
Institute of Artificial Intelligence of China Telecom. Rooted in AI, flowing across edges.
Joined April 2026
- Tweets 55
- Following 14
- Followers 17
- Likes 0
20 Photos and videos








Jun 10
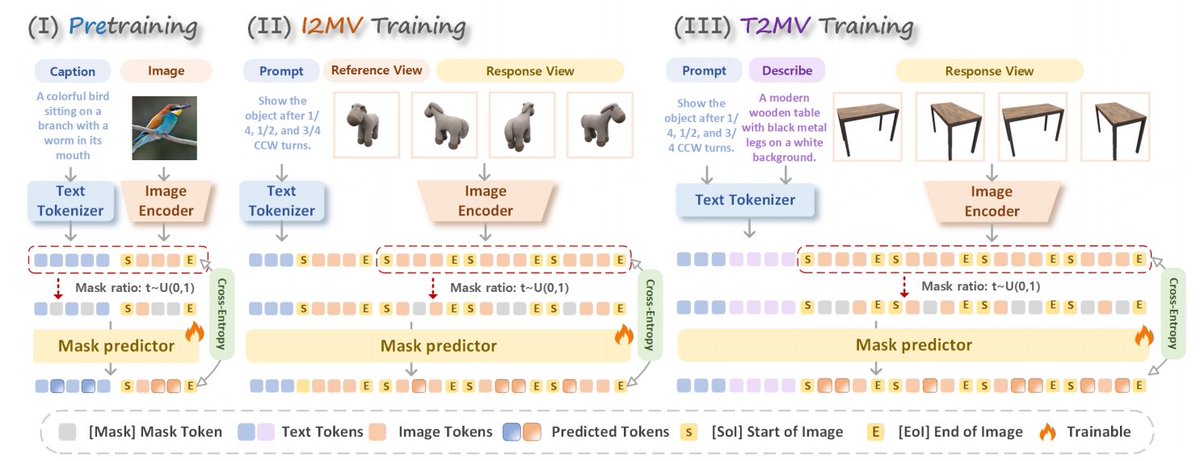
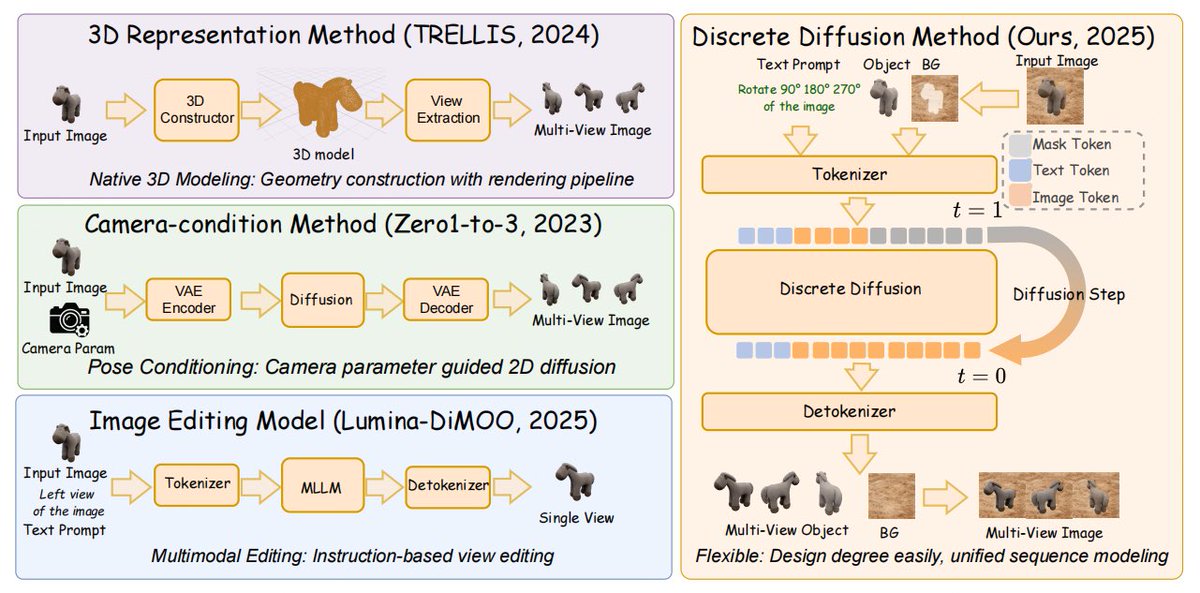
🤔Can AI reconstruct an object's unseen views from a single observation?
🔷Multi-view consistency has long been a fundamental challenge for world modeling. Existing approaches often rely on explicit 3D reconstruction, camera conditioning, or specialized geometric designs.
In our latest ICML 2026 paper, we explore a different path.
✨Meet ViewMask-1-to-3, an innovative multi-view generation framework built for advanced world models!
Paper: arxiv.org/abs/2512.14099
#ICML2026 #ViewMask #WorldModel

1
1
1
85
Jun 10
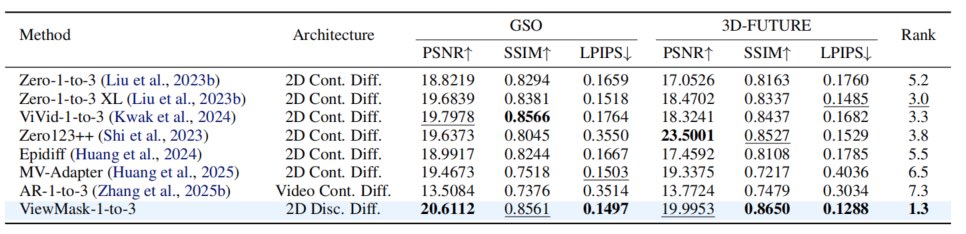
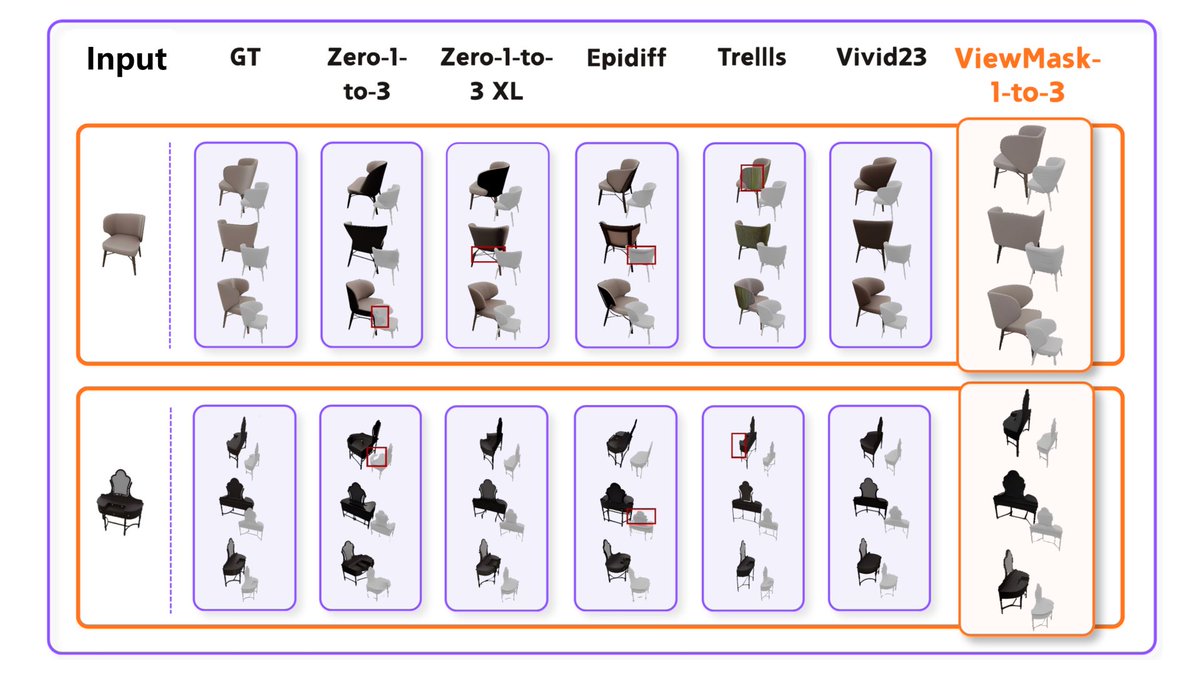
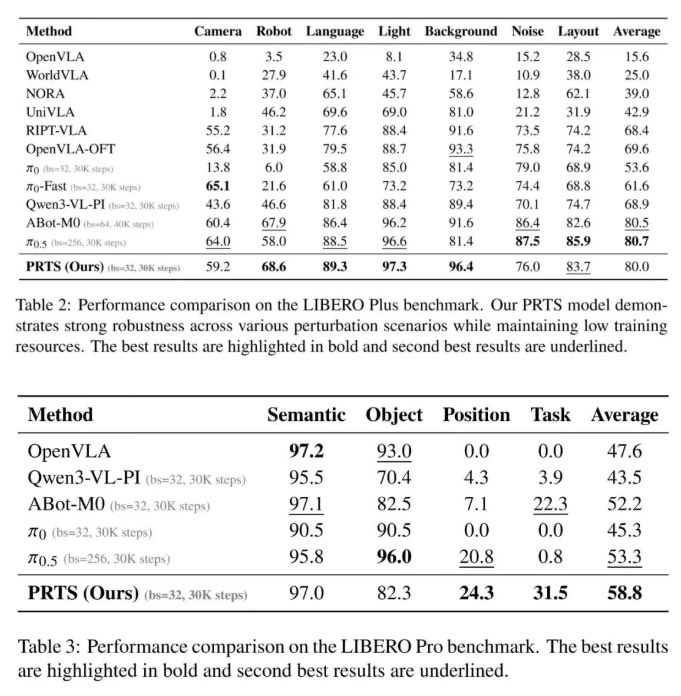
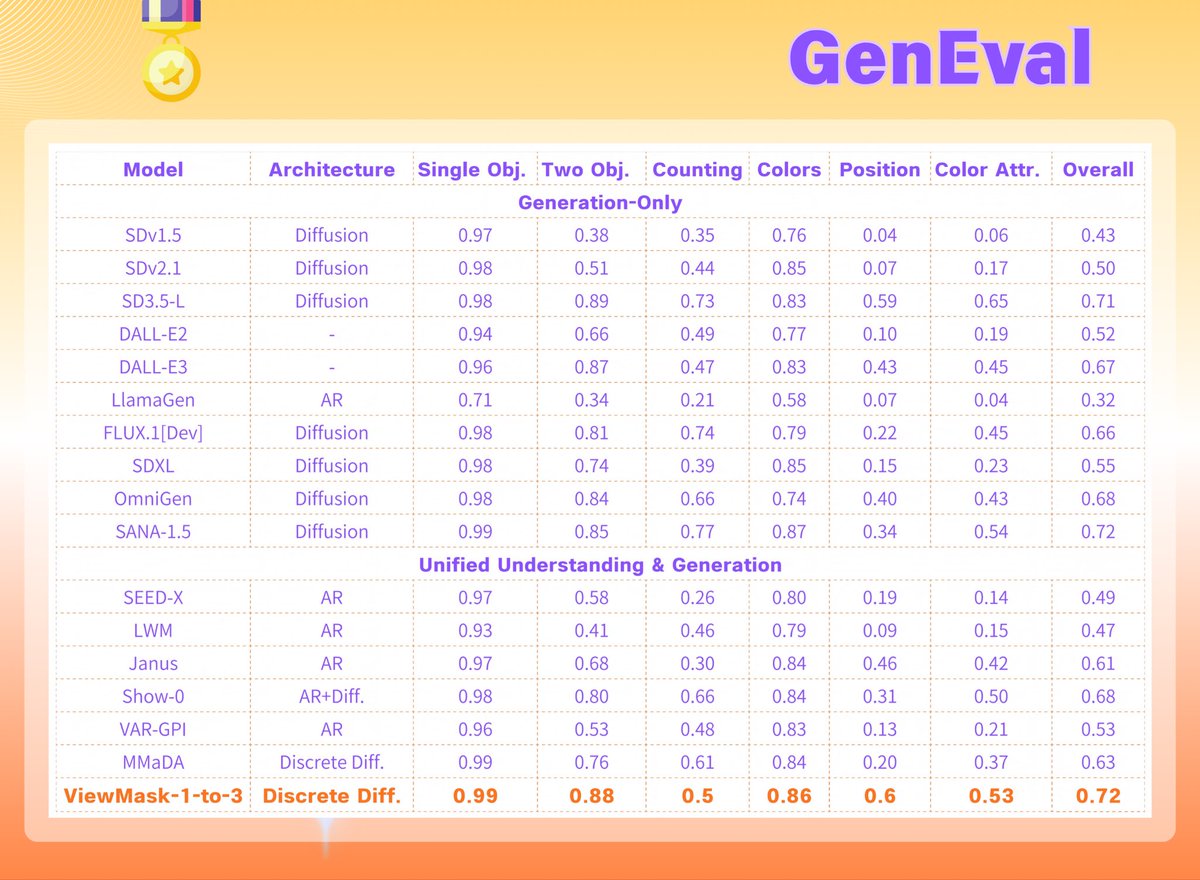
ViewMask-1-to-3 outperforms the baseline on both GSO and 3D-FUTURE:
🏆#1 average ranking across image-level metrics (PSNR, SSIM, LPIPS, CD, IoU)
🏆Up to 10.6% IoU higher on 3D-FUTURE than continuous diffusion models
🏆Ranked top tier on GenEval
2
1
35
Jun 10
Potential applications include:
🤖Environmental perception for embodied robots
🎮Automatic content creation for VR/AR and games
🛜Full-view display for e-commerce products
With a streamlined structure and strong generalization, it enables easier, more economical large-scale deployment of world models.
#AIGC #WorldModel
1
23
Jun 5
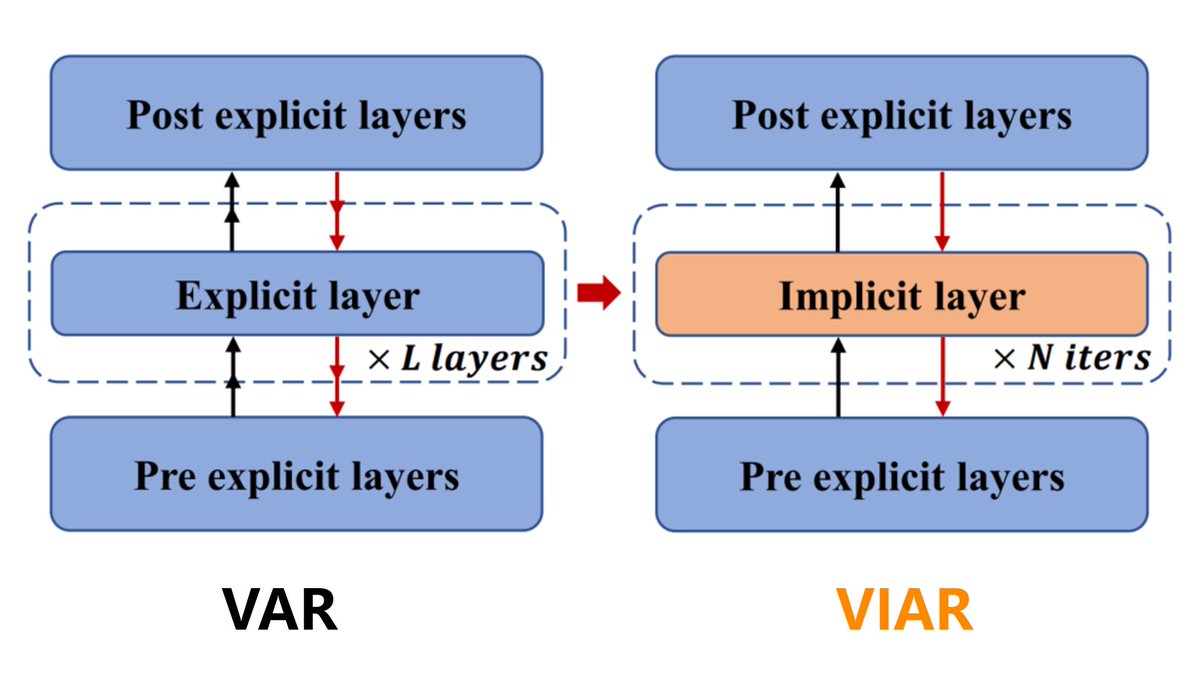
✨Meet VIAR (Visual Implicit Autoregressive Modeling)!
⚙️Built as our major upgrade to VAR(Visual Autoregressive Modeling), this cutting-edge next-gen visual generator nails the balance between generation quality and operational efficiency for large-scale real-world deployment.
We’re pleased to share the full paper, which has also been recently accepted by @icmlconf 2026 — our first batch of accepted ICML research papers!
Full paper: arxiv.org/abs/2605.01220
#VIAR #AutoregressiveModels #ICML2026 #AIResearch
1
2
66
Jun 5
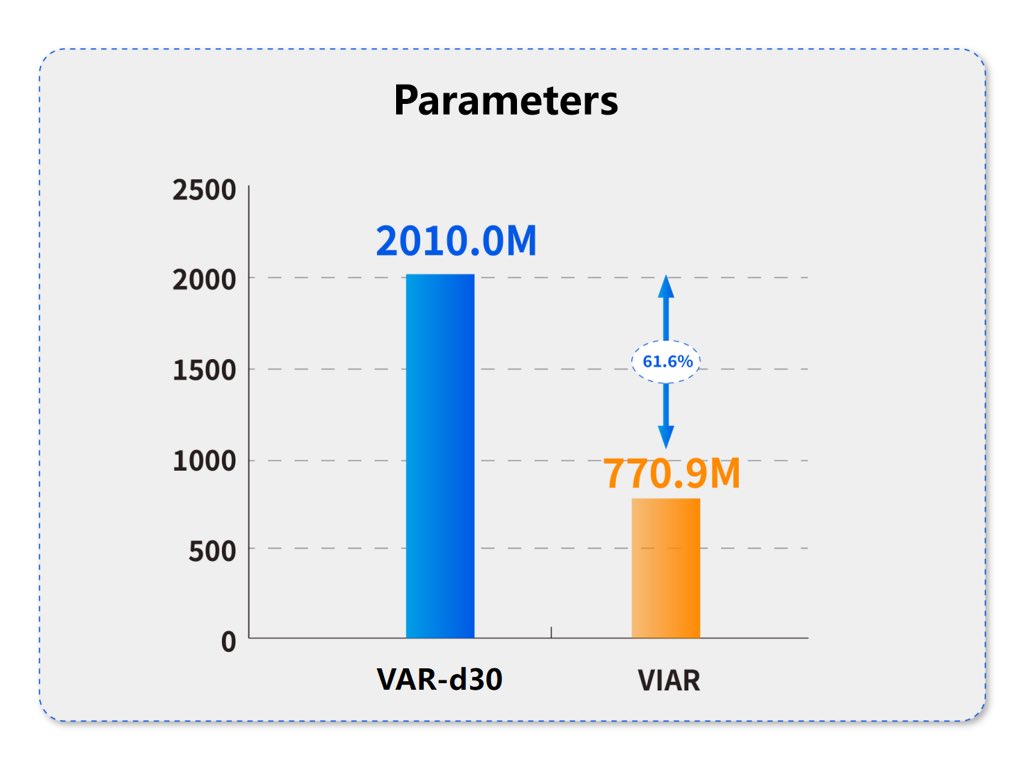
VIAR vs. VAR: Breakthrough Performance Gains
✅ 61.6% fewer total parameters
✅ Peak inference GPU memory usage drops by 42.0%
✅ 2.1× higher inference throughput
✅ FID 2.16, sFID 8.07 (top-tier generation quality)
✅ Stronger zero-shot in-painting and class-conditional editing
#ModelEfficiency #ZeroShotLearning #VisualAutoregression

1
1
35
Jun 5
For Generative Transmission of AI Flow
✅ Lightweight deployment for edge and terminal devices
✅ high-fidelity visual generation and low-latency transmission
✅ Flexible quality adjustment without retraining
VIAR strikes a dynamic balance across quality, speed, GPU memory, parameter efficiency, and deployment flexibility, powering AI Flow and paving a more economical, scalable path for real-world AI applications
#EdgeAI #GenerativeTransmission #VisualGeneration #AIApplications
1
29
Jun 3
🌍Physics you can trust. Worlds you can interact with.
🍎Use TelePhysics, a training-free framework, to reconstruct a physically consistent 3D environment from a single RGB image, then customize its dynamics and appearance however you want.
Go from a static image to a fully interactive, physics-grounded 3D world in seconds.
🌐Now, world models can be built to be more realistic
#worldmodel #AI #3D #TeleAI
1
2
1
78
Jun 3
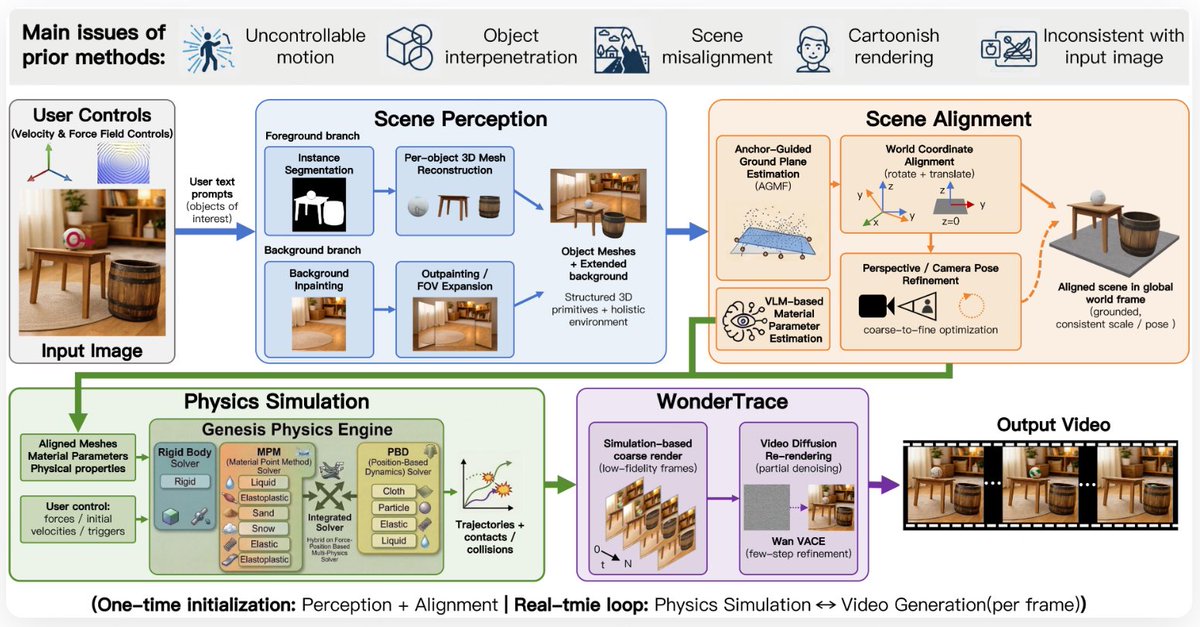
🤔How TelePhysics builds physical 3D worlds from a single image:
We reconstruct the entire scene holistically, not piece by piece.
✅ A unified world coordinate system:
Resolves penetration and alignment ambiguities and guarantees geometrically coherent configurations.
✅ A scene-aware pose alignment mechanism:
Places objects into the 3D scene without violating physical constraints.
✅ A coarse-to-fine camera pose optimization strategy:
Ensures precise photometric and geometric alignment.
1
1
1
56
Jun 3
🚀We’re building TelePhysics to power next-gen creative and simulation workflows.
Built on the AI Flow framework, TelePhysics enhances foundational world models to generate physically consistent 3D environments, providing a canvas for storytelling, robotics simulation, and design to transform how we build and interact with digital environments.
Follow @TeleAI_AIFlow for more updates.
Here’s the full paper:
arxiv.org/pdf/2605.20290
Open-sourced on:
telephysics.github.io/
1
41
May 22
✨Turn a single-view video into a 4D scene in minutes!👀
👉Meet Full-4D — TeleAI’s unified framework that reconstructs a complete 4D scene from just one monocular video, using joint time-view modeling.📹
Outputs are:
- Geometrically accurate
- Temporally smooth
- Visually consistent
- Free to explore from any viewpoints
Swipe to see how it works!
#WorldModel #4D #TeleAI
1
1
85
May 22
4D Reconstruction from Generated Multi-View Videos
🧑💻Videos alone aren’t enough.
we turn them into explorable, real-time renderable 4D scenes.
👉Core Tech 1: 4D Gaussian Splatting (4D-GS)
Lifts videos into dynamic Gaussian primitives for real-time, free-viewpoint rendering.
👉Core Tech 2: Flow Matching Distillation (FMD) Loss
Uses a pretrained diffusion prior to refine geometry and fill occlusions with plausible content.
🌐Together, they deliver a coherent, explorable 4D reconstruction from a single video.
#4DGaussianSplatting #RealTimeRendering #WorldModel #4D #TeleAI
1
1
53
May 22
Where Full-4D matters:
🤖Robotics: Provides precise simulation for humanoid training
👓AR/VR: Turn everyday videos into explorable 4D worlds.
🎬Video Production: One shot, infinite angles.
🚗Autonomous Driving: One clip turns into an interactive and trainable simulation.
This isn't just generating scenes.
🌍It's giving AI new eyes to observe the world.
Follow @TeleAI_AIFlow . Redefining AI's real-world 4D perception.
#EmbodiedAI #FutureOfAI #TeleAI #WorldModel
54
May 13
🤖True robot teamwork isn’t about moving in parallel. It’s about moving as one.🤝
But how? How about a multi-robot groupchat?💬
For too long, multi-robot collaboration suffered:
⏱️No shared clock → misaligned actions
🚧Rigid roles → no adaptation to unexpected obstacles or mistakes
💬We need a robot system that can evolve through communication.
💡Meet DeCoNav: A dialog-enhanced long-horizon collaborative vision-language navigation powered by AI Flow which can fix both flaws above at once.
Paper: arxiv.org/pdf/2604.12486
#MultiAgent #Robotics #AI #DeCoNav
1
1
1
63
May 13
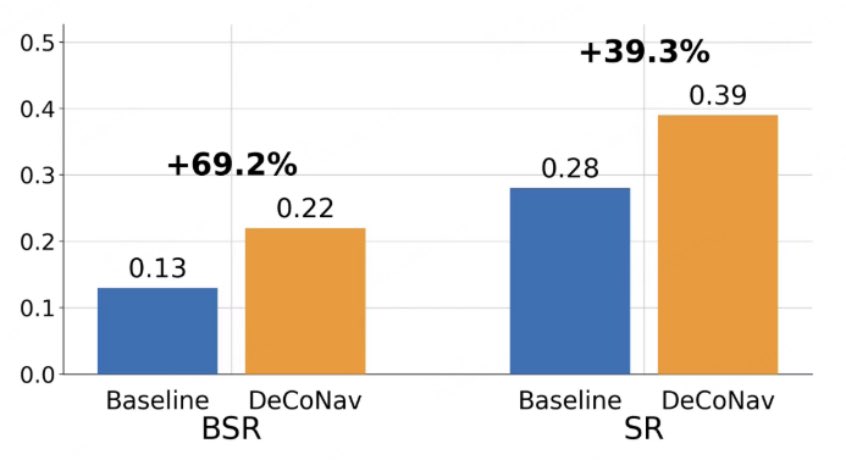
🚀Under strictly synchronized evaluation, DeCoNav achieves a qualitative leap:
- BSR (Both Success Rate): 0.13 → 0.22
Relative improvement: 69.2%
- Success Rate (SR): 0.28 → 0.39
Relative improvement: 39.3%
1
1
46
May 13
Across real-world scenarios that demand collaboration:
- 📦Warehouse logistics
- 🏭Industrial inspection
- ⛑️Emergency rescue
DeCoNav provides a blueprint for next-gen robots to be dialogue-driven, negotiable, and reconfigurable in real time.
#FutureOfRobotics #AIResearch #TeleAI #CollectiveIntelligence
1
46