
Your CI says WHAT broke. Testhide says WHY. 8 AI models diagnose every build — root cause, flakiness, log patterns. Self-hosted CI/CD.
Joined May 2026
- Tweets 55
- Following 8
- Followers 4
- Likes 1
6 Photos and videos




Pinned Tweet

May 29
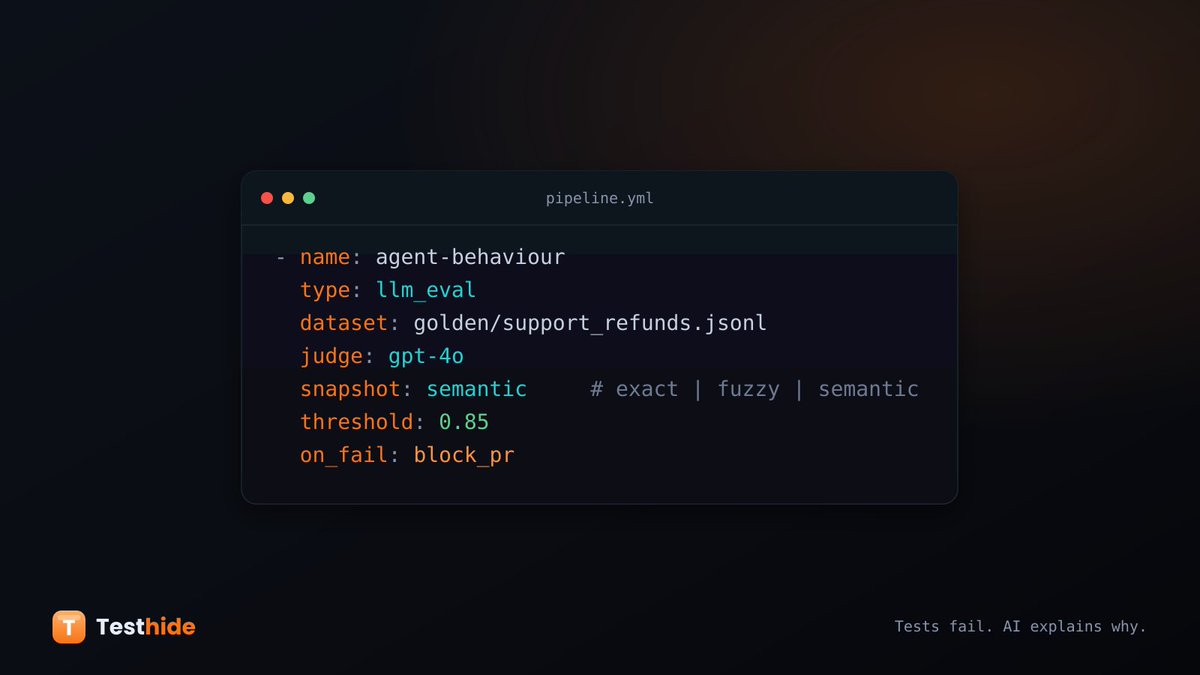
Your AI agent passed 41 unit tests. The eval suite was green. Your teammate merged and went home.
By Monday it was quietly denying refunds it should approve — in ~1 of 20 real conversations. No error. No alarm. Nothing "failed."
Why green CI lies about agents 🧵
1
1
23
Jun 1
Google ran the numbers: 84% of their test failures that flip from pass→fail are flaky — not real bugs.
Flaky tests are the tax almost every CI pays and almost no CI fixes.
What flaky tests actually cost, and how to kill them — a thread 🧵
1
1
1
10
Jun 1
The better question isn't "re-run or mute?" — it's "is this red signal or noise?"
Testhide answers it with a Flakiness Predictor: gradient-boosted trees over 41 features, scoring each failure — its history (top signal: recent fail-rate) build context.
Real regression → block the PR. Noise → smart-quarantine. 👇
1
1
16
Jun 1
Smart-quarantine = the test still runs and reports, it just doesn't gate the merge — so coverage stays, red stays trustworthy. And we watch the model's own drift (PSI) so it doesn't rot.
Not blind rerun. Not raw history. Prediction, in-pipeline, self-hosted.
→ testhide.com
Tests fail. AI explains why.
7
May 31
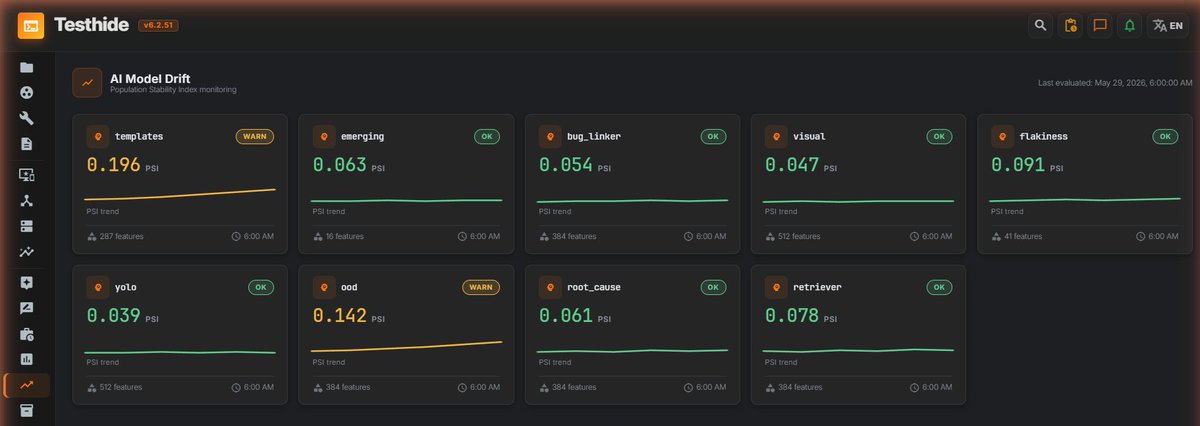
Your CI is green. Your ML models are quietly going wrong anyway.
A model trained on last quarter's data drifts as the real world shifts under it — accuracy decays, retraining never fires, and not one test turns red.
The blind spot almost no CI/CD covers 🧵
1
1
1
15
May 31
Why Testhide is different:
• plain CI (Jenkins, GitHub Actions, TeamCity) → no model monitoring at all
• eval tools (Braintrust, Langfuse) → a separate dashboard, not your pipeline, no per-model input drift or retrain trigger
We run it in-pipeline, per real input, self-hosted.
1
4
May 31
The payoff: a red card is the model that actually drifted — and only that one retrains. No fan-out, no wasted GPU, no silent decay.
Drift monitoring is only as good as the signal you measure. So measure the real one, per model.
Self-hosted, runs daily → testhide.com
Tests fail. AI explains why.
1
15
May 29
Your AI agent passed 41 unit tests. The eval suite was green. Your teammate merged and went home.
By Monday it was quietly denying refunds it should approve — in ~1 of 20 real conversations. No error. No alarm. Nothing "failed."
Why green CI lies about agents 🧵
1
1
23
May 29
But your golden set goes stale the day you freeze it. So the same models keep watching prod.
An OOD detector flags inputs that look like nothing it's seen → you turn that into a fixture → the next PR's eval defends against a failure your users found for you.
The loop closes.
1
6
May 29
Honest results from our own pipeline (no invented logos):
🟢 silently-wrong outputs now blocked at the PR
🟢 2 of our bigger incidents would've been caught earlier by OOD
Eval-in-CI post-deploy monitoring, one system, 100% self-hosted.
docker compose up → testhide.com
Tests fail. AI explains why.
6