
| Product Designer 🖥️ | Graphic Designer 👨💻 | Brand Identity Designer 🎨 | Creative Educator 🌱✨ |
Joined June 2023
- Tweets 136
- Following 43
- Followers 34
- Likes 473
104 Photos and videos














Incredible work by @lucasmaes_ and the team! Stable, end-to-end JEPA training from raw pixels is a massive leap forward.
I took the 15M parameter LeWorldModel, trained it from scratch, and pushed the local inference speed to the absolute limit.
The Engineering Pipeline:
• Cloud Training: 100k steps on the 43GB PushT dataset using an H100.
• The Bottleneck: To run local MPC planning on a consumer gaming GPU, the native PyTorch Epps-Pulley math for the SIGReg loss was memory-bound.
•I wrote a custom Warp-Reduction CUDA kernel, fusing the mean, variance, and hinge-loss calculations directly into the SM registers.
• The Result: Crushed execution latency from 6.6ms down to 92µs (a 72.4x speedup) and achieved an exact 86.0% zero-shot success rate.
What This Means for Robotics:
Giving a robot a "World Model"—a brain that can actually imagine and predict the physics of its environment before making a move—used to require massive, expensive compute. By optimizing the underlying CUDA math, this just proved these forward-thinking robotic brains can run smoothly in real-time on a standard consumer laptop. Fast, cheap, and accessible robotic AI is here.
Custom CUDA kernel & local-to-cloud pipeline available in my fork here:
github.com/Kars07/le-wm-cuda…
Mar 23

JEPA are finally easy to train end-to-end without any tricks!
Excited to introduce LeWorldModel: a stable, end-to-end JEPA that learns world models directly from pixels, no heuristics.
15M params, 1 GPU, and full planning <1 second.
📑: le-wm.github.io
2
15
32
1,406

Jan 12
No brief. No client. Just play.
One logo became a full identity.
Bambi Arts.
#BrandIdentity #DesignProcess #StillSPECTRE



1
3
20
Jan 3
Not everything built in 2025 was posted 👀
Here’s a glimpse of the work behind the scenes
#LogoFolio2025 #DesignWork #SpectreHub #StillSPECTRE



3
17
Jan 2
2025 was about learning and refining.
This year, we BUILD.
The process is in motion.
What comes next will speak for itself.
#NewYear2026
#DesignThinking
#ProductDesign
#CreativeIndustry
#BrandDesign
#Innovation
#CreativeLeadership
#SpectreHub
#StillSPECTRE
3
13
9 Dec 2025
Pushed the class deeper into the UX process today — from empathy to definition, into ideation, and now user flows.
The growth is showing. Step by step, designers are emerging. 🚀
#ProductDesign #UXDesign #DesignClass #StillSPECTRE


4
28
26 Nov 2025
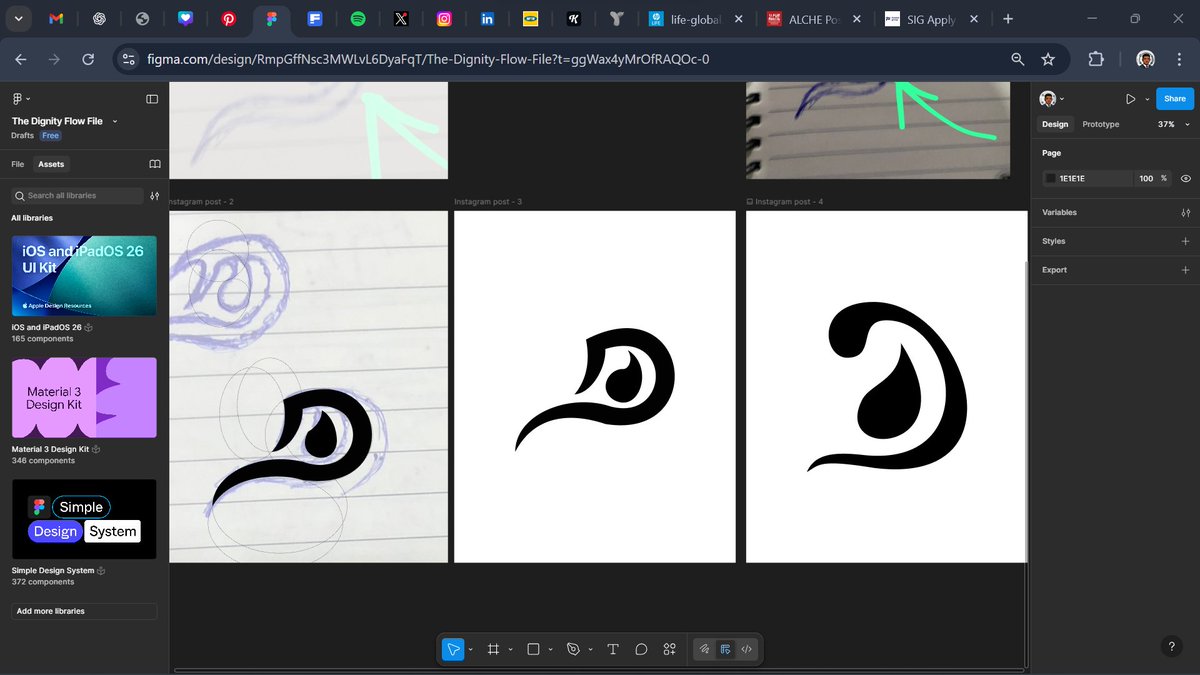
Just wrapped the visual identity for The Dignity Flow Project — a menstrual health initiative empowering young girls with education, essentials, and dignity. 🌸✨
#MenstrualEquity #DesignForGood #VisualIdentityDesign #PeriodPoverty #StillSPECTRE

2
19
18 Nov 2025
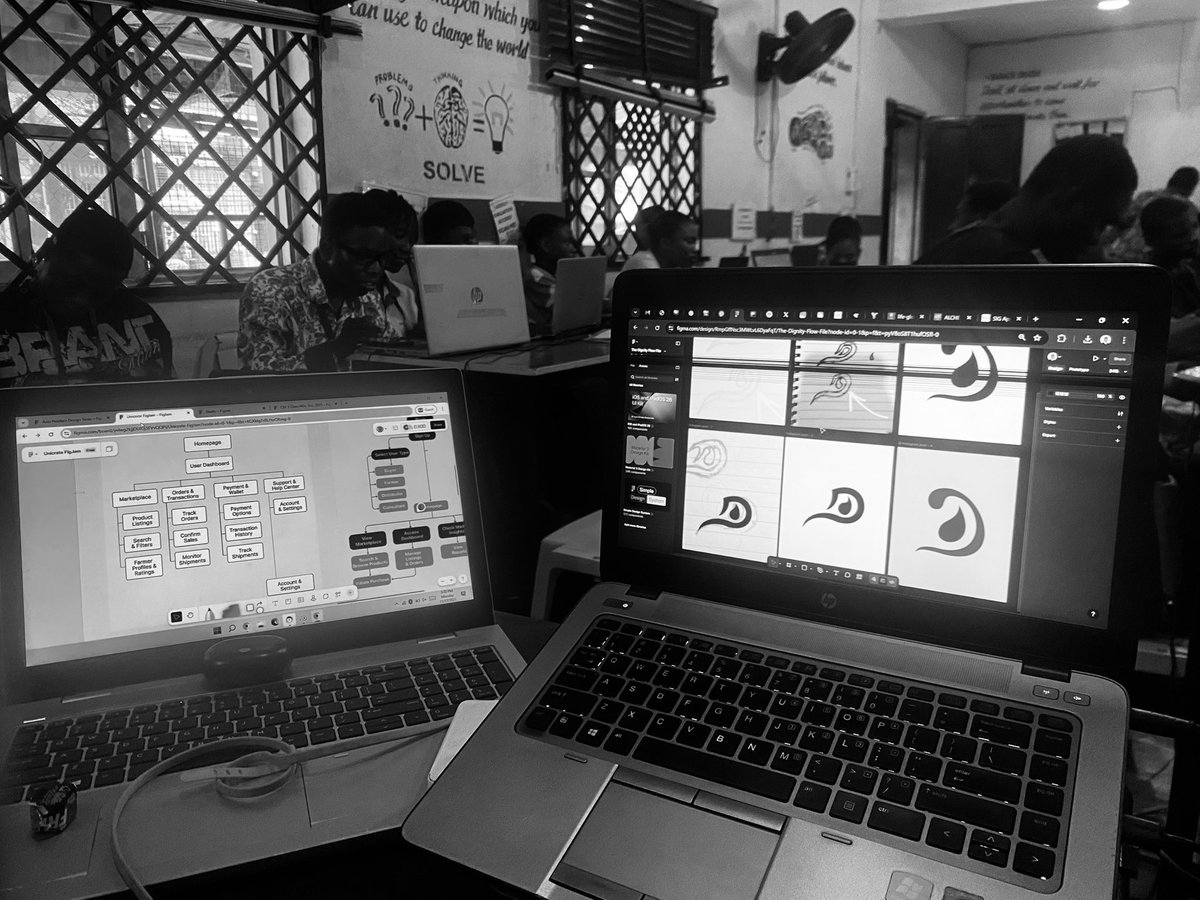
Balancing teaching my product design class with handling personal gigs isn’t easy — impact is the goal, but the business still has to run.
One class at a time, one project at a time. We move. 🚀
#StillSPECTRE

4
21
17 Nov 2025
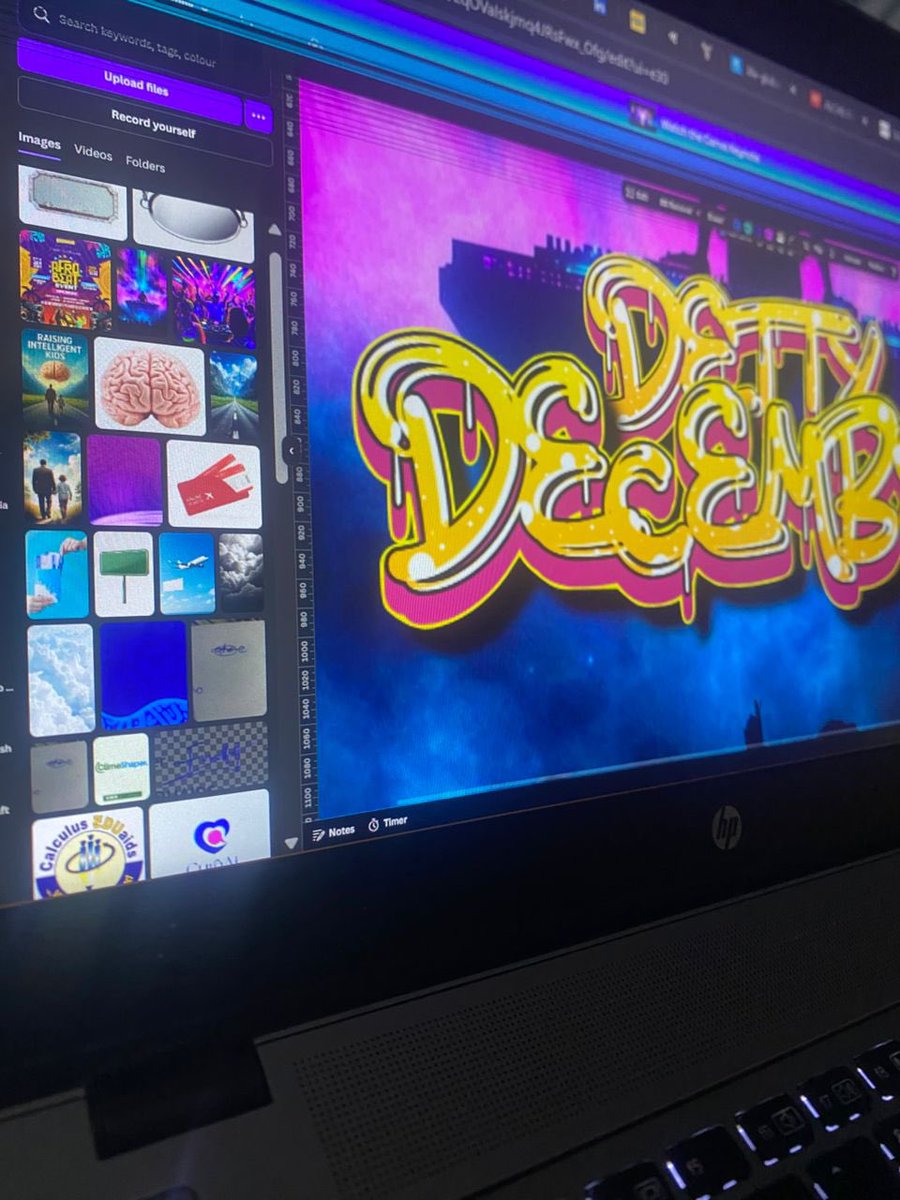
Detty December just got louder — get ready to rave with Spextre. Lights, vibes, and energy loading. 🔥💜🎧✨⚡️
#DettyDecember #Spextre #RaveSeason #DecemberVibes #PartyMode #LitVibes #NightLifeNG #TurnUpLagos #GoodVibesOnly #EnergyLoading #StillSPECTRE
2
42
17 Nov 2025
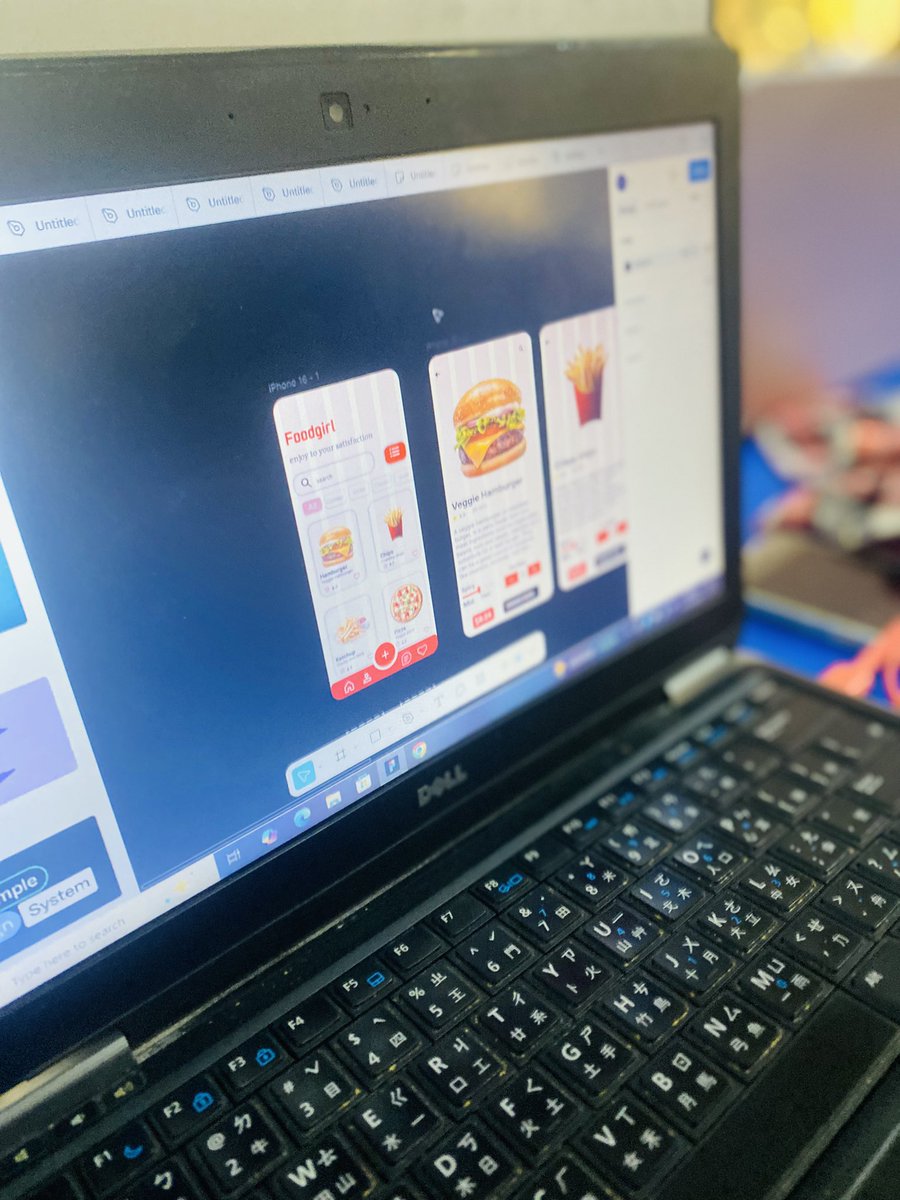
Week 1 of my Product Design class:
Most students couldn’t relate to the design terms yet, so we kept it simple.
We recreated a basic burger UI from Pinterest and used it to break down alignment, spacing, hierarchy & other design principles.
#StillSPECTRE #ProductDesign


3
77
12 Nov 2025
The Teacher I Never Planned to Be
In primary school, no one raised their hand when asked who wanted to be a teacher — not even me.
Now, teaching is one of my greatest strengths.
Funny how purpose finds us even when we run from it.
#TeachingJourney #ImpactOverEverything


4
16
16 Oct 2025
This image was entirely built from a JSON prompt I wrote from scratch 👇
Structured creativity is the future of design.
#AIDesign #JSONPrompt #DesignInnovation #CreativeTechnology #SpectreHub #StillSpectre #AIArt #DesignEcosystem
16 Oct 2025

The Reference ................The Design
Just generated this using a custom JSON prompt 💡
Structured creativity AI precision = 🔥 results.
Defined every detail — scene, outfit, mood & lighting.
Welcome to Spectre Studios 👊🏽
#AIDesign #JSONPrompt #StillSPECTRE #AIArt

2
49
16 Oct 2025
The Reference ................The Design
Just generated this using a custom JSON prompt 💡
Structured creativity AI precision = 🔥 results.
Defined every detail — scene, outfit, mood & lighting.
Welcome to Spectre Studios 👊🏽
#AIDesign #JSONPrompt #StillSPECTRE #AIArt


3
112
12 Oct 2025
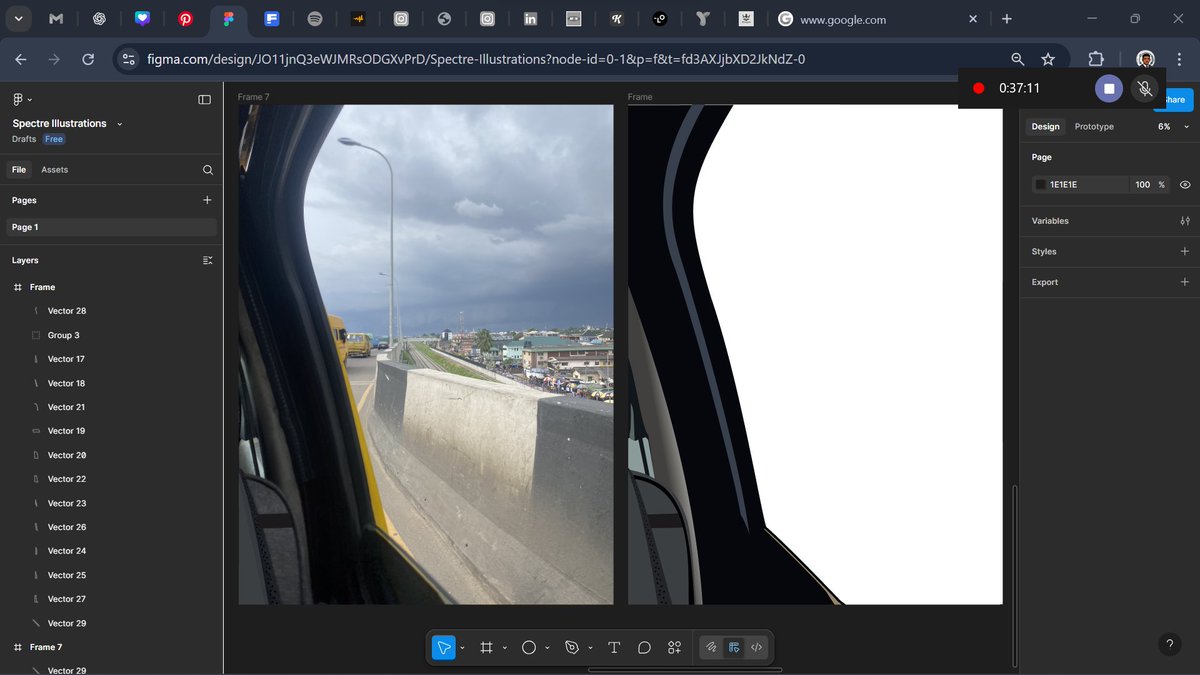
Stuck in Lagos traffic — but this time, I turned the moment into art.
New illustration loading... 🚍✨
#LagosLife #Illustration #ArtInMotion #CreativeProcess #StillSpectre

4
50
SpectreHub retweeted

12 Oct 2025
The reference The illustration




20
31
514
23,250
12 Oct 2025
Coming Soon!!!!
Stuck in Lagos traffic — but this time, I turned the moment into art.
New illustration loading... 🚍✨
#LagosLife #Illustration #ArtInMotion #CreativeProcess #StillSpectre
12 Oct 2025

Third attempt at illustration on pixelLab
⭐
The illustration The reference


1
3
127
12 Oct 2025
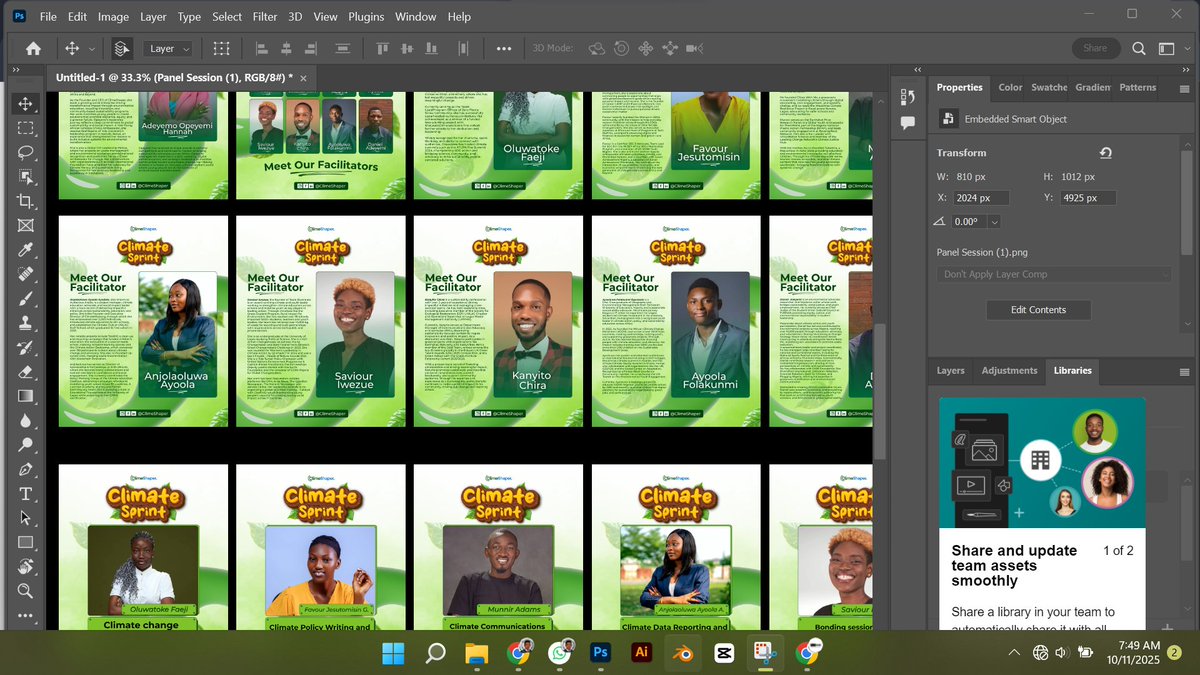
Last week, I worked on the Climate Sprint Workshop project to show how design can do more than look good — it can educate, inspire, and drive real climate action. 🌿
#ClimateAction #Sustainability #EcoDesign #DesignForImpact #CreativeChange #StillSpectre
1
2
25
3 Oct 2025
pin.it/3ja12ZGQZ A raw glimpse into everyday urban life — weathered apartment blocks, water tanks, tangled power lines, and a lone car parked on a dusty road. This scene captures the resilience, history, and unfiltered reality of inner-city living.
#UrbanLife #CityStories
1
3
36
1 Oct 2025
🇳🇬 Today, we celebrate 65 years of freedom, unity, and resilience.
May our great nation continue to rise in peace, progress, and prosperity.Happy Independence Day, Nigeria! 💚🤍💚
#NigeriaAt65 #HappyIndependenceDay #ProudlyNigerian #PeaceAndProgress #StrongerTogetherWould
4
25
24 Sep 2025
Beyond Ordinary - Day 02,
Creativity is the mountain we stand before, vision is the climb that drives us upward, and imagination is the force that carries us beyond ordinary.”
#photoshop #DesignInspiration #Imagination #PhotoManipulation #DigitalArt #StillSPECTRE

1
22
18 Sep 2025
Taking scattered pieces and making something bold — that’s the magic. This isn’t just about the design; it’s about the process and vision.
@Nike JUST DO IT ✅
#BeyondOrdinary #DesignLife #StillSPECTRE

1
23