
“I have read and agree to the #termsofservice” is the biggest lie on the web! 📑 We aim to fix that! Get involved at edit.tosdr.org #ToSDR
Joined June 2012
- Tweets 1,705
- Following 69
- Followers 7,713
- Likes 269
76 Photos and videos



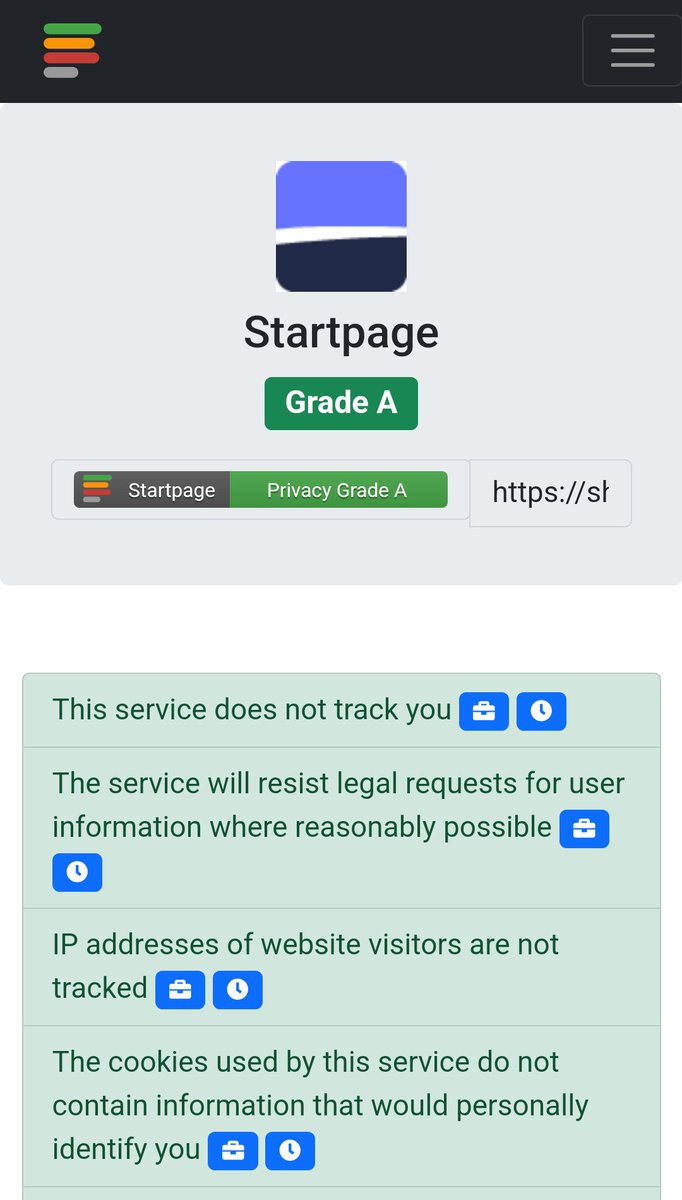
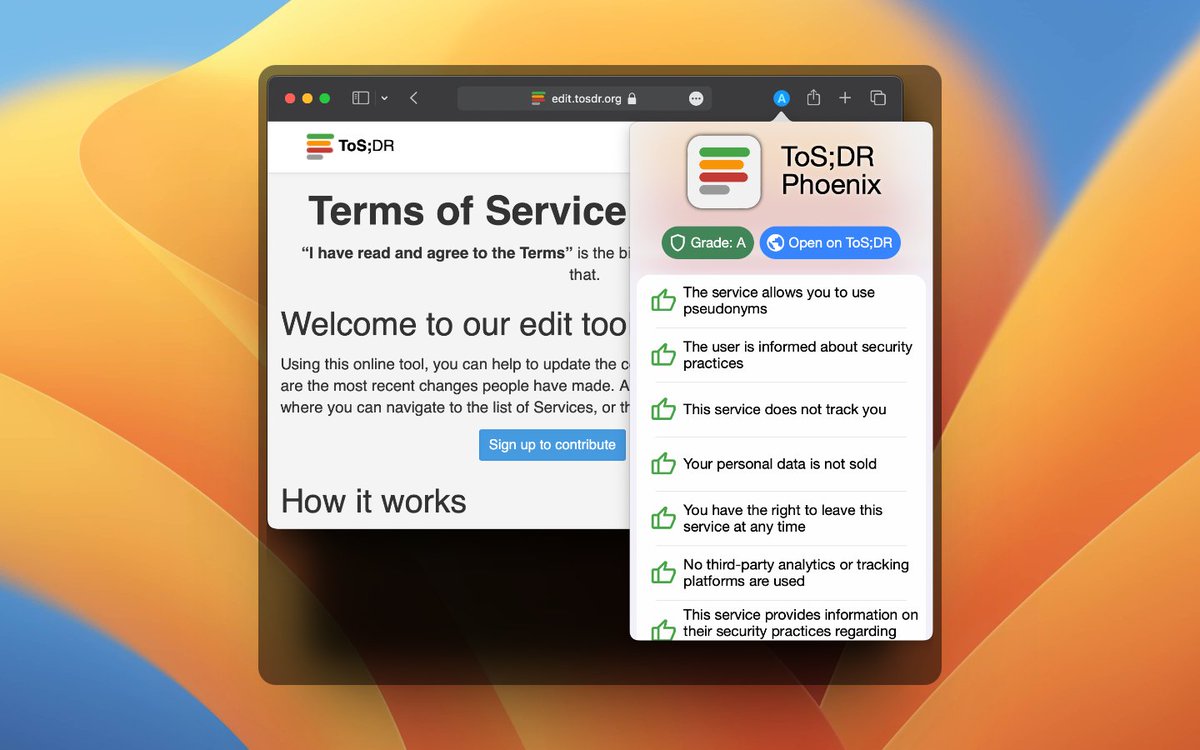


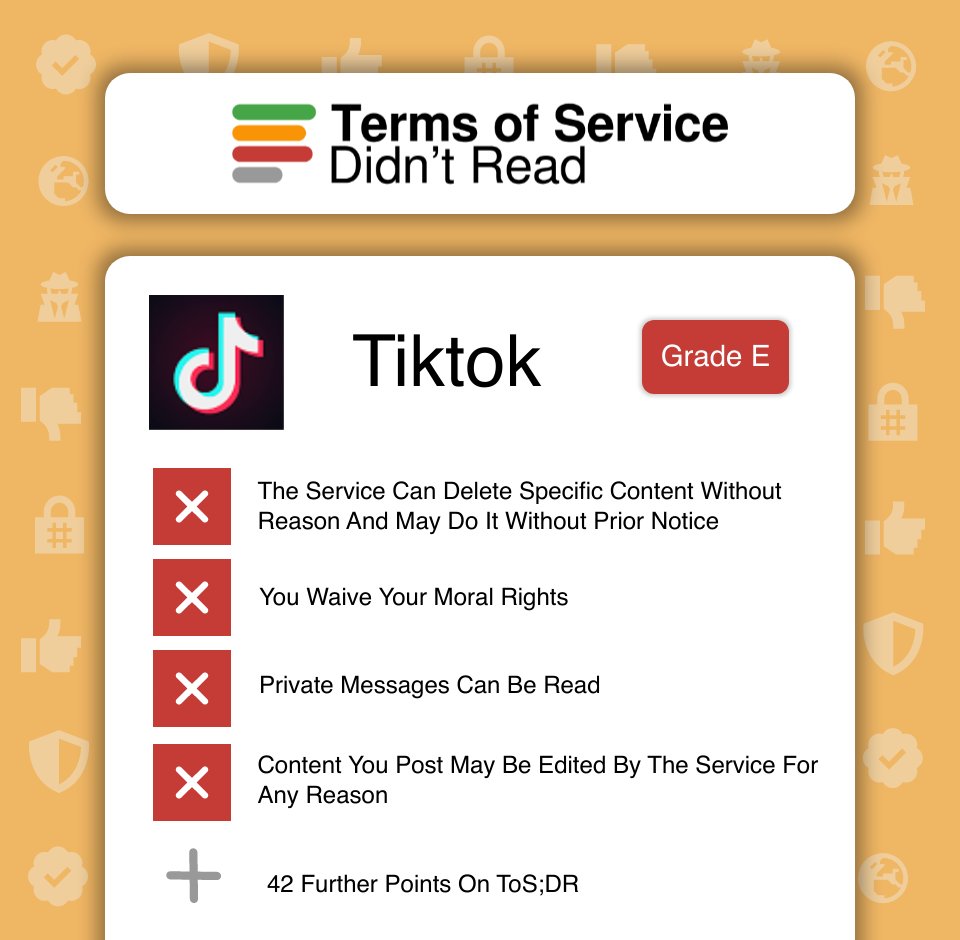








1 Feb 2025
We regret to have to inform you that we will be shutting down our public Matrix server.
Check out our forum post to find out what to do if you have an account, why we are shutting down and how the timeline on this will be.
tosdr.community/t/matrix-tos…
#matrix #tosdr
6
842
Terms of Service; Didn't Read 🚥 retweeted

1 Aug 2024
"You consented to that data collection"
I push back against the myth of consent in a world where companies deliberately try to obfuscate how much data they're collecting, and wrap it in 60 pages of legalize and vague language.
36
101
542
17,907
Terms of Service; Didn't Read 🚥 retweeted

14 Jul 2024
Le programme de financement européen NGI est en danger. Cette initiative permet de soutenir financièrement des centaines de projets libres communautaires.
Cette disparition mettrait en péril tout l’écosystème des logiciels libres qu’il consolide.
framablog.org/2024/07/14/lun…
4
68
71
6,882
Terms of Service; Didn't Read 🚥 retweeted

1 Jun 2024
I've just contributed to @ToSDR. Consider supporting them too — every little helps! opencollective.com/tosdr via @opencollect
3
5
939

Terms of Service; Didn't Read 🚥 retweeted

12 Mar 2024
Good a time as any to revisit this study from 2008 by @lorrietweet and co that found that it would take 244 hours (or a month, if you spent 10 hours a day reading) to review all the privacy policies you agree to in a given year: kb.osu.edu/server/api/core/b…
2
19
40
7,503
Terms of Service; Didn't Read 🚥 retweeted
5 Jan 2024
After being broken for a while our #Safari Extension is back! And not just that, we now have dedicated apps for #iOS and #MacOS, quickly checking the rating and summary of any Service #TermsOfService and #privacy policy. Get them here: apps.apple.com/us/app/tos-dr…
ALT A Screenshot of the Safari Browser with the new ToS;DR Extension showing a summary of the terms of service and privacy policy of the website that is currently open.

ALT Two Screenshots showing the new ToS;DR app for IOS.
2
8
20
3,705
Terms of Service; Didn't Read 🚥 retweeted

29 Feb 2024
➡ Free #privacy resource
You read the Terms of Service, right? No, of course not! The way companies publish their ToS makes it difficult to parse. How they embed them into user workflows encourages individuals to skip over them. And since there are more of them than you, it becomes an asymmetric problem that you can't properly manage at scale.
One tool to help with this imbalance is @ToSDR (tosdr.org/). They distill the legal jargon of various sites' ToS into human-readable outlines to help you make sense of it all. For the most popular sites they even provide ratings. The code is open source. You can submit new sites. There's also communities on IRC and discord.
#cybersecurity #learncybersecurity #privacyawareness #termsandconditions #dataprivacy
3
9
858
23 Feb 2024
#Avast sold data collected by a "privacy tool". Let this be a reminder to actually read the terms and not just the marketing!
Check out our summary of Avast Terms here:
tosdr.org/en/service/2141
Read about Avast selling user data to advertisers at @verge
theverge.com/2024/2/22/24080…
1
1
9
741
Terms of Service; Didn't Read 🚥 retweeted

13 Feb 2024
Ever been curious about what companies can do with your information or what you're agreeing to when you click I agree? Check out tosdr.org/ They have a wonderful website where you can see exactly what you're agreeing to! #tosdr
Terms of Service; Didn't Read
We help you understand Terms of Service and Privacy Policies
tosdr.org 1
3
495
10 Jan 2024
Not reading the Terms of Service, how convenient there’s a service for that :)
10 Jan 2024

What’s the worst online #privacy habit you’ve seen among your friends? And how would you fix it?
We’ll select a random winner for a $5 Proton gift card.
2
18
1,690
9 Jan 2024
Thanks so much for the positive feedback over the last few days - I spent months of my life pouring my heart and soul into making the app for each of you. Get excited for future updates and feel free to leave feedback anywhere for us, thank you!!!
-EH
5 Jan 2024

After being broken for a while our #Safari Extension is back! And not just that, we now have dedicated apps for #iOS and #MacOS, quickly checking the rating and summary of any Service #TermsOfService and #privacy policy. Get them here: apps.apple.com/us/app/tos-dr…
ALT A Screenshot of the Safari Browser with the new ToS;DR Extension showing a summary of the terms of service and privacy policy of the website that is currently open.
ALT Two Screenshots showing the new ToS;DR app for IOS.
1
12
1,003
Terms of Service; Didn't Read 🚥 retweeted

9 Jan 2024
To be fair, who has time to read an agreement the size of a textbook? 😐

1
4
25
1,700
1 Jan 2024
Happy new year 🎊
...Soon™️ 👀
ALT A modern redesign of the Frontpage of terms of service didn't read.
1
3
19
1,175
Terms of Service; Didn't Read 🚥 retweeted

27 Dec 2023
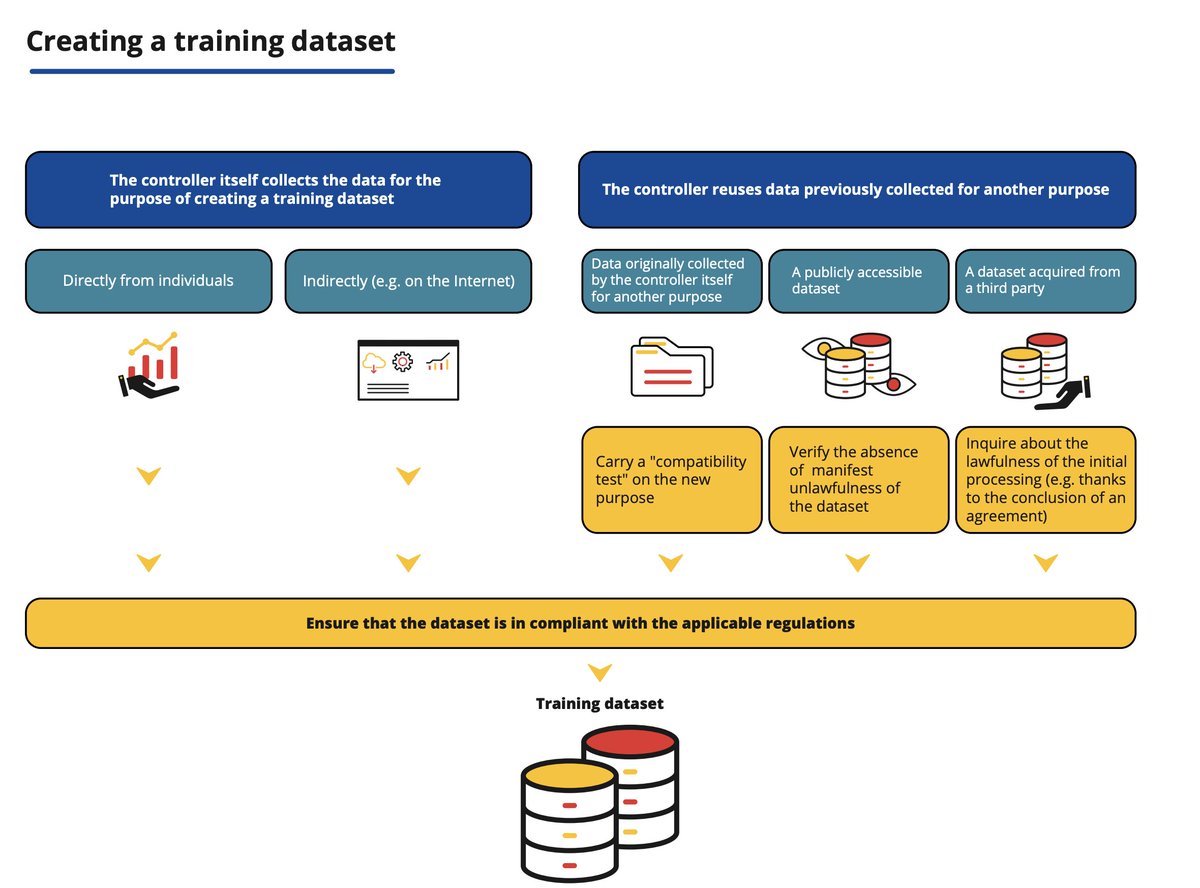
🔵 UNPOPULAR OPINION: the GDPR also applies when creating and training AI datasets - and most tech companies ignore it. This must change. Read this:
As the @CNIL's infographic below shows, regardless of the data source, data protection law must be observed when creating a training dataset.
A reminder that Article 6 of the GDPR establishes that these are the possible ways to process personal data lawfully:
- consent
- contract
- legal obligation
- vital interest
- public interest
- legitimate interested
Most AI companies developing large language models today rely on legitimate interest to scrape data from the web and train their models.
However, despite seeming an "easy" alternative, legitimate interest has its own legal requisites, including the three-part test (purpose, necessity, balancing), transparency, data minimization, and storage limitation.
Most tech companies developing AI today don't comply with any of these (and I did not mention yet data subjects' rights and other data protection principles).
With the quick and ubiquitous integration of generative AI and large language models-based capabilities into daily applications, data protection law must be implemented and made effective (or privacy rights and advancements - which took so much effort and time - will be undermined).
Privacy matters, ALSO when AI is involved.
Join our 4-week Privacy & AI Bootcamp on January 31st and learn more about it.
5
56
146
17,156
Terms of Service; Didn't Read 🚥 retweeted
6 Dec 2023
23andMe just updated their terms of service limiting the time in which users can take legal action and adding a class action waver.
If you are a 23andMe user you have 30 days to opt-out. This comes after millions of user data including DNA was leaked.
23andme.com/legal/terms-of-s…
18
22
5,003