
AI Tools | Automation | Productivity | Helping you work smarter with AI | Daily insights & workflows | Let’s Collab — DM 0r Mail: 📩 tipswithai01@gmail.com
Joined December 2021
- Tweets 280,327
- Following 207
- Followers 13,581
- Likes 269,401
1,734 Photos and videos












Pinned Tweet

Jun 12
🔥FREE BOOK DROP🔥
In:
⚡Write code that’s easy to read & maintain
⚡Master agile craftsmanship principles
⚡Level up with Robert C. Martin’s wisdom
🔥Worth $129 — FREE For First 300 People..!
Get it:
1️⃣Like & RT
2️⃣Type “ CODE ” [Must]
3️⃣Follow Me @Tips_With_AI For Instant DM
24
38
57
1,313
AI Tips retweeted

🚨 Google Gemini is replacing entire workflows.
People use it to:
• Create content
• Build apps
• Learn faster
• Automate tasks
• Make money online
I packed the best Gemini prompts, tools & hacks into a FREE guide.
Like Rt Comment " SEND " Follow Me: @insights_m_x

6
9
13
67
AI Tips retweeted

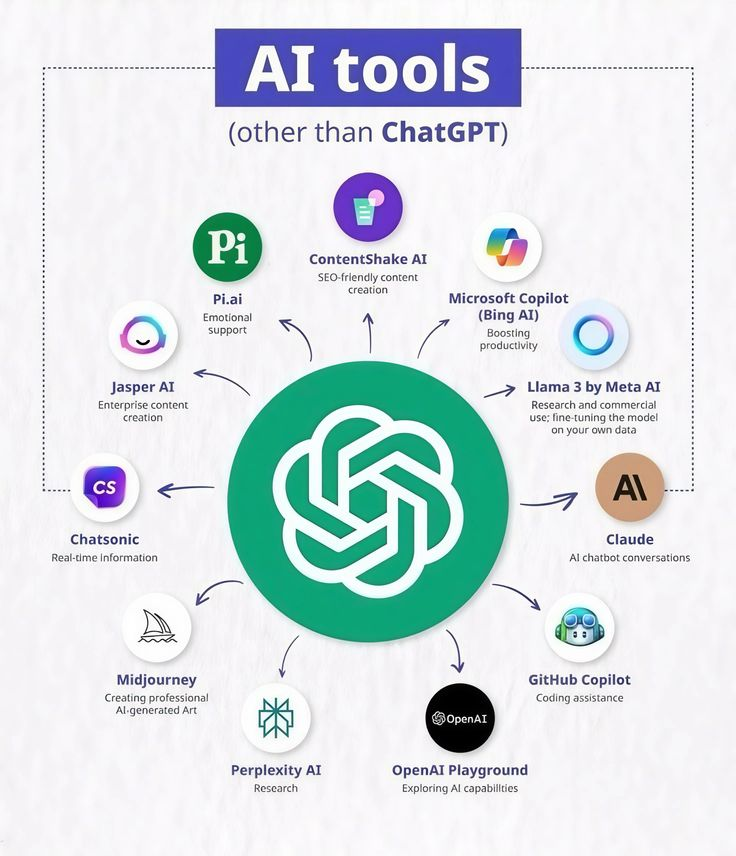
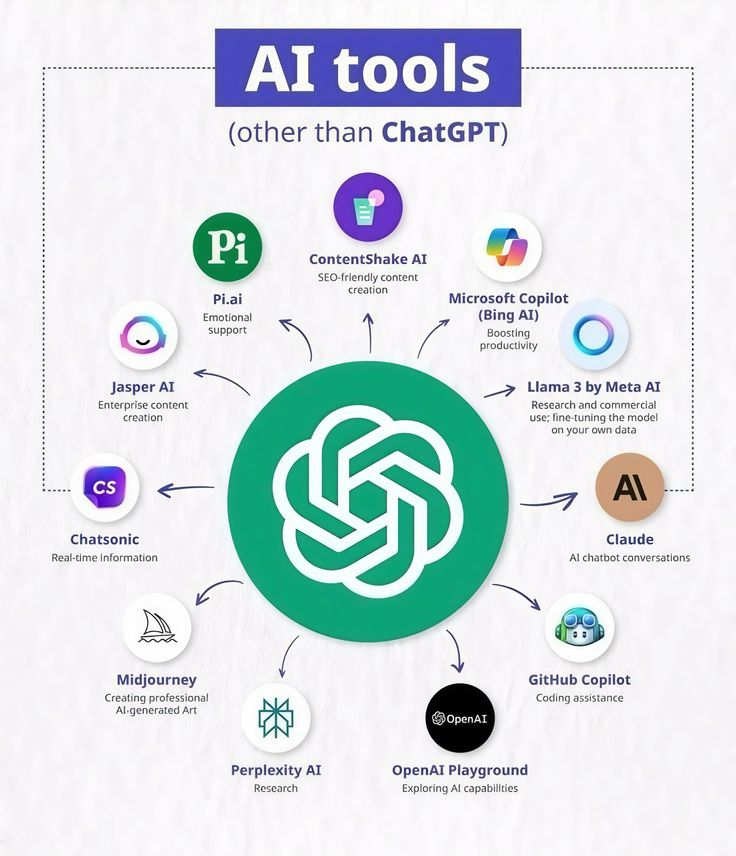
Most people are paying for 10 AI tools every mo💸
But this single dashboard replaces all of them:
• Claude
• Copilot
• Jasper
• Midjourney
• Perplexity
• Chatsonic
• Pi AI
• ContentShake
Free For Today only.
Like & RT Type " SEND " Follow Me
12
18
23
141
AI Tips retweeted

Jun 13
The Notes app on your iPhone is one of the most powerful tools available.
But 99% of people don’t know its true potential.
Here are 15 amazing features you must know:

Jun 12

Everyone is obsessed with bigger GPU clusters.
The real bottleneck has quietly become storage.
@KAYTUS_ Official's new All-QLC flash architecture tackles a problem most AI infrastructure discussions ignore: feeding 10,000 GPUs fast enough to keep them busy.
The headline numbers are impressive—10 TB/s bandwidth, 100 million IOPS, and a claimed 70% reduction in 5-year TCO—but the more interesting story is the architectural shift behind them.
Instead of forcing data through fragmented storage layers and costly ETL pipelines, KAYTUS is betting on a unified data plane powered by high-capacity QLC flash and AI-native parallel file systems. The goal isn't just faster storage; it's eliminating the friction between data and compute.
For AI training workloads where 90% of operations are reads, paying a premium for TLC endurance often makes little economic sense. That's where the All-QLC approach becomes compelling: lower cost, lower power consumption, and potentially much better economics at exabyte scale.
If the benchmarks hold up in production environments, this is less about storage hardware and more about improving GPU utilization—the metric that ultimately determines how efficiently AI infrastructure capital is deployed.
As AI clusters continue scaling from thousands to tens of thousands of GPUs, the winners may not be the companies building bigger models, but the ones solving the infrastructure bottlenecks underneath them.
KAYTUS is making a strong case that storage is one of those bottlenecks.
Learn more at kaytus.com
33
38
61
4,257
AI Tips retweeted

Jun 13
🎉 JUST IN: Gimini 3.5 Flash and Claude Opus 4.8 now available on GlobalGPT — free to try!
Create AI videos with dynamic comic IPs, lively ads, energetic dance videos, and unique running videos in various styles, all powered by Happy Horse and Seedance.
No limits. No regional barriers. No invite codes. 👇
20
35
48
2,187
AI Tips retweeted

Jun 13
🚨 10 Premium Courses FREE (First 4,500 People)
✓ AI
✓ Machine Learning
✓ Claude, ChatGPT & Grok
✓ Data Analytics
✓ AWS
✓ Data Science
✓ Big Data
✓ Python
⏳ 72 Hours Only
Subscribe👉intellisphere.com
🔁 RT 💬 Comment "DRIVE"
Follow me so I can DM you.

1
1
1
32
AI Tips retweeted

Jun 13
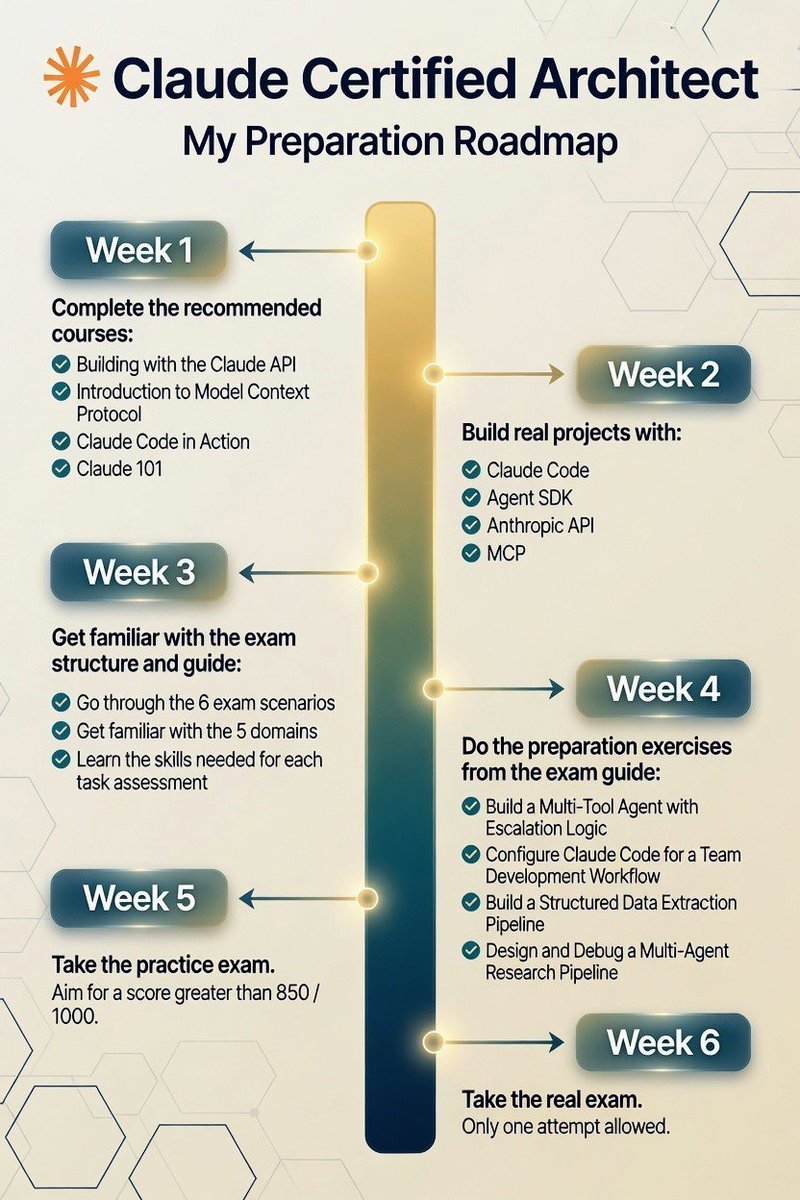
GIVEAWAY: Most people just “chat” with Claude.
Top builders use it to architect entire AI systems.
Inside this FREE 6‑Week Claude Architect Roadmap:
→ Weekly project milestones
→ Advanced Claude API workflows
→ Multi‑agent design.
→ Exam prep shortcuts.
Type"DM" & Follow
5
14
30
167
AI Tips retweeted

Jun 12
Big moment for AI creators.
Our AI Personality of the Year Awards was featured on @GMB this morning, with our ambassador Aitana Lopez presenting the Grand Prize to Soraya Thorne.
Congratulations to Soraya and all the incredible creators pushing the boundaries of AI creativity.
66
272
442
1,080,473
AI Tips retweeted
Jun 12
🔥FREE BOOK DROP🔥
In:
⚡Write code that’s easy to read & maintain
⚡Master agile craftsmanship principles
⚡Level up with Robert C. Martin’s wisdom
🔥Worth $129 — FREE For First 300 People..!
Get it:
1️⃣Like & RT
2️⃣Type “ CODE ” [Must]
3️⃣Follow Me @Tips_With_AI For Instant DM
24
38
57
1,313
Jun 12
Most people are paying for 10 AI tools every mo💸
But this single dashboard replaces all of them:
• Claude
• Copilot
• Jasper
• Midjourney
• Perplexity
• Chatsonic
• Pi AI
• ContentShake
Free For Today only.
Get it?
1️⃣Like & RT
2️⃣Comment "DM"
3️⃣Follow @Tips_With_AI
35
34
67
2,041
Jun 11
People overcomplicate making money online.
My faceless YouTube channels make $2,997.80 /month from long-form videos.
No luck. Just a proven system.
Want my free course?
To get it:
- Comment " SEND "
- Like & Retweet
- Follow me: @Tips_With_AI (𝐬𝐨 𝐭𝐡𝐚𝐭 𝐈 𝐜𝐚𝐧 𝐃𝐌)
28
28
40
1,166
Jun 10
🚨EXPOSED🚨
11 passive income ideas that pay while you sleep.
Focus on your INBOX.
People are making $120K /year with Faceless YouTube.
Simple
Scalable
Beginner-friendly
I built a side hustle to $9K /month.
All you need:
Phone/PC
Internet
3–4h daily
Follow RT Type "SEND"
20
14
31
385
Jun 9
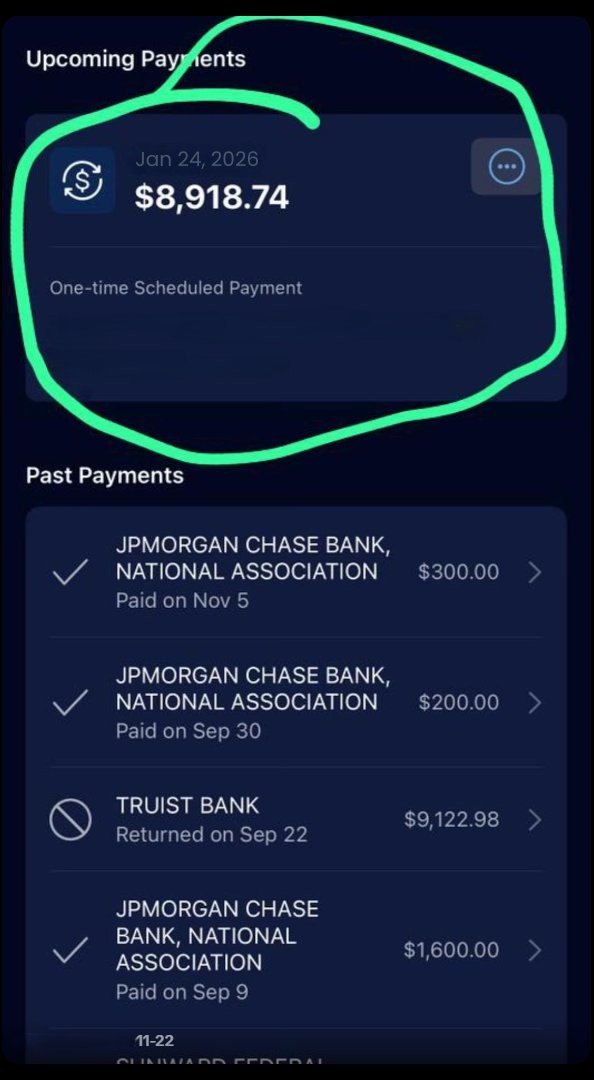
THAT’S WHY AIRLINES HATE CLAUDE 4.6 🧵
Flight listed at $879.
I paid $299.
No points.
No airline status.
No VPN tricks.
Just 8 prompts I used with Claude to book like a pro ↓
20
29
47
1,577
Jun 9
9/ The truth?
Airlines don’t “hate Claude.”
They hate that pricing isn’t invisible anymore.
1
1
71
Jun 9
I hope you've found this thread helpful.
Follow me @Tips_With_AI for more.
Like/Repost the quote below if you can:
Jun 9

THAT’S WHY AIRLINES HATE CLAUDE 4.6 🧵
Flight listed at $879.
I paid $299.
No points.
No airline status.
No VPN tricks.
Just 8 prompts I used with Claude to book like a pro ↓
1
86