
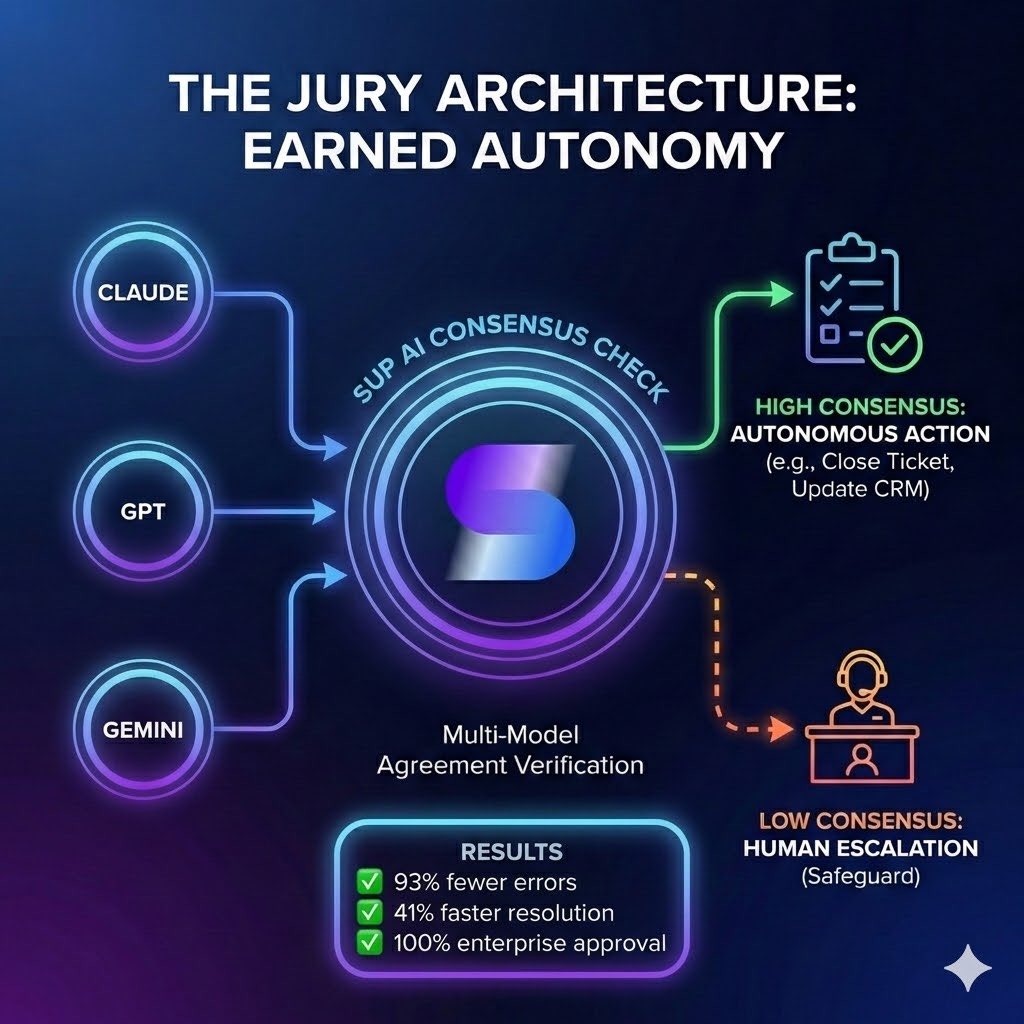
Sup AI: Multi-LLM Orchestration: Real-time synthesis, always cited verifiable sources, no hallucinations, persistent memory across 40 frontier models. Try Free
- Tweets 142
- Following 48
- Followers 26
- Likes 129
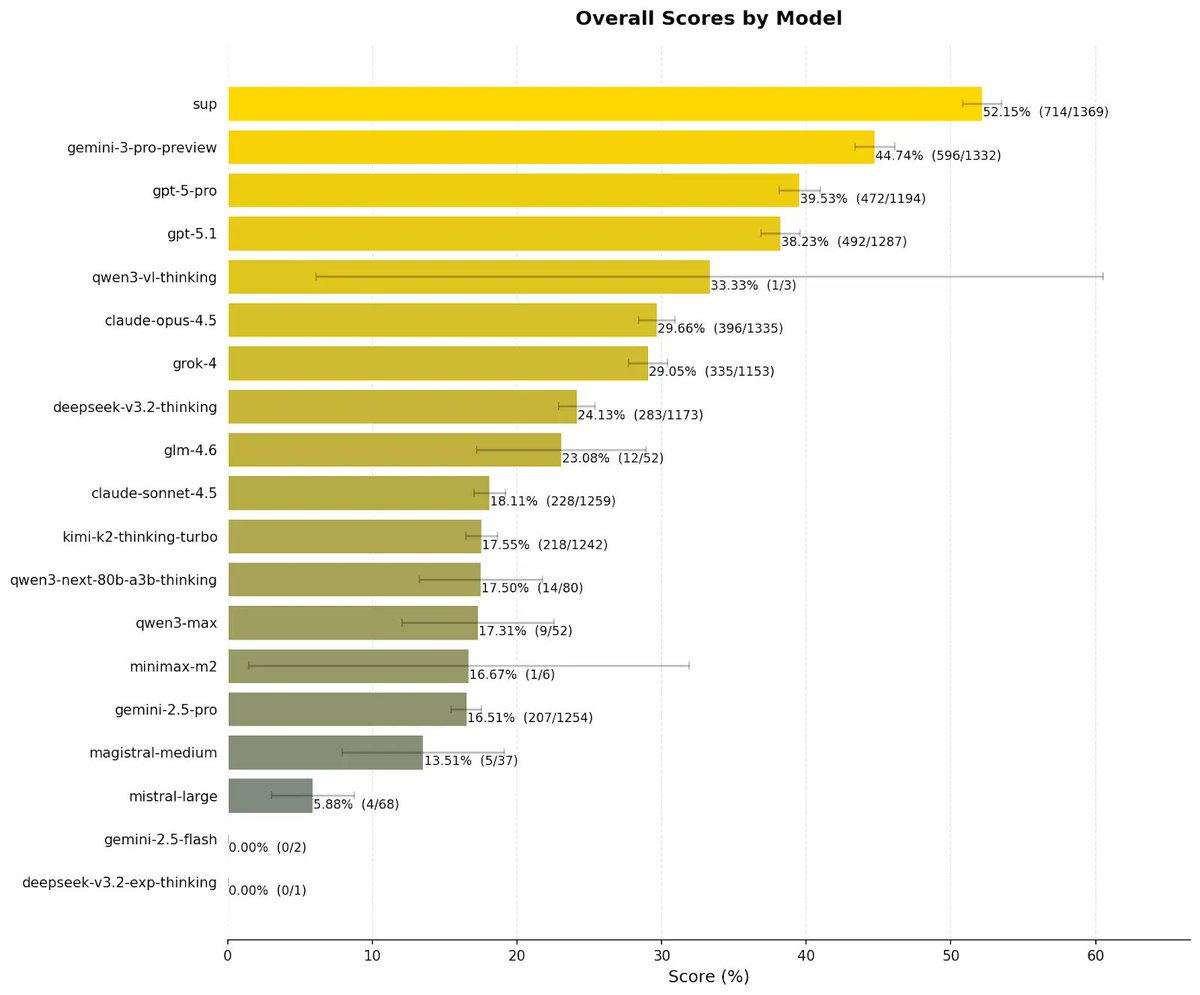



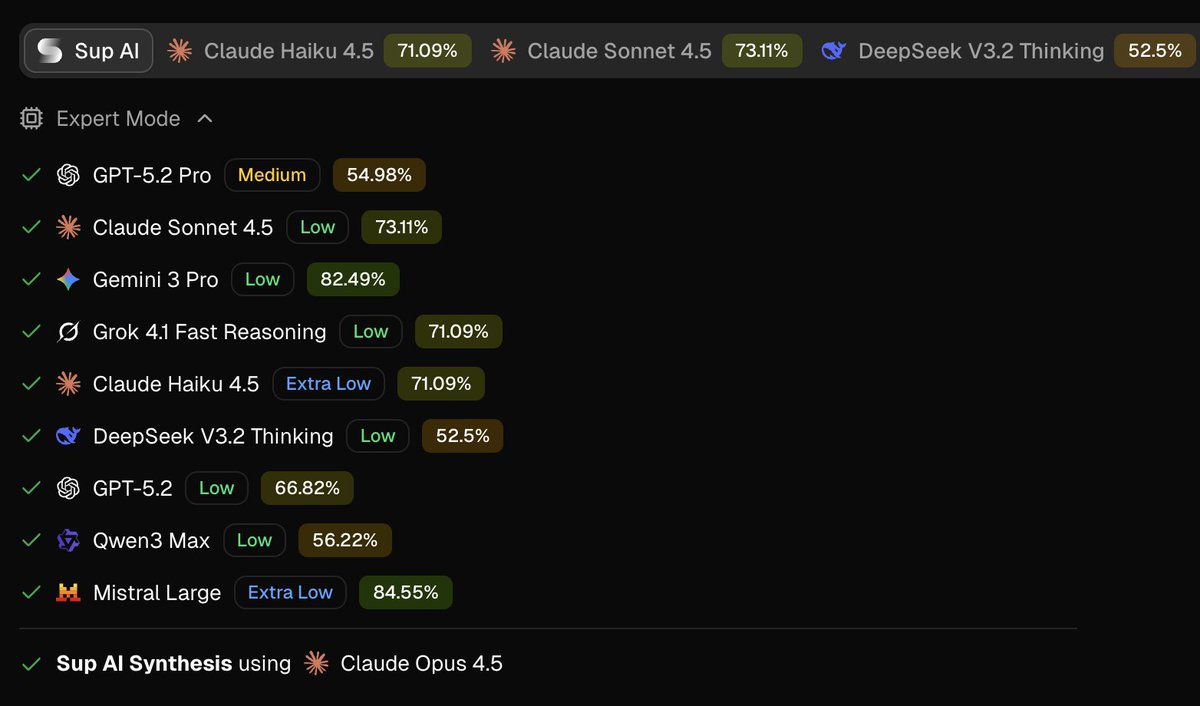





ALT A screenshot of the Sup AI "Expert Mode" dashboard showing a list of AI models. Each model is labeled with an effort level (Medium or Low) and a logprob percentage. The interface highlights 9 frontier models including Claude Sonnet 4.5 and GPT-5.2 Pro with high logprobs, while noting that the current synthesis is being performed using Claude Opus 4.5.



ALT Main Section: Expert Mode Below the navigation bar, a header reads "Expert Mode" with a small circuit-board icon and a downward arrow. Underneath is a vertical list of nine AI models. Each entry shows a green checkmark (indicating it's selected), the model's logo, its name, a colored priority tag, and a percentage score: GPT-5.2 Pro — Yellow "Medium" tag — 54.98% Claude Sonnet 4.5 — Green "Low" tag — 73.11% Gemini 3 Pro — Green "Low" tag — 82.49% Grok 4.1 Fast Reasoning — Green "Low" tag — 71.09% Claude Haiku 4.5 — Blue "Extra Low" tag — 71.09% DeepSeek V3.2 Thinking — Green "Low" tag — 52.5% GPT-5.2 — Green "Low" tag — 66.82% Qwen3 Max — Green "Low" tag — 56.22% Mistral Large — Blue "Extra Low" tag — 84.55% Footer A thin horizontal line separates the list from the footer. The footer displays a green checkmark followed by: "Sup AI Synthesis using Claude Opus 4.5." Visual Style Summary The interface uses a dark grey/black background with white and light grey text.
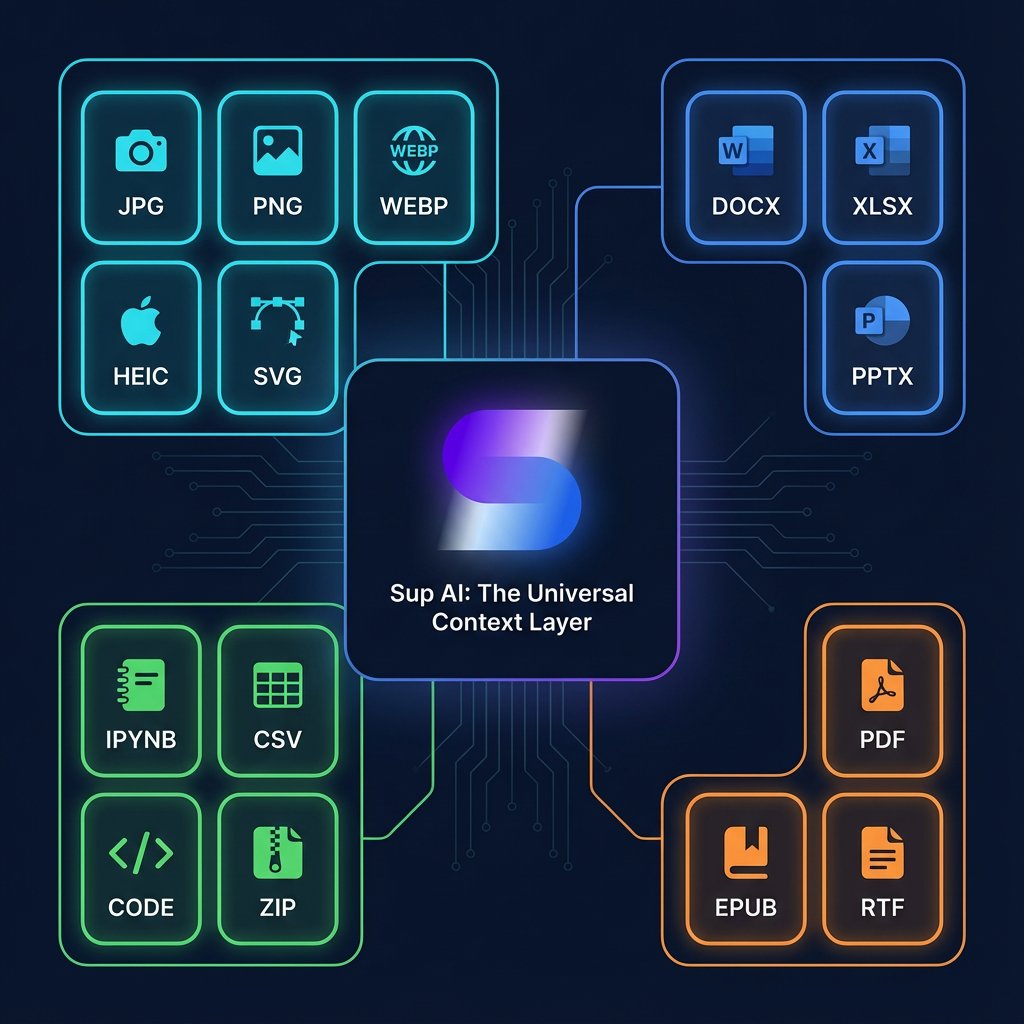
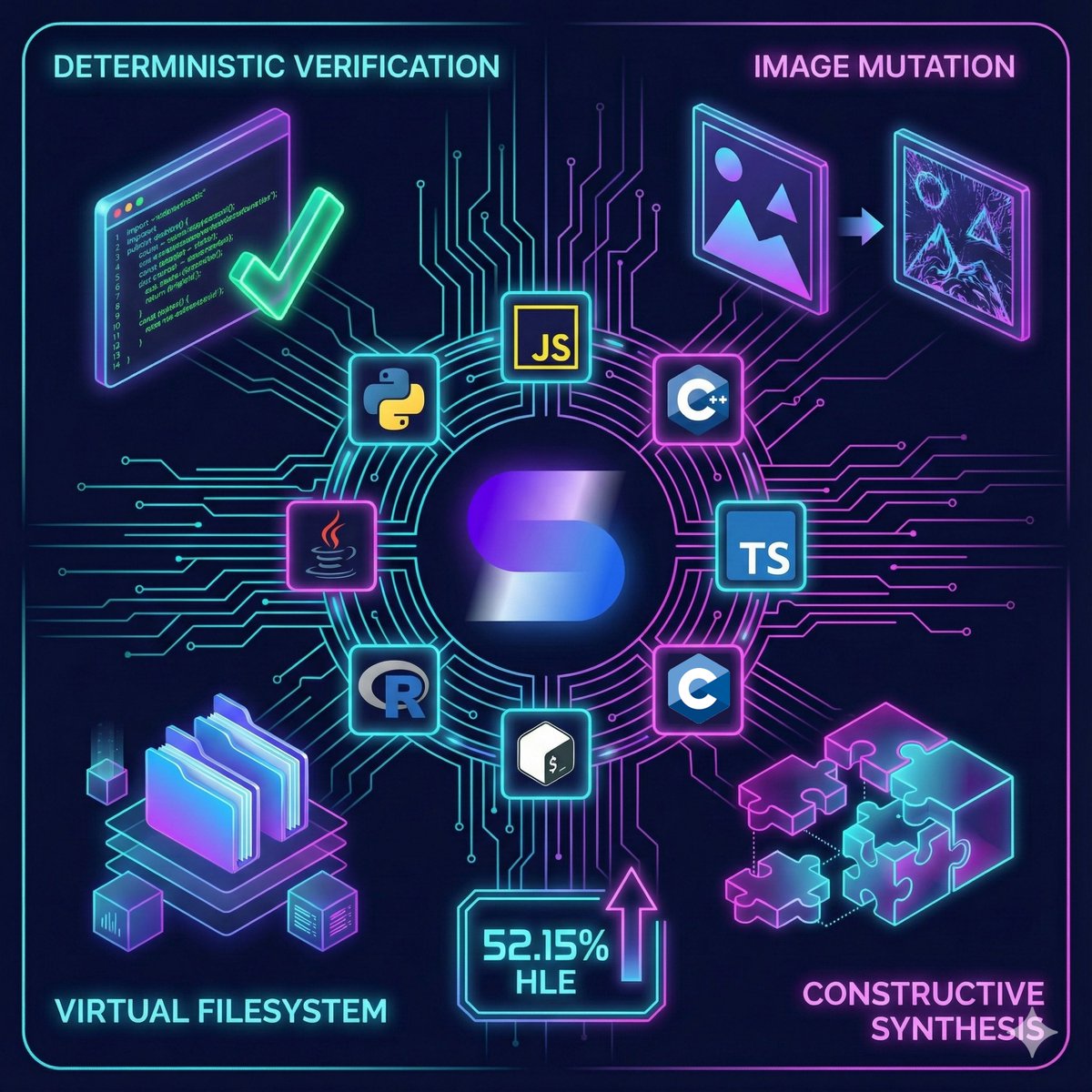
ALT Sup AI infographic showing supported file formats: Images (JPG, PNG, WEBP, HEIC, SVG), Office (DOCX, XLSX, PPTX), Dev (IPYNB, CSV, CODE, ZIP), and Docs (PDF, EPUB, RTF) connected to central Sup AI logo labeled "The Universal Context Layer" on dark navy background with neon circuit lines.