
Joined March 2016
- Tweets 2,552
- Following 3,677
- Followers 7,420
- Likes 6,281
452 Photos and videos













Pinned Tweet

I'm extremely excited to be on the organizing committee this year for my favorite workshop ever!
Submissions (up to 8 pages) are due April 24! Co-submission with ICML and NeurIPS is encouraged!
taigr-workshop.com/

🚨📢Announcing the second Technical AI Governance Research (TAIGR) workshop @icmlconf. Accepting submissions (up to 8 pages) until April 24 on technical topics in AI governance! #icml2026

3
6
69
15,519
Cas (Stephen Casper) retweeted

Jun 13
We need better expertise. That's why a powered up CAISI (or even a National AI Laboratory as called for by the @scientistsorg) would have saved a lot of pain.


2
5
58
4,501
Now that I have your attention by posting this spinning point cloud GIF, I'd like to propose a litmus test for AI mechanistic interpretability research. You might call it the "interp hammer" test.
If the things achieved by a mechanistic interpretability research project had been accomplished by an undergraduate who was (1) just prompting a model or (2) doing exploratory data analysis, would it impress you? If not, the project might not have accomplished much.
10
3
118
6,826
Glad to join Doom Debates with Liron! And yes -- if I could press a button and stop research on "superalignment", "scalable alignment", and "scalable oversight" research, I would. (I might even do it for mechinterp too.)
youtube.com/watch?v=0XVmtazg…
2
2
44
11,687
Cas (Stephen Casper) retweeted
My reasoning behind wanting to stop superalignment research:
- Principal-agent alignment is neither necessary nor sufficient for safety and ecosystemic health. I think the vast majority of our problems will come from scenarios involving systemic harms, negligence, or malice instead of situations in which someone benevolent was exercising what would be considered “best technical practices” at the time but non-foreseeably loses control of their AI.
- I think that current alignment, control, and containment strategies are actually pretty good and there is a big incentive for ML people to underemphasize the effectiveness of these tools to justify their existence. If you’re willing to pay a safety tax and are not “move fast and break things,” existing best practices can make systems pretty robustly safe.
- Superalignment is pretty safety washed and is touted by big companies to justify their ambitions to build the superintelligence.
- Solving superalignment would be a huge boon and would consolidate enormous power in big tech. This is itself a risk factor.
- Jevons paradox — it’s easy to see how lowering the perceived risk of building superintelligence would make more companies choose to try.
6
4
37
3,076
Wonderful talking with crux artist and all-around smart guy, @liron. Thanks for having me!
Check out the debate for discussions on doom, disinformation, disempowerment, deepfakes, and demagogues!
Jun 10

NEW: Harvard Professor @StephenLCasper (a.k.a. Cas), a computer scientist working on AI safeguards and governance research, worries that alignment efforts will backfire! 🤦♂️
Today on Doom Debates, we agree that slowing down AI development would make the world safer… but you know Cas's position is unique when he says he’d prefer to have *less* research on AI alignment!
We cover:
⬜ Cas's research focus
⬜ What's Your P(Doom)?™
⬜ How high is the intelligence ceiling?
⬜ Idiocracy-inspired gradual disempowerment
⬜ Poor governance led to sycophancy, MechaHitler, nudification
⬜ Case study: Safeguards on DALL-E 2 vs. Stable Diffusion
⬜ The #PauseAI treaty option
⬜ Why Cas opposes alignment research
This episode is a substantive AI doom debate with a brilliant guest. Highly recommended! 👇
3
3
46
4,513
Here's my PhD thesis defense from 5 weeks ago. This link exists, so I thought I might as well share.
drive.google.com/file/d/1Zs9…
2
46
3,390
There are really interesting academic questions emerging around AI and epistemic risks. I only fear that, by the time we reach consensus, we will be too dumb to understand it.
Humanity's ability to know, reason, judge, and act well is the foundation of science, democracy, crisis response, & management of AI itself.
AI poses serious risks to that foundation.
New paper on epistemic risks by 30 experts calls for attention to this. Link in thread.

1
5
34
4,055
Anthropic and OpenAI are publicly pointing out how having the option to slow down AI would offer a potentially critical form of optionality in the future. The correct response for any policymaker should be "Damn, this is serious. How can I help build that capacity?"

1
19
108
3,982
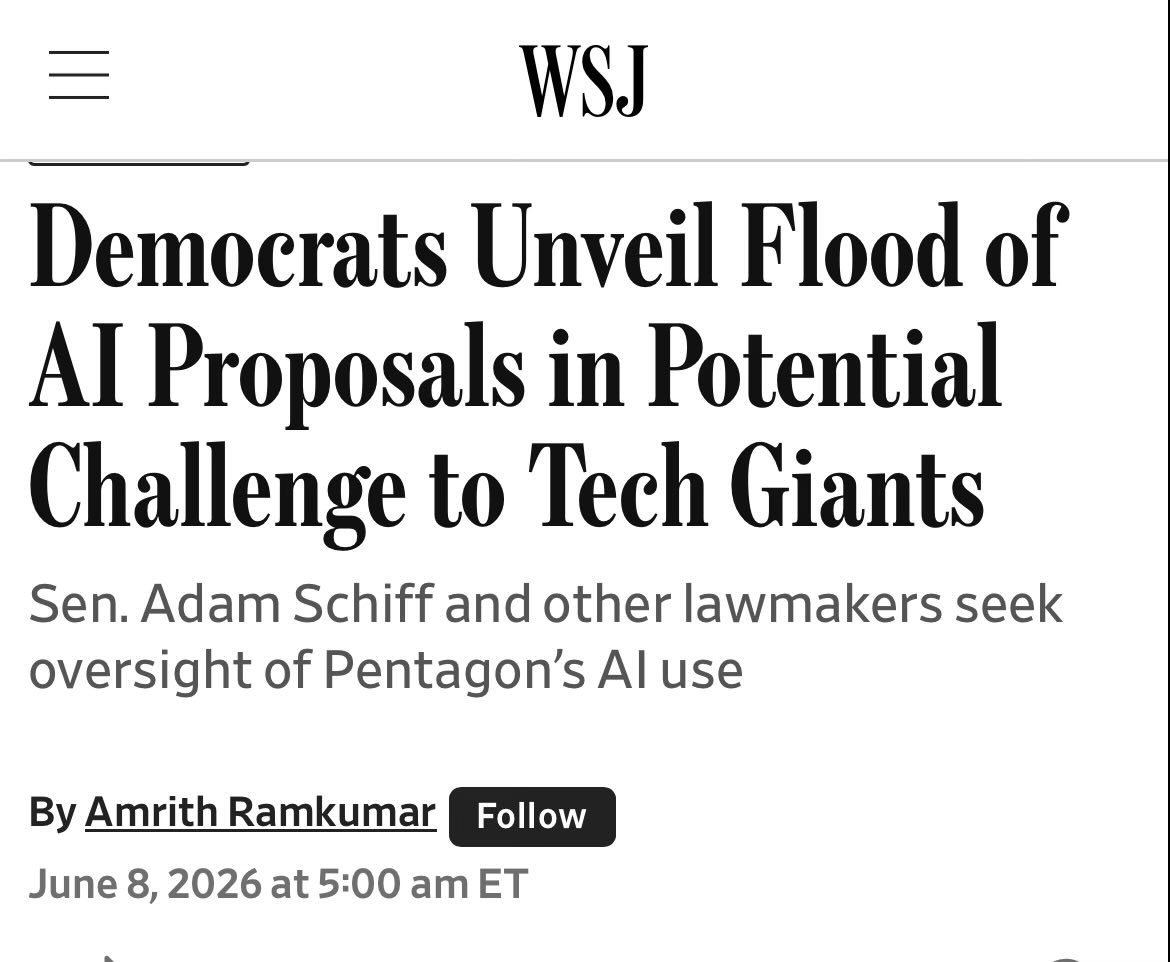
Cas (Stephen Casper) retweeted

Jun 8
I doubt Democrats will produce good policy re: AI, but Republicans have allowed them to capitalize on public concern about the power and influence of Big Tech by failing to adopt a sensible framework that will protect the public from the very real downsides of the technology.
A policy that says transhumanists in Silicon Valley should be able to do what they want is not an acceptable approach, nor is it a politically viable approach.
126
245
1,051
84,226
According to the MIT Libraries' database of theses (dating back to the 1800s), my thesis was only the 2nd in the institute's history to contain the word "shit."
6
3
163
14,172
Cas (Stephen Casper) retweeted

Jun 4
As increasingly capable AI systems are deployed, humans, institutions, and other AI systems adapt in response — i.e. the world pushes back.
So is capability still the central safety challenge for AI?
We think not. We believe the harder challenge is coexistence.
The current AI research paradigm treats the world as a stationary source of feedback, what we refer to as the solipsistic approach to AI design. This raises serious risks for coexistence.
In our new #ICML2026 paper, we argue that superintelligence — an extremely capable task solver, built through such a solipsistic approach — is unlikely to be cooperative. 🧵

1
6
35
14,375
Cas (Stephen Casper) retweeted

Jun 5
Our highest and most urgent national priority should be AI safeguards. The risks of AI weapons, pathogens, mass unemployment, surveillance, and even extinction must not continue to be largely ignored.

Anthropic Urges Global Pause in AI Development, Flags ‘Self-Improvement’ Risk on.wsj.com/4o5IBpe
482
781
4,442
1,026,542
Sometimes I run into old papers or books that I can't believe weren't written about AI today.



2
37
2,349
Having worked in the space for a few years, I can definitively say that the most troublesome thing about working on open model safety has been the benchmarking. Glad tamper bench can help.
Jun 4

Open-weight LLMs ship with safety training that can be stripped in a few hundred fine-tuning steps. Can current defenses stop this?
We built and open-sourced TamperBench, the first unified framework for evaluating tamper resistance, and the answer is mostly no. 1/7

1
25
2,606
Cool project! Should experts expect to be well-calibrated? No. But that's not the point. Tomorrow, if climate scientists said that they expect at 10% chance of catastrophic warming or military analysts said that there was a 10% chance of a nuclear bomb dropping this year, the right reaction is to worry, not be a pedant.

📢 New paper: Prioritization of Risks from Artificial Intelligence: A Delphi Study of 272 International Experts
AI creates many risks, from discrimination, privacy loss, and fraud to more emerging concerns such as overreliance, dangerous capabilities being misused in weapons or cyberattacks, and AI systems pursuing unintended goals.
But which risks are most severe? Who is most vulnerable? And who is most responsible for addressing them?
To answer these questions, we conducted a three-round expert consultation with 272 AI experts.
💡 Four insights from our findings:
1️⃣ If things continue as they are over the next 5 years, experts assigned ≥10% probability of catastrophic outcomes (e.g., >1 million deaths or >$100 billion in losses) to 18 of 24 risks. Top concerns: cyberattacks and weapons, dangerous AI capabilities, competitive dynamics, power centralization, and disinformation and influence at scale.
2️⃣ Even assuming pragmatic mitigations, 5 risks remained above the 10% catastrophic threshold: dangerous AI capabilities, cyberattacks and weapons, environmental harm, inequality, and power centralization.
3️⃣ Vulnerability is broadly distributed, but responsibility is concentrated. Experts assigned the highest vulnerability to AI users and the general public, while assigning primary responsibility for mitigation to frontier AI developers, governments, regulators, and standards bodies.
4️⃣ Information, finance, and national security were rated the sectors most vulnerable to AI risks.
🔗How can you engage? See our (fancy) new webpage for our interactive summaries of the findings and preprint, and please share with anyone working on AI risk, governance, or policy.
airisk.mit.edu/priorities
This research is part of the MIT AI Risk Initiative (@MITAIRisk), which aims to help society understand, prioritize, and manage risks from AI. The initiative includes the MIT AI Risk Repository, a living database of more than 1,700 AI risks, the AI Incident Tracker, a collaboration with the Responsible AI Collaborative, which connects risks to over 1,400 incidents, and the MIT AI Governance Map, which analyzes risk coverage across more than 1,000 laws, standards, policies, and other governance documents curated by the Center for Security and Emerging Technology (CSET).
#AI #AIrisk #AISafety #AIGovernance #ResponsibleAI #RiskManagement

16
1,970
Dean Weinstein's leadership on AI and belief that it is today's most pressing governance challenge is one of the reasons why I am glad to join HKS and why I think it will be a unique source of academic leadership in AI governance.
hks.harvard.edu/faculty-rese…
3
1
22
1,579
Cas (Stephen Casper) retweeted

Jun 2
.@berniesanders is right: the future of humanity belongs in the hands of our workers, not the handful of AI oligarchs pursuing unlimited wealth and power at the expense of our job, our kids, our economy, our climate, and our democracy.
Here in NY, I delivered the strongest AI safety bill in the country. Now, I'm running for Congress to put Americans ahead of AI, and I look forward to partnering with Senator Sanders to get it done.

AI is built on humanity’s collective knowledge.
The wealth it generates must benefit humanity — not just Elon Musk, Sam Altman and other AI oligarchs.
That’s why I’ll be introducing the American AI Sovereign Wealth Fund Act — to give the public a direct ownership stake.

50
27
153
10,028
Cas (Stephen Casper) retweeted

I'll be introducing the American AI Sovereign Wealth Fund Act, a bill giving the public a direct stake to determine AI's future.
When a public resource generates wealth, the public should share in that wealth. x.com/i/broadcasts/1qxoNNPjL…
412
607
2,354
131,763
Just finished my PhD at @MITCSAIL. In July, I'll start as an assistant professor at the @Harvard @Kennedy_School. I have lots to learn and lots to do.
With others (some TBA 👀) at HKS, I'm looking forward to helping academia offer guidance for governing the next chapters of AI.



71
25
806
51,290
Cas (Stephen Casper) retweeted

May 29
New paper: We identify a new class of reward hacking caused by mitigations, which we call reward bias substitution. We prove no standard benchmark detects it, even with oracle access to the true reward. We find it active in GRPO, in SOTA reward models, and published methods.
1
5
36
4,953