
Rεsεαrch Sciεητisτ @GoogleDeepMind. I ∈ Optimization ∩ Machine Learning. Here to discuss research 🤓. Like heavy music🤘.Origin=🇮🇷 Citizen=🇺🇸.
Joined December 2010
- Tweets 1,380
- Following 786
- Followers 6,453
- Likes 5,196
123 Photos and videos












Hossein Mobahi retweeted

We introduce a method for training RNNs that is time-parallel and does not suffer from vanishing/exploding gradients.
Key idea is to decouple learning 1) what should be remembered (can be done without recurrence) and 2) how to update memory (can be one-step supervised by #1).
Jun 7

We never really knew how to train nonlinear RNNs well… BPTT struggled with vanishing grads (no long-range memory) and sequential rollout (hard to parallelizable).
What if instead an oracle told us the optimal memory state m_t at each step? Then the RNN could do one-step supervised learning on (m_t, x_{t 1}) → m_{t 1} labels.
We call this Supervised Memory Training (SMT): a replacement for BPTT that trains RNNs without unrolling them. SMT is time-parallelizable and solves vanishing gradients.
Website: akarshkumar.com/smt/
arXiv: arxiv.org/abs/2606.06479

2
22
226
28,936
The end of an era. Dimitri Bertsekas, a pioneer of mathematical optimization, has passed away. So many of us relied on his textbooks to get through graduate school. His work shaped the minds of a generation.
1
29
192
10,904
Hossein Mobahi retweeted

May 29
🚨 Postdoc opening in my group at Johns Hopkins on min-max optimization, ML/AI & large-scale RL.
Apply by June 15 for full consideration: apply.interfolio.com/184958
I’ll be at #SIAMOP26 in Edinburgh next week!
Please reach out, happy to chat!
@HopkinsDSAI, @JohnsHopkinsAMS
6
18
4,928

May 10
Bidding on my #NeurIPS AC batch today I noticed two submissions proposing a method with the exact same name, and reshuffled title words, and reworded abstract. Looks like a deliberate near duplicate submission to boost acceptance chances. Heads up ACs and reviewers.
@NeurIPSConf
8
7
196
22,874
Hossein Mobahi retweeted

1/ We found that deep sequence models memorize atomic facts "geometrically" -- not as an associative lookup table as often imagined.
This opens up practical questions on reasoning/memory/discovery, and also poses a theoretical "memorization puzzle."
58
244
1,503
92,261
Hossein Mobahi retweeted

1/ New paper! "Wait, Wait, Wait… Why Do Reasoning Models Loop?"
Under greedy/low-temp decoding, reasoning LLMs get stuck in loops repeating themselves, wasting test-time compute and sometimes never terminating!
We study why this🔁 happens and why increasing temp is a band-aid

25
86
756
105,521
Hossein Mobahi retweeted
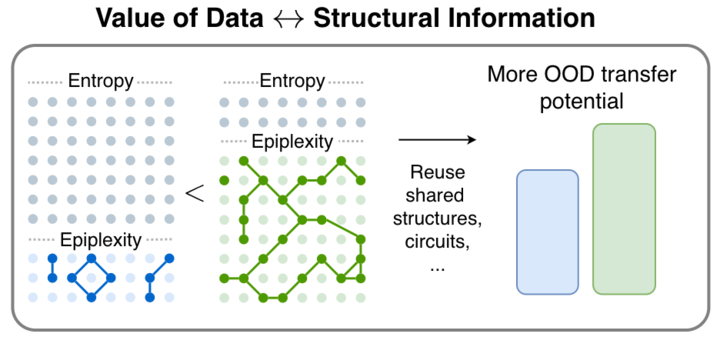
We introduce epiplexity, a new measure of information that provides a foundation for how to select, generate, or transform data for learning systems. We have been working on this for almost 2 years, and I cannot contain my excitement! 1/7
Jan 7

1/🧵 We are very excited to release our new paper! From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence
arxiv.org/abs/2601.03220
with amazing team @ShikaiQiu @yidingjiang @Pavel_Izmailov @zicokolter @andrewgwils
34
189
1,259
163,594
Hossein Mobahi retweeted

31 Dec 2025
Continuing Tutorial II for Physics of Language Models.
We often trust large-scale results simply because they are large; but once noise is removed, the synthetic pretrain playground starts to push back — hard!
The second video (Part 4.1b, 90 minutes) makes this pushback concrete.
From it, I derive 20 architectural principles, organized into 12 result blocks.
Two highlights that consistently surprise even experienced readers:
Result 2.1 (new):
"Why Canon layers actually work."
Not because of multi-token attention — that explanation only applies to the first layer.
The real mechanism is how Canon reshapes hierarchical learning across depth.
Result 11:
"Why linear models reason 4× shallower than Transformers."
This has nothing to do with memory size —
it is a structural failure shared by nearly all linear architectures.
In Result 12, I show which of these principles already emerge at academic-scale pretraining (1.3B / 100B) —
with orders-of-magnitude lower cost and far cleaner signals than many real-life large-scale runs.
The remaining principles do not disappear; they only emerge when scaling to 8B / 1T, which I will show in the third video (Part 4.2).
⏮️ Previous: Part 4.1a — methodology & playground design
▶️ This: Part 4.1b — architectural principles from the playground
🔜 Next: Part 4.2 — when the playground reshapes real-life pretraining

ALT What Emerges from the Playground — Canon Layers & Architectural Principles
13
98
707
187,554
Hossein Mobahi retweeted

5 Dec 2025
I'm hiring a Student Researcher to work on scaling laws at Google DeepMind! Project is for 16 weeks, starting spring/summer '26, in-person in SF (pic from the amazing office). If you're interested, fill out this form: forms.gle/MsgPfJumTLLobNtB7

18
69
751
73,857
Hossein Mobahi retweeted

16 Nov 2025
Don't let people underestimate you. I remember interviewing for a postdoc at an industry lab, where I introduced spectral mixture kernels. I was told my work was "NIPS-y". It wasn't a compliment and I didn't get the position. 10 years later I was asked to autograph that paper.
7
13
517
49,288
12 Nov 2025
🚨Intern Hiring🚨
Join Peter Bartlett and me at @GoogleDeepMind in Mountain View to study hierarchical learning in deep networks. Ideal for PhD students with a strong background in ML, optimization, linear algebra, and Python (JAX preferred). Apply here docs.google.com/forms/d/1dXZ…
7
31
328
27,972
6 Nov 2025
An exciting moment for AI in math! A new paper by a team of mathematicians, including Terence Tao tackled 67 pure math problems and in several cases found solutions that improved on the best-known human results.
arxiv.org/abs/2511.02864
1
1
8
1,312
Hossein Mobahi retweeted

23 Oct 2025
I was impacted by the Meta Superintelligence Labs layoffs yesterday
I’m an AI researcher passionate about training large language models to be both more capable and safer. I’ve worked R&D of Llama Guard, Meta’s multimodal LLM safety guardrail, and on continued pre-training, post-training, and preference alignment of LLMs for custom use cases. Seeking new opportunities in LLM training and safety research
If you know of teams working on these challenges, please reach out
41
40
474
69,339
Hossein Mobahi retweeted

23 Oct 2025
After 7 years at FAIR, I've been affected by the recent AI layoffs. If you are interested in robotics learning, let's chat :)
61
53
1,011
135,776
Hossein Mobahi retweeted

28 May 2025
As promised, we put on Arxiv the proof we did with Gemini. arxiv.org/pdf/2505.20219
This shows that the Polyak stepsize not only will not reach the optimum, but it can cycle, when used without the knowledge of f*.
Gemini failed when prompted directly ("Find an example where the best and average iterate do not converge"), but it worked when I gave more specific instructions ("Find a function and an initial point where it generates a cycle of length 3 and none of the iterates nor their average converge to the minimum").
As you can see, the proof is not difficult, but it is very creative: Rewriting the update with trigonometric functions and using their doubling formulas to show the cycle is not something I would have thought!

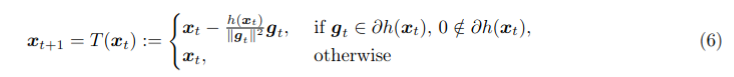
22 Apr 2025

This is a turning point: I just proved a complex math result useful for my research using an LLM.
I am not sure if I should be happy or scared...
6
60
417
69,967
Hossein Mobahi retweeted

21 Apr 2025
🚀 Introducing Data Agents— generate accurate, reasoning-based AI benchmarks from your own data in minutes!
⚡ With Data Agents, we’ve created 100 benchmarks with 100K samples using docs from tools like React, PyTorch, Kubernetes, LangChain, and more.
📂 All benchmarks are now live on RELAI.ai and HuggingFace: huggingface.co/relai-ai
📊 Coming next: Our LLM leaderboard — see how popular models perform across these benchmarks.
📅 Want your own custom AI benchmarks? Book a demo here: calendly.com/d/crx2-k7b-pcm
More Details 👇

6
30
122
29,736
10 Apr 2025
It is time! Applications for the global @Google PhD Fellowship Program are NOW open.
11 Mar 2025

Applications for the global @Google PhD Fellowship Program opens on Apr 10th. Fellowships support graduate students doing exceptional and innovative research in computer science and related fields as they pursue their PhD. Learn more and apply by May 15 at goo.gle/phdfellowship
1
4
57
14,102
11 Mar 2025
Applications for the global @Google PhD Fellowship Program opens on Apr 10th. Fellowships support graduate students doing exceptional and innovative research in computer science and related fields as they pursue their PhD. Learn more and apply by May 15 at goo.gle/phdfellowship
1
40
212
38,350
5 Feb 2025
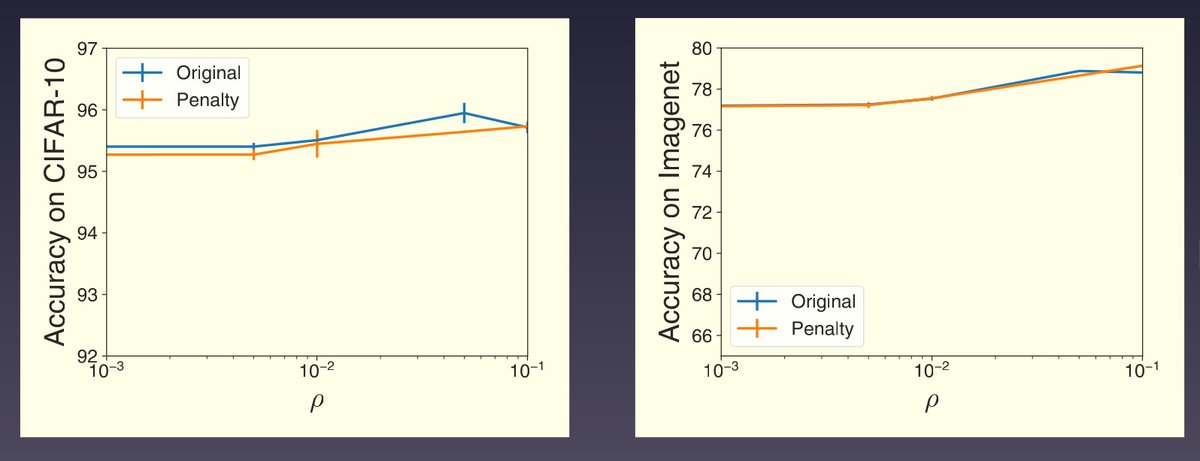
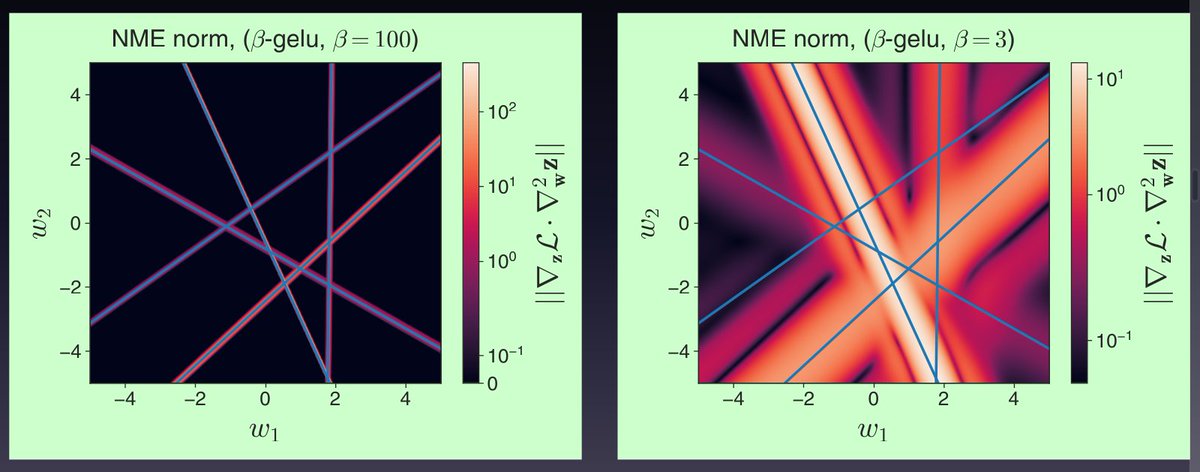
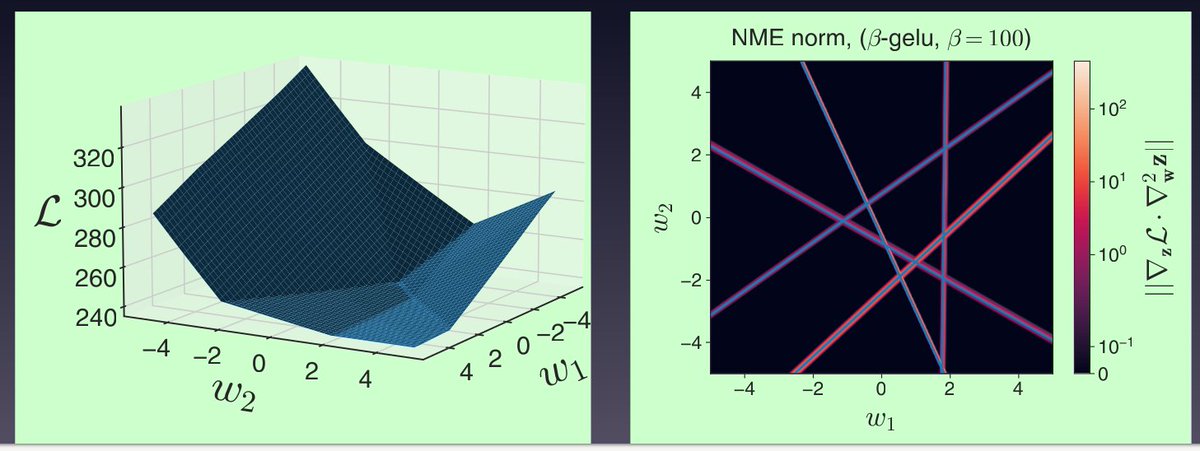
(1/2) Ever wondered why Sharpness-Aware Minimization (SAM) yields greater generalization gains in vision than in NLP? I'll discuss this at @UCLA CS-201 seminar February 18th, relating it to the balance of SAM's impact on logit statistics vs model geometry.
cs.ucla.edu/upcoming-events/…
1
10
57
6,113
5 Feb 2025
(2/2) Not at UCLA but interested in this work? Check arxiv.org/abs/2502.02407. Thanks to our fantastic intern @unregularized (soon to return full-time!) for leading this project, along with collaborators @ynd and Atish. Thanks to my UCLA host @baharanm for the seminar invitation!
2
1
20
2,252