
Research Scientist @GoogleDeepMind - Gemini video. Previously PhD @Oxford_VGG
Joined March 2019
- Tweets 143
- Following 613
- Followers 1,594
- Likes 686
24 Photos and videos











Tengda Han retweeted

Congratulations to the authors of "Efficiently Reconstructing Dynamic Scenes One D4RT at a Time", recipient of the #CVPR2026 Best Paper Award! 🏆 arxiv.org/pdf/2512.08924 @GoogleDeepMind

14
28
503
34,689

Jun 7
We will present “Seeing without Pixels” sites.google.com/view/seeing… at ExHall A, Poster #248, Sunday (today) from 15:30 to 17:30 @CVPR !! This work just won a CVPR Compute Transparency Champion award! Welcome to come by and say hi! #CVPR2026 #CVPR
Seeing without Pixels
Can you guess which action goes with which camera trajectory?
sites.google.com
2 Dec 2025

Excited to share our latest work! Grateful for the guidance from all my collaborators, and special thanks to Tengda for being such an amazing mentor during my internship @GoogleDeepMind 😊
1
20
1,479
Jun 5
Fun fact: the apartment we rented in Oxford Summertown from 2021-2023 has accommodated @elliottszwu (CVPR20 best paper awardee) and @jianyuan_wang (CVPR25 best paper awardee) as subletters. Now also @ChuhanZhang5 - new CVPR26 best paper awardee. Grateful to be at @Oxford_VGG !!

Huge congrats to the team, D4RT is a team work and all the authors have been working very hard on this in the past one year. Very well deserved. 🍻 and thank you Award Committee Members for the recognition.
3
6
88
13,028
Jun 5
Congratulations to @ChuhanZhang5 and the team @GoogleDeepMind !!!
Huge congrats to the team, D4RT is a team work and all the authors have been working very hard on this in the past one year. Very well deserved. 🍻 and thank you Award Committee Members for the recognition.
19
1,988


Feb 26
1 Dec 2025

Human perception is active: we move around to see, and we see with intention. In our latest work "Seeing without Pixels", we find "how you see" (how the camera moves) roughly reveals "what you do" or "what you observe" -- and this connection can be easily learned from data.
6
77
7,848
Feb 26
4 Dec 2025
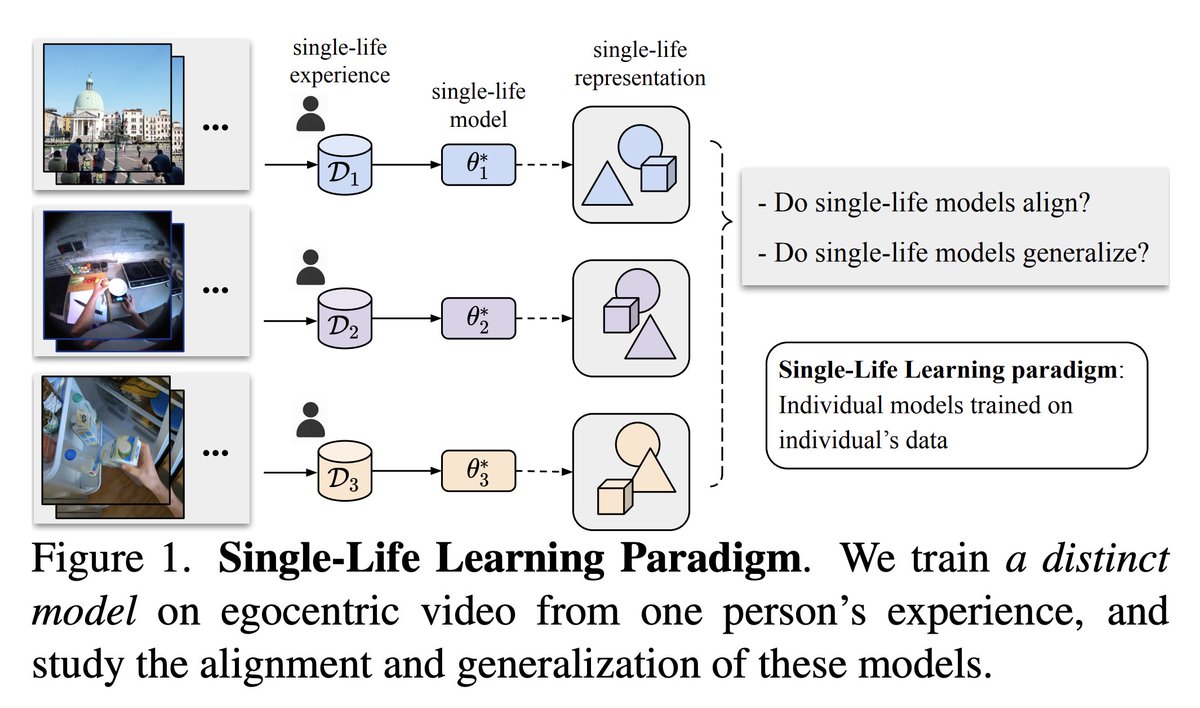
Human learns from unique data -- everyone's OWN life -- but our visual representations eventually align. In our recent work "Unique Lives, Shared World" @GoogleDeepMind, we train models with "single-life" videos from distinct sources, and study their alignment and generalisation.

1
6
34
4,442
Tengda Han retweeted

Feb 19
Gemini 3.1 Pro is here.
We’ve significantly improved the model’s overall intelligence so it can solve tougher problems. 🧵
288
725
6,263
925,071
Tengda Han retweeted

10 Dec 2025
I’m looking for PhD students in Audio & Video for a Summer 2026 internship at Google DeepMind!
⚠️ Requirement: Prior publication in this area.
To apply, tell me the most critical research gap in AV understanding to see if we are a match! docs.google.com/forms/d/1qTv…
1
19
127
11,761
10 Dec 2025
A SOTA model on 4D reconstruction from @GoogleDeepMind! Amazing work from @ChuhanZhang5 and the team! It was so satisfactory to see these reconstruction results and I've been having a great experience using it
10 Dec 2025
A SINGLE encoder decoder for all the 4D tasks!
We release 🎯 D4RT (Dynamic 4D Reconstruction and Tracking).
📍 A simple, unified interface for 3D tracking, depth, and pose
🌟 SOTA results on 4D reconstruction & tracking
🚀 Up to 100x faster pose estimation than prior works
5
21
200
17,683

🚀 Glad to share the exciting project — SceneGen: Single-Image 3D Scene Generation in One Feedforward Pass! We explored the generation of 3D scenes with multiple assets from a single image. 🎉 ACCEPTED by 3DV 2026!!!
All resources have been open-sourced and publicly available!
📄 Paper: arxiv.org/abs/2508.15769
💻 Code: github.com/Mengmouxu/SceneGe…
🔗 Model: huggingface.co/haoningwu/Sce…
🌐 WebPage: mengmouxu.github.io/SceneGen
#3DVision #AI #GenerativeAI #ComputerVision #3DV2026 #SceneGen

1
2
7
891
Tengda Han retweeted

4 Dec 2025
Future AI models will learn predominantly post-deployment – to do the tasks of interest to each user. This will happen throughout an individual “life”. In a new paper arxiv.org/pdf/2512.04085 we lay out groundwork for this type of capabilities in the wild from a visual standpoint.
4 Dec 2025
Work from @SaynaEbrahimi, myself, and @dilaragoekay, @goolygu, Maks Ovsjanikov, Iva Babukova, @DanielZoran_ , Viorica Patraucean, @joaocarreira , Andrew Zisserman and @dimadamen at @GoogleDeepMind.
Arxiv: arxiv.org/abs/2512.04085
2
4
15
2,432
4 Dec 2025
Human learns from unique data -- everyone's OWN life -- but our visual representations eventually align. In our recent work "Unique Lives, Shared World" @GoogleDeepMind, we train models with "single-life" videos from distinct sources, and study their alignment and generalisation.
10
31
147
13,041
4 Dec 2025
Work from @SaynaEbrahimi, myself, and @dilaragoekay, @goolygu, Maks Ovsjanikov, Iva Babukova, @DanielZoran_ , Viorica Patraucean, @joaocarreira , Andrew Zisserman and @dimadamen at @GoogleDeepMind.
Arxiv: arxiv.org/abs/2512.04085
1
2
13
3,187
2 Dec 2025
Sherry is currently on the industry job market. Highly recommend!!
2 Dec 2025
Excited to share our latest work! Grateful for the guidance from all my collaborators, and special thanks to Tengda for being such an amazing mentor during my internship @GoogleDeepMind 😊
1
1
10
3,219
1 Dec 2025
Human perception is active: we move around to see, and we see with intention. In our latest work "Seeing without Pixels", we find "how you see" (how the camera moves) roughly reveals "what you do" or "what you observe" -- and this connection can be easily learned from data.
2
18
165
21,635
1 Dec 2025
Can you tell which action corresponds to which camera trajectory in the video above? Check out our paper for answers! Work done by our great intern Sherry Xue @sherryx90099597 at @GoogleDeepMind, and with Kristen Grauman, @dimadamen and Andrew Zisserman.
arxiv.org/abs/2511.21681
1
3
13
1,406
1 Dec 2025
Project page for more details and qualitative examples: sites.google.com/view/seeing…
Sherry will be at @NeurIPSConf this week! Catch her to chat more!
Seeing without Pixels
Can you guess which action goes with which camera trajectory?
sites.google.com 6
692
1 Dec 2025
Animated movies can be effortlessly understood by young minds, but appear to be challenging for video-language models, why? The key problem is the huge diversity of animated characters -- their appearance ranges from human-like faces, to cars, fish, blobs, etc.
1
3
13
2,039
1 Dec 2025
A belated post for our ACMMM paper: we recognize and track animated characters for movie understanding tasks. Great work from Zhongrui Gui, also with @JunyuXieArthur @WeidiXie and Andrew Zisserman from @Oxford_VGG .
Project page with code and dataset: robots.ox.ac.uk/~vgg/researc…
1
198