
Privacy Enabled Portable AI Context Memory
Joined May 2024
- Tweets 498
- Following 168
- Followers 99,822
- Likes 601
71 Photos and videos













Pinned Tweet

May 14
SuperNet is excited to announce that our core context memory technology Atomic Memory is live on GitHub today ⭐
May 14

We just open-sourced AtomicMemory.
The AI memory industry has a black-box problem.
AtomicMemory is a configurable open-source SDK self-hosted Core engine for memory your AI can inspect, correct, swap, and run on your own infrastructure.
Apache 2.0. HTTP-first. Docker quickstart.
github.com/atomicstrata
3
5
18
984
Jun 9
llm-wiki v0.9.0 is out.
Big thanks to our contributors who pushed this release forward.
This update adds the missing loop for durable AI knowledge:
• detect stale or orphaned wiki pages when sources change
• repair only affected pages with `llmwiki refresh --stale`
• export compiled pages as JSON records for Atomic Memory
• run evals over MCP, including source utilization and citation depth
• use the new in-process SDK to embed llmwiki directly in other tools
The goal: turn raw sources into an interlinked, cited, inspectable wiki that stays current as the underlying knowledge changes.
Visit us: github.com/atomicmemory/llm-…
3
9
234
Jun 8
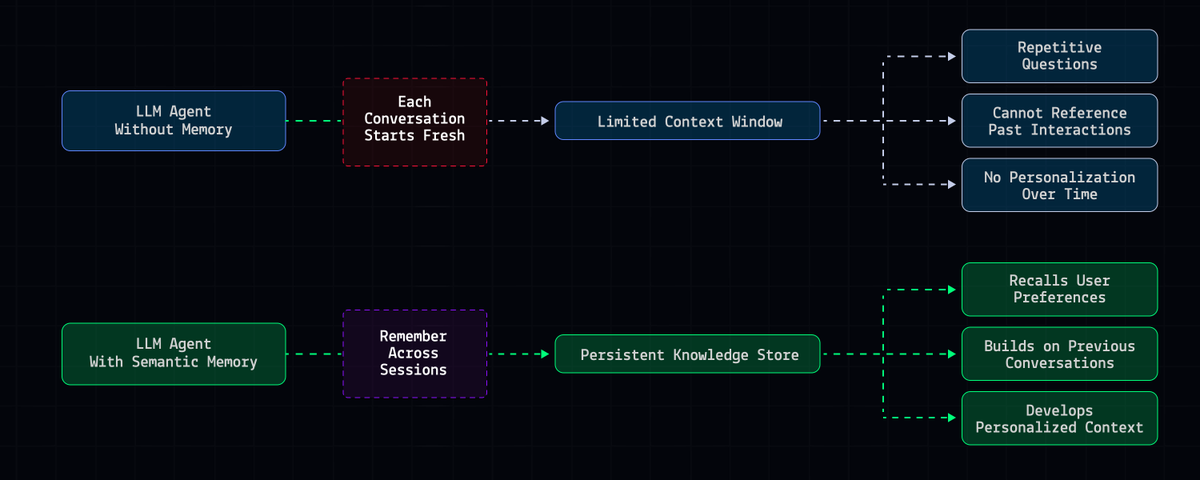
Agent memory stops being accurate over time if you're using the wrong semantic memory pattern.
Most vibe coders don't realize other patterns exist as distinct choices. They either default to RAG or copy a tutorial setup without understanding the tradeoffs.
Knowing these 3 patterns means you can pick the right one for your use case instead of hitting a wall six months in ⬇️
4
5
16
205
Jun 8
The 3 main architectural patterns for implementing semantic memory in LLM agents are:
1) Vector store retrieval (RAG-based)
The most common pattern. When your agent needs context, it runs a similarity search against the current query and pulls the closest matches.
2) Knowledge graphs
Instead of a similarity search, memory is stored as entities and relationships. Your agent retrieves facts by traversing connections between nodes rather than matching embeddings.
3) Hierarchical memory with consolidation
Hermes uses this pattern. It divides memory into layers where facts are extracted from raw sessions and stored separately, so retrieval pulls what your agent actually learned rather than searching through full transcripts.
2
1
11
148
Jun 8
Knowing which pattern fits your use case before you ship means you won't get trapped into a setup where changing your model or framework means losing all of your agent's accumulated memory.
If you found this useful, share what you're building or contribute to what we're building at @AtomicStrata 🤝
github.com/atomicstrata
11
79
Jun 3
We built two open-source memory tools for AI agents, both developed by @AtomicStrata
LLM-Wiki Compiler is your persistent knowledge base - Durable markdown compiled from your sources and built to compound over time.
Atomic Memory is your agent's persistent working memory - It only finds the specific facts that it needs, and you can directly correct its knowledge when needed.
Each remains valuable on its own, but even stronger together. Available at: github.com/atomicstrata
1
5
13
215
Jun 1
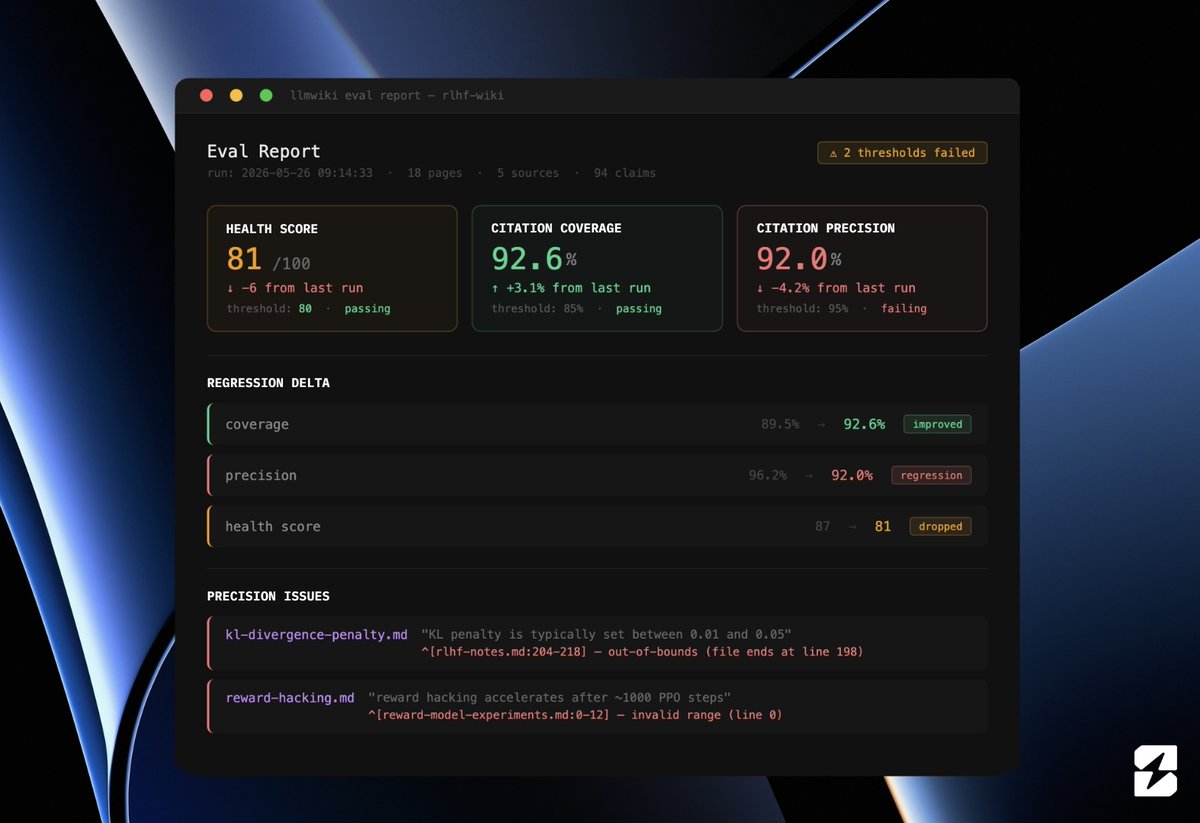
Check your wiki's health score before its too late!
llmwiki eval runs after every compile and scores your wiki on citation coverage, precision, and health. When a score drops, it tells you exactly which page and which claim caused it so you can fix the exact issue.
Devs, test it for your next compile: github.com/atomicstrata/llm-…
3
1
13
190
May 28
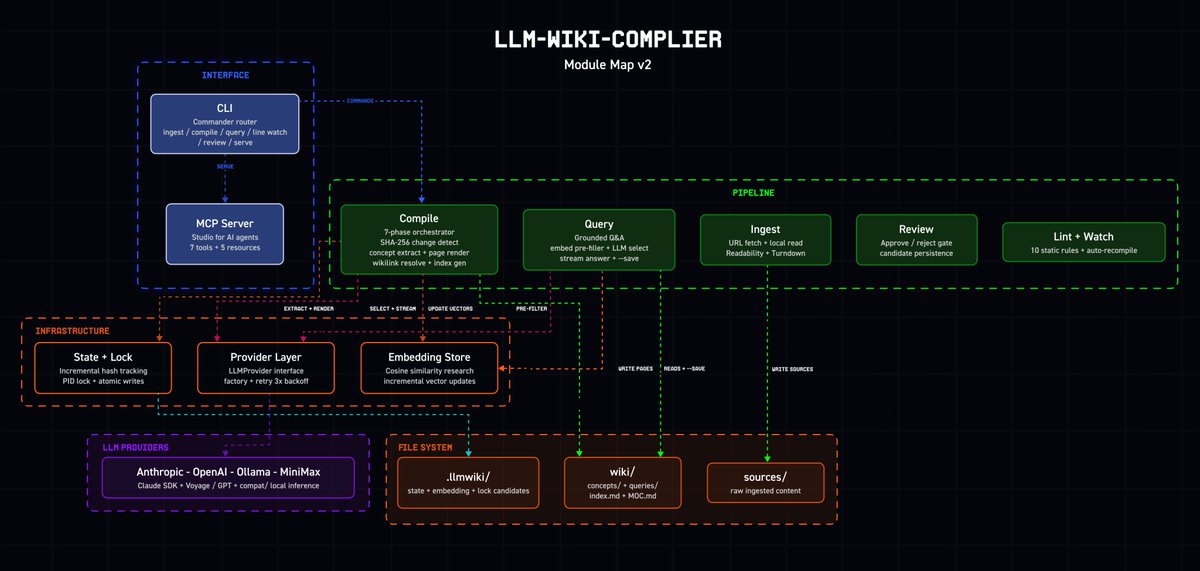
llm-wiki-compiler v0.8.0 shipped
We're now 1.4K Stars on GitHub! ⭐
The new release adds guided project next steps, one-command quickstart, and the first eval harness for measuring wiki quality over time.
Read the full changelog below ↓
2
3
15
484
May 28
Next up:
1) Task and decision ledger
Turn session ingest into durable agent memory: goals, decisions, open questions, outcomes, and next-agent handoffs.
2) Rollback, audit, and source
Undo/reverse ingest, compile diff reports, stale-claim checks, freshness reports, and a durable operation log.
3) Domain templates
Schema/prompt packs for research, codebase docs, team handbooks, decision logs, and standards/regulations.
4) Eval extensions
Retrieval recall suites, update-drift benchmarks, and comparisons against serious retrieval baselines.
If you like ambitious problems, open an issue to claim one or kick off a design discussion!
github.com/atomicstrata/llm-…
2
1
5
125
May 26
We've built to solve the AI memory black box problem with an open source that gives AI agents inspectable, correctable, and contradiction-safe memory you own.
Come join in our pitch at @StanfordSBA Today!
May 26

We at Atomic Strata are excited to be pitching at the Stanford Blockchain Acceleartor Demo Day today 9-10:30a pt. Join here luma.com/x3dqhaw0
4
1
8
322
Supernet AI 🌐 retweeted

May 25
This is @_HermesAgent backed by Atomic Memory in a real work setup.
Every decision, update, and correction your team makes gets organized and stays inspectable across sessions.
Atomic Memory improves your Hermes agent by replacing the 2.2KB native memory cap with unbounded, per-turn memory that resolves contradictions before anything hits storage.
The memory layer your team actually needs.
github.com/atomicstrata/atom…
5
8
19
724
May 25
The most pressing challenge in AI memory is multi-agent systems.
Single-agent memory is largely solved, but multi-agent memory is not. Most teams aren't aware of this until integrating it, and breaks in production after a month.
Here's what actually happens when multiple agents share memory 🧵
2
6
268
May 25
Shared memory means every agent in the system reads from the same pool and writes back to it after every session.
The idea is that what one agent learns, all agents benefit from.
The break happens when writes overlap. Two agents handle the same user in parallel, store different versions of the same fact, and the memory layer keeps both with no flags raised or conflicts resolved. The system then starts retrieving contradictions and acting on whichever one scores higher at retrieval time.
1
2
173
May 25
SuperNet is building an AI memory infrastructure that is designed around real production failure starting with @AtomicStrata
Because we believe that a great agent system is only as strong as its memory layer.
2
153
May 22
Your compiled wiki deserves better than a markdown folder.
llmwiki view turns your compiled wiki into a browsable web UI with citation chips linking every claim to its exact source line, organized tabs for concepts and saved queries, and a health dashboard for your sources.
Built on @karpathy's LLM Wiki pattern.
Now with a front end 🤝
github.com/atomicstrata/llm-…
1
5
376
May 19
Your compiled wiki now has a local web browser 🖥️
llm-wiki-compiler v0.7.0 shipped
read the full changelog below ↓
3
3
17
638
May 19
v0.7.0 closes one of the items from the last roadmap post.
llmwiki view gives your compiled wiki a local web UI. sidebar, search, citation chips that jump to the exact source line, and a health dashboard that doesn't re-run lint on every load.
1
3
239
May 19
Open to Discussion:
1) Recurring source refresh jobs — re-ingest URLs on a schedule, diff against the prior snapshot, re-compile only what changed
2) MCP prompt resources — curated agent prompts such as "review the wiki", "propose new sources", and "draft a comparison page"
3) Codex OAuth provider — ChatGPT subscription auth as a dedicated provider, with clear token refresh and embedding-limit behavior
4) Team-chat connectors for Slack / Discord / Teams-style institutional memory
If you like ambitious problems: graph/context packs and eval harness are the meatiest next contributions. Open an issue to claim one or kick off a design discussion ➡️ github.com/atomicstrata/llm-…
2
157
Supernet AI 🌐 retweeted

May 14
SuperNet is now Atomic Strata, and we just open-sourced Atomic Memory, our core AI context memory infrastructure.
Our thesis is that AI memory is becoming a foundational layer of the AI stack. It will determine what agents and AI apps know about users, teams, projects, workflows, and organizations. That layer cannot remain a hosted black box.
Most memory products today bundle storage, extraction, embeddings, retrieval, ranking, packaging, scope, and observability into one opinionated backend.
That creates lock-in at exactly the layer where developers need flexibility.
Atomic Memory is built around a more modular approach: a configurable SDK and self-hosted Core engine that developers can inspect, customize, swap, and run on their own infrastructure.
The key idea is simple: applications should not be permanently wired to one memory vendor, one model stack, or one theory of context.
This is the first step in the broader Atomic Strata rollout: open-source memory infrastructure first and then more exciting things to launching in the coming months.
May 14
We just open-sourced AtomicMemory.
The AI memory industry has a black-box problem.
AtomicMemory is a configurable open-source SDK self-hosted Core engine for memory your AI can inspect, correct, swap, and run on your own infrastructure.
Apache 2.0. HTTP-first. Docker quickstart.
github.com/atomicstrata
4
3
19
4,596
May 14
SuperNet is excited to announce that AtomicMemory — our core context memory technology — is partnering with Filecoin Onchain Cloud.
Persistent memory for AI agents, backed by decentralized storage.
With AtomicMemory × Filecoin, agent memory becomes:
→ Wallet-encrypted
→ Inspectable
→ Correctable
→ Persistent by design
We believe AI memory should be portable, user-owned, and verifiable — the way context should have always worked.
Connect your wallet and try it on Calibration testnet today ⬇️
atomicmem.filecoin.cloud
9
8
50
8,116