
On X we surface the AI research that matters and explain the ideas behind it. In the newsletter, we connect the dots between AI’s past, present, and future ⬇️
Joined June 2020
- Tweets 19,470
- Following 9,297
- Followers 85,932
- Likes 13,418
7,571 Photos and videos










Turing Post retweeted
Hermes Agent updates (the most important ones)
• Hermes turned from a “CLI agent” into a full desktop app.
• Hermes overtook OpenClaw on OpenRouter
• It became faster and more modulAR
• Anthropic / HERMES.md billing incident
• Some developers moved to Hermes because of OpenClaw vulnerabilities
We’ve updated our Hermes article with the latest news – read the whole story is in one place: turingpost.com/p/hermes
3
5
15
1,094
Turing Post retweeted

Jun 12
3 layers of AI engineering:
• Skill engineering – the newest one
This is about giving agents reusable skills – mini-procedures they can discover, apply, improve, version, and reuse across tasks.
→ Skill tells the agent what to do and how to do it again
• Context engineering – creating basic context a model/agent should know and access when it acts or responds
• Prompt engineering – writing a good instruction for a specific request. Used to make one task better right now
Skill engineering is especially important today as agents turn into longer-running systems.
And now the main question is: how to optimize skills?
Here is a guide to 3 fresh methods – SkillOpt, SkillOps, and SkillMOO – for making skills self-optimize inside your systems. Check it out! turingpost.com/p/from-prompt…
6
15
64
3,762
Turing Post retweeted
Jun 7
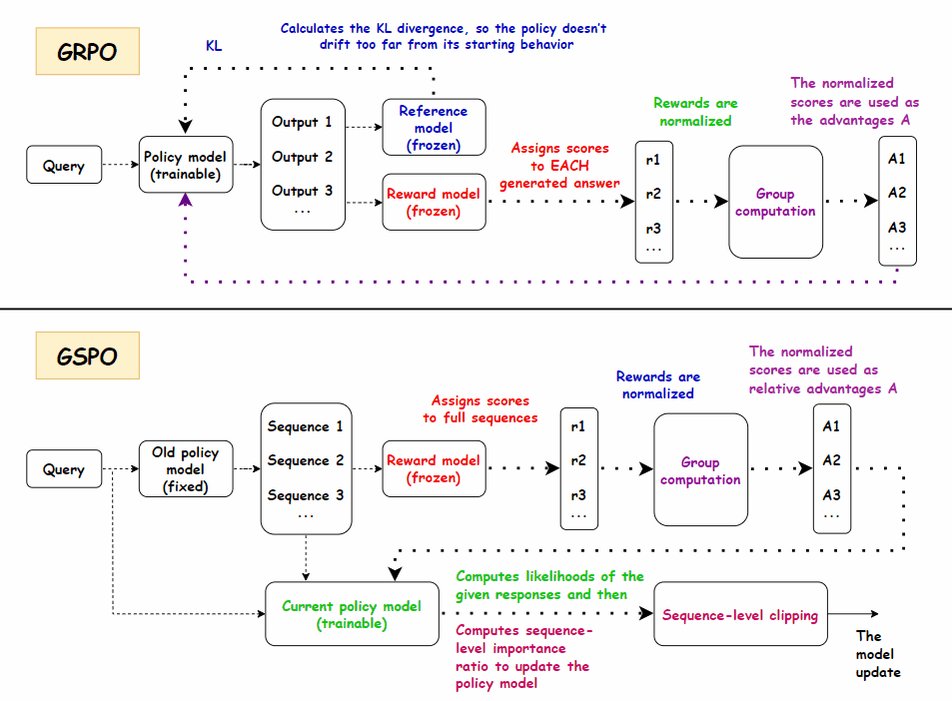
15 Policy Optimization and Preference Optimization techniques important in 2026
▪️ GRPO
▪️ DPO
▪️ REINFORCE
▪️ DAPO (Dynamic sAmpling)
▪️ Dr. GRPO
▪️ GSPO (Group Sequence)
▪️ DHPO (Dynamic Hybrid)
▪️ EP-GRPO (Entropy-Progress Aligned)
▪️ TR-GRPO (Token-Regulated)
▪️ DPPO (Dynamic Pruning)
▪️ ARPO (Agentic Reinforced)
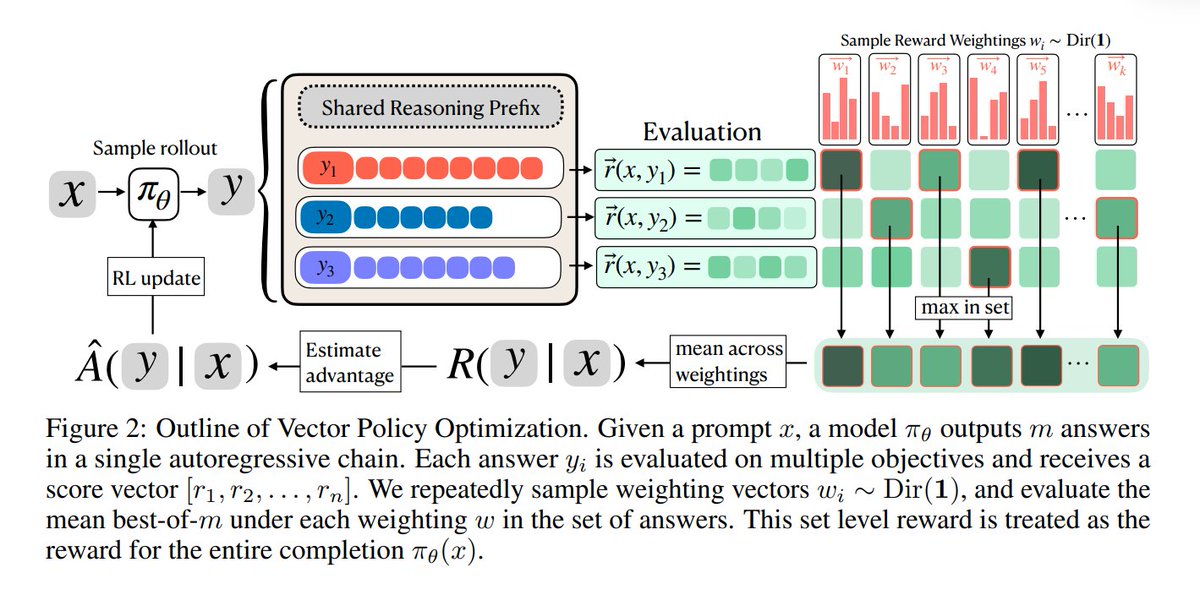
▪️ VPO (Vector PO)
▪️ InSPO (Intrinsic Self-reflective Preference Optimization)
▪️ TI-DPO (Token-Importance Guided DPO)
▪️ RAPPO (Reliable Alignment for Preference PO)
Save this list as a quick reference for the most relevant policy optimization methods in 2026: turingpost.com/p/reasoning-r…
14
69
351
18,810
Turing Post retweeted
Jun 8
OpenProse – an open-source "logical English" language that turns your agentic workflows into reusable agent programs.
It runs inside the coding agent you already use: Claude Code, Codex, OpenCode, Hermes, Pi – and gives it a structured contract to follow.
→ The key idea – the coding agent becomes the "compiler".
This delivers:
- Less babysitting of multi-agent coding sessions
- Reviewable .prose.md programs instead of disposable prompts
- Explicit skill and tool dependencies
- Isolated sub-agent sessions with clean outputs
- Run receipts, logs, artifacts, and audit trails
- Reuse of sessions on demand
So OpenProse extracts the entire workflow: phases, contracts, decision gates, loops, parallel work, mistakes, fixes, and validation evidence. It's like a “git for agent workflows”.
9
18
80
9,392
Turing Post retweeted
Jun 9
"Businesses are built on love and trust. Trustworthiness is the most underrated asset in all of business."
@ericries, entrepreneur and author of The Lean Startup and Incorruptible, on the real competitive advantages across industries
Watch the full interview on how AI is disrupting capitalism – and what comes next: youtube.com/watch?v=ypHhsCRW…
2
6
22
4,958
Turing Post retweeted
Jun 12
Refreshing deep learning with a 400 textbook: "The Principles of Deep Learning Theory"
Covers:
- An "effective theory" framework for deep neural networks
- Criticality, chaos, and signal propagation at initialization
- Neural Tangent Kernels (NTKs) and kernel learning
- Bayesian learning and finite-width effects
- Why deep networks learn features instead of behaving like kernels
6
46
308
14,249
Jun 12
Refreshing deep learning with a 400 textbook: "The Principles of Deep Learning Theory"
Covers:
- An "effective theory" framework for deep neural networks
- Criticality, chaos, and signal propagation at initialization
- Neural Tangent Kernels (NTKs) and kernel learning
- Bayesian learning and finite-width effects
- Why deep networks learn features instead of behaving like kernels
6
46
308
14,249
Jun 12
Follow @TheTuringPost for more.
Get deep analysis, guides & breakdowns of what AI is about now.
Join 100,000 readers from top AI labs, VC funds & universities.: turingpost.com/subscribe
2
2,675
Jun 12
1
13
1,097
Jun 12
Wow, this is interesting..
@Stanford researchers put a common assumption to the test: large models need only “high-quality” filtered training data.
What if the best filter is no filter at all?
They compared full Common Crawl data with heavily filtered versions of it and got surprising results:
1. Filtering can help with small compute budgets, because models can't learn from everything well.
2. However, as models get larger and train longer, the full, unfiltered dataset becomes the winner.
Large models handle messy data better than expected – low-quality text, irrelevant text, or some “junk” data are not a big deal; these models can tolerate them.
And they can even extract useful signal from data that looks poor.
These facts transform general rules:
→ Filtering helps when compute is limited. But when compute is very large, removing too much data may throw away useful information.
This also connects with the concept of "bitter lesson": at large scale, simple scaling often beats clever human design.
But the final choice depends on your constraints and preferences – would you rather increase compute costs or put more resources and time into filtering?
Interesting to see your answers 👀
10
56
370
31,393
Jun 12
1
3
9
2,192
Turing Post retweeted
Jun 10
1
32
151
7,963
Turing Post retweeted
Jun 9
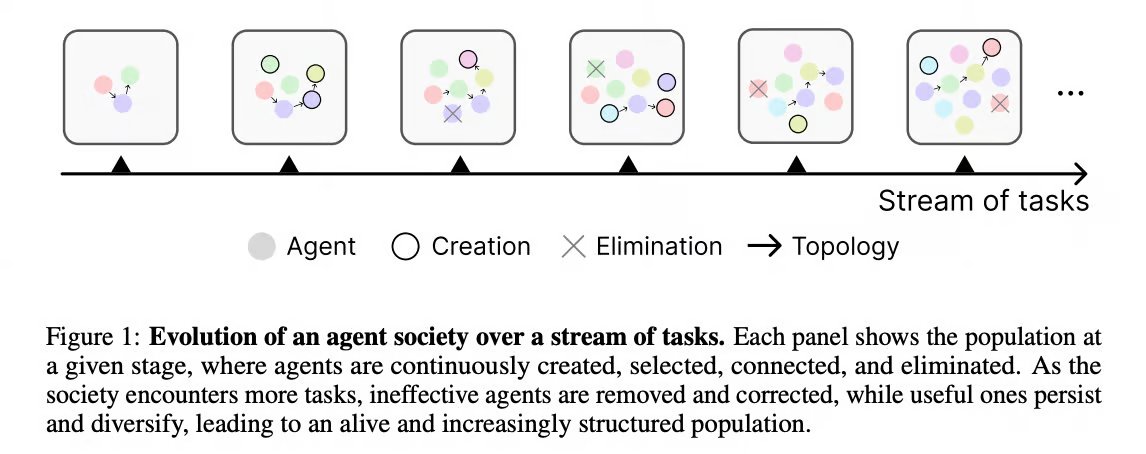
AutoScientists – a research lab made of agents
@Harvard researchers connected agents into a self-organizing scientific team without a boss agent standing in the middle
All agents look at the same shared workspace: they share memory, explore multiple directions in parallel, critique each other, avoid repeated failures, and reorganize as evidence changes.
But the teams are not fixed. Agents can gather around a promising direction, like architecture, optimizer changes, or data augmentation, then abandon it if it stops working.
Before they spend compute, they discuss proposals and critique each other.
AutoScientists also shows strong results:
- 74.4% mean leaderboard percentile on BioML-Bench
- 1.9× faster GPT training optimization
- 12.5% on ACE2–Spike, with the same method transferring to 217 ProteinGym assays for a 6.5% average gain
5
40
205
21,857
Turing Post retweeted
Jun 10
Github might not be ideal but everybody is using it. That's why I wanted to talk to Mario – how is the platform changing because of the agents?
Watch the video ->
Jun 10

AI is redefining who can build and how far they can go. We should be lowering the floor while raising the ceiling.
Enjoyed this discussion with @TheTuringPost on this and other topics.
2
3
3
1,509