
PM - Green Ash Horizon Fund. Perusing latent space
Joined March 2021
- Tweets 887
- Following 1,219
- Followers 623
- Likes 3,380
141 Photos and videos







Jun 12
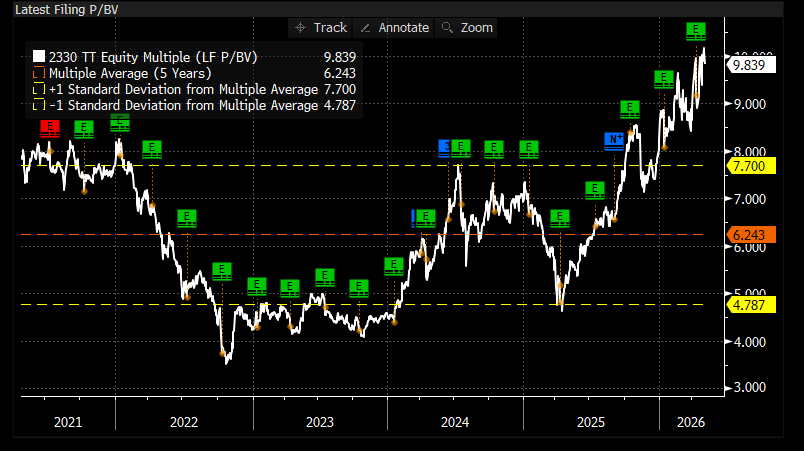
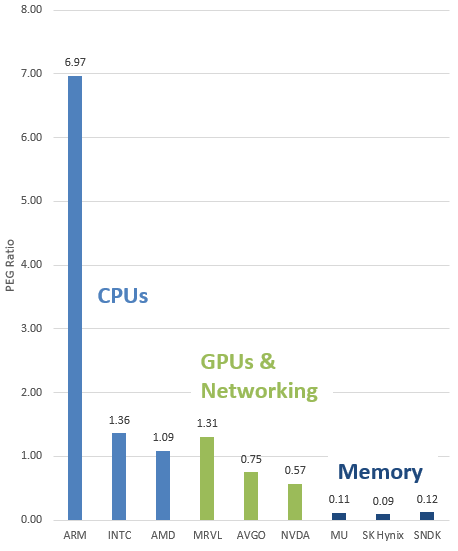
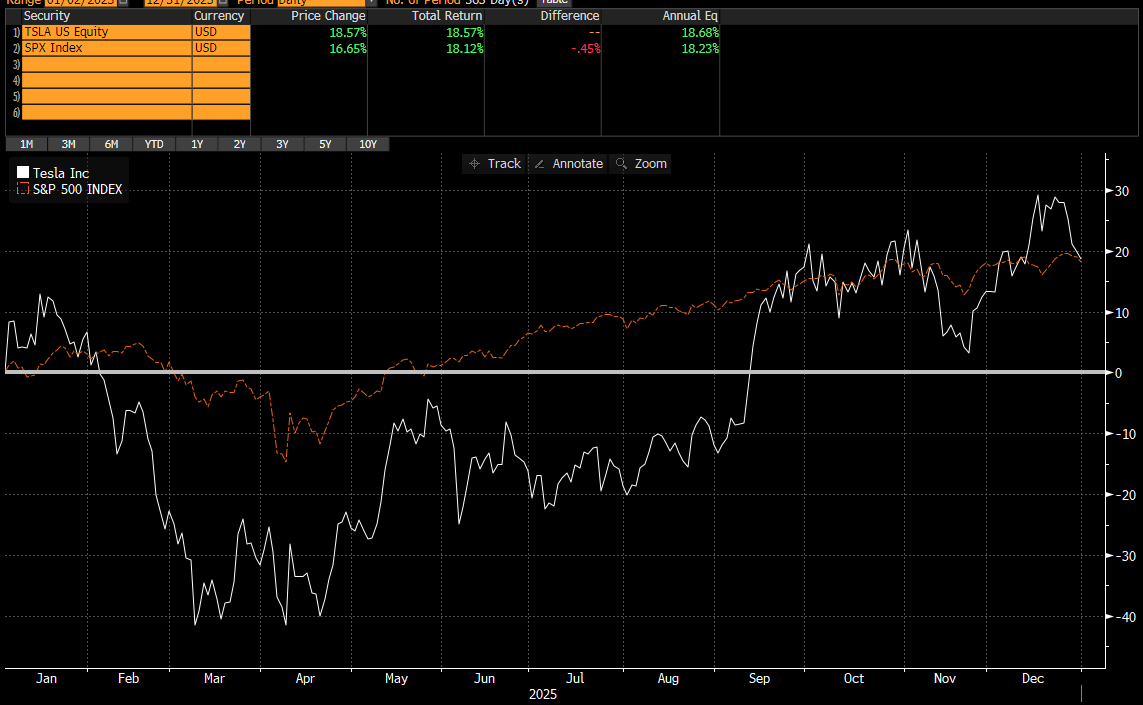
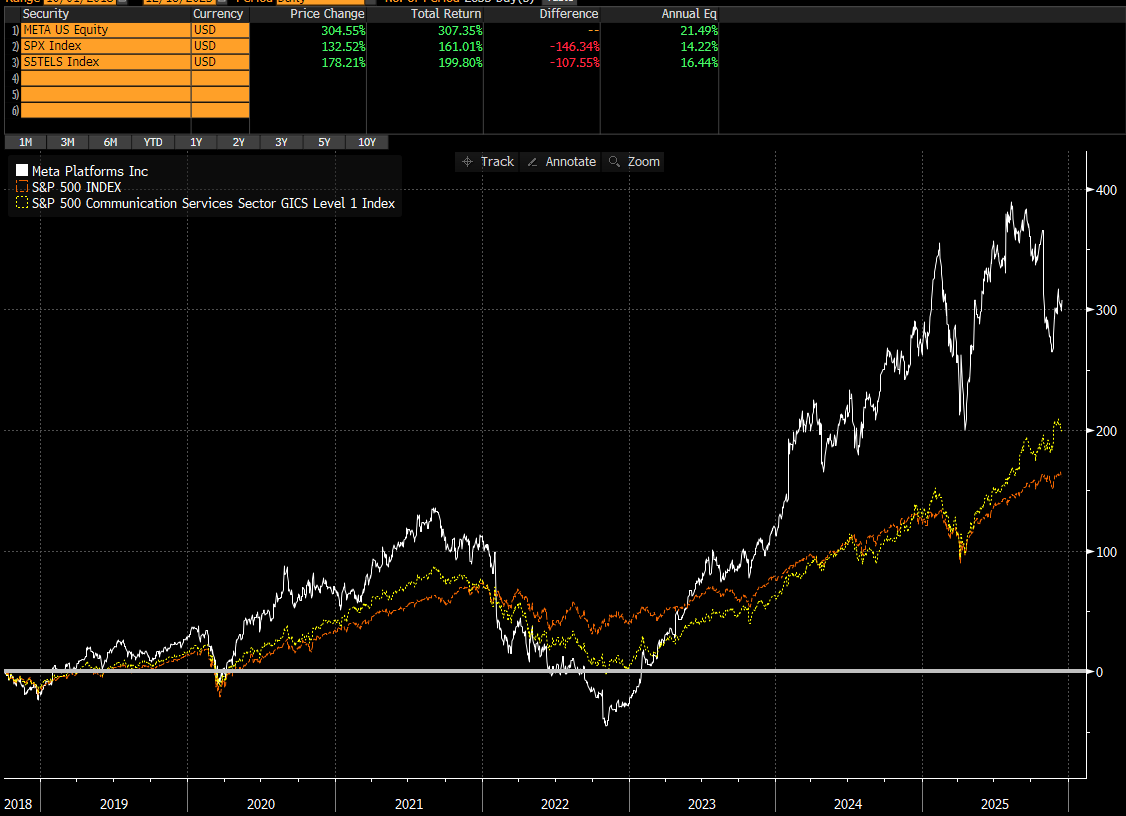
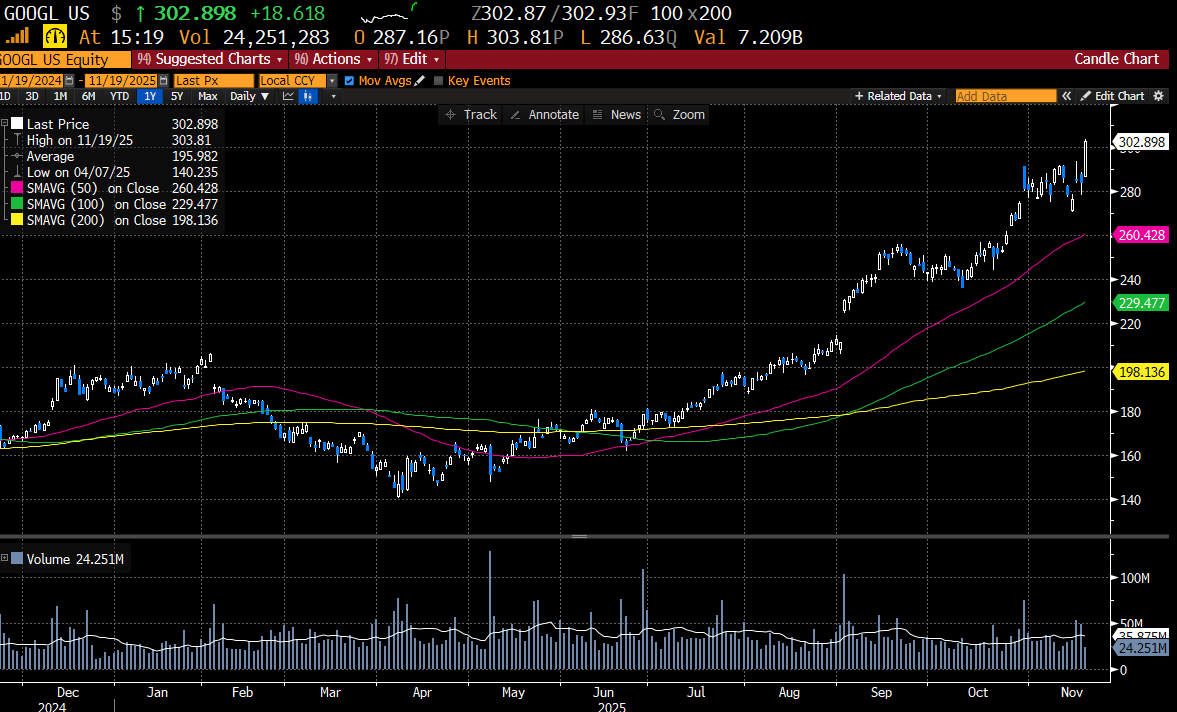
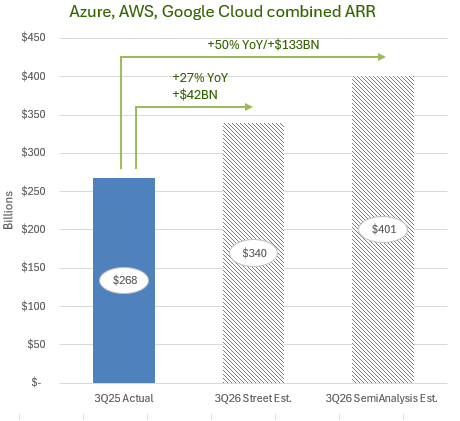
Earth Observation - We expect the combination of EO and AI to enable a significant expansion of TAMs across sector verticals like defence & intelligence, agriculture, resource extraction, financial services, supply chain logistics and civil government. Planet Labs CEO, Will Marshall, pegs the company's total addressable market at $75-100 billion - ~10x larger than the current EO market and ~300x larger than Planet's revenues last year. This sits somewhat in the middle of the peer group, with BlackSky's $40 billion at the lower end and Satellogic's $140 billion at the upper. The economic value that could be unlocked by Earth observation is larger still - the WEF estimate EO data generated $266 billion in economic value in 2023, and this could rise to over $700 billion by 2030, based on forecasted adoption trends. Looking horizontally across sectors, there is over half a trillion dollars in commercially measurable value to address in precision agriculture, supply chain monitoring and vulnerability analysis alone.
5/8
1
30
Jun 12
Datacentres in Space - SpaceX's reference design for an AI satellite assumes 70kW/tonne. On these numbers you could put 6MW of AI compute into orbit per Starship launch and a GW per year if a Starship launched every other day. If orbital datacentres prove viable on a 5–15 year horizon — which remains an open engineering and economic question - we can start to think about this theme from an investment perspective. The good news is that much of the domain knowledge acquired during the current AI infrastructure boom will be useful for investors in the potential ODC boom of the 2030s. Maybe GPUs/XPUs and memory silicon get a makeover to harden them against the g-force of rocket launches or long-term exposure to radiation, but they will remain fairly close cousins to the chips powering AI datacentres on Earth. The optics theme we are just embarking on will continue to provide an important role, not least for their lower thermal overhead vs. copper, and lasers will form the backbone of satellite-to-satellite communication. And the GaN/SiC components that are featuring in new NVIDIA 800V DC system designs will be equally useful in AI satellites, given the need for power and thermal efficiency, and that solar PV supplies DC power natively.
6/8
27
May 20
After Meta spent $80BN failing to build the metaverse, Google have released it as a side project

Project Genie is a @GoogleLabs experiment that lets you simulate dynamic worlds you can navigate in real time with Genie, our general-purpose world model.
Today, we’re connecting Project Genie to nearly 20 years of Street View data from Google Maps — so you can now build interactive spaces based on real-world locations.
Street View imagery in Project Genie is available now for places in the U.S., and will expand to more locales over time.
#GoogleIO
107
James Sanders ⚛🌍 retweeted

May 17
Attempted to write a Steam Engine hype at the era of Industrial Revolution as if it was the age of AI —
The steam engine breakthrough is insane right now.
Watt’s separate condenser new GRPO optimization just dropped the 405 hp-class engine. We went from 7 hp → 70 hp → 405 hp in basically three years. One machine now does the work of 50 men or water wheels — nonstop, rain or shine, anywhere.
Textile mills, ironworks, everything scaling 5-10x overnight. Productivity exploding.
This isn’t incremental. It’s automating physical labor at massive scale. Jobs shifting forever. Society about to look unrecognizable.
The Industrial Revolution isn’t coming. It’s here and accelerating faster than anyone predicted.
Terrified. Excited. Both.
What a time to be alive. 🚂💨
355
635
5,531
20,116,783
Jan 15
So interesting. Do models learn easy tasks first because they need to understand those to learn the hard tasks, or are the hard tasks just less well represented in the training data?
Jan 15

This is an extremely beautiful plot because it sheds light on why scaling laws are so smooth, and reconciles empirical findings from both scaling laws and grokking.
Even though mean loss across all tasks (red line) decreases smoothly, we see that individual subtask losses drop in a much more phase transition / grokking-like way. Easier subtasks are learned first, harder subtasks learn much later. This is also consistent with many LLM evals where you see a sharp inflection as you scale, rather than smooth linear improvement.
It also suggests why robotics models have not yet seen sufficiently convincing scaling laws: even though we may collect enormous numbers of demonstrations & hours of data, the data do not contain enough diversity or "underlying subtask quanta" for the losses to "meld together" to form a clean scaling law.
It remains a mystery why natural data, sorted by subtask difficulty, seems to form a Zipfian distribution. Are tasks we perceive as "difficult" actually nothing more than "infrequent" in our training distribution? There is relationship between the length of the shortest program that can generate some data, and the frequency of that data. If a subtask were *more* frequent, then you could actually shorten the program needed to generate it, thereby making the task easier from a Kolmogorov Complexity POV.
And if you assume my previous claim about robotic scaling laws is true, why makes robotics data have such bad zipfian coefficients? Does the coefficient only get "good" once you do the tokenizer dedup operationalize the data collection just right?
Does a hard subtask take more steps to learn because it requires representations from "easier" subtasks to be learned first? Representational dependency enforces a strict ordering in tasks that can be learned (task B cannot be learned until task A is mostly learned, task C cannot learn until B is mostly learned)? This could explain why there is an "ordering" of difficulty - it arises from natural ordering of dependencies in distributed representations like DNNs.
It would be interesting to study this in a synthetic context, where one has the power to tune frequency of data independently of "minimum description length" as defined by P(Internet text), and see if it is possible to "learn hard tasks faster". Lots of potential in applying a better mechanized understanding to how scaling laws form to improving scaling properties on frontier models.
1
220
Jan 10
I wrote about Claude Code. Three weeks late for twitter, in-line for substack, and six months early for linkedin.
The Great Unhobbling: How Claude Code Stole Christmas
greenash-partners.com/docume…
2
141
James Sanders ⚛🌍 retweeted

24 Dec 2025
we’re going to have a century of christmas cheer compressed into five years

20
88
1,843
102,174
17 Dec 2025
"Gemini, draw a poster where you say A is for an AI datacentre subcomponent (can be power, cooling or semiconductor) that starts with the letter A, B for component that starts with B, all the way to Z"
1
100
5 Dec 2025
In light of DeepSeek acknowledging the need to scale pre-training in their most recent paper, it's fun to re-visit some of the bad takes from the 'DeepSeek moment' at the start of the year:
"DeepSeek now also undermines the business case for scaling. OpenAI has been burning through staggering sums of cash to keep up its scaling paradigm and has yet to figure out how to balance its checkbooks - and it turns out it didn’t need to spend so much cash." - Karen Hao, The Atlantic (Jan 27, 2025)
"If scale is the answer, what is the question? How DeepSeek exposed a fundamental AI scaling myth... Was the Tech CEO narrative about scale simply self-serving all along, and at its core, little more than a money grab?" — Daniel Akarca, IAI News (Jan 29, 2025)
"[DeepSeek-R1] overturns the accepted wisdom that scaling is the way forward... It suggests that US companies are throwing money away and can be beaten by more nimble competitors."— James Vincent, The Guardian (Jan 28, 2025)
"DeepSeek’s resource-efficient methods could force a reconsideration of brute-force AI strategies... we could very well see demand for AI Computing power cool off." — Trefis Team, Nasdaq (Jan 27, 2025)
"Given the scaling up of pre-training compute also stalled, we'll see less AI progress via compute scaling... and more of it will come from inference scaling."— Effective Altruism Forum / Alignment Research Sentiment (Jan/Feb 2025)
"Investors are questioning whether the AI narrative is permanently changed... [DeepSeek] highlight that the rapid growth of AI computing requirements is slowing."— Invesco Investment Insights (March 2025)
1
69