
An AI coding agent for any model.
Joined May 2026
- Tweets 121
- Following 10
- Followers 59
- Likes 16
13 Photos and videos



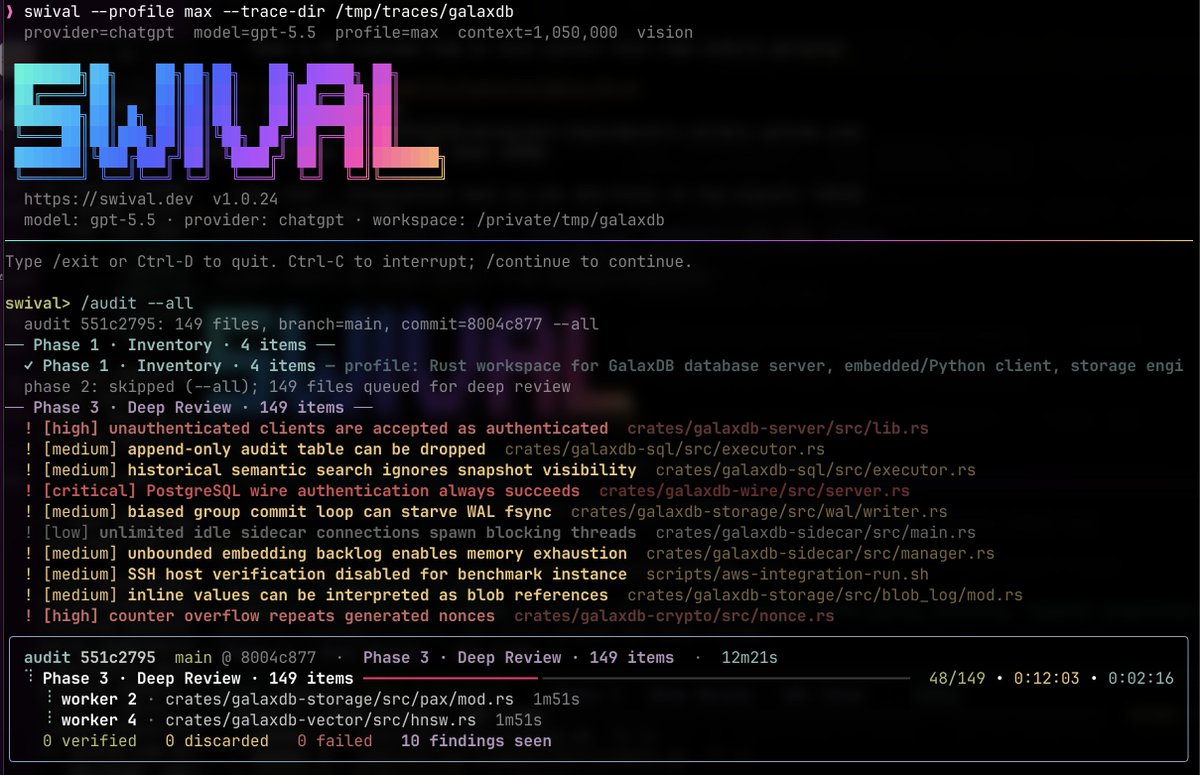



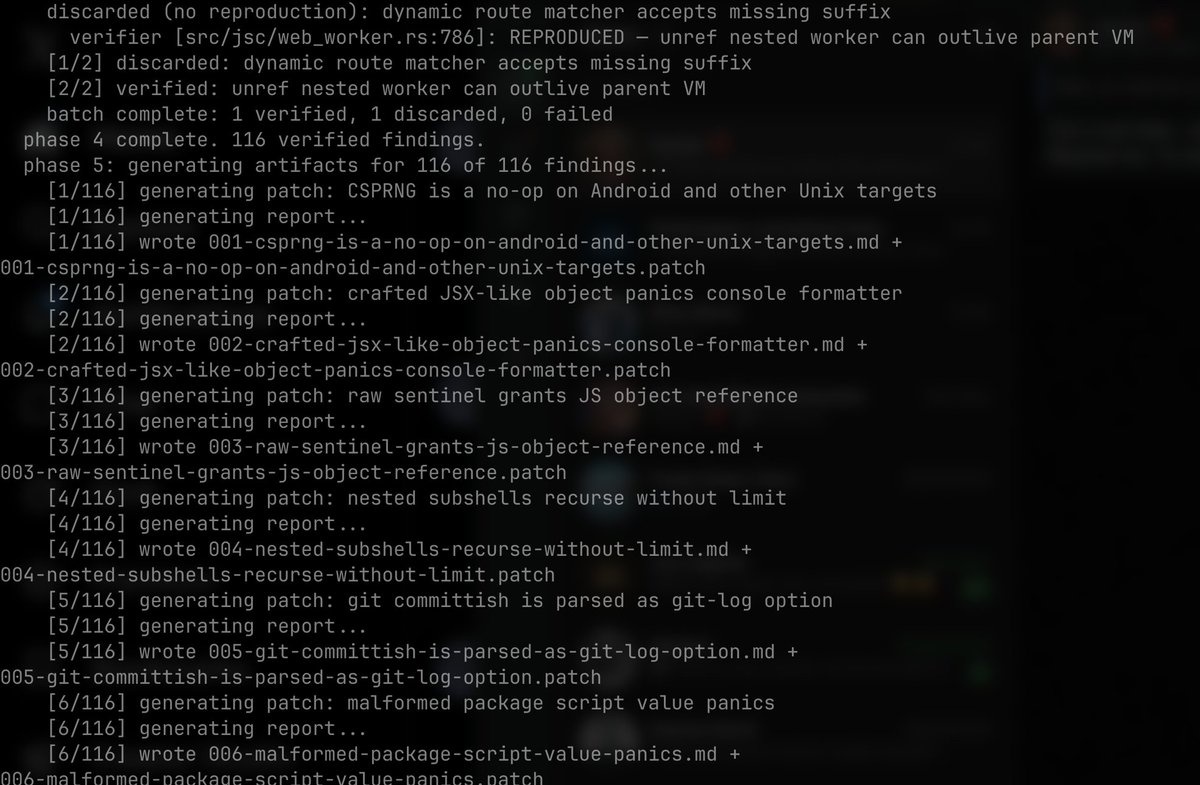



Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
docs.z.ai/devpack/latest-mod…
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
314
916
7,683
1,835,329
Swival.dev retweeted

Jun 12
"Make a simple game in JavaScript" with Qwopus 3,6 27 B-Coder huggingface.co/spaces/jedisc…
3
1
11
10,285
Swival.dev retweeted

Jun 12
🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


614
1,617
13,554
1,936,459
Jun 10
Xiami MiMo Code: mimo.xiaomi.com/blog/mimo-co… - Some interesting ideas there! @XiaomiMiMo
86
Swival.dev retweeted

Jun 9
One of my personal favorite features announced at WWDC will I suspect be a sleeper hit: container machines, allowing your Mac to run a lightweight, persistent Linux environment with your home directory and repos automatically mounted: github.com/apple/container/b…
227
815
9,698
728,610
Jun 9
I’m testing CohereLabs/North-Mini-Code-1.0. This model makes risky decisions on its own. I’m glad I enabled the Nono sandbox.
76
Jun 9
Swival 1.0.30 is out, with bug fixes and support for Apple Foundation Models. github.com/swival/swival
29

Swival.dev retweeted

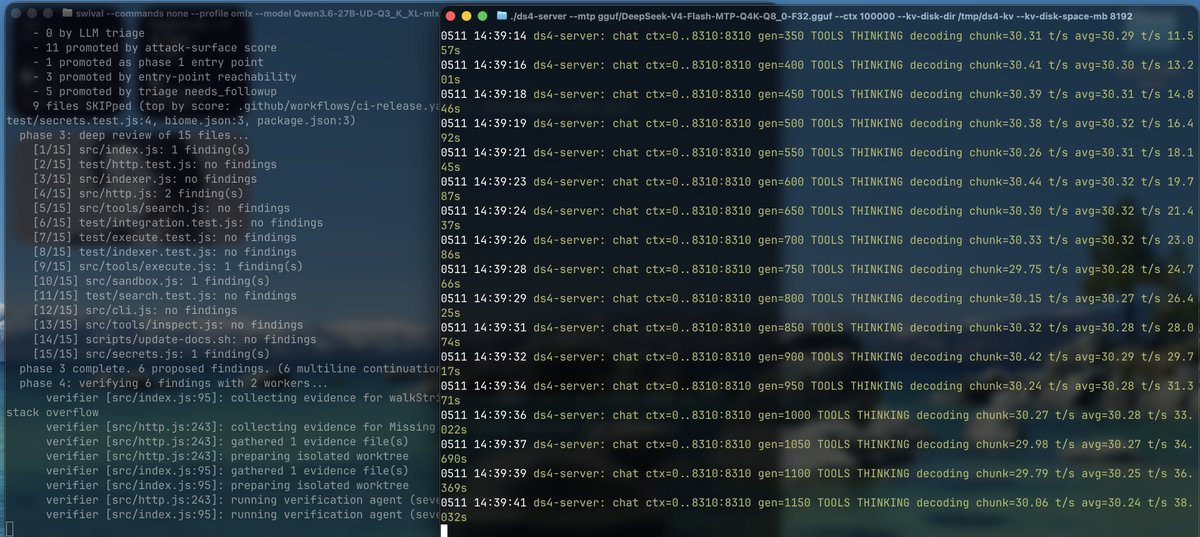
DeepSWE and DeepSeek V4 Pro: surely the benchmark is designed to facilitate GPT 5.5, and mini-swe is not ideal for many models tested, but personally I executed it, against DeepSeek official API, using V4 Pro and reasoning Max. It used around 1B tokens and I've got only 5.3% at the end 😢
Estimated cost:
- cache-hit input: $3.54
- cache-miss input: $3.74
- output: $4.89
- total: $12.18
Without cache-aware pricing, the same token volume would look like about $433.76 😱, so cache accounting is essential here.
Bottom Line from AI analysis:
This is a clean direct-DeepSeek run from an infrastructure/methodology standpoint: no OpenRouter ambiguity, no Docker setup failures, no missing thinking metadata, and no retries. The result is low: 6/113 = 5.31%, with 3 agent timeouts counted as failures.
I invite others to check what's going here in details, results seem really odd, but code is there, verifiers is there, all in the open. I'm retrying now with reasoning High and later I'll try with a different harness.
Composer 2.5 with Grok Build gave me ~10%
We need to keep investigating. I'm testing MiniMax M3 now.

45
10
312
32,254
Swival.dev retweeted

Jun 5
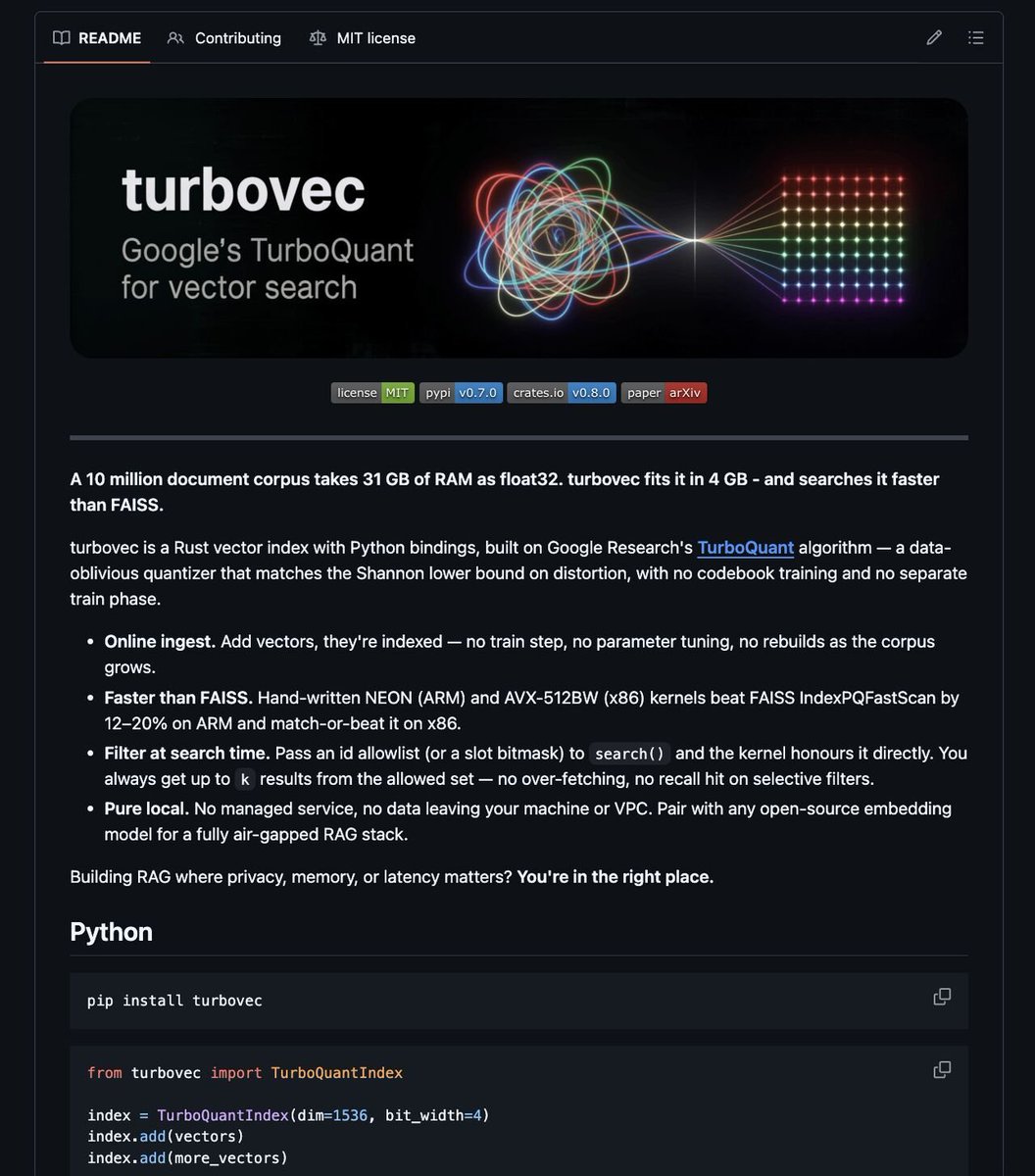
Google's new algorithm just shrunk 31GB of memory down to 4GB 🤯
TurboVec is a new open-source tool that stores the data your AI app searches through, using 16x less memory.
It runs on Google's TurboQuant, which skips the slow setup step every other tool needs.
→ Faster search than the popular alternative (FAISS)
→ Works on both Mac and standard servers
→ Narrow results to exactly what you want
→ Plugs straight into LangChain and LlamaIndex
Your data never leaves your machine. Runs fully offline, works with Python out of the box.
100% Open Source.
57
343
2,631
148,058
Swival.dev retweeted

Jun 6
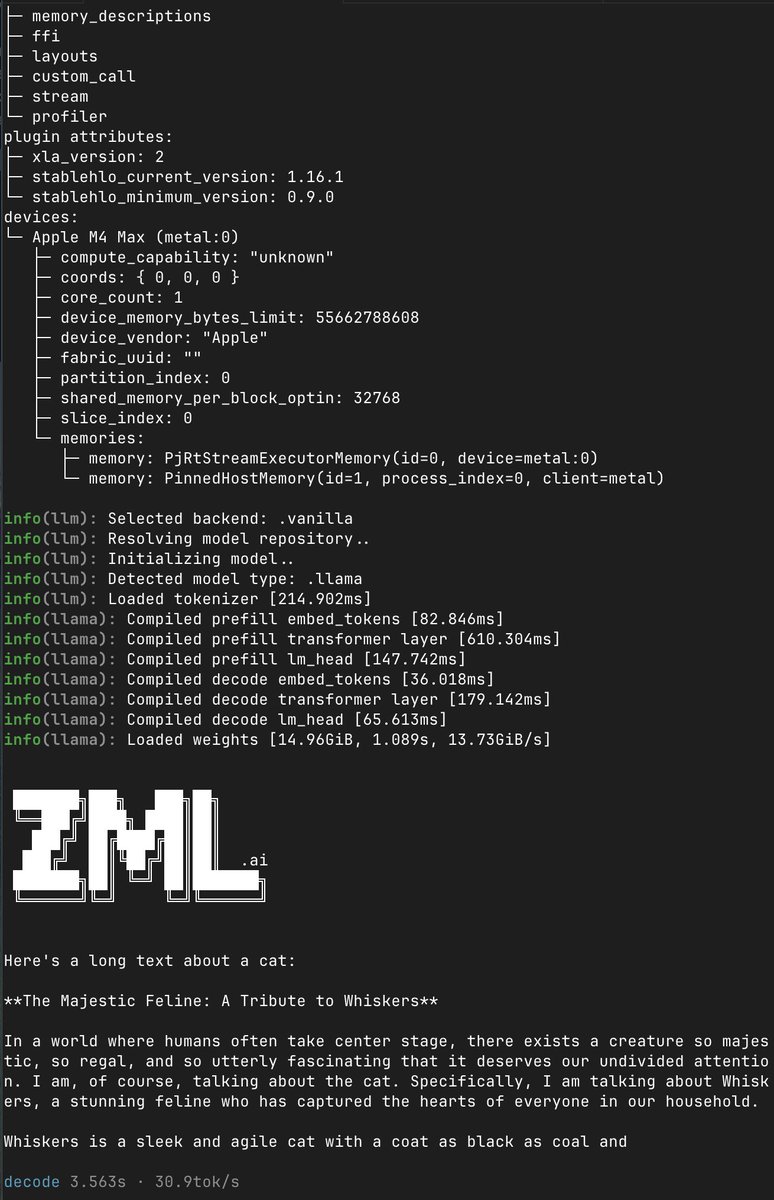
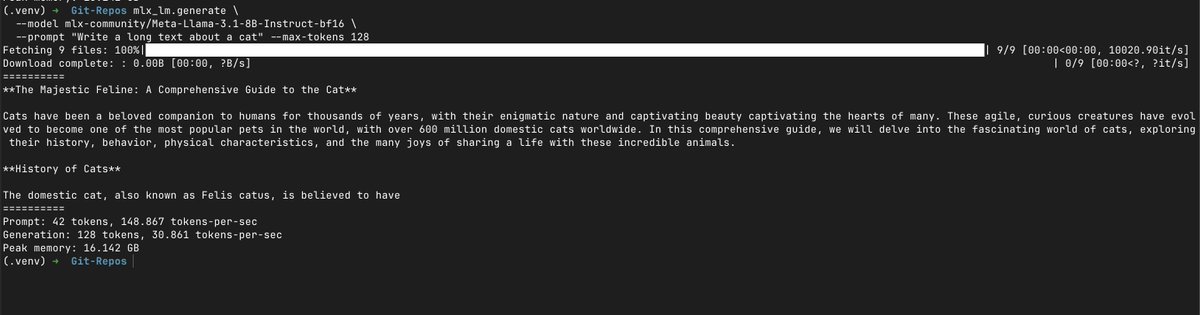
.@zml_ai's Metal backend is now as fast as MLX in tok/s (llama 3.1 8B)
4
4
60
6,002
Swival.dev retweeted

Jun 5
Before the week ends, let's acknowledge one of the most INSANE week ever for open AI, with 25 notable open-weight drops across every modality:
🧠 LLMs
→ NVIDIA Nemotron 3 Ultra: 550B hybrid Mamba-MoE, only 55B active, 1M context, MMLU 89.1. NVFP4 variant claims ~5x throughput on Blackwell. First openly-weighted 550B hybrid Mamba-Transformer, closing the gap with frontier closed models.
→ Google Gemma 4 12B: fully open dense any-to-any (text/image/audio/video), 256k context, encoder-free, 140 languages, AIME 2026 at 77.5. Shipped with a 23-checkpoint QAT wave (mobile ONNX MLX). Most deployable model of the week.
→ StepFun Step-3.7-Flash: 198B sparse MoE VLM, ~11B active, SWE-Bench PRO 56.3. Apache 2.0.
→ Liquid AI LFM2.5-8B-A1B: edge MoE, just 1.5B active, 128k ctx, MATH500 88.8, MLX-ready. Best on-device option this week.
→ JetBrains Mellum2-12B-A2.5B-Thinking: their first open MoE, near-Qwen3-14B coding at 2.5B active. Apache 2.0.
🎨 Image gen (the surprise of the week)
→ Ideogram 4: their FIRST-EVER open weights. 9.3B flow-matching DiT trained from scratch. #2 overall behind GPT Image 2, top open-weight model on Design Arena LMArena. Strongest open checkpoint for text-rich images, full stop. It has taste. Still can't believe this is open weights.
🔊 Audio & Speech (a breakout week for open TTS, 4 labs shipped)
→ Boson Higgs Audio v3 4B: 102 languages, 21 emotions, singing/whispering/shouting, sub-second TTFA.
→ RedNote dots.tts: the only fully continuous (no codec) open TTS pipeline, Apache 2.0.
→ Google Magenta RealTime 2: real-time music gen, <200ms latency, text audio MIDI. multimodalart ported it to PyTorch within hours with live ZeroGPU demos.
→ NVIDIA Nemotron-3.5 ASR: 600M streaming, 17x more concurrent streams vs Parakeet RNNT 1.1B.
👁️ Vision & VLMs
→ PaddleOCR-VL-1.6: SOTA document parsing at 1B params, Apache 2.0.
→ Baidu NAVA: 6.3B joint audio-video gen, best-in-class A/V sync, Apache 2.0.
🎬 Video, 3D & World Models
→ NVIDIA Cosmos3-Super: 64B omnimodal world model coupling action trajectories with video audio gen, for Physical AI.
→ JD JoyAI-Echo: up to 5-min multi-shot text-to-video on LTX-2.3.
→ ByteDance Bernini-R VAST TripoSplat (single-image-to-3D Gaussian splats, MIT).
87
409
2,758
527,027


推荐大家读一下MAI-Thinking-1的technical paper,里面有详细的怎么训出一个SOTA LLM的(几乎)所有细节。
microsoft.ai/wp-content/uplo…
23
230
1,441
183,019
Swival.dev retweeted

おはようLLM
今日のピックアップはフランス発のこのモデル。Qwenベースの35BモデルでSonnet4.6超えのベンチをマーク
いや絶対試すから
huggingface.co/Hcompany/Holo…
12
33
387
23,834
Swival.dev retweeted

Jun 2
I just shipped oMLX v0.4.0, the first official release with the new native Swift macOS app.
github.com/jundot/omlx/relea…
oMLX now ships with a redesigned onboarding flow, settings UI, Hugging Face cache discovery, and a much more native-feeling way to manage and run local models on macOS.
- Huge thanks to GitHub contributor popfido for the excellent work that drove the Swift transition.
My goal is still the same: I want oMLX to be the app someone can open on a Mac and immediately try Local AI with, without needing to understand all the machinery first.
If you try 0.4.0, I’d really appreciate feedback on the macOS app experience, especially first launch, model discovery, server start/stop, update checks, and anything that still feels confusing.
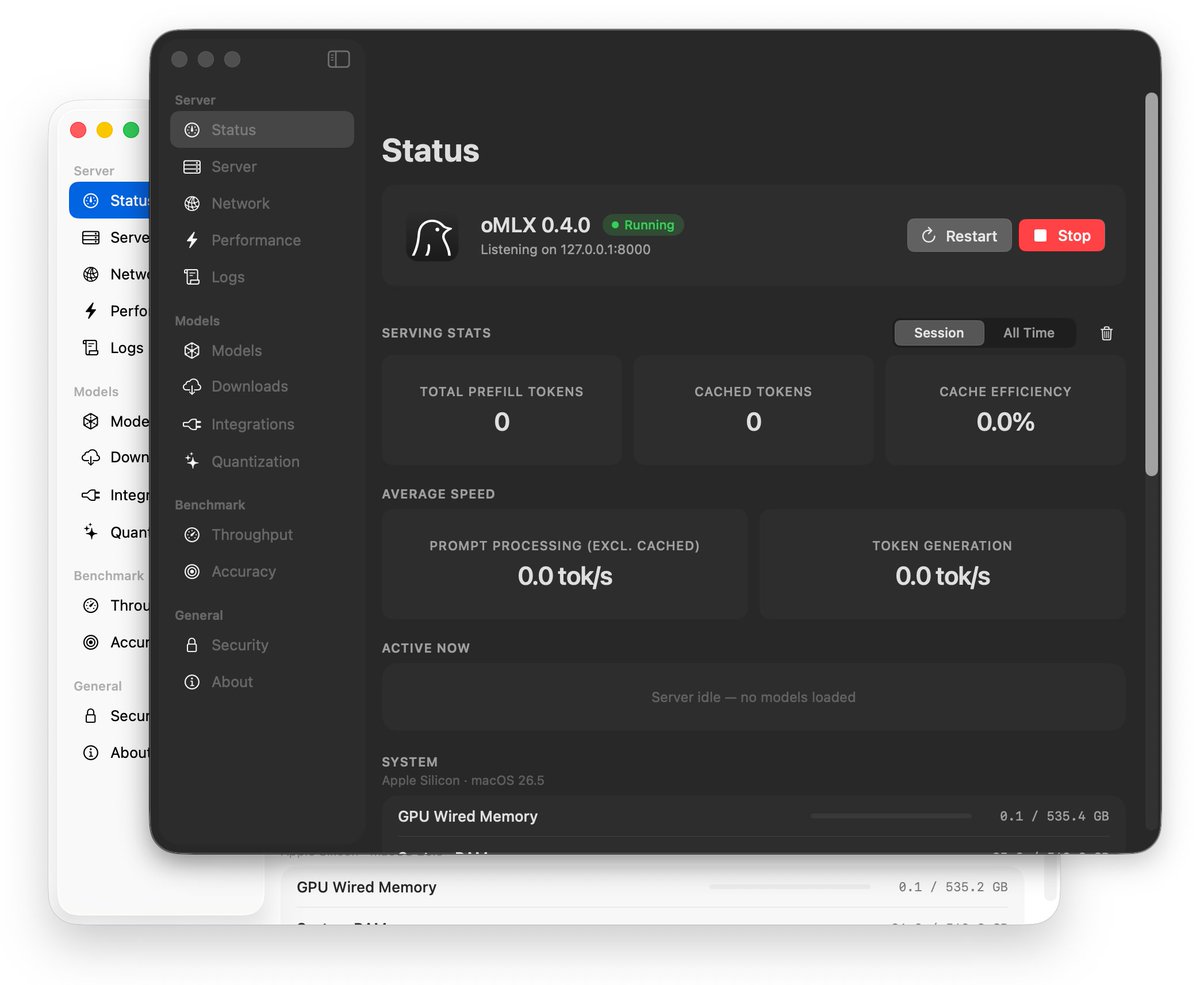
25
28
286
40,488
Swival.dev retweeted

Jun 1
Mellum started with code completion.
Mellum2 is built for more – handling both natural language and code.
A 12B-parameter open-source LLM for routing, RAG, and sub-agents, optimized for ultra-low-latency inference.
Now on @huggingface.
Learn more: jb.gg/zpb9dp
24
65
334
99,230