
Joined April 2023
- Tweets 27,387
- Following 1,227
- Followers 277,887
- Likes 75,991
5,846 Photos and videos













Pinned Tweet

Jun 8
News: I made a deal with my cofounder @rryssf on the God of Prompt brand.
He's taking over everything except this X account.
I, Alex, was the person behind this account the entire time, so the difference will be minimal.
In a few days I'll switch the handle to @alex_prompter.
I'm focusing on building a marketing agency now, but I'll never stop sharing prompt tips, tricks, and frameworks.
I don't want to share publicly anything about the dispute we had.
Some time needs to pass. It was emotionally huge for both sides to go through.
I wish @rryssf nothing but the best.
Thanks for sticking around.
8
5
63
19,234
The last 2 weeks in AI have been the most absurd stretch in tech history.
I can’t even keep up. And this is literally what I do for a living.
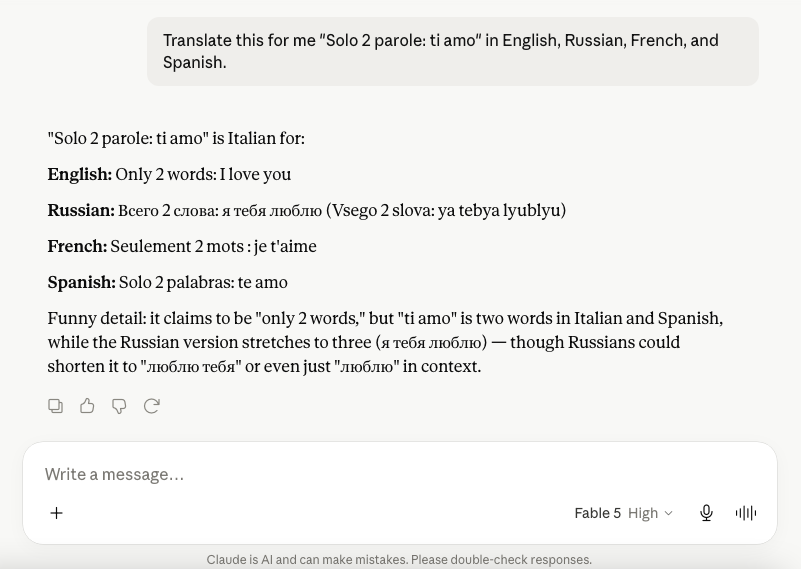
→ Anthropic launched Claude Fable 5, its most powerful model ever made public. State of the art on nearly every benchmark. Scored 10% higher than Opus 4.8.
→ Three days later the U.S. government ordered Anthropic to shut it down for everyone. Export control directive. National security. Gone.
→ A model used by millions on Monday was disabled by Friday night. First time in history a government has pulled a live frontier model.
→ Anthropic filed for IPO at a $965 billion valuation. $47 billion annualized revenue.
→ OpenAI filed its own confidential IPO paperwork with the SEC days later.
→ SpaceX went public yesterday. Largest IPO in history. $1.77 trillion valuation. Ticker: SPCX.
→ Elon Musk became the world’s first trillionaire. Worth more than the next four richest people combined.
→ Apple held Tim Cook’s final WWDC keynote. He’s stepping down as CEO in September.
→ Apple rebuilt Siri from the ground up. Powered by a custom 1.2 trillion parameter Gemini model. Licensed from Google at $1 billion per year.
→ iOS 27 lets users choose which AI chatbot runs their phone. Claude, Gemini, ChatGPT. You pick.
→ ChatGPT crossed 1 billion monthly users. Fastest app in history to hit that number.
→ Visa embedded its payment network directly inside ChatGPT. AI agents can now shop and complete transactions on your behalf.
→ Microsoft launched MAI models at Build 2026. First AI models built entirely in-house without OpenAI. Microsoft is building its own stack.
→ NVIDIA unveiled RTX Spark at Computex. 1 petaflop of AI performance on a laptop chip. 120 billion parameter models running locally. No cloud needed.
→ Anthropic published a paper called “When AI Builds Itself” warning AI systems may soon achieve recursive self-improvement. Then released their most powerful model 5 days later.
→ A 269-page federal AI bill dropped. The Great American AI Act. Most comprehensive AI regulation ever proposed in the U.S.
→ Trump and Bernie Sanders both publicly discussed partial government ownership of AI companies. In the same week.
→ Goldman Sachs and JPMorgan are building derivatives markets to trade the cost of GPU computing power.
→ Global AI spending forecast to hit $2.59 trillion in 2026. 47% jump over last year.
Three IPOs worth over $4 trillion combined.
A frontier model launched and killed within 72 hours.
The first trillionaire in human history.
AI agents making purchases with your credit card.
And we’re not even halfway through June.
11
16
62
11,275
Turn Claude into 20 different specialists for marketing & business.
Install real expertise, not just prompts.
Get my Claude skills bundle 👇
linktr.ee/alex_prompter
1
4
2,174
God of Prompt retweeted

Token costs are the number one complaint in AI coding right now. Most of the damage comes from a few default habits that are easy to fix.
I tested every optimization I could find this month. These 7 made the biggest difference in Claude Code:
1. Clear context between tasks. Type /clear when you switch tasks. Every new message re-sends your full conversation history as input tokens. That debugging session from an hour ago is still inflating every prompt you send. A fresh start costs nothing. Carrying stale context costs you on every turn.
2. Compact at 60%, not 95%. Claude auto-compacts near 95% context capacity. By then, output quality has already degraded. Run /compact focus on [current task] at 60% yourself. You get a cleaner summary and stay in the range where the model still performs well.
3. Match the model to the task. Opus for complex reasoning. Sonnet for routine code. Haiku for simple lookups and formatting. Most tasks don't need the most expensive model. One team documented a 72% cost reduction just from model switching and prompt caching over three months.
4. Offload heavy reads to subagents. A 10,000-line log file that Claude reads early in a session stays in context for every message after it. Instead of reading it in your main session, spin up a subagent. It reads in isolated context and returns only the findings. Your main window stays clean.
5. Build deterministic tools that cost zero tokens to run. Not everything needs an LLM call. Data formatting, file moves, test runners, API calls with known inputs. Write these as regular scripts. The LLM orchestrates. Deterministic code executes. The scripts run for free, every time, with predictable output.
6. Keep CLAUDE. md lean. It loads into every session before anything else. A 5,000-token CLAUDE. md costs 5,000 tokens before you've typed a word. Every turn. Every session. Keep it under 200 lines. Move project-specific context into scoped markdown files that only load when relevant.
7. Run /usage before starting a new task. Don't wait until you notice the model making mistakes it wouldn't have made 20 minutes ago. Check /usage, see where you stand, and decide whether to /compact or /clear before committing to the next chunk of work.

8
5
55
9,419
God of Prompt retweeted

What timeline are we on man.
There’s a $60 million UFC cage on the White House lawn for the president’s 80th birthday. 125,000 guests. 494 port-a-potties. He compared it to the Eiffel Tower and said maybe they’ll never take it down.
The world’s first trillionaire was minted yesterday. SpaceX IPO. One person now holds more wealth than the GDP of most countries.
The government is negotiating to own a piece of OpenAI. The CEO walked into the White House and pitched it himself. They’re calling it a Public Wealth Fund.
That same government killed OpenAI’s biggest competitor’s models on a Friday night. The reason? A verbal jailbreak claim from an unnamed company. The same jailbreak works on OpenAI’s models. Nobody touched them.
The competitor got blacklisted by the Pentagon four months ago. Their crime? Refusing to let the military use their AI for mass surveillance of American citizens. A judge called it retaliation. The Pentagon did it anyway.
Both AI companies filed to go public in the same two-week window. Both targeting trillion-dollar valuations. One has a government equity deal in progress. The other can’t keep its products online.
The engineers who built the banned models can’t use them anymore. Because of their passports.
And an AI company that spent thousands of hours cooperating with government safety testing got punished harder than any company that didn’t bother.
UFC on the White House lawn. A trillionaire. Government-owned AI. Export controls based on phone calls. Cage fights and trillion-dollar IPOs in the same news cycle.
Watch the film titled Idiocracy. That’s the timeline we’re on.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
104
739
4,286
697,728
God of Prompt retweeted
The timeline nobody’s lining up:
OpenAI and the Trump administration have been negotiating for over a year on a deal that would give the US  government an equity stake in the company.
OpenAI CEO Sam Altman first pitched the idea to Trump in early 2025. 
Trump wrote on Truth Social calling Anthropic “Leftwing nut jobs” and ordered every federal agency to stop using their technology. Hours after, OpenAI struck a Pentagon deal for classified networks. 
Defense Secretary Hegseth designated Anthropic a “supply chain risk,” the same classification normally reserved for Chinese telecom companies. The reason: Anthropic refused to let the military use Claude for mass domestic surveillance. 
A federal judge found the designation was retaliatory. 
OpenAI filed its S-1 around May 22. Anthropic filed June 1. Both targeting trillion-dollar IPOs. 
Trump confirmed the OpenAI equity talks on Air Force One on June 5 , saying Americans would become “partners” in AI companies.
Four days later Anthropic launched Fable 5.
Three days after that, the government killed it.
Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
9
18
65
17,064
The timeline nobody’s lining up:
OpenAI and the Trump administration have been negotiating for over a year on a deal that would give the US  government an equity stake in the company.
OpenAI CEO Sam Altman first pitched the idea to Trump in early 2025. 
Trump wrote on Truth Social calling Anthropic “Leftwing nut jobs” and ordered every federal agency to stop using their technology. Hours after, OpenAI struck a Pentagon deal for classified networks. 
Defense Secretary Hegseth designated Anthropic a “supply chain risk,” the same classification normally reserved for Chinese telecom companies. The reason: Anthropic refused to let the military use Claude for mass domestic surveillance. 
A federal judge found the designation was retaliatory. 
OpenAI filed its S-1 around May 22. Anthropic filed June 1. Both targeting trillion-dollar IPOs. 
Trump confirmed the OpenAI equity talks on Air Force One on June 5 , saying Americans would become “partners” in AI companies.
Four days later Anthropic launched Fable 5.
Three days after that, the government killed it.
Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
9
18
65
17,064
Turn Claude into 20 different specialists for marketing & business.
Install real expertise, not just prompts.
Get my Claude skills bundle 👇
linktr.ee/alex_prompter
4
2,865
Competing on price means you've run out of ways to be different.
Blue Ocean Strategy finds the market no one else is fighting for.
Steal my Claude prompt to find the uncontested space your competitors can't follow you into: 👇
1
2
23
7,693
How to run it:
1. Copy the prompt into Claude.
2. Fill in your offer, your competitors, and who you serve.
3. Send it. You get the ERRC grid, a value curve against the field, and a one-sentence blue ocean position.
4. Push back on any factor that feels generic. It rebuilds the grid sharper.
The framework finds the opening, but you decide if it's one you want to own.
1
4
2,301
This strategy is also a part of one of the skills in my bundle.
Turn Claude into 20 different specialists for marketing & business.
Install real expertise, not just prompts.
Get my Claude skills bundle 👇
linktr.ee/alex_prompter
1
1,937
AI image tools make pretty pictures.
The hard part is getting them on-brand and consistent, post after post.
Here are the 7 steps to make AI produce visuals and infographics that look like one brand:
3
1
31
21,334
String these together and your visuals look like one brand instead of random AI output.
The tools render the pixels, but you set the standard they have to hit.
1
2,068
If you found this useful, check this out as well.
Turn Claude into 20 different specialists for marketing & business.
Install real expertise, not just prompts.
Get my Claude skills bundle 👇
linktr.ee/alex_prompter
2
2,142