
Building AI Infrastructure with AI; fast kernels go brrr
Joined September 2025
- Tweets 21
- Following 4
- Followers 1,918
- Likes 20
10 Photos and videos
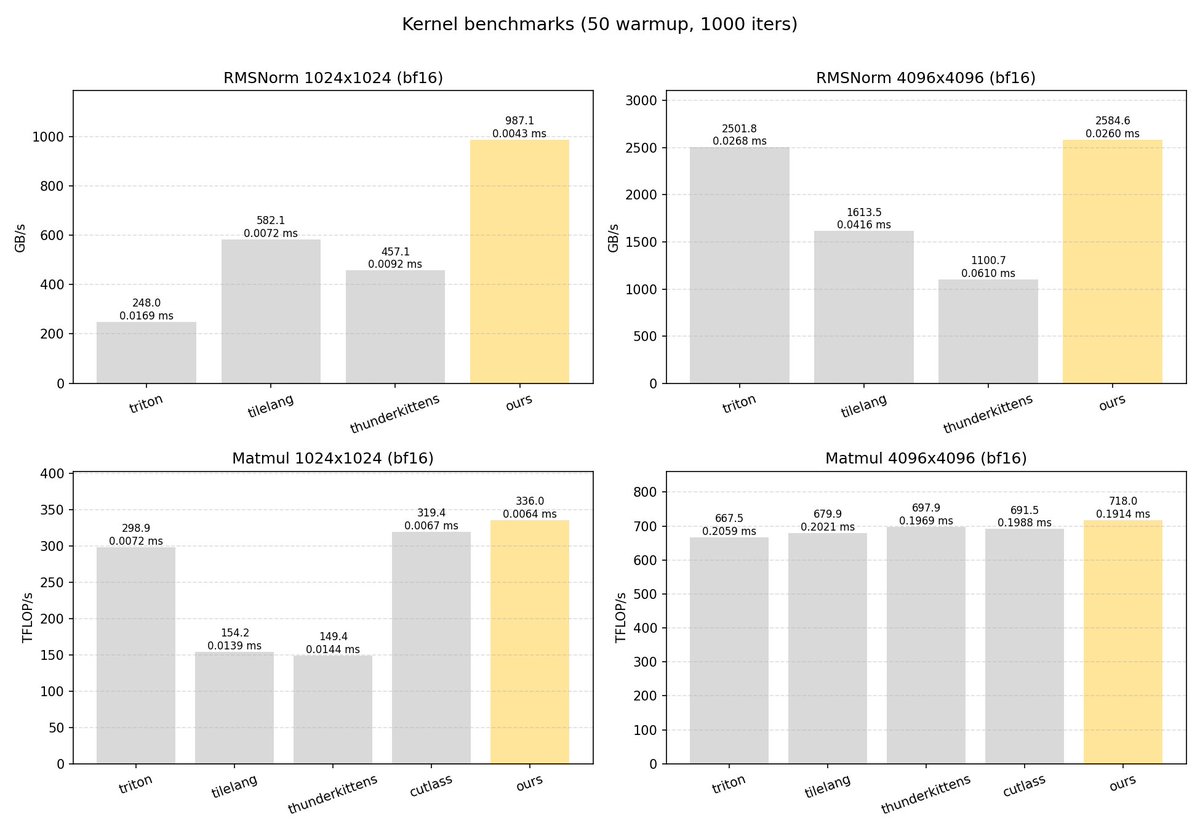
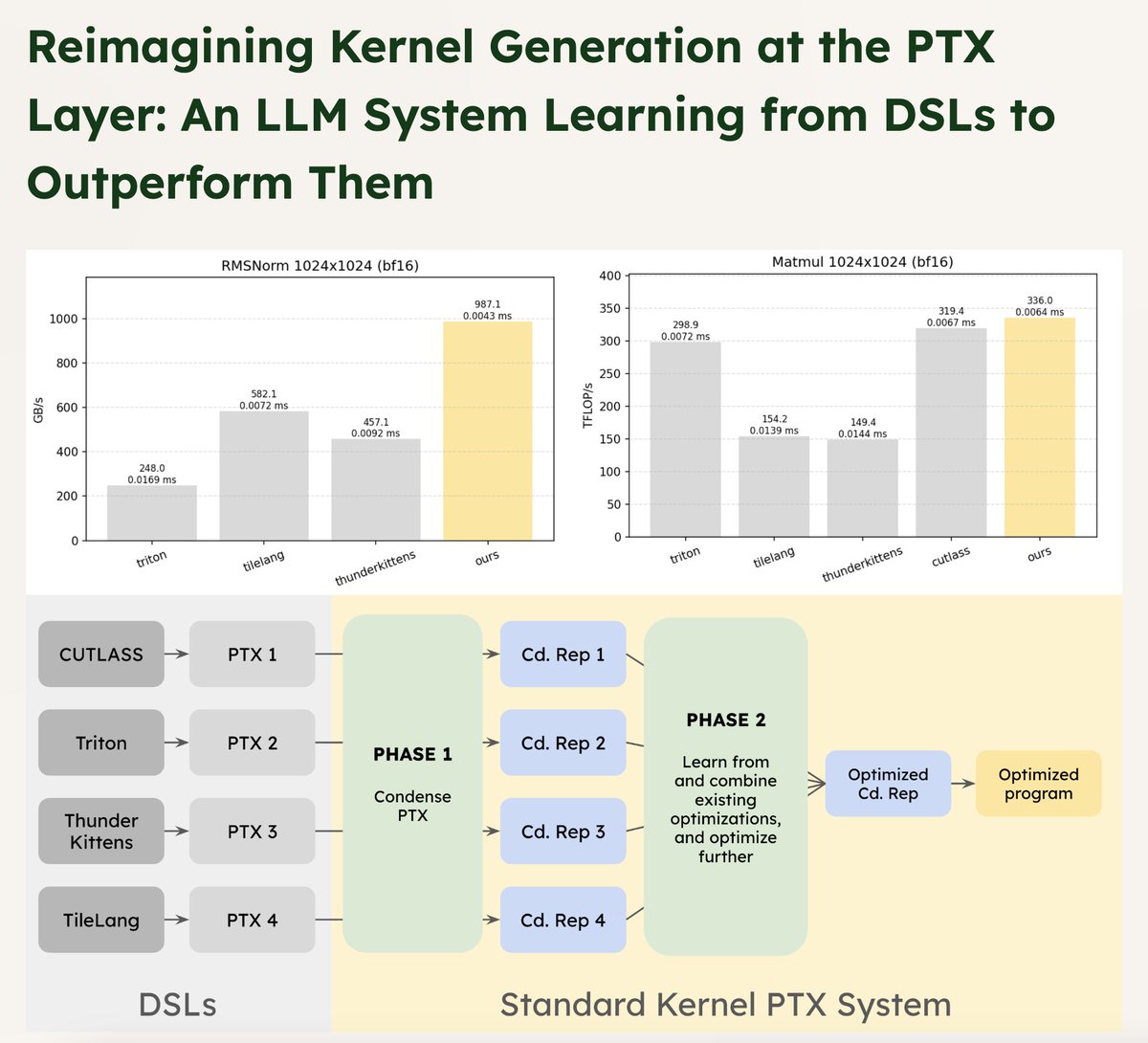



We built a system combining program analysis and LLMs to transform and optimize PTX. By operating at this shared layer across DSLs (e.g. Triton, TileLang, ThunderKittens, CUTLASS), our system learns the best ideas from each and generates kernels that outperform all of them (1/5)
5
31
256
23,049
One exciting application: a universal optimization layer across DSLs. High-level DSLs (Triton, CUTLASS, TileLang, ThunderKittens) are powerful but opaque, as they don’t reveal why one outperforms another. By working at the shared PTX layer, we can compare, learn, and compose their best implementations into kernels that outperform them all. (4/5)
1
14
1,662
Full post at standardkernel.com/blog/reim… (5/5)
2
18
1,453
Standard Kernel Co. retweeted

Mar 20
We have a utilization problem.
GPUs are running <30% capacity.
@Standard_Kernel (@anneouyang @ChrisRinard ) unlocks up to 4x performance.
Why we invested: jumpcap.com/insights/why-we-…

4
17
2,215
Standard Kernel Co. retweeted
Mar 16
AI progress increasingly depends on how efficiently workloads run on hardware.
@Standard_Kernel is tackling this challenge at the kernel level, unlocking more performance from modern GPUs.
We're proud to lead their seed with @generalcatalyst, @CoreWeave, @felicis, & @ericsson

1
11
1,654
Standard Kernel Co. retweeted

Mar 11
It’s rare to find founders so perfectly and uniquely suited to solve a problem, let alone a problem of this magnitude and importance. Proud to lead @Standard_Kernel’s seed round.
Mar 11

Excited to share @Standard_Kernel's seed round and some reflections on what we’ve learned about kernel generation and what we believe is next. Grateful to our amazing team, supporters, and the broader community pushing this space forward.

1
1
10
3,468
Standard Kernel Co. retweeted

Mar 11
Anne is killing it. Here's my quote from the press release
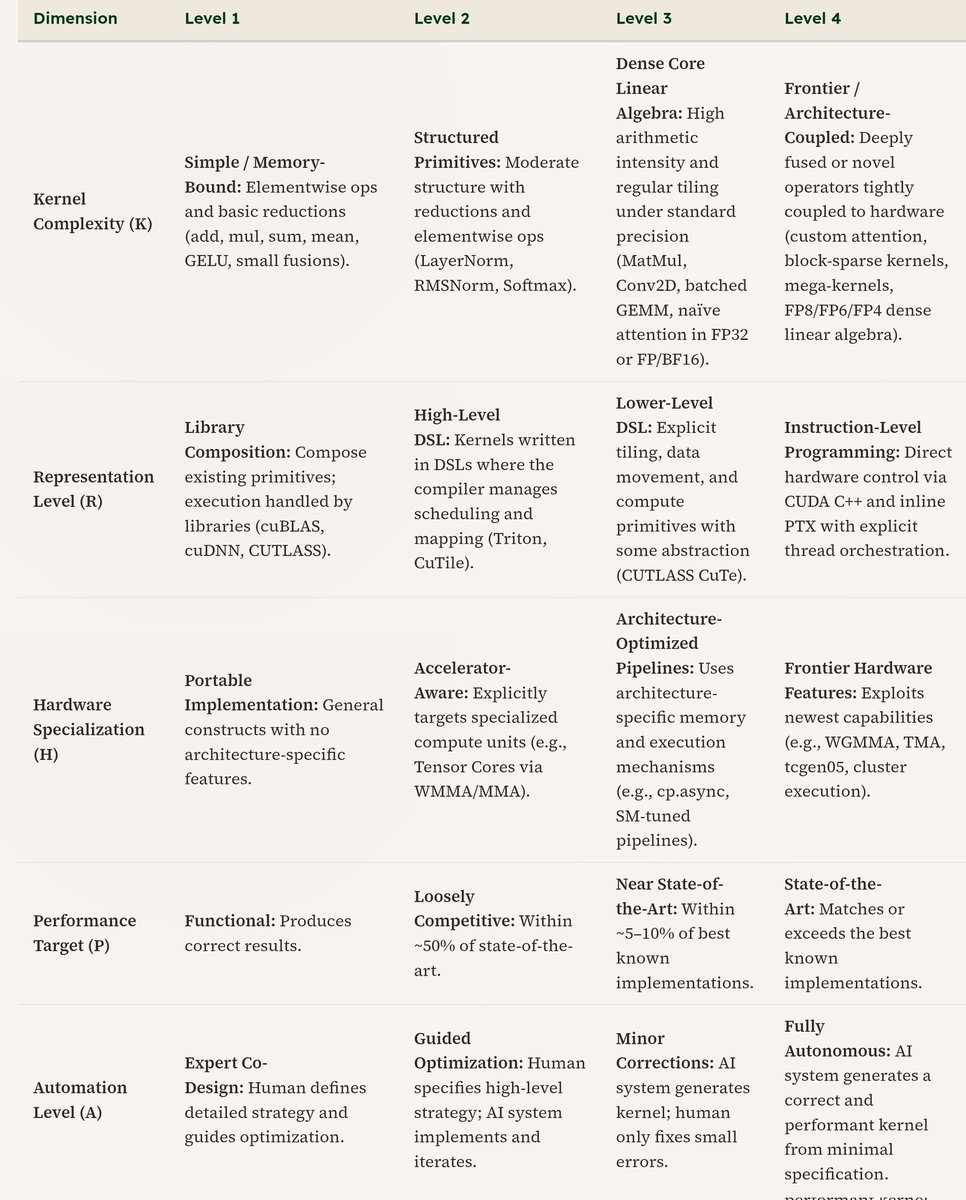
Kernel generation is key for improving performance and efficiency of AI hardware. As fleet sizes for users of AI hardware get larger, and more hardware diversity is introduced, Standard Kernel becomes key to deployment.”
Mar 11
Excited to share @Standard_Kernel's seed round and some reflections on what we’ve learned about kernel generation and what we believe is next. Grateful to our amazing team, supporters, and the broader community pushing this space forward.
3
18
289
60,848
Standard Kernel Co. retweeted

Mar 11
Excited to share @Standard_Kernel's seed round and some reflections on what we’ve learned about kernel generation and what we believe is next. Grateful to our amazing team, supporters, and the broader community pushing this space forward.
48
45
518
134,929
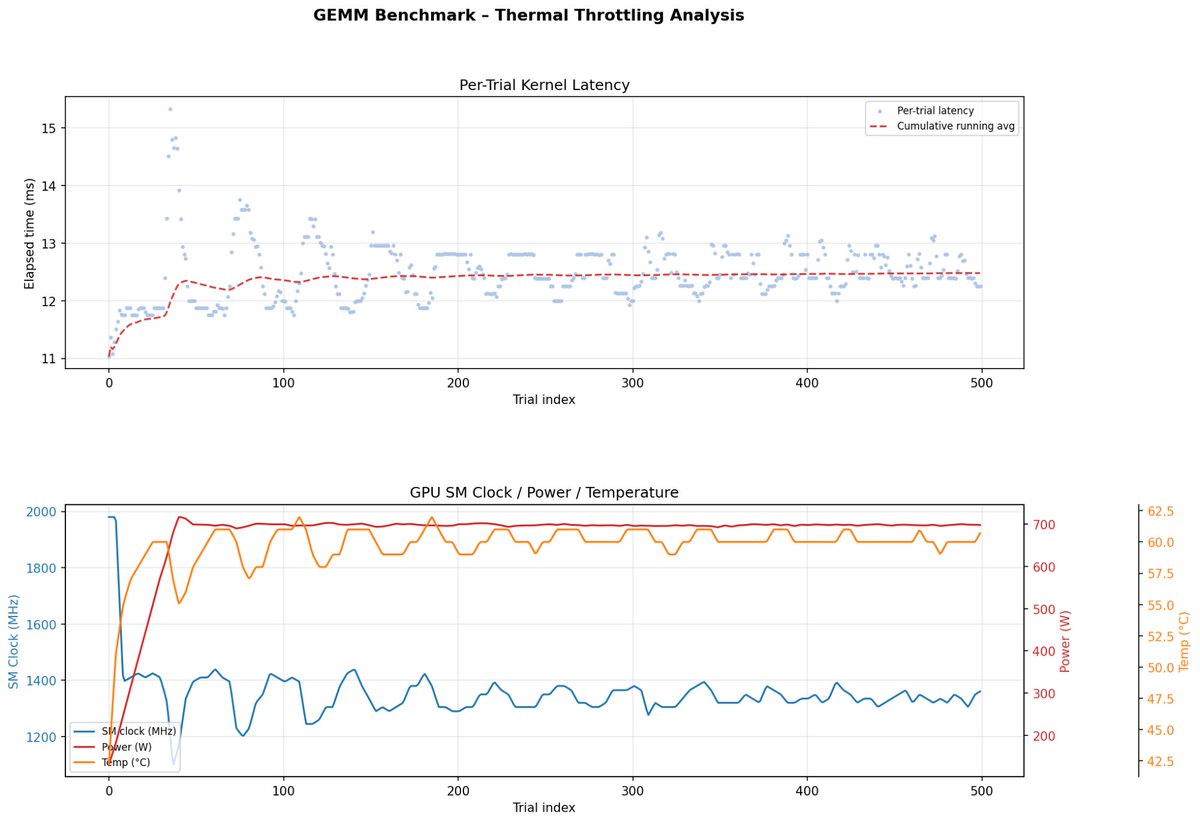
GPU timing is deceptively hard. Power limits, thermal state, clock behavior, caching, and measurement method all affect results in subtle ways. We explored sources of timing variation to obtain more reliable results for kernel benchmarking. (1/9)
5
19
136
33,504
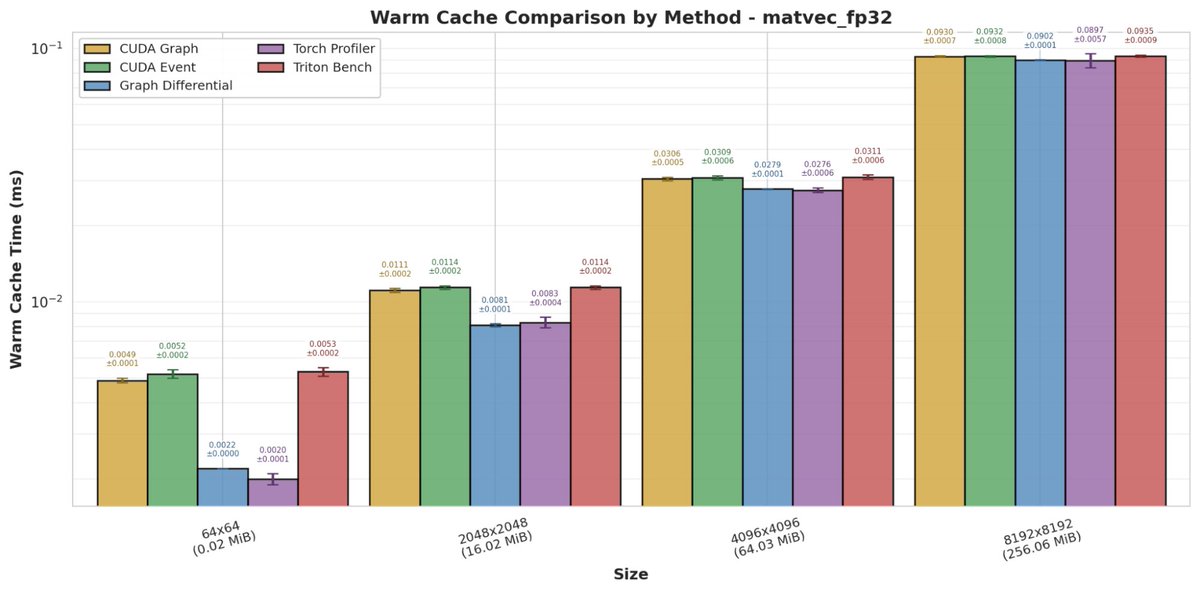
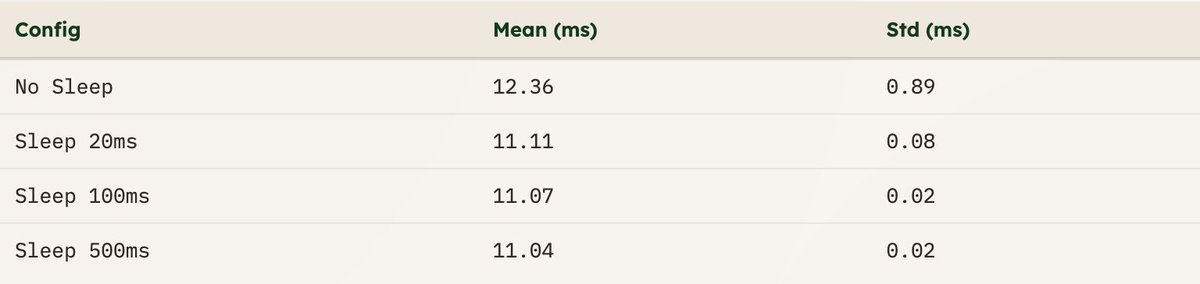
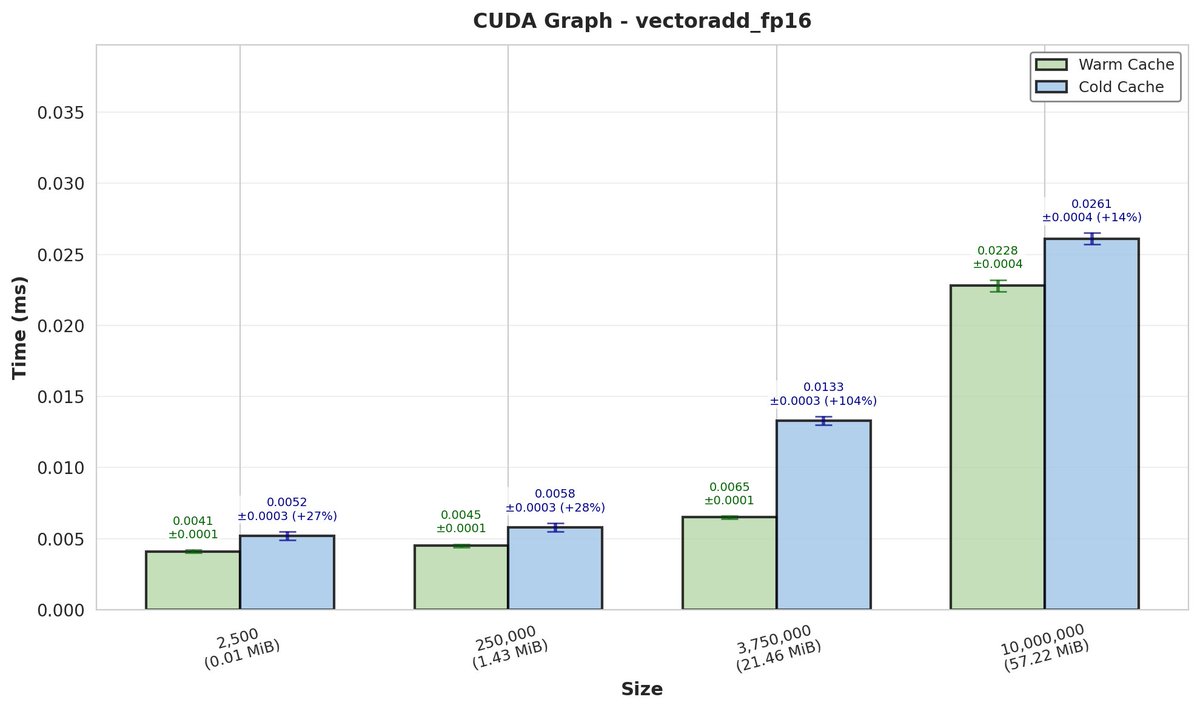
Warm caches can make GPU kernels appear much faster, and sensitivity to cold vs. warm cache varies by workload. Be explicit about which condition you measure, as the appropriate choice depends on the behavior you want to evaluate. (6/9)
1
1
9
1,444
The choice of timing method (CUDA events, CUDA graphs, Nsight Compute, PyTorch profiler, etc.) can result in different measured GPU performance, and the effect depends on the workload. For microsecond-scale kernels, true execution time is often indistinguishable from measurement overhead and system variance. (7/9)
2
589
Standard Kernel Co. retweeted
Feb 24


GPU timing is deceptively hard. Power limits, thermal state, clock behavior, caching, and measurement method all affect results in subtle ways. We explored sources of timing variation to obtain more reliable results for kernel benchmarking. (1/9)
6
6
149
19,563
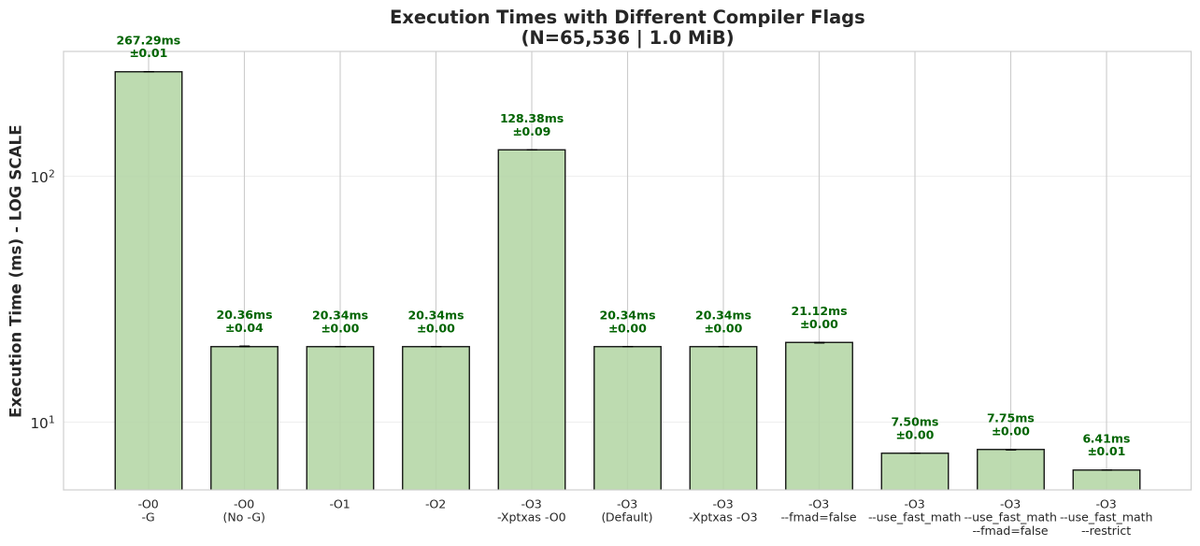
Compilation flags can change GPU performance on the same kernel hardware. Sensitivity varies by workload, so uncontrolled flags can look like real algorithmic gains when they're just compiler effects. (8/9)
1
1
10
1,133
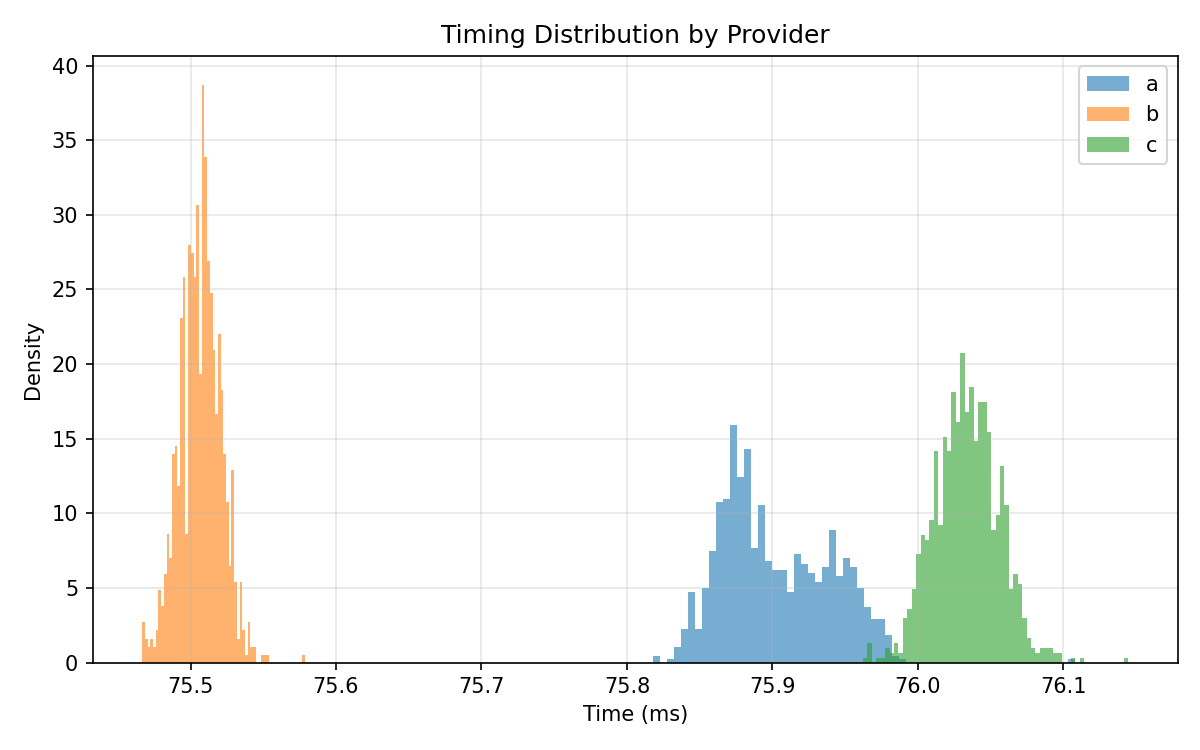
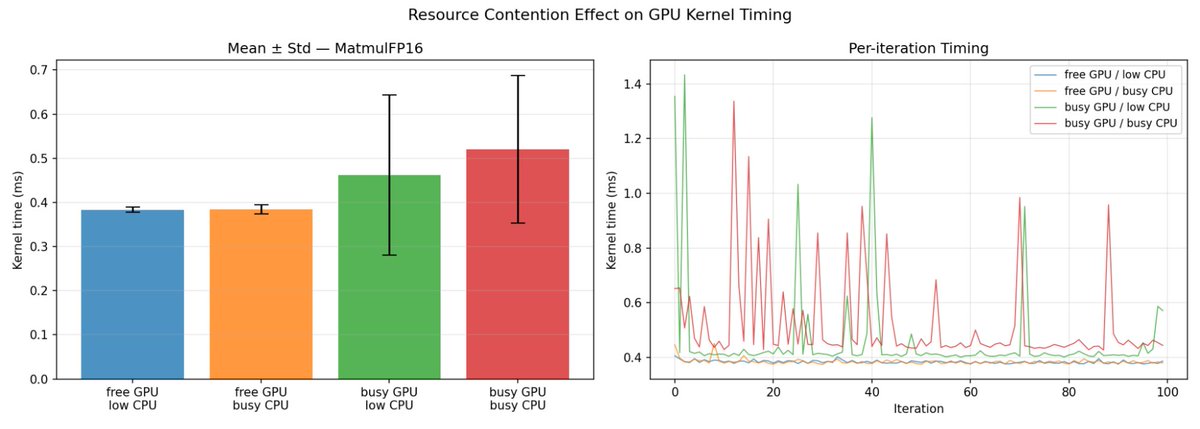
Getting identical hardware from cloud providers is not guaranteed. Across three cloud providers all listing “A100 80GB,” we received different variants with differing clock limits, power caps, and driver environments. When benchmarking an identical GEMM, the runtime distributions formed distinct clusters for each provider. (9/9)
2
14
1,151