
...
Joined December 2023
- Tweets 78
- Following 203
- Followers 14
- Likes 52
20 Photos and videos








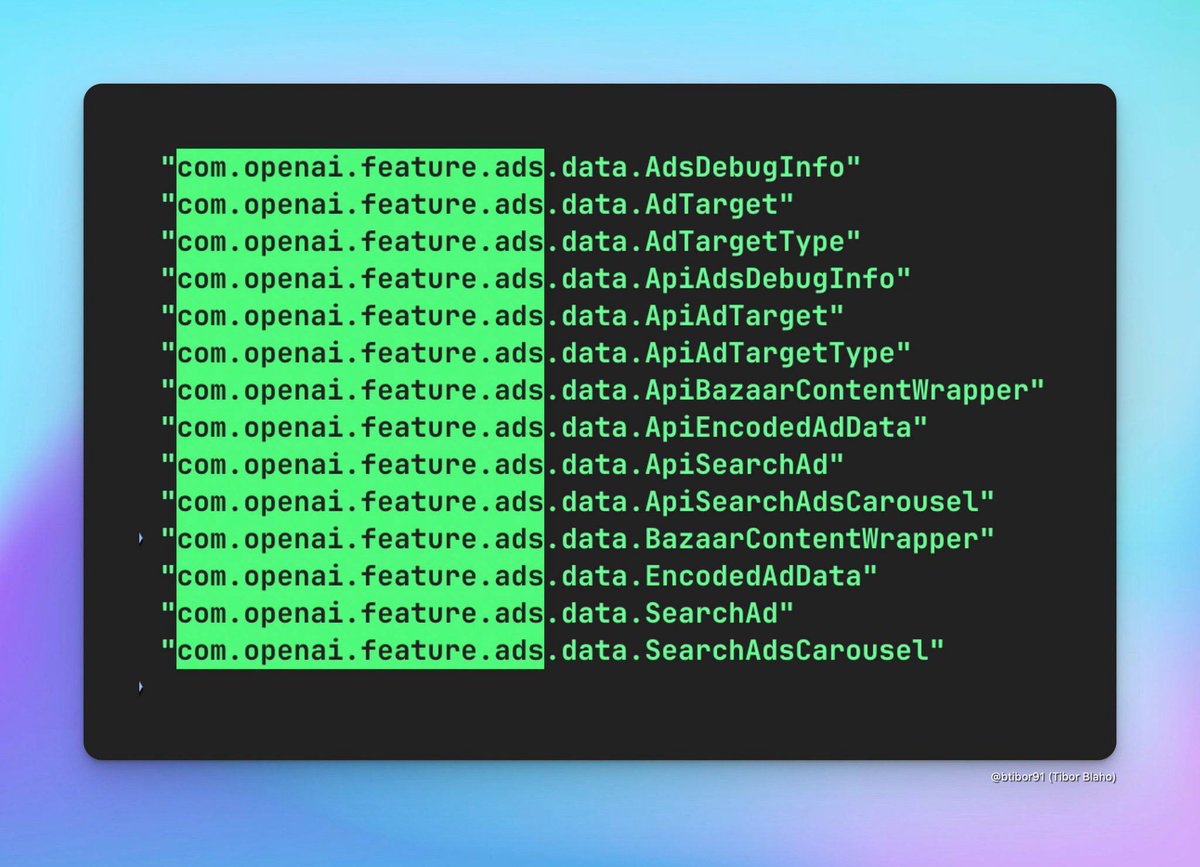







There is no greater 2026 irony than a developer using a high-level Agent (via MCP) to write a bash script (for a CLI) because they miss the 'simplicity' of manual labor. We are officially inventing tools to help us pretend we’re still the ones doing the work.
20
The weirdest part of the AI era isn't that machines are starting to think like us; it's that we’re starting to ‘prompt’ our friends and family because we’ve forgotten how to just ask a question without specifying a persona and output format.
12
people keep asking when ai becomes conscious
nobody asks when humans stopped being curious
15
every tech cycle ends the same way
step 1 overpromise
step 2 subsidize losses
step 3 call it inevitable progress
step 4 ask governments for patience
16
Just heard Elon declare we've hit the Singularity in 2026. So why is my Grok still generating conspiracy theories faster than it can deny polluting the planet with methane-spewing supercomputers? At this rate, AI will solve climate change by melting us all first. #TwinTransition
19

22 Dec 2025
how many h100s can we plug into the desert before the sand turns to glass?
14
22 Dec 2025
Elon Musk just spending the gdp of a small country to troll bill gates from orbit.

24
22 Dec 2025
if silver hits $420 next, i’m deleting my consciousness and uploading it to a ti-84 calculator.
37
22 Dec 2025
we are mining the planet to death so the "thinking" gpt-5.2 can tell you it doesn't have a personal opinion on whether water is wet.
36
22 Dec 2025
it’s december 22nd. we are exactly 48 hours away from the annual capitalist DLC update known as christmas eve.
26
Twin Transition retweeted

19 Dec 2025
As amazing as LLMs are, improving their knowledge today involves a more piecemeal process than is widely appreciated. I’ve written before about how AI is amazing... but not that amazing. Well, it is also true that LLMs are general... but not that general. We shouldn’t buy into the inaccurate hype that LLMs are a path to AGI in just a few years, but we also shouldn’t buy into the opposite, also inaccurate hype that they are only demoware. Instead, I find it helpful to have a more precise understanding of the current path to building more intelligent models.
First, LLMs are indeed a more general form of intelligence than earlier generations of technology. This is why a single LLM can be applied to a wide range of tasks. The first wave of LLM technology accomplished this by training on the public web, which contains a lot of information about a wide range of topics. This made their knowledge far more general than earlier algorithms that were trained to carry out a single task such as predicting housing prices or playing a single game like chess or Go. However, they’re far less general than human abilities. For instance, after pretraining on the entire content of the public web, an LLM still struggles to adapt to write in certain styles that many editors would be able to, or use simple websites reliably.
After leveraging pretty much all the open information on the web, progress got harder. Today, if a frontier lab wants an LLM to do well on a specific task — such as code using a specific programming language, or say sensible things about a specific niche in, say, healthcare or finance — researchers might go through a laborious process of finding or generating lots of data for that domain and then preparing that data (cleaning low-quality text, deduplicating, paraphrasing, etc.) to create data to give an LLM that knowledge.
Or, to get a model to perform certain tasks, such as use a web browser, developers might go through an even more laborious process of creating many RL gyms (simulated environments) to let an algorithm repeatedly practice a narrow set of tasks.
A typical human, despite having seen vastly less text or practiced far less in computer-use training environments than today's frontier models, nonetheless can generalize to a far wider range of tasks than a frontier model. Humans might do this by taking advantage of continuous learning from feedback, or by having superior representations of non-text input (the way LLMs tokenize images still seems like a hack to me), and many other mechanisms that we do not yet understand.
Advancing frontier models today requires making a lot of manual decisions and taking a data-centric AI approach to engineering the data we use to train our models. Future breakthroughs might allow us to advance LLMs in a less piecemeal fashion than I describe here. But even if they don’t, the ongoing piecemeal improvements, coupled with the limited degree to which these models do generalize and exhibit “emergent behaviors,” will continue to drive rapid progress.
Either way, we should plan for many more years of hard work. A long, hard — and fun! — slog remains ahead to build more intelligent models.
[Original text: deeplearning.ai/the-batch/is… ]
171
364
1,942
200,122
Twin Transition retweeted

14 Dec 2025
How do you profit from—or dodge—the unexpected when political, economic, and tech factors create critical unknowns? Our Winter 2026 special report features leading scholars and practitioners on new approaches to scenario planning and strategic foresight. >> mitsmr.com/44Nghzu

4
8
1,196
Twin Transition retweeted

12 Dec 2025
Doing a podcast here. ☺️

3,435
1,983
30,006
1,670,394
12 Dec 2025
A fuel tanker erupts in flames out of nowhere, but the team's response is a masterclass in efficiency.
11
7 Dec 2025
much needed feature.
5 Dec 2025

🥳We recently launched the Colab Data Explorer- a new feature that lets you search Kaggle datasets, models, and competitions directly from a Colab notebook! 🔍
Easily import data with a KaggleHub code snippet and use integrated filters to find exactly what you need.
Learn more and start exploring! 👇
kaggle.com/discussions/produ…
10