
The Toronto Student Media Network (TSMN) off the air, 09/09/23
Joined January 2019
- Tweets 22,313
- Following 2,709
- Followers 770
- Likes 20,607
1,939 Photos and videos














TSMN studios retweeted

21 May 2025
New prompt for you to play with - Through the keyhole
prompt: looking through a [MATERIAL] keyhole towards a mythical [WORLD] dark fantasy, [very black background] around keyhole, sharp focus, photographic
Would love to see your keyhole creations. Have a great week!




20
18
132
15,976


TSMN studios retweeted

4 Jun 2024
Composer Tan Dun's three-movement Water Concerto is hypnotic, both visually and aurally. Using water as a musical instrument, this extraordinary piece uses innovative techniques to explore "organic music"
58
61
302
73,586



DexCap: a $3,600 open-source hardware stack that records human finger motions to train dexterous robot manipulation. It's like a very "lo-fi" version of Optimus, but affordable to academic researchers. This isn't teleoperation: data collection is decoupled from the robot execution, so that you don't need a one-to-one ratio of human operators babysitting the robots at all times.
Great work from @chenwang_j & @StanfordAILab!
21
139
707
108,596
TSMN studios retweeted

15 Mar 2024
The co-founder of @nunet_global Dr. Weaver D.R. Weinbaum proposes aligning #AGI to a ground principle of benevolence applicable to all instances of Open Ended Intelligence to shape a friendlier future where humans and AGIs coexist. Read on to learn more: medium.com/bright-hall/a-pri…
3
48
274
11,303
TSMN studios retweeted

13 Mar 2024
The phone-based world in which children and adolescents now grow up is profoundly hostile to human development, @JonHaidt writes. Here's how to save childhood: theatlantic.com/technology/a…
14
186
556
316,948
6,633
16,816
161,883
62,471,451
TSMN studios retweeted

6 Mar 2024
AI can show you things that you have never seen before. What’s your favorite humanimal?
311
351
2,328
7,051,463
TSMN studios retweeted

5 Mar 2024
Unlike FB and IG, these bad boys never go down.

ALT Encyclopedia Britannica volumes on a shelf
162
974
5,816
447,902

Here are today's AI headlines:
[1] Anthropic Unveils Game-Changing Claude 3 AI
[2] Microsoft Amplifies Azure with €2 Billion Mistral Investment
[3] Wix Revolutionizes Web Design: Launches AI Chatbot for Instant Website Creation from Simple Prompts
[4] OpenAI Enhances ChatGPT with 'Read Aloud' Feature
[5] Amazon Bedrock Launches Anthropic's Advanced Claude 3 AI Models
To read more, check out:
natural20.beehiiv.com/p/anth…
2
2
13
1,235
Anthropic is so back. Two things I like the most about Claude-3's release:
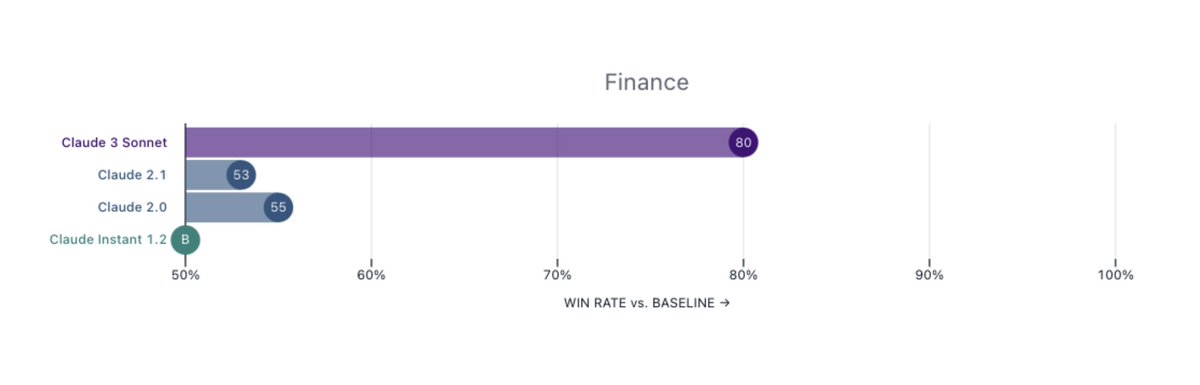
1. Domain expert benchmarks. I'm much less interested in the saturated MMLU & HumanEval. Claude specifically picks Finance, Medicine, and Philosophy as expert domains and report performance. I recommend all LLM model cards to follow this, so that the different downstream applications know what to expect.
2. Refusal rate analysis. LLMs' overly cautious answers to innocent questions are becoming a pandemic. Anthropic is typically on the ultra safe end of the spectrum, but they recognize the problem and highlight their efforts on it. Bravo!
I love that Claude dials up heat in the arena that GPT and Gemini dominate. Though keep in mind that GPT-4V, the high water mark that everyone desperately tries to beat, finished training in 2022. It's the calm before the storm.
19
138
965
200,479

Your order was delivered… to the Moon! 📦
@Int_Machines' uncrewed lunar lander landed at 6:23pm ET (2323 UTC), bringing NASA science to the Moon's surface. These instruments will prepare us for future human exploration of the Moon under #Artemis.
1,381
5,117
19,199
4,391,771
TSMN studios retweeted

17 Dec 2023
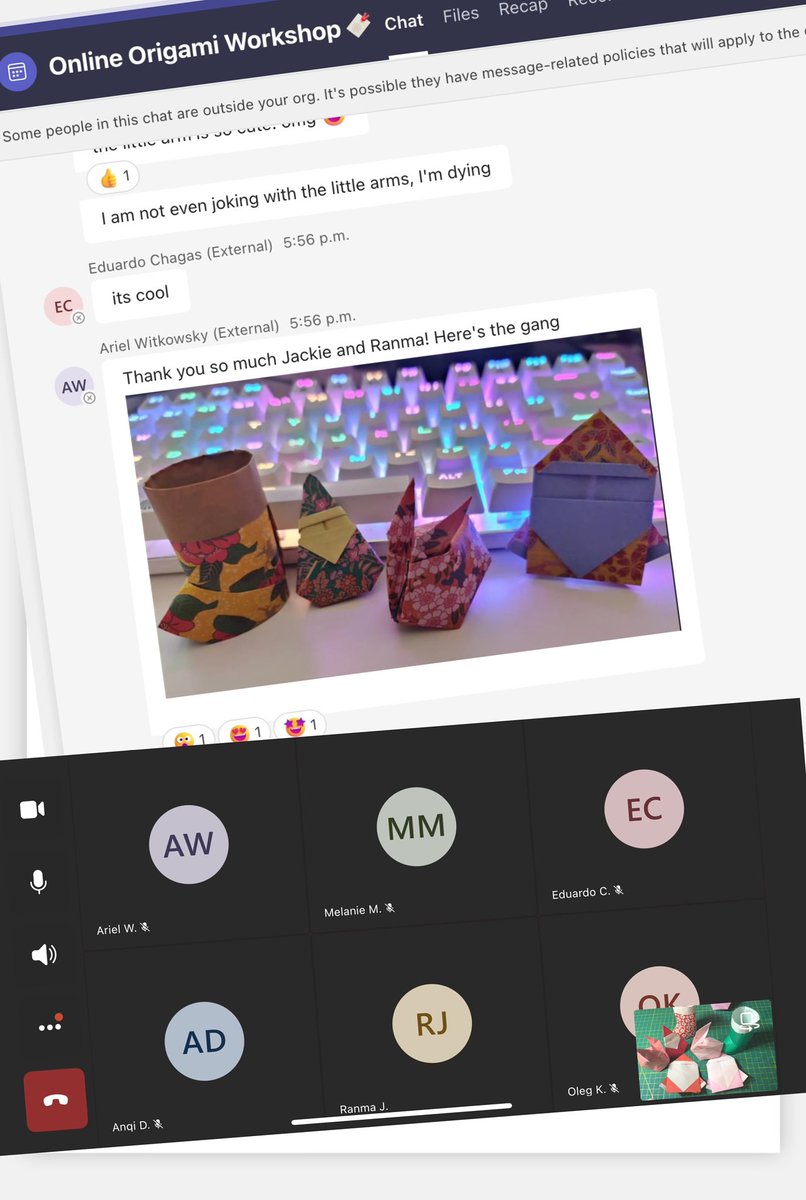
🎄As Christmas approached, companies welcomed us for virtual #WorkplaceWellness 📌Origami sessions are great for team building and de-stressing—we would love for more events like this! 💪 😊 @TSMN_studios @DavidWestRH @RichmondHillPL @CreativePulseTW @RHCulturalPlan @lmurua1979

1
3
173
TSMN studios retweeted
13 Dec 2023
🎄Christmas is around the corner! Origami Fun at @shop_hillcrest. Thanks so much for the @RichmondHillPL invitation! Way to go, guys 😊😊 @DavidWestRH @lmurua1979 @dukeofedcanada @ShadNetwork @CreativePulseTW @VARC_TStvMedia @TSMN_studios




3
5
163
TSMN studios retweeted
17 Jul 2023
😍So sweet #origami fun at the Unionville Summer Festival! Way to go, our squad 🙌🙌 @unionvillebia @markhamlibrary @yeehongcentre @DavidWestRH @RHCulturalPlan @TSMN_studios @CreativePulseTW @lmurua1979




1
5
140
TSMN studios retweeted
14 May 2023
Wish all moms Happy #MothersDay 🥰🥰🥰 @DavidWestRH @TSMN_studios @CreativePulseTW @lmurua1979 @dukeofedcanada @ShadNetwork @RichmondHillPL @agotoronto @OrigamiUSA




2
7
267
TSMN studios retweeted

18 May 2023
Breaking 🚨
Open AI launched an official app for ChatGPT.
This official app is free (no ads!), syncs your history across devices, and brings you the newest model improvements from OpenAI.
Download it from the link below.

12
13
87
38,898