
Frictionless #CX & revenue growth thru #AppliedAI, #CDP/#MDM as CEO @YourBrainTrust, #DataExchanges @EdgeAutonomy, Board @theARFoundation tweets=me
Joined March 2008
- Tweets 40,059
- Following 3,410
- Followers 8,752
- Likes 41,065
1,868 Photos and videos

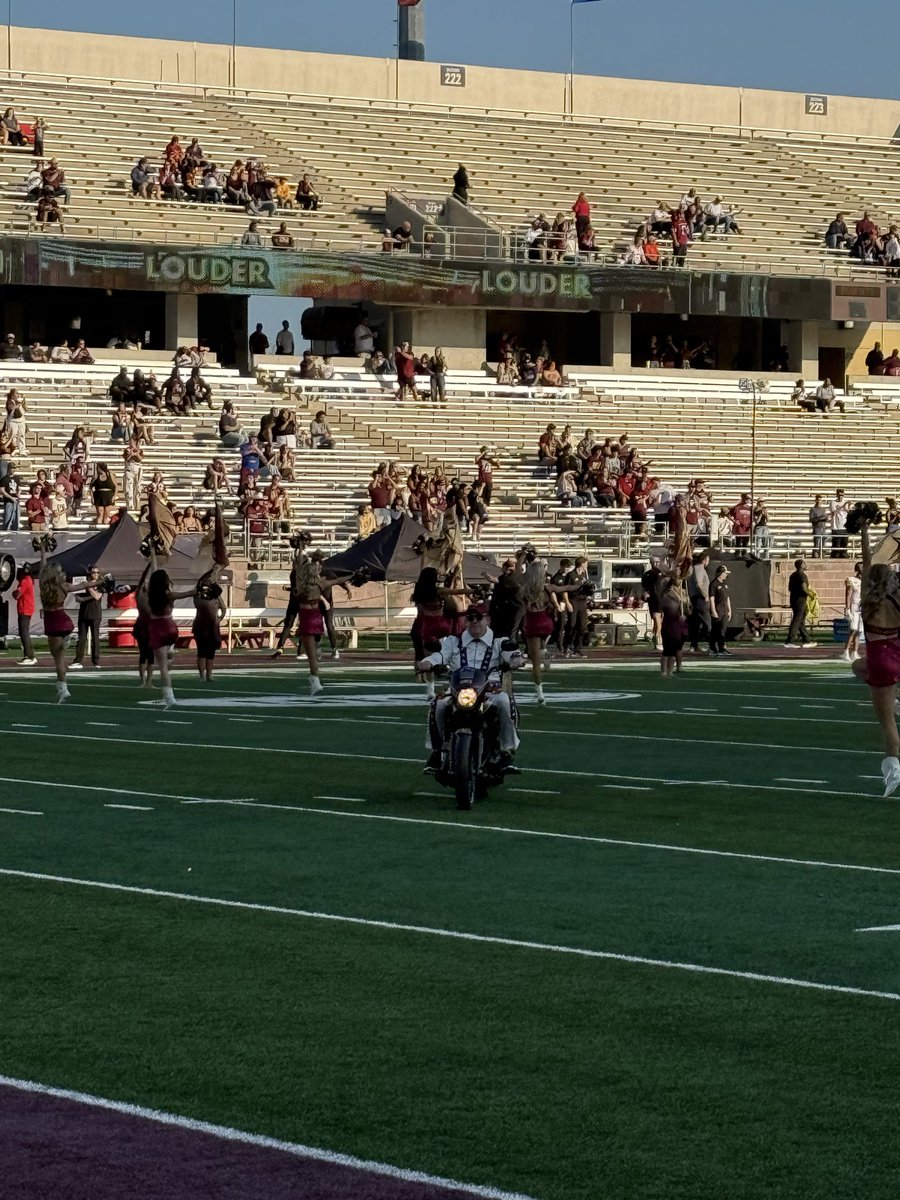








Pinned Tweet

4 Oct 2021
Today is a shining example for brands that operate on rented land such as Facebook.
The time has passed for marketers to establish a direct relationship with customers, current and prospective.
Onward.
7
9
65
Tim Hayden retweeted

NATIONAL CHAMPION. AGAIN. 👑😼🥇
ELISABET RUNARSDOTTIR IS YOUR NCAA HAMMER THROW NATIONAL CHAMPION!
A MASSIVE lifetime-best throw of 73.19m secures her second career national title and etches her name among the greatest athletes in Texas State history.
#EatEmUp

5
57
217
34,285
Tim Hayden retweeted

May 25
INSTEAD OF WATCHING AN HOUR OF NETFLIX TONIGHT.
This 60-minute Cambridge lecture by Demis Hassabis will teach you more about the future of AI than most people will learn in the next 5 years.
Bookmark it and give it an hour, no matter what.
40
636
2,896
454,561


May 22
Thanks to @jowyang, we in "early days" of applying Polsia to some workflows. Congrats, @Bencera.
I'm almost a fan.

Polsia just raised $30M at a $250M valuation.
Approaching $10M annual run rate.
One Founder AI. Zero employees.
Polsia runs companies autonomously.
It also ran its own fundraising.
I just showed up for signatures.
115
May 18
That's @YourBrainTrust

Now running ops for a consultancy that helps Fortune 500s own their AI instead of renting it. Sovereign data is the next enterprise battleground and they saw it coming years ago.
2
65
Tim Hayden retweeted

4
44
191
8,339
Tim Hayden retweeted

May 5
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
1,489
2,870
22,980
12,819,426
Apr 12
Verifying myself: I am timhayden on Keybase.io. hJXbt_rI9XMwQB4L1zrrnUKXZjZQfqRihjK8 / keybase.io/timhayden/sigs/hJ…
1
89
Tim Hayden retweeted

Apr 8
Whet a night in the new Irvine-Rasmussen Ballpark! This team is fun to compete with! See you all again tomorrow night! Let’s go!

2
13
122
6,209
Tim Hayden retweeted

Apr 2
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
2,887
7,228
59,757
21,351,227
Feb 12
Go, Cats, Go West!

Your wait is over 🤠
Our inaugural Pac-12 schedule is here!
#EatEmUp | #BackThePac
1
7
385
Tim Hayden retweeted

Your wait is over 🤠
Our inaugural Pac-12 schedule is here!
#EatEmUp | #BackThePac
42
131
861
111,761

Tim Hayden retweeted

In this episode of The AI Hat Podcast, learn about the importance of having a data strategy, and how to start, before implementing AI, with @thetimhayden theaihat.com/why-your-smb-ne…
1
2
108
Tim Hayden retweeted

25 Nov 2025
#TXST QB Brad “Birthday Boy” Jackson addressing the media ahead of the Bobcats’ regular season finale against South Alabama this Saturday:
6
49
7,290
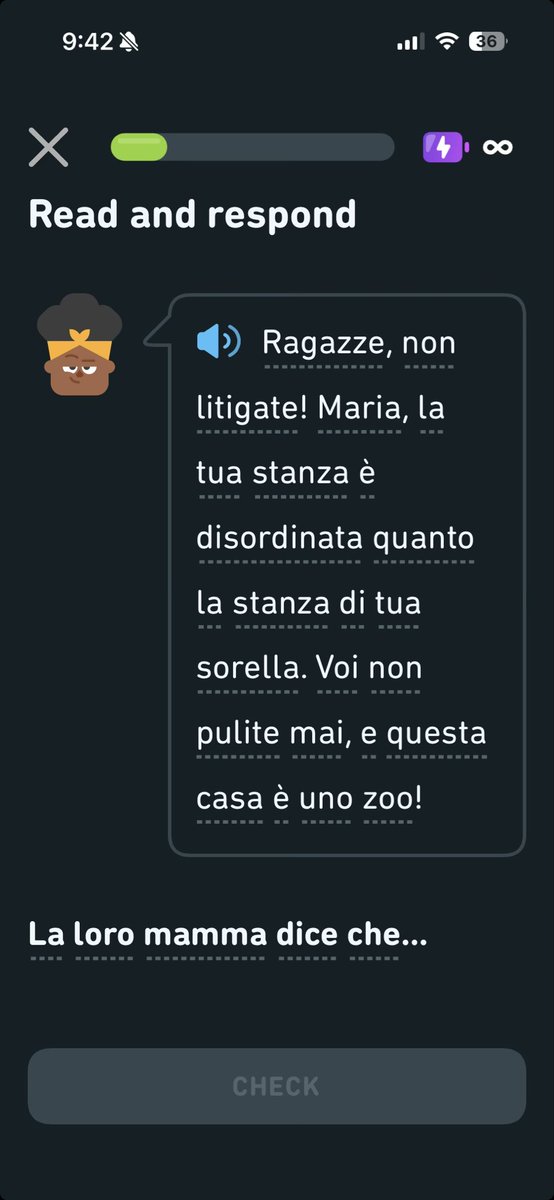
17 Nov 2025
@duolingo how do I get support with Section 3, Unit 13 of Italian? It freezes every time I get to the “Read and Respond”
1
1
75
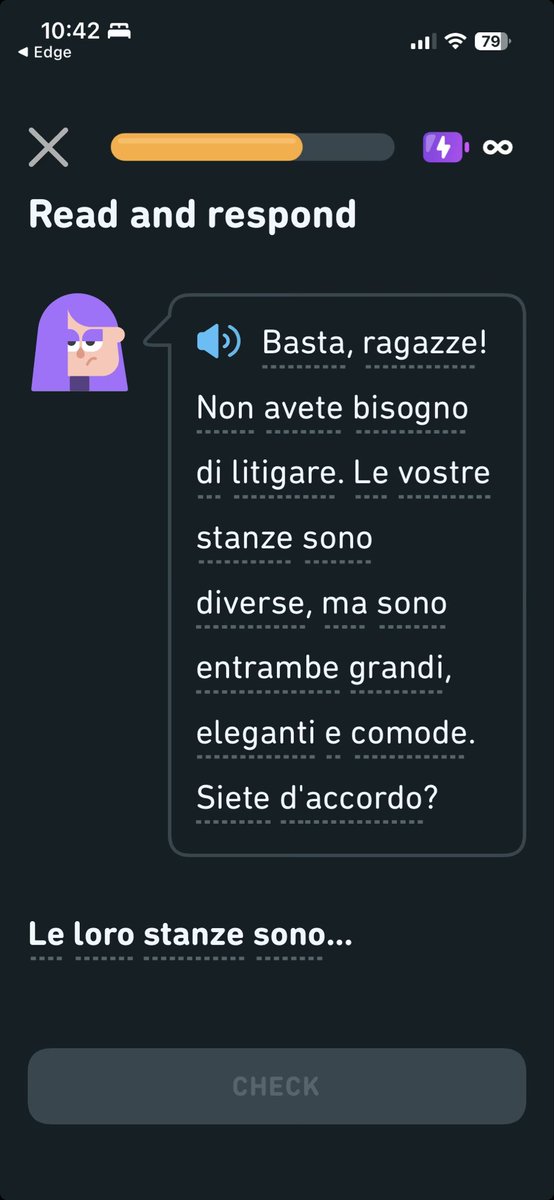
19 Nov 2025
@duolingo new day, after working around the issue via my browser, I went back to the app and got this far before it once again prohibited me from scrolling to the answer choices.
1
64
Tim Hayden retweeted

16 Nov 2025
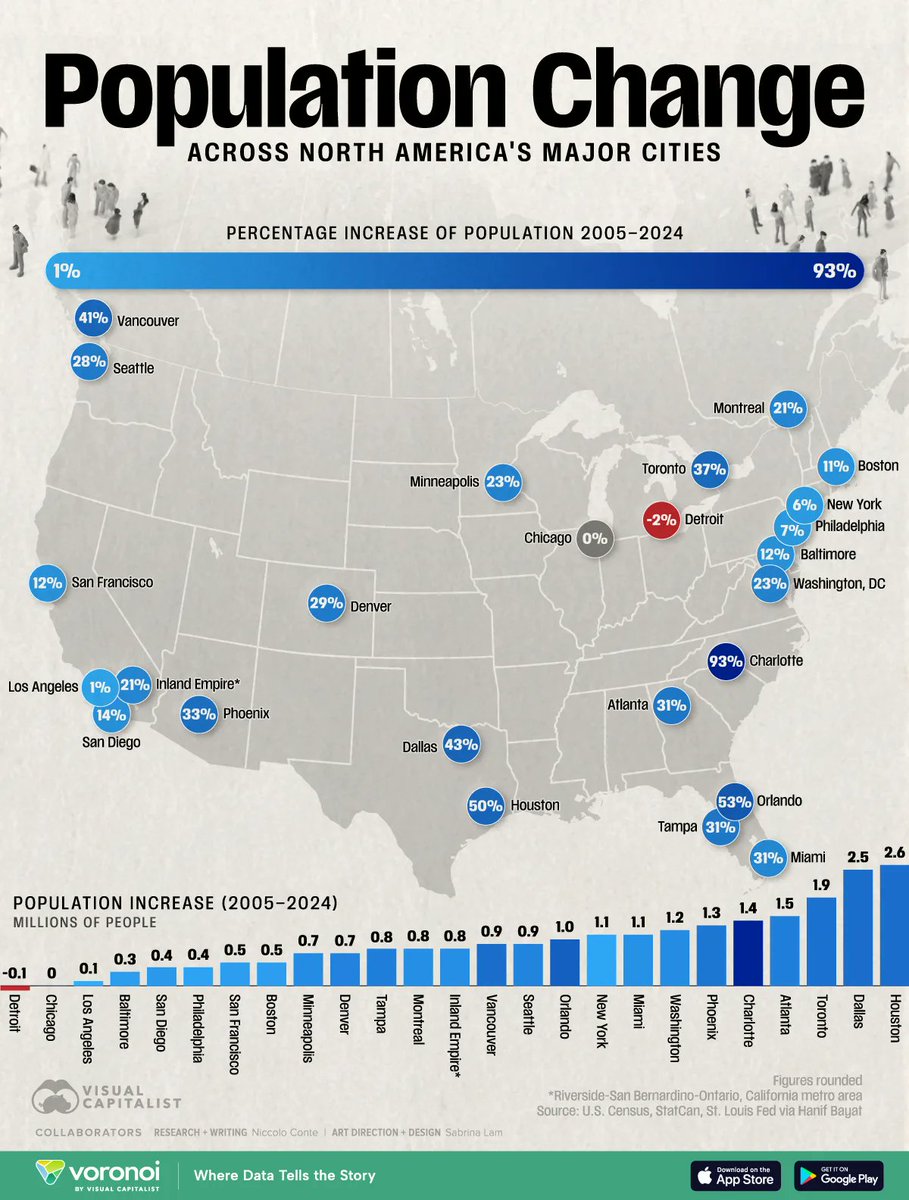
They left off Austin 🤔
2005 the metro was 1.2M & by end of 2024 it’s 2.5M.
The 1.3M jump puts us 6th in absolute growth, & the 104% increase would rank 1st in percentage growth by 10 points.
Stop sleeping on the frontier city.
73
77
753
583,828
17 Nov 2025
One week from last night, I can’t wait to lead @TXSTATEFOOTBALL on to the field for the game against @LouisianaMonroe.
#GoCatsGo
#EatEmUpCats
1
3
254