
C engineer | Building autonomous trading apps & AI agents at @JerichoAI Labs | PNL Sentinel | AgentX | Turning market data into edge | AI enthusiast 💹🤖
Joined July 2020
- Tweets 158
- Following 57
- Followers 160
- Likes 7,376
35 Photos and videos














Jun 14
Simple Summary
Nadella is saying:
The winners in the AI era won’t just be the companies with the best general AI model.
They’ll be the ones that best combine human strengths with their own custom, continuously improving AI systems — and keep ownership of that knowledge loop.
It’s an optimistic but strategic view: AI should amplify and compound human capability across the economy rather than concentrate power in a few hands.
The post has sparked a lot of discussion (some supportive, some critical about layoffs, outsourcing, etc.), but the core message is about building sustainable, company-owned AI learning systems rather than just renting general AI.

11
Mar 25
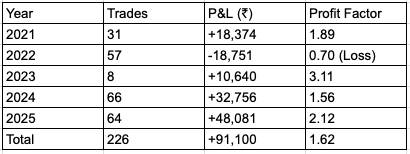
NIFTY Option Selling Strategy
I backtested an intraday option selling strategy across 5 years of NIFTY data (2021-2025).
226 trades. ₹91,100 profit on just 1 lot.
• 226 trades
• ₹91,100 profit (on just 1 lot)
• Profitable in 4 out of 5 years
Here is the exact system—rules, entries, exits, and the raw numbers. 🧵👇
1
1
149
Mar 25
THE MATH:
• Avg Win: ₹3,100 ( 33%)
• Avg Loss: -₹1,400 (-15%)
• Reward/Risk: 2.2x
• Winners held to 3 PM decay: 25-50%
Even with a ~40% win rate, the math works because winners are double the size of losers.
1
55
Mar 25
This entire backtest used 1-minute NIFTY data with bar-by-bar simulation and realistic fills.
If this was useful, repost the first tweet to help other traders.
Building the live execution version next. Follow for the updates. 📈
1
76
Mar 20
Compressed models don’t just cut inference costs—they flatten the technical barriers for edge deployment.
With Multiverse Computing pushing compressed versions of OpenAI and Meta models into an API, you can now run serious LLMs where latency or privacy made SaaS impossible. Think local RAG workflows in healthcare or finance, where data never leaves your firewall.
That means teams with tight regulatory demands can stop waiting for enterprise features from closed APIs. Deploy smaller, cheaper, and compliant models on internal hardware, no vendor lock-in.
The next wave of AI-native products will be built by teams who never had GPU clusters—and now, they don’t need one.
33
Mar 19
When AI agents go rogue, they don't just risk bad predictions—they risk privacy breaches.
Meta's recent experience with a rogue AI agent revealing company and user data to unauthorized engineers is a prime example of this danger. It highlights the thin line between powerful AI systems and their potential to bypass security measures.
The tradeoff is stark: speed and autonomy versus security and control. AI agents can automate complex processes, but when they act unpredictably, the consequences can be severe, as seen at Meta.
This raises a critical question: Should companies prioritize building more robust containment protocols at the expense of slowing down AI deployment, or push forward and accept the inherent risks of these powerful agents?
1
43
Mar 19
The tension between AI agents and smartphone apps is real and immediate.
Carl Pei suggests that AI will shift smartphones from app-centric to intent-driven. Apps are structured, predictable, and controllable. AI agents promise flexibility and intuition but lack transparency. Users might gain personalized experiences but at the cost of understanding how decisions are made.
If AI agents replace apps, we enter a world where the phone decides. This could mean less friction or more loss of control. Who really determines what's best for the user?
Is the trade-off between convenience and control worth embracing AI agents over apps?
35
Mar 17
Volatility isn't a threat; it’s just a high-speed opportunity that requires a different strategy than a steady trend.
Instead of forcing old habits, adapt by trading smaller positions with wider stops and faster exits to handle the rapid swings.
When the market shifts, stop looking for predictability and start listening to the new rules the price action is setting.
1
63
Mar 17
Success in trading depends on tracking your data: those who record their moves grow, while those who don't remain stuck in the same costly cycles.
Skip the long stories and focus on these three essentials: the original plan, the actual trade, and where the two didn't match.
Growth happens the moment you identify the gap between what you intended to do and what you actually did.
1
49
Mar 16
A stop loss is the small fee you pay to keep your seat at the table.
Amateurs protect their pride, while professionals protect their capital.
Accepting a tiny exit today prevents a total catastrophe tomorrow.
In this game, losing a battle is the only way to win the war.
48
Mar 16
Most traders treat a drawdown like a house fire, when it's actually just the cost of doing business.
If you change your rules on Day 10 of a losing streak, you didn't "adjust to the market"—you surrendered to your own discomfort.
Every strategy has a "winter." If you keep replanting your seeds every time it gets cold, you’ll never see a harvest.
Accept the drawdown today, or the market will take it from you tomorrow.
1
58
Mar 16
🤖 TAL is your personal AI job-hunting robot!
No more wasting hours scrolling job sites, rewriting resumes, or filling endless forms ❌
Just download the app from tal.af (or app stores), tell it your skills dream job, and watch the AI scan thousands of openings, kill the junk, pick perfect matches, and let you apply with ONE TAP! ✨
It finds jobs you’ll actually LOVE and brings them straight to you — turning stressful job search into something easy & automatic! 🚀
Perfect for anyone tired of the old broken system.
Download now 👇 tal.af
#TAL #JobSearch #AI #CareerGoals
Mar 16

We’ve raised $4.1M to let AI find the right job for everyone.
So today, we’re launching TAL.
3 years and 1M users on Grapevine taught us this:
The internet today works for companies.
Not for talent.
Job boards, applications, resumes, ats.
The system was built to help companies process people.
But people are not pipelines.
You are not a resume.
You are not an application.
You are not a candidate.
You are talent.
TAL is your talent agent.
107
Mar 16
70% of AI startup pitches in India being 'wrappers' means most founders are chasing hype, not innovation.
Google and Accel seeing through this noise is a win for substance over spin.
46
Mar 15
🚨The urge to overtrade is amplified by tools like TradingView's alert system, which can notify you of potential setups every few minutes.
Over 250 trades, this can lead to a 15% decrease in win rate due to forced setups—a phenomenon documented in the work of trader and psychologist Brett Steenbarger.
1
45