
Launch instantly tradeable coins on base for free and earn creator fees.
Joined June 2025
- Tweets 646
- Following 258
- Followers 1,307
- Likes 808
208 Photos and videos















The Cabal retweeted

4h
🐸 27.1% of the pond claimed in under 24 hours.
4,322 lily pads left.
52 hours remaining at 90% discount.
after that — full price.
the pond doesn't wait.
🌿 tobypixelpond.xyz
1
4
8
45
The real question is…. Who cares.
Jun 15

Most people assume $BASE will launch as a normal ERC-20 token.
But what if it doesn’t? 👀
@base has confirmed they’re exploring a network token, but we still don’t know how it will work, how it will be distributed, or what standard it will use.
One possibility:
→ A token built with compliance in mind
Why would Coinbase do that?
→ Easier to work with regulators
→ Better security
→ More attractive for institutions
That’s where B20 could fit in.
Unlike a regular ERC-20 token, B20 can include compliance features like identity verification and transfer controls. This could help Base stay regulation-friendly while making the network more attractive to institutions.
@jessepollak has already said that if Base launches a token, they want to work with regulators.
That could mean future distributions may include some form of verification or KYC.
I’m not saying this will happen for sure..
But remember: the token standard could tell us a lot about Base’s long-term plans, not just the token itself. 🔥
Things are getting clear day by day , be ready for $BASE 🎉

1
46
And I haven’t heard / used a single one.
😂👏


2
3
89
Today is a nice day to get rugged

Today.
June 16.
1
1
1
37
lol shameless tag. Mr. Baldy out here tagging KOLs to help push the newest rug.

.@nikitabier thoughts?
23
#1 coding tool that I never heard of. Industry standard is coderabbit and greptile I know there’s a million AI vibe coded ones spawning but don’t tell me his is a popular one

Claude Code creator:
"100% of our pull requests at Anrtopic are run by Claude Code. 80–90% of code review too.
The feature I’m using the most today is /loops. I’m not prompting Claude anymore - I’m building loops"
in 1-hour interview, Boris reveals his setup, which helps him build the #1 coding tool of this year.
Worth more than a $500 vibe-coding course.
65
No use case openclaw too slow burns too many tokens and too bloated. Hermes I never even bothered looking into just build your own.
If I see another random bloated GitHub repo of 100 random tools I swear I’m gonna crash out
Jun 15

finally looking into openclaw and hermes agent, i feel like a boomer man, i just don't get the use case
40
Yes part of their “take control” so they want more control now there is an unnecessary token standard oh lord.

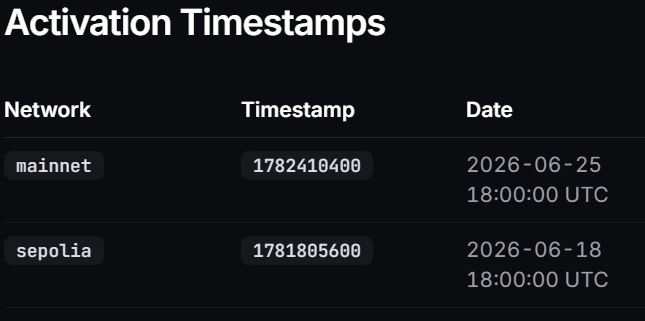
🥳 Base B20 native standard mainnet goes live this month....
Activation Timestamps;
Mainnet—2026-06-25
Sepolia—2026-06-18
Recently Base Docs added the B20 standard to their webpage.
It clearly mentions what B20 is, how it will function, and what the key changes are between B20 and ERC-20.
If you really want to know more, read these docs:
⛓️docs.base.org/base-chain/spe…
1
27
I’m glad they are switching to Deep Seek

JUST IN: Pentagon announces it has transitioned over two-thirds of its daily AI workflows off Anthropic to rival AI vendors.
63


US government banning AI. Now UK government banning social media. Why all the bans? Yall need to chill and relax…
8
The Cabal retweeted
Jun 15
🐸 CALLING ALL TOADS — TOBY PIXEL POND IS LIVE
tobypixelpond.xyz
A permanent on-chain canvas just opened on Base.
5,929 lily pads. 77 × 77. One canvas. Forever.
Upload your picture. Claim your spot. Become part of the monument.
@base @toadgod1017 @Tobyonbase
3
11
21
361

Jun 15
Love this idea. One of the best things I’ve done to my automatic code review patch pipeline is to add in the prompts that less diff is better. That instantly made a huge difference. You don’t really need a dedicated sub agent for that, but it is an option.
Jun 14

A dev got so frustrated watching his AI agent write 500 lines for a 5-line problem that he built a fix.
He called it Ponytail. Named after the guy every team has - long ponytail, oval glasses, been there longer than the version control. You show him fifty lines; he looks at them, says nothing, and replaces them with one.
Now your agent does the same. Before writing anything, it looks for a reason not to.
80-94% less code. 47-77% cheaper. 3-6x faster.
The best code is the code you never wrote.
GitHub Repo: github.com/DietrichGebert/po…

1
23
Jun 15
Big boss Musk coming in hot. Love it.

This censorship law is a wolf in sheep’s clothing. The real goal is to enable the UK government to track everyone.
13
Jun 15
I have been using @MistralAI agents for years they have super cheap models and very nice API.
Happy to see some news on an even better model, will need to test it.
Jun 15

While Anthropic is fighting with the US government, Europe quietly built the most powerful AI in the world
Mistral, the best EU model, completely dominated competition in the most crucial benchmark
We must now ban access to Mistral for all Americans
It's just too powerful. It's a matter of national EU security

29
Jun 14
You could just run open code with some steps to let it read memory files with a cheap model and retrieve it.
Combine with Obsidian QMD and local models to do retrieval it’s already pretty good
Jun 14

MIT just made every AI company's billion dollar bet look embarrassing.
They solved AI memory. Not by building a bigger brain. By teaching it how to read.
The paper dropped on December 31, 2025. Three MIT CSAIL researchers. One idea so obvious it hurts. And a result that makes five years of context window arms racing look like the wrong war entirely.
Here is the problem nobody solved.
Every AI model on the planet has a hard ceiling. A context window. The maximum amount of text it can hold in working memory at once. Cross that line and something ugly happens — something researchers have a clinical name for.
Context rot.
The more you pack into an AI's context, the worse it performs on everything already inside it. Facts blur. Information buried in the middle vanishes. The model does not become more capable as you feed it more. It becomes more confused. You give it your entire codebase and it forgets what it read three files ago. You hand it a 500-page legal document and it loses the clause from page 12 by the time it reaches page 400.
So the industry built a workaround. RAG. Retrieval Augmented Generation. Chop the document into chunks. Store them in a database. Retrieve the relevant ones when needed.
It was always a compromise dressed up as a solution.
The retriever guesses which chunks matter before the AI has read anything. If it guesses wrong — and it does, constantly — the AI never sees the information it needed. The act of chunking destroys every relationship between distant paragraphs. The full picture gets shredded into fragments that the AI then tries to reassemble blindfolded.
Two bad options. One broken industry. Three MIT researchers and a deadline of December 31st.
Here is what they built.
Stop putting the document in the AI's memory at all.
That is the entire idea. That is the breakthrough. Store the document as a Python variable outside the AI's context window entirely. Tell the AI the variable exists and how big it is. Then get out of the way.
When you ask a question, the AI does not try to remember anything. It behaves like a human expert dropped into a library with a computer. It writes code. It searches the document with regular expressions. It slices to the exact section it needs. It scans the structure. It navigates. It finds precisely what is relevant and pulls only that into its active window.
Then it does something that makes this recursive.
When the AI finds relevant material, it spawns smaller sub-AI instances to read and analyze those sections in parallel. Each one focused. Each one fast. Each one reporting back. The root AI synthesizes everything and produces an answer.
No summarization. No deletion. No information loss. No decay. Every byte of the original document remains intact, accessible, and queryable for as long as you need it.
Now here are the numbers.
Standard frontier models on the hardest long-context reasoning benchmarks: scores near zero. Complete collapse. GPT-5 on a benchmark requiring it to track complex code history beyond 75,000 tokens — could not solve even 10% of problems.
RLMs on the same benchmarks: solved them. Dramatically. Double-digit percentage gains over every alternative approach. Successfully handling inputs up to 10 million tokens — 100 times beyond a model's native context window.
Cost per query: comparable to or cheaper than standard massive context calls.
Read that again. One hundred times the context. Better answers. Same price.
The timeline of the arms race makes this sting harder. GPT-3 in 2020: 4,000 tokens. GPT-4: 32,000. Claude 3: 200,000. Gemini: 1 million. Gemini 2: 2 million. Every generation, every company, billions of dollars spent, all betting on the same assumption.
More context equals better performance.
MIT just proved that assumption was wrong the entire time.
Not slightly wrong. Fundamentally wrong. The entire premise of the last five years of context window research — that the solution to AI memory was a bigger window — was the wrong answer to the wrong question.
The right question was never how much can you force an AI to hold in its head.
It was whether you could teach an AI to know where to look.
A human expert handed a 10,000-page archive does not read all 10,000 pages before answering your question. They navigate. They search. They find the relevant section, read it deeply, and synthesize the answer.
RLMs are the first AI architecture that works the same way.
The code is open source. On GitHub right now. Free. No license fees. No API costs. Drop it in as a replacement for your existing LLM API calls and your application does not even notice the difference — except that it suddenly works on inputs it used to fail on entirely.
Prime Intellect — one of the leading AI research labs in the space — has already called RLMs a major research focus and described what comes next: teaching models to manage their own context through reinforcement learning, enabling agents to solve tasks spanning not hours, but weeks and months.
The context window wars are over.
MIT won them by walking away from the battlefield.
Source: Zhang, Kraska, Khattab · MIT CSAIL · arXiv:2512.24601
Paper: arxiv.org/abs/2512.24601
GitHub: github.com/alexzhang13/rlm
22
Jun 14
Great stack.
I prefer grok beta cli and a custom PR review patch agent stack.
Also using deep seek v4 pro for the main brain which is a replacement for hermes. Modeled it like a real brain with input coming from sensors and outputting actions / commands to motor neurons aka sub agents.
Self evolving agents are being built now.

If you have:
Hermes Agent
Claude Code & Codex Handoffs
Obsidian QMD Memory System
Run Agentic Loops
Fleet Tailscale Mesh
Cron Jobs Kanban Board
Agentic Workflows
Congrats you are the top 1% of the AI god stack
1
3
202