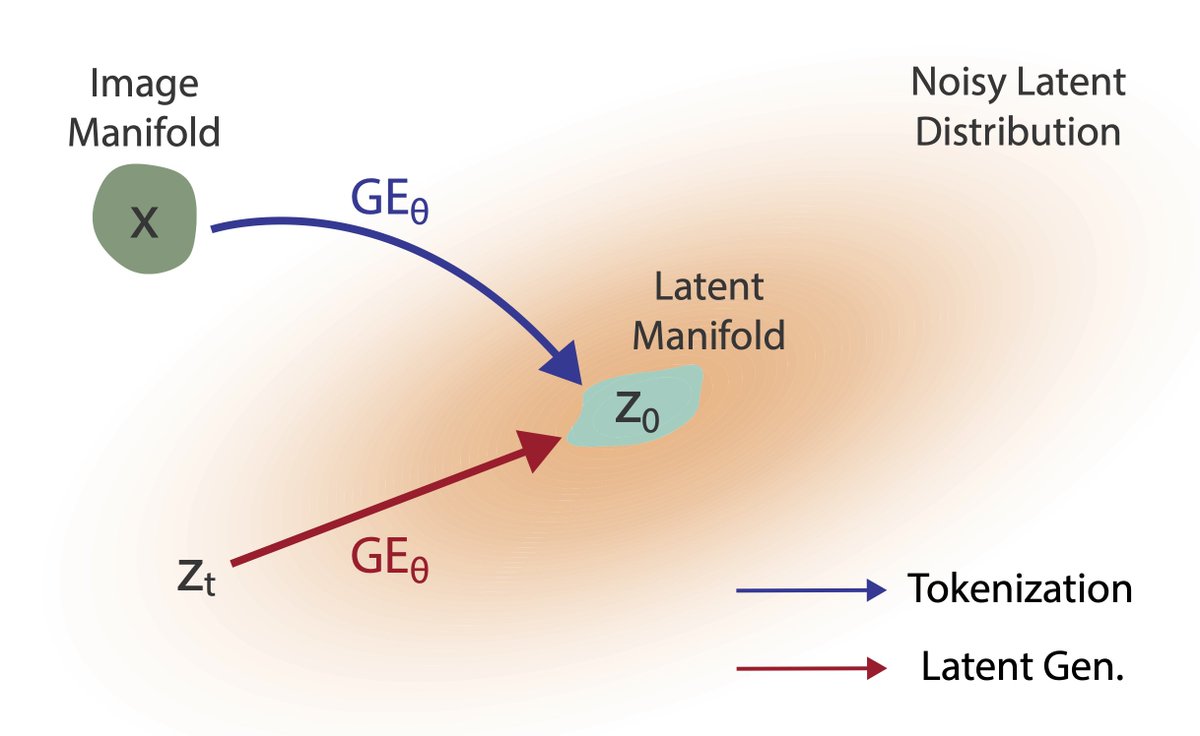
In our formulation, image tokenization and latent generation become two sides of the same coin. One model, one stage, from scratch—no pretrained encoders needed.
Especially excited about applying UNITE to modalities like molecules and crystals, where a pretrained DINO simply doesn't exist.
Very unforgettable collaboration with @ShivamDuggal4 and our amazing team at Adobe Research!
Mar 24

Tokenization & Generation power Large Models. But are they really separate?
Tokenization=Generation under strong observability
UNITE: An end-to-end training framework where one shared Generative Encoder (GE) performs both token. & latent denoising
Paper: arxiv.org/abs/2603.22283
1
9
61
8,549
Feb 19
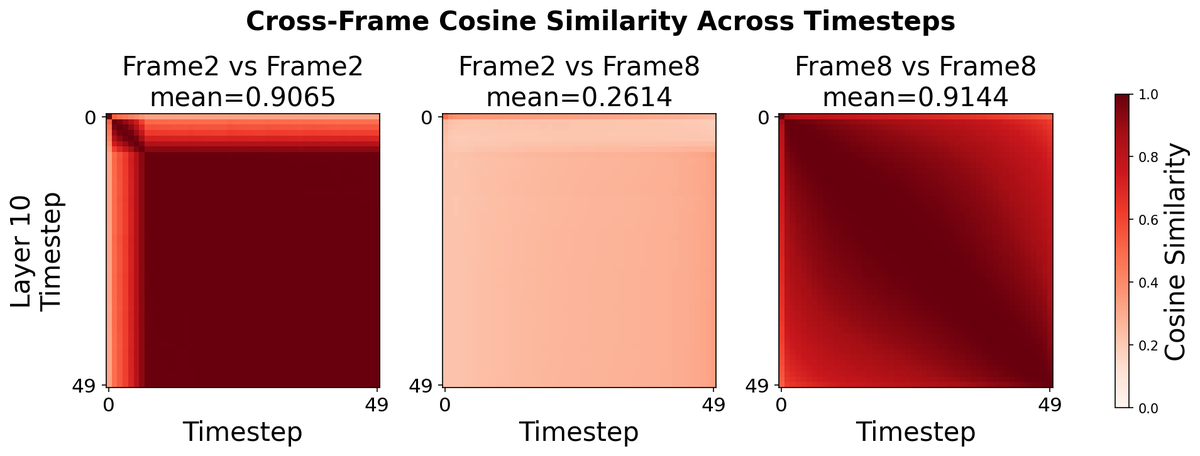
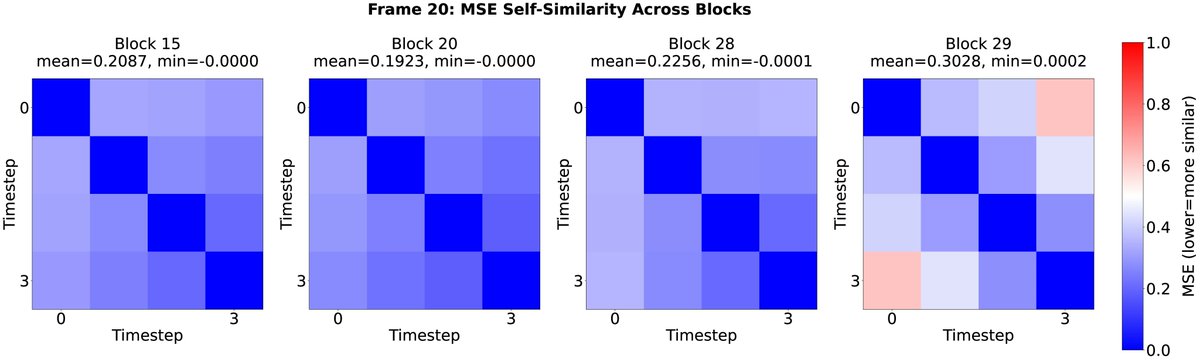
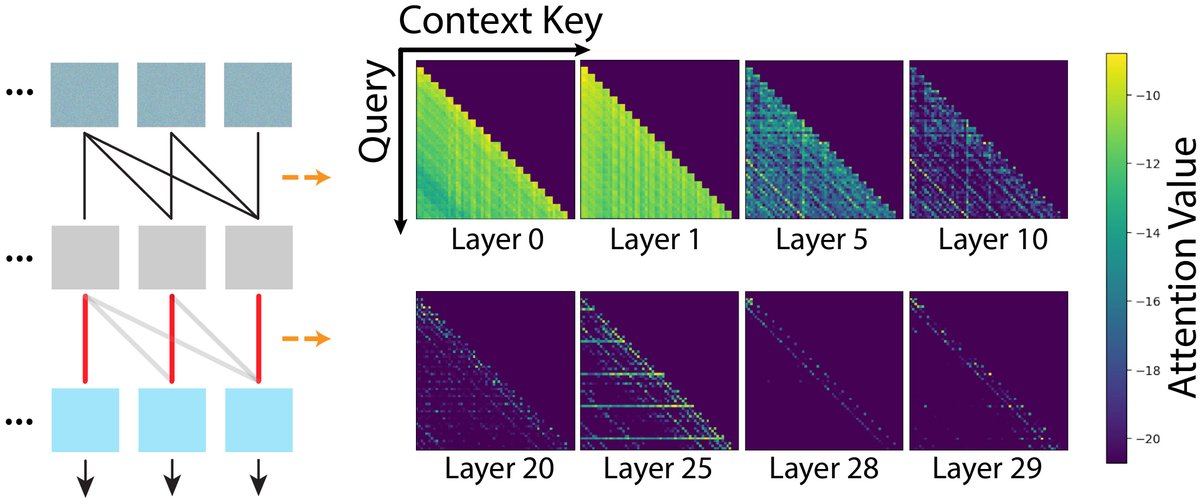
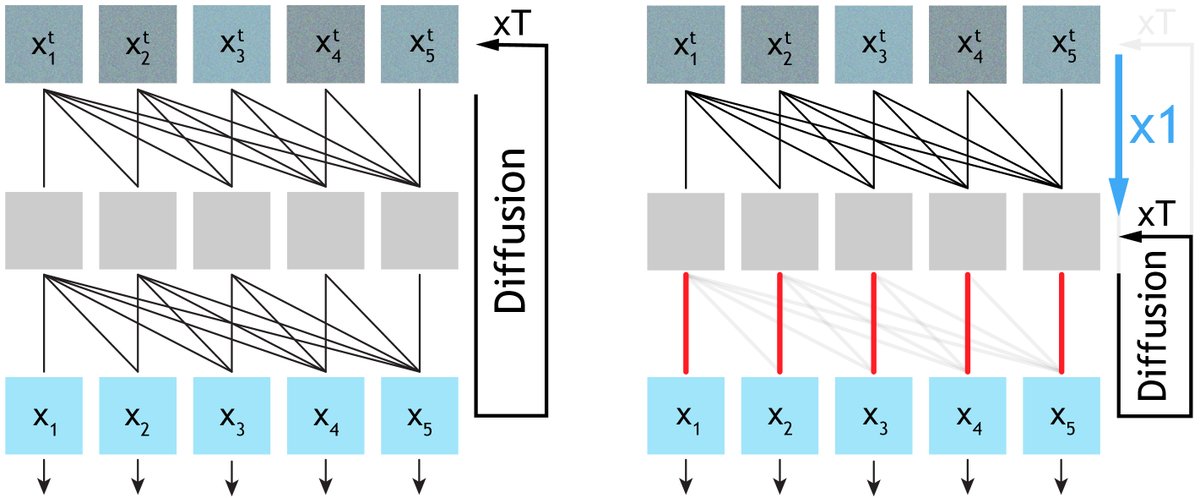
Do causal video diffusers really need dense causal attention at every layer, every denoising step?
We looked inside and found: no. Causality is separable from denoising.
Here are two surprising observations that hold across architectures, training objectives, and scales.
4
48
330
68,294
Feb 19
Trained from scratch, SCD beat previous models in all metrics at 4x lower latency.
We also fine-tuned from WAN 2.1, matching the VBench performance of the best frame-wise autoregressive models, while having 35% lower latency than Self Forcing, >10x faster than original WAN 2.1.
1
2
28
3,238
Feb 19
Project page: xingjianbai.com/sparse-causa…
Code (train from scratch): github.com/xingjian-bai/spar…
This work would not be possible without my amazing collaborators, @guande_he , @xxunhuang, @zhengqi_li, @elishechtman, @zongze_wu. I truly learned a lot from you through this exciting journey.
1
2
40
3,006