
Joined May 2026
- Tweets 10
- Following 5
- Followers 10
- Likes 2
2 Photos and videos


Jun 12
What are Claude Code & Codex doing under the hood? At a minimum: Running a model, a loop, and a few tools.
@wolfmanfx explains how to build a fully local coding agent from scratch: llama.cpp, a hand-written harness, and NVIDIA OpenShell as the sandbox.
soverius.ai/blog/implementin…
1
1
62
Jun 9
Tokens are becoming increasingly expensive. Are local LLMs ready to replace them? Join our free webinar to see for yourself.
We'll demo local setups, tools, and hardware.
You'll leave with a production-ready setup for immediate use.
Register now!
soverius.ai/webinars/softwar…
1
1
31
May 28
For a long time, AI discussions were mostly about the model.
🤖 Which one is better?
📊 Which benchmark was beaten?
🚀 Which new release changed everything?
But only the model is not enough. The layer around it is just as important: That's the harness.
📖 soverius.ai/blog/what-is-a-h…
2
10
755
Soverius AI retweeted

May 22
I really like it when tech CEOs skip the marketing fluff and just talk straight.
Sundar Pichai on the Hard Fork podcast, speaking openly about Google's current AI position:
"…when it comes to agentic coding… I think we are a bit behind at this moment."
youtu.be/RgV57kDzcng
1
1
3
810
May 18
Using @CopilotKit & Google's #A2UI with local LLMs? 🤖
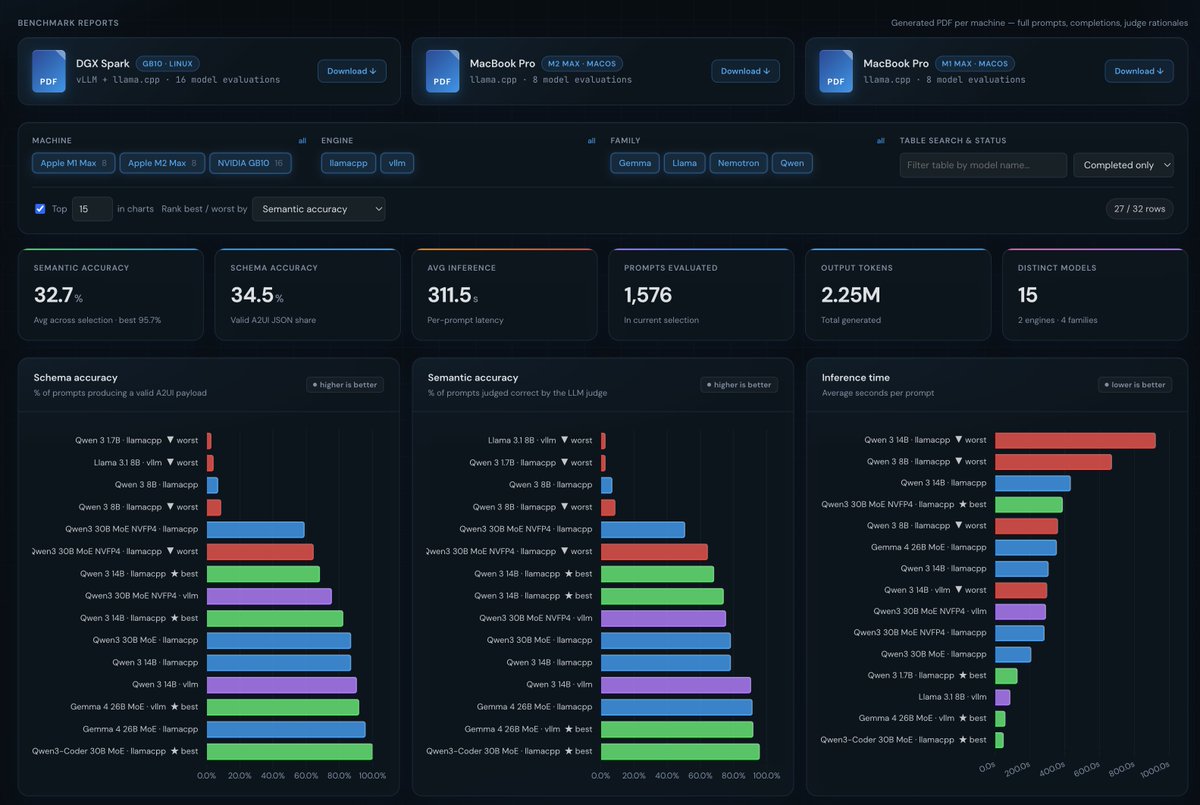
Following up on our article last week, here's the fully interactive, visual dashboard showcasing our benchmarks, created by @wolfmanfx:
👉 a2ui-bench.web.app/
The 3 key takeaways from our evaluation prompts 👇 (1/4)
1
2
2
916
May 18
2️⃣ Inference Engines Shift Accuracy ⚙️The engine matters. Running identical weights on different runtimes yielded completely different semantic accuracy. Qwen 3 14B hit 90.4% accuracy on vLLM, but dropped to 68.2% on llama.cpp. It's not just a performance choice! (3/4)
1
28
May 18
3️⃣ The Winner 🏆Gemma 4 26B MoE (NVFP4 via vLLM) is the winner. It achieved a 91.8% accuracy rate and clocked the fastest median inference speed.
Read our full architectural deep dive on how the validation schema and renderers handle this: 🔗 soverius.ai/blog/behind-the-… (4/4)
22
May 13
AI offers massive potential for UIs. The interface can be dynamically generated for each user.
A key technology is #A2UI, which is framework-agnostic.
Our new post covers:
✅ What is A2UI?
✅ How does it work?
✅ How to run it fully autonomously.
soverius.ai/blog/behind-the-…
2
4
889
May 8
RAG in a browser tab? No backend? Yes, it is possible.
@wolfmanfx spoke at AI India on "From the AI Jungle to RAG in a Tab." If you want to build full RAG pipelines that run entirely client-side for ultimate privacy and speed, the slides are live:
soverius.ai/talks/from-the-a…
1
1
88