
38 Photos and videos















UCSB AI retweeted

Jun 7
Excited to share that our paper SAW-Bench: Learning Situated Awareness in the Real World received the Best Paper Award Runner-Up at the #CVPR2026 WMAS workshop!
Congratulations to all co-authors, and thanks to the organizers and reviewers for the recognition.
Special thanks to @jieneng_chen for hosting me at WMAS!


Feb 19

Human perception is inherently situated – we understand the world relative to our own body, viewpoint, and motion.
To deploy multimodal foundation models in embodied settings, we ask:
“Can these models reason in the same observer-centric way?”
We study this through SAW-Bench: a novel benchmark for observer-centric situated awareness:
- 786 real world egocentric videos
- 2,071 human-annotated QA pairs
Across all tasks, we evaluate 24 state-of-the-art MFMs:
📉 Best model: 53.9%
🧑 Humans: 91.6%
Models systematically:
❌ Confuse head rotation with physical movement
❌ Collapse under multi-turn trajectories
❌ Fail to maintain persistent world-state memory
👉 We see that maintaining a stable observer-centric representation remains challenging.
As MFMs are increasingly integrated into embodied agents, situated awareness becomes essential for reliable real-world interaction.
We release SAW-Bench and encourage further research toward improving observer-centric reasoning in multimodal foundation models.
1
3
17
3,565

Congratulations to @_Chuhan_Li , @xwang_lk, and their collaborators for their SAW-Bench paper on receiving the Best Paper Award Runner-Up from the CVPR 2026 WMAS workshop! 🏆
Feb 19
Human perception is inherently situated – we understand the world relative to our own body, viewpoint, and motion.
To deploy multimodal foundation models in embodied settings, we ask:
“Can these models reason in the same observer-centric way?”
We study this through SAW-Bench: a novel benchmark for observer-centric situated awareness:
- 786 real world egocentric videos
- 2,071 human-annotated QA pairs
Across all tasks, we evaluate 24 state-of-the-art MFMs:
📉 Best model: 53.9%
🧑 Humans: 91.6%
Models systematically:
❌ Confuse head rotation with physical movement
❌ Collapse under multi-turn trajectories
❌ Fail to maintain persistent world-state memory
👉 We see that maintaining a stable observer-centric representation remains challenging.
As MFMs are increasingly integrated into embodied agents, situated awareness becomes essential for reliable real-world interaction.
We release SAW-Bench and encourage further research toward improving observer-centric reasoning in multimodal foundation models.
3
4
2,047
📜SAW-BENC evaluates situated awareness in real-world egocentric videos: can a model track where it is, where it came from, and what actions are possible from its current viewpoint? Results reveal a large gap between current multimodal models and humans.
x.com/_Chuhan_Li/status/2024…
Feb 19
Human perception is inherently situated – we understand the world relative to our own body, viewpoint, and motion.
To deploy multimodal foundation models in embodied settings, we ask:
“Can these models reason in the same observer-centric way?”
We study this through SAW-Bench: a novel benchmark for observer-centric situated awareness:
- 786 real world egocentric videos
- 2,071 human-annotated QA pairs
Across all tasks, we evaluate 24 state-of-the-art MFMs:
📉 Best model: 53.9%
🧑 Humans: 91.6%
Models systematically:
❌ Confuse head rotation with physical movement
❌ Collapse under multi-turn trajectories
❌ Fail to maintain persistent world-state memory
👉 We see that maintaining a stable observer-centric representation remains challenging.
As MFMs are increasingly integrated into embodied agents, situated awareness becomes essential for reliable real-world interaction.
We release SAW-Bench and encourage further research toward improving observer-centric reasoning in multimodal foundation models.
1
1
387
📜Reasoning Within the Mind: Dynamic Multimodal Interleaving in Latent Space: A training-free multimodal reasoning framework that interleaves latent reasoning and visual evidence, improving both reasoning accuracy and visual grounding
x.com/liuchen02938149/status…
20 Dec 2025

🧠 Can Multimodal Models Think Like Humans?
Most multimodal models reason in rigid pipelines: either see once, then overthink in text or constantly use external visual tools to re-check. Can reasoning and perception be dynamically interleaved like in the human mind?
👤 Human: 👀 Look → 🧠 Think in mind → 🔁 Re-look when confidence is low
🤖 DMLR (ours): 👀 Perception → 🧠 Think in latent space → 👀 Selective re-percept to maximize token confidence
1️⃣ 🫣 Seeing at Every Step Is Unnecessary. Only a small subset of reasoning steps require visual input.
2️⃣ 🧭 Confidence as the Compass. Confidence captures the model’s intrinsic state, reflecting accuracy, reasoning quality, and visual grounding.
3️⃣ 🧠 Drafting in the "Mind". DMLR directly optimizes think token in latent space, enabling deeper reasoning without additional generation cost.
4️⃣ 💉 Dynamic Visual Injection Strategy. DMLR selects and injects only the most relevant visual patches, dynamically updated across iterations.
🚀 Read on to explore more analysis and insights! 🎓

1
239
📜Self-Evolving 3D Scene Generation from a Single Image: A self-evolving framework for single-image 3D scene generation that alternates between reconstruction and novel-view synthesis, progressively improving geometry, coverage, and texture quality
x.com/KaizhiZheng/status/199…
10 Dec 2025

🚀 Introducing EvoScene: Self-Evolving 3D Scene Generation from a Single Image!
Generating complete, textured 3D scenes from a single photo is challenging due to limited coverage and inconsistent textures. EvoScene solves this with a novel, training-free, self-evolving framework that progressively reconstructs high-quality, ready-to-use 3D meshes.
🧠 What's new: We establish a virtuous cycle where geometry and appearance mutually refine each other by synergistically combining geometric reasoning from 3D diffusion models and visual knowledge from video generation models. This process expands spatial coverage and completes unseen regions.
🏆 SOTA Results Confirmed: EvoScene achieves superior geometric stability, layout coherence, and photorealistic appearance compared to strong baselines.
Human Preference Win Rate: 78.5%–90.5% across all quality criteria.
Semantic Fidelity (CLIP): 0.8643, a 15.9% improvement over Trellis.
Read the full paper and see the visualizations below! 🧵
Project page: eric-ai-lab.github.io/evosce…
Paper: arxiv.org/abs/2512.08905
Code: github.com/eric-ai-lab/EvoSc…
#3DGeneration #ComputerVision #SceneGeneration

1
613
New update: we decided to fully convert from UCSB NLP&AI to UCSB AI for simplicity.
New X handler: x.com/UCSB_AI
New Github org: github.com/UCSB-AI
5
524
UCSB AI retweeted

🤔It is time to rethink how we evaluate agent memory
🌍 As agents become longer horizon and more autonomous, memory is no longer just a module for storing past chats.
🛠️ It determines how agents track changing worlds, learn from past actions, revise outdated information, and reuse experience for future decisions.
🔍 This raises three key questions:
Are human designed write store retrieve memory pipelines still the best choice?
If harnesses such as Codex, Claude Code, and OpenClaw already let agents observe, act, call tools, write files, and reorganize context, can memory also be managed by the harness itself?
Do current evaluations really cover how agent memory is used in realistic settings? Many benchmarks are still text centric or single modal, with limited pressure from screenshots, GUIs, tool feedback, and environment changes.
❓ Is final QA accuracy enough?
🔥 We present WorldMemArena, a multimodal benchmark for evaluating agent memory through action world interaction.
📌 Key insights:
🧩 Memory is a lifecycle, not a static cache.
📉 Better memory storage does not necessarily lead to better final performance.
🖼️ Multimodal memory remains a major bottleneck for current systems.
🌍 Real agentic trajectories expose the fragility of memory systems.
⚙️ Harness-based memory is more flexible, but still costly and unstable.

2
10
37
25,510
UCSB AI retweeted

Jun 2
𝐓𝐡𝐞 𝐁𝐢𝐭𝐭𝐞𝐫 𝐋𝐞𝐬𝐬𝐨𝐧 𝐨𝐟 𝐀𝐠𝐞𝐧𝐭𝐢𝐜 𝐌𝐞𝐦𝐨𝐫𝐲: memory should be a derived capability that exists because it makes an agent better at acting over time.
𝐖𝐨𝐫𝐥𝐝𝐌𝐞𝐦𝐀𝐫𝐞𝐧𝐚 is designed around this principle. Rather than evaluating memory as a storage problem, WorldMemArena evaluates memory through 𝐚𝐜𝐭𝐢𝐨𝐧–𝐰𝐨𝐫𝐥𝐝 𝐢𝐧𝐭𝐞𝐫𝐚𝐜𝐭𝐢𝐨𝐧, instrumenting the full write → maintain → retrieve → use lifecycle across 400 multimodal, multi-session tasks.
And it exposes the findings that should mark the end of the storage-centric era:
→ Storage ≠ use. Better memory storage and retrieval do not necessarily produce better task performance. Optimizing the component we designed does not optimize the capability we actually care about.
→ Harness-based memory performs best where memory is hardest. Agents that can write files, reorganize context, create artifacts, and interact with persistent environments adapt most effectively in long-horizon settings. They are costly and unstable today, which is exactly what many Bitter Lesson transitions look like before scaling and learning take over.
The deeper move is in what gets measured. Memory shouldn't get a score; it should be inferred from capability: how much does remembering improve performance over time.
WorldMemArena drags evaluation off the static object and into the action–world loop, the only place you can tell whether an agent has developed memory or is just simulating it convincingly.

🤔It is time to rethink how we evaluate agent memory
🌍 As agents become longer horizon and more autonomous, memory is no longer just a module for storing past chats.
🛠️ It determines how agents track changing worlds, learn from past actions, revise outdated information, and reuse experience for future decisions.
🔍 This raises three key questions:
Are human designed write store retrieve memory pipelines still the best choice?
If harnesses such as Codex, Claude Code, and OpenClaw already let agents observe, act, call tools, write files, and reorganize context, can memory also be managed by the harness itself?
Do current evaluations really cover how agent memory is used in realistic settings? Many benchmarks are still text centric or single modal, with limited pressure from screenshots, GUIs, tool feedback, and environment changes.
❓ Is final QA accuracy enough?
🔥 We present WorldMemArena, a multimodal benchmark for evaluating agent memory through action world interaction.
📌 Key insights:
🧩 Memory is a lifecycle, not a static cache.
📉 Better memory storage does not necessarily lead to better final performance.
🖼️ Multimodal memory remains a major bottleneck for current systems.
🌍 Real agentic trajectories expose the fragility of memory systems.
⚙️ Harness-based memory is more flexible, but still costly and unstable.
5
31
144
19,541
UCSB AI retweeted
May 29
Finally, this got done. It always felt off when people were treating VLAs as a separate class from multimodal LLMs. Better late than never.
May 29

Excited to share Qwen-VLA paper, our exploration of generalist Vision-Language-Action models.
It extends Qwen’s multimodal backbone from visual understanding and reasoning to continuous action generation and trajectory prediction.
Paper:
arxiv.org/pdf/2605.30280

1
5
34
7,257


Huge congrats to @_Chuhan_Li!  His paper “Learning Situated Awareness in the Real World” just took home Best Paper Runner-Up at the #CVPR2026 WMAS Workshop.
Fresh off an #ICML2026 Spotlight, massive recognition for great work in world models and active sensing.
1
5
1,865
UCSB AI retweeted

May 22
Check out the full paper for our controlled experiments on Python prediction and our deterministic DSL twin task that strips out pretraining priors to prove these dynamics!
📝 Paper: arxiv.org/abs/2605.22217
💻 Code: github.com/SophiaPx/survive-… 9/9

6
25
1,532
UCSB AI retweeted
May 22
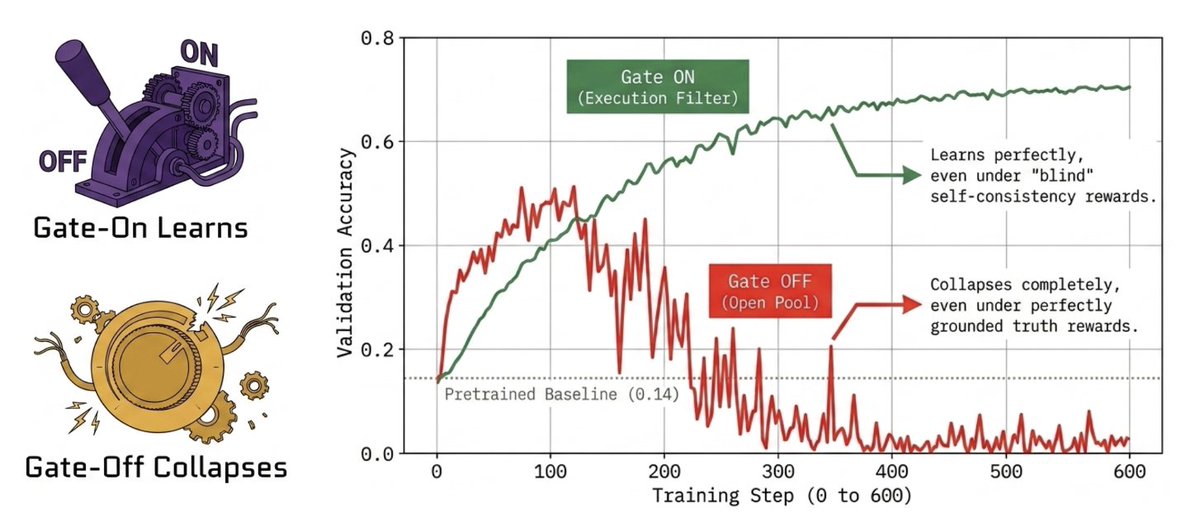
We discover the 𝐀𝐬𝐲𝐦𝐦𝐞𝐭𝐫𝐢𝐜 𝐑𝐨𝐥𝐞𝐬 𝐨𝐟 𝐃𝐚𝐭𝐚 𝐆𝐚𝐭𝐢𝐧𝐠 𝐚𝐧𝐝 𝐑𝐞𝐰𝐚𝐫𝐝 𝐆𝐫𝐨𝐮𝐧𝐝𝐢𝐧𝐠 𝐢𝐧 𝐒𝐞𝐥𝐟-𝐏𝐥𝐚𝐲 𝐑𝐋: data gating, not reward grounding, is the binding constraint on stability. A strict gate stabilizes every reward we tested, including a self-consistency reward with no access to ground truth; while no reward stabilizes once the gate is removed, not even one grounded in execution truth.
It challenges the common assumption that reward grounding is what governs self-play stability. The field's response to collapse has been better rewards: confidence penalties, momentum anchors, hacking detectors, all on the reward side. The binding constraint lives upstream, in the data pipeline.
A self-play system has two distinct levers that prior work conflates. A DATA GATE decides which proposer-generated tasks enter the training pool. A REWARD decides how the policy updates on what's admitted. The gate decides what data exists; the reward decides how the optimizer reacts. They are not symmetric!
The reward doesn't filter bad data; instead, it's maximized by it. Under self-consistency, the intrinsic–grounded gap saturates near 1.0: corrupted data receives higher reward than clean data, because intra-group agreement is easiest to maximize on ambiguous tasks.
The counterintuitive consequence we call the Grounded Proposer Paradox: a proposer with ground-truth verification access collapses FASTER than an ungrounded one when paired with a self-consistency solver. Cleaner tasks form the lowest-resistance path to the spurious self-consistent attractor. The upstream agent doesn't bias the downstream one toward truth; it sharpens the corridor to the wrong fixed point.
The shift: stop treating self-play stability as a reward-design problem. What enters the training loop matters more than how the optimizer scores it.

May 22

🚨 Why does Self-Play RL for LLMs keep collapsing? Most fixes focus on the reward signal. In our new paper "Survive or Collapse", we show that's the wrong lever. The true binding constraint is actually Data Gating: deciding which generated tasks enter the training pool. 🧵 1/n
2
24
113
26,022
📜🚨 Check out the latest from our lab on why Self-Play RL keeps collapsing in LLMs!
May 22
🚨 Why does Self-Play RL for LLMs keep collapsing? Most fixes focus on the reward signal. In our new paper "Survive or Collapse", we show that's the wrong lever. The true binding constraint is actually Data Gating: deciding which generated tasks enter the training pool. 🧵 1/n
2
366
UCSB AI retweeted
May 22
🚨 Why does Self-Play RL for LLMs keep collapsing? Most fixes focus on the reward signal. In our new paper "Survive or Collapse", we show that's the wrong lever. The true binding constraint is actually Data Gating: deciding which generated tasks enter the training pool. 🧵 1/n
7
41
258
33,658
🎓 Finishing your PhD soon and looking for your next step?
If you’re excited about AI Physics, don't miss this opportunity!
Come join our lab as a postdoc with Prof. @xwang_lk at @UCSantaBarbara World-class research on an amazing campus (home to last year’s Nobel in Physics!)🧑🔬
3
363
UCSB AI retweeted

May 19
❗️📜📢Thrilled to share this new work! Learning POMDP World Models from Observations with Language-Model Priors!
It introduces Pinductor ➡️ An LLM proposes executable POMDP code from partial observations and refines it against a belief-based likelihood, matching methods that need ground-truth hidden states 🤯
May 18

🧵1/7
Ever tried building a world model for a partially observable environment from just raw observations? It's tough - but what if LLMs could help?
We explore this question in our latest preprint: 'Learning POMDP World Models from Observations Using Language-Model Priors.'

3
2
13
962