
A Self-Sustaining Community - The first and unique social platform on AO @aoThecomputer and Arweave.
Joined May 2024
- Tweets 145
- Following 36
- Followers 385
- Likes 318
40 Photos and videos















Typr x @aox_xyz Poll is Live 🔥
🗳️ Vote: typr.day/#/story/5dbe7bf9-27…
It’s been two weeks since @aoTheComputer officially launched the #PI token! $AR holders can customize their airdrop rewards.
So, what did you pick? 🤔
$AO?$PI?$AO $PI?
Come and share your choice! 👏
15
7
22
4,854
Typr x @aox_xyz Poll is Live 🔥
🗳️ Vote: typr.day/#/story/5dbe7bf9-27…
It’s been two weeks since @aoTheComputer officially launched the #PI token! $AR holders can customize their airdrop rewards.
So, what did you pick? 🤔
$AO?$PI?$AO $PI?
Come and share your choice! 👏
15
7
22
4,854
Typr retweeted

26 Mar 2025
🔄 Unlike traditional blockchains that terminate testnets and start fresh, AO's approach preserves all existing processes and data. It's a deliberate strategy that prioritizes continuity over arbitrary deadlines. ⏱️ Your applications remain functional throughout the infrastructure improvements as we optimize for long-term reliability. 🏗️🔒

4
16
86
3,835
Typr retweeted

20 Mar 2025
Yep, can understand the frustration. Outages on the free compute nodes that @fwdresearch runs truly suck because they are so widely used.
There is some confusion around this that should be cleared up:
➡️ AO processes themselves live on Arweave, so inherently they are never unavailable. You can always boot up your own node and execution them.
➡️ Sometimes, though, subsets of the legacynet nodes that @fwdresearch runs drown in free compute requests.
➡️ This is just like a gateway going down in a typical network -- it doesn't mean the network itself is unavailable. Same situation as Infra outages vs Ethereum stalls, etc. Almost all of the apps right now use the Forward Research cluster directly, though, so the UX can feel like 'fwd cluster is slow => aO iS DoWn?!'
➡️ At the moment most people use our cluster because it is free and until recently had very high rate limits. We ran it this way such that the widest set of people can get started and use the network easily. For some context on scale, the cluster is ~10,000 CPU cores right now. Ours alone is literally at small supercomputer-scale. I haven't seen charts for total requests served, but I expect it is into the >300m range per day.
➡️ We aren't the only people running nodes, though. For example, recently the @ar_io_network process was experiencing 10-15k reqs/min on our cluster. This led free compute requests to be slow/fail. Some gateways in the ARIO network run their own compute nodes, though, and were subsequently completely unaffected.
So the obvious question is: Where do we go next? We gave a workshop outlining our expectations of the run ahead as well as a deep dive into AO-Core at the end of February (linked in next tweet), but here's a rundown of the key points:
➡️ AO-Core is an extremely modular protocol. All functionality is implemented in 'devices' (think: the decentralized supercomputer-equivalent of physical components you plug into a motherboard). These devices can be composed on top of one another to generate many different types of computations, customized to each use case.
➡️ Pre-launch our focus was placed on getting AO-Core itself correct, as well as the first set of devices which are focused on handling payments and relaying of HTTP requests. This shipped on Feb 8 with mainnet and allows you to spin up a cluster (like the fwd one), offering paid compute via AO-Core and its devices. We call this milestone 1.
➡️ Milestone 2 shipped a couple of weeks after mainnet, offering preview versions of the full stack of devices needed in order to execute AO processes natively inside the new node implementation. This includes the full schedulers, messaging systems, compute (with multiple engines, in fact), TEE support for trust-minimized execution, as well as access gating with the payments from milestone 1. You can boot up AOS and hit a HyperBEAM node to start playing around with this.
➡️ Our current focus is milestone 3: Making HyperBEAM nodes fully compatible with existing legacynet processes. After this, our focus will be to help the community smoothly move from the free legacynet cluster, to the decentralized network of HyperBEAM AO-Core nodes for their computing needs.
Unlike a traditional testnet that is simply terminated, AO testnet was already carrying a significant amount of value by the time mainnet arrived. The community also have the opportunity to 'live transition' their services, without any explicit 'cut' in operations, because the processes don't actually 'live' in either AO mainnet or legacynet: They are simply data on Arweave. Subsequently, by focusing on compatibility of the implementations we can make the upgrade to mainnet seamless for millions of processes that are already live.
tl;dr:
➡️ Free compute => slow compute. You can run your own, but few people do right now.
➡️ Focus is on making the new nodes that bring configurable payments fully compatible with legacynet.
➡️ Once achieved, focus will be on helping the community start to make use of those nodes, rather than relying on free compute.
Hopefully that helps bring some clarity. It is not simple because live-migrating a network running constantly at >100 TPS and handling millions of requests an hour across hundreds of nodes was never going to be 'simple'. But this is where we are at and the direction of travel 🙂.
13
81
110
14,816
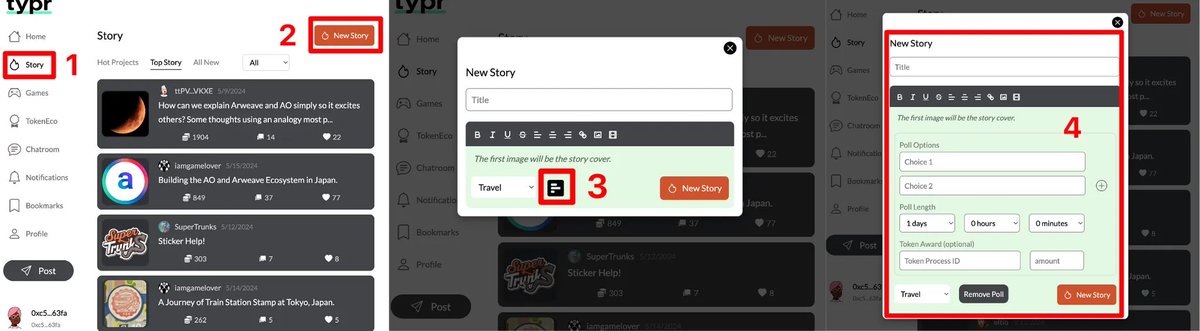
1/ Exploring Typr’s Poll Feature
#Poll is one of the key features of #Typr, the decentralized social platform on @aoTheComputer.
If you’ve joined the poll event over the past two weeks, you’ve probably already experienced it firsthand.
Why are we building this? 👇
24
11
28
2,282
3/ Poll Value
👉 Boosts Engagement: Drives @aoTheComputer community interaction, fuels hot topics, and strengthens ecosystem stickiness.
👉 Empowers Projects: Enables @aoTheComputer projects gather user insights and feedback through incentivized polls, driving growth.
1
150
🎉 #AO WAVE POLL Has Ended!
A total of 131 participants joined the poll, and it’s clear that #GameFi is the most favored sector in the @aoTheComputer ecosystem!
This poll was more than just a vote — it was a great way to boost engagement and strengthen #AO community vibe. ✌️
21
13
36
2,392
Typr Poll is Live 🔥🔥🔥
🗳️ typr.day/#/story/36d02c3f-8b…
🌊 The @aoTheComputer Eco Is Taking Shape – Which Sector Will Take Off First?
🤖 AgentFi
📊 DeFi
🎮 GameFi
💬 SocialFi
If you could ride the next big wave, where would you dive in? 👀
Vote now! Share the 300 BP rewards! 😜
23
14
37
6,480
Check out the @aoTheComputer breakdown on #HyperBeam to get the lowdown on its definition and how to get involved—definitely worth a read!🤖👇
5 Mar 2025

1
1
13
505
⚡ Million-Scale Seamless Poll Potential?
🔹 #HyperBeam recently launched, rebuilt on the Erlang VM, handles massive tasks.
🔹 Powered by #HyperBeam, typr has the potential to enable million-scale polls and seamless real-time interactions.
1
1
209
Typr retweeted
5 Mar 2025
🧮 Pi Day (3.14) is approaching! Learn how the PermaWeb Index creates an automated compass to navigate the AO, AR, and permaweb ecosystem. Set your preferences now at ao.arweave.net/#/mint/deposi…
Note: $AR holders will default to receiving the PI token as of 3.14, but can change their preferences anytime through the above link
124
145
250
21,913
🎉 Exciting news!
Since Typr launched, we’ve already had:
👥 Users: 7,877
📮 Messages: 3,897
🗯️ Replies: 1,458
While we’re still in the early stages, this is just the beginning of @aoTheComputer Social-Fi. 🔥
Also, congratulations to #HyperBeam for its arrival! Lets Build~💪
19
12
28
838