
Joined February 2020
- Tweets 501
- Following 684
- Followers 651
- Likes 1,810
25 Photos and videos








Pinned Tweet

19 Dec 2024
At AGU I talked to NASA people about how agencies could better support open-source tools they rely on. I argued that our recent collaboration between Xarray and NASA ESDIS on xarray.DataTree was a good model to copy - read about how it happened here!
xarray.dev/blog/datatree
1
4
25
1,767

Science needs a social network for sharing big data hackmd.io/@TomNicholas/H1Kzo… by @TEGNicholasCode
1
4
245
Tom Nicholas retweeted

28 Jan 2025
We're moving over to BlueSky and LinkedIn for all our future announcements. Follow us at bsky.app/profile/pangeo.io to find out more about tomorrow's showcase 😉 (p.s., it's on Xpublish at Scale at 4 PM EST 🚀) Connect with us on LinkedIn at linkedin.com/company/pangeo-…
3
3
1,043
Tom Nicholas retweeted

9 Jan 2025
Our friend's over at @zarr_dev made a big release today!
Xarray v2025.01.1 was also released today with full support for Zarr-Python 3 🚀

🎉 Zarr-Python 3 is here! 🎉
- Full support for Zarr v3 spec
- Chunk-sharding for more efficient data storage
- Major performance boosts with async I/O & parallel compression
💻 pip install --upgrade zarr
Blog post: zarr.dev/blog/zarr-python-3-…
8
25
4,002
Tom Nicholas retweeted

20 Dec 2024
🌤️ #AMS2025 is just around the corner! We are taking AMS by storm with an exhibitor booth (booth 353), two talks from @_jhamman and @rabernat , and hosting a @pangeo_data Community Happy Hour (register here: lu.ma/ddtba5f5)!

1
6
11
1,311
4 Dec 2024
Completely agree - "in theory" we have the simple scalability of the cloud, but in practice it's often a headache, for no good reason, which prevents adoption by most users (including many scientists)
4 Dec 2024

New Post: Cloud Computing is Broken
matthewrocklin.com/cloud-is-…
Investor asks: "What's next for Data/Cloud Infrastructure?"
My answer: "Boring stuff. People struggle with basics."
Cloud feels like MP3 players before iPod. In theory everything is good. In practice adoption is low
1
5
304
Tom Nicholas retweeted

18 Nov 2024
That said, it isn't 100% clear that NASA's best move is to immediately convert 10000 data sets into cutting edge ARCO formats. Kerchunk and Virtual Zarr offer benefits of ARCO while keeping data in the native formats.
1
2
11
2,766
14 Nov 2024
I'll also be there if you want to join me working on @xarray_dev , DataTree, or VirtualiZarr!
14 Nov 2024

Are you heading to #AGU24 next month? Consider joining us for a bonus day of hacking on @pangeo_data. I'll be there representing @EarthmoverHQ and helping folks work with #icechunk and @zarr_dev.
Details and signup here: discourse.pangeo.io/t/post-a…
1
5
335
Tom Nicholas retweeted

12 Nov 2024
Come learn about recent @xarray_dev GroupBy improvements at tomorrow's (Wed, Nov 13) Pangeo Showcase!
discourse.pangeo.io/t/pangeo…

1
7
28
1,774
Tom Nicholas retweeted

24 Oct 2024
We've talked a lot about #Icechunk's performance this week 🚀. But the Zarr-Python 3 results are also very encouraging! We're a few weeks away from the 3.0 launch but what this chart shows is that the new AsyncIO multi-threading functionality in Zarr is going to be really good.
24 Oct 2024

ALSO this release is the first to be compatible with the much anticipated v3 implementation of zarr-python! (still on its beta branch right now)
This brings big performance benefits when reading @zarr_dev on S3 via async and (b) compatibility with @EarthmoverHQ 's Icechunk.
1
8
626
24 Oct 2024
Xarray v2024.10.0 has just been released, including support for xarray.DataTree and zarr-python v3 !!!
github.com/pydata/xarray/rel…
@xarray_dev @zarr_dev
2
26
95
13,451
24 Oct 2024
ALSO this release is the first to be compatible with the much anticipated v3 implementation of zarr-python! (still on its beta branch right now)
This brings big performance benefits when reading @zarr_dev on S3 via async and (b) compatibility with @EarthmoverHQ 's Icechunk.
1
6
948
24 Oct 2024
All these integrations represent literally years-worth of effort, all coming out at once 🤯
And that's not even mentioning all the other changes you see in a typical xarray release!
1
9
288
Tom Nicholas retweeted

21 Oct 2024
⚡️ Icechunk is fast! What does this mean for users? Reduced cost for all data-intensive compute jobs and enhanced productivity for the data scientists who work with data all day long.
Icechunk, @EarthmoverHQ's new transactional cloud-native storage engine for array / tensor data, works together with @zarr_dev , augmenting the Zarr core data model with features that enhance performance, collaboration, and safety in a multi-user cloud-computing context.
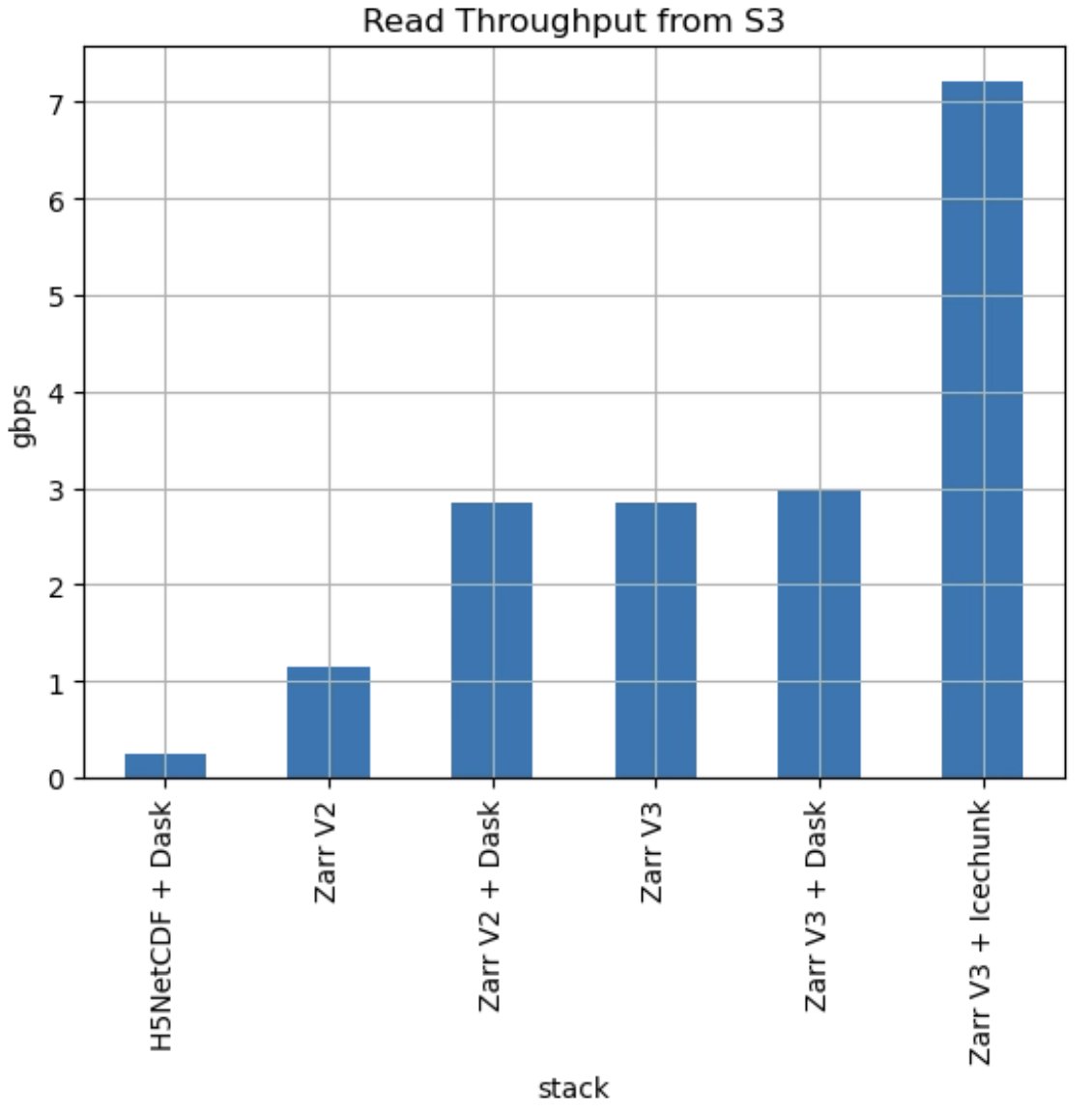
Reading data through Icechunk is 36x faster than trying to read HDF5 files from cloud object storage, 6x faster than regular Zarr alone, and 2.5x faster than regular Zarr Dask. Most importantly, Icechunk can achieve throughput on par with the compute instance network bandwidth, the "hardware limit" for I/O bound workloads.
Want to learn more about this benchmark? Come to our Icechunk informational webinar tomorrow, Tuesday, October 22nd from 12 - 1 PM EST. Registration link: share.hsforms.com/1SCOFqe2kT…

ALT Performance analysis of various I/O stacks for reading data from S3. The NetCDF dataset was a 1.8 GB NetCDF file (4GB uncompressed) from the NSF NCAR Curated ECMWF Reanalysis 5 (ERA5) The dataset was transformed to Zarr with zstd compression and written in both V2, V3, and V3 Icechunk format. It was read back using Xarray plus different I/O stacks, with and without Dask.
1
8
35
4,699
Tom Nicholas retweeted

18 Oct 2024
🎉 @source_coop is now open source!
The web application - github.com/source-cooperativ… - and the data proxy - github.com/source-cooperativ… - have been opened up & updated with documentation on how to get it running locally.
More documentation coming soon tasks for new developers!
8
17
928
Tom Nicholas retweeted
17 Oct 2024
We’re hosting a webinar on Tuesday, October 22 from 12- 1 PM EST to discuss what Icechunk means for the scientific data community and answer questions from attendees. Register here: share.hsforms.com/1SCOFqe2kT…

15 Oct 2024

🚀 We are thrilled to announce the release of the Icechunk storage engine, a new open-source library and specification for the storage of multidimensional array (a.k.a. tensor) data in cloud object storage.
Read our blog post about Icechunk here: earthmover.io/blog/icechunk
7
10
1,508
Tom Nicholas retweeted
17 Oct 2024
Great opportunity to work with @BalwadaDhruv, one of most innovative physical oceanographers in the world, at @LamontEarth in NYC!
16 Oct 2024

We are looking to hire a postdoctoral scholar at Lamont Doherty Earth Observatory to work on submesoscale and mesoscale ocean turbulence using observations and machine learning: academic.careers.columbia.ed…
2
9
1,205