
Building open source tools for distributed training.
Joined June 2023
- Tweets 61
- Following 30
- Followers 70
- Likes 80
2 Photos and videos

NeptuneAI shuts down March 5th.
@TrainyAI just launched Pluto on @ycombinator, a drop-in replacement so you don't lose years of experiment data.
Swap one import. Dual-log to validate. Export your history.
Open source. On Neptune's official transition hub.
ycombinator.com/launches/PLM…
2
2
19
7,239
@TrainyAI's Konduktor platform helps bring the benefits of a leading research team to your GPU cluster. We provide a fault-tolerant scheduler, integrated observability, and more.
Check out our docs: konduktor.readthedocs.io/en/…
2
2
246
Top tier AI research teams (Meta, OpenAI, etc.) have figured out the most efficient way to work with a cluster of GPUs. Instead of managing each GPU separately, they create a pools of GPU nodes and let sophisticated schedulers manage GPU availability efficiently.
1
2
2
233
Is your team struggling with GPU failures? Let’s talk!
Docs: konduktor.readthedocs.io/en/…
1
1
116
At @TrainyAI, we built a controller within Konduktor to monitor GPU node health and isolate unhealthy nodes. This way if a job fails, 0 manual intervention is required. K8s does its magic of placing work only on healthy nodes, and we forward relevant GPU/NCCL logs to your CSP. 🚀
1
1
1
105
4/ Struggling with multinode setups on your cloud provider? We'll cut your setup time from weeks to minutes. Docs: konduktor.readthedocs.io/en/…
1
1
63
3/ One of the biggest value-adds of @TrainyAI's Konduktor platform is that we simplify this complexity. We abstract away network configurations, so you can launch multinode training with high-bandwidth networking across different clouds in the same way.
1
1
1
64
Setting up and validating GPU networking is a lot less trivial than you'd think. Here's why:
1/ GPU fabric technology varies a lot across cloud providers for the H100. For example, Google Cloud has TCP-X, while AWS uses EFA. Once you commit to one setup, it often locks you in.
1
2
2
152
He lays out the ARC-AGI benchmark, how it tests generalization abilities rather than memorization, and his thoughts on what kind of AI system will be necessary to improve on the SoTA.
Watch here: youtube.com/watch?v=s7_NlkBw…
1
3
102
The latest Machine Learning Street Talk (MLST) episode, with François Chollet discussing inherent limitations of LLMs, was amazing.
It was a breath of fresh air to hear some sound reasoning after all the usual Doomer/Acceleration talk on AGI. He makes some great points:
1
2
3
151
With the features above and more, AI teams using @TrainyAI's Konduktor platform see at least 2x the utilization out of their GPU cluster. Curious? Drop me a message or click here to check out our docs: konduktor.readthedocs.io/en/….
1
1
53
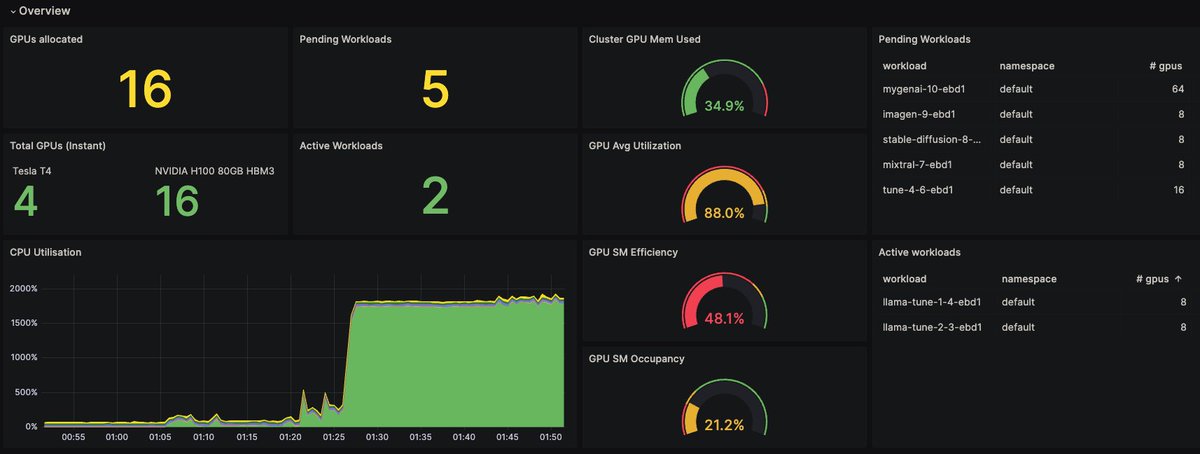
3. Enhanced Observability: Our platform offers comprehensive dashboards that provide a clear view of cluster usage and performance. Metrics like SM Efficiency help you understand how effectively your GPUs are being used, across different jobs and teams.
1
1
1
50
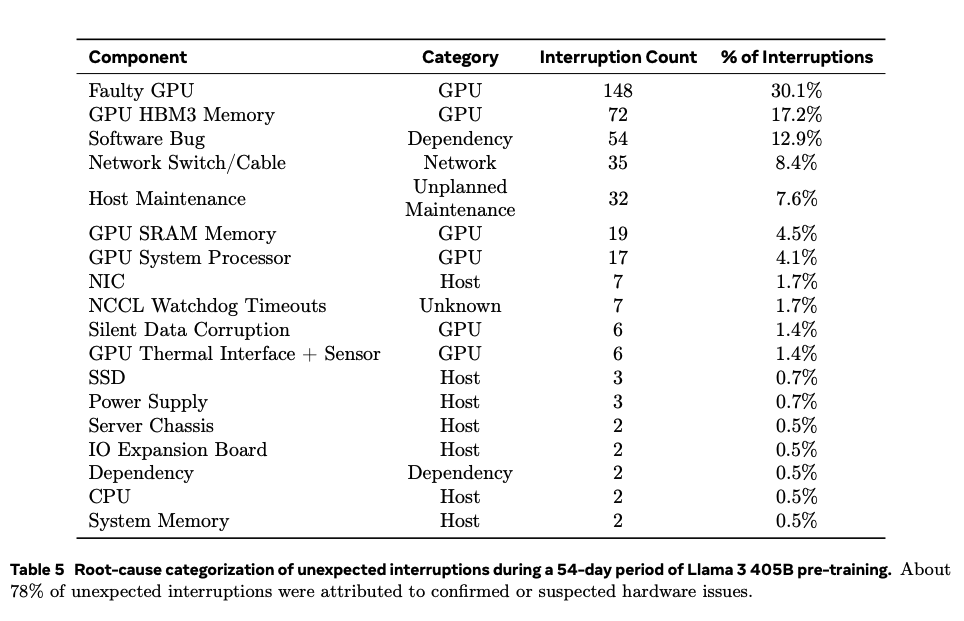
2. Minimize Downtime Disruptions: Traditional setups require manual intervention if a job fails. With H100 GPUs, these hardware faults are quite frequent (~30%). Konduktor detects hardware issues on failure, resumes jobs on healthy GPUs, and alerts your provider with logs.
1
1
1
29
@TrainyAI's Konduktor platform is here to change that.
1. Maximize GPU Utilization: With Konduktor, engineers can queue up a large number of jobs on their GPU cluster of varying priorities. This means the P0 workloads get run first, and your GPUs keep crunching numbers 24/7.
1
1
1
33