
Joined September 2009
- Tweets 2,707
- Following 432
- Followers 3,293
- Likes 4,061
586 Photos and videos














UNC Computer Science retweeted

Jun 11
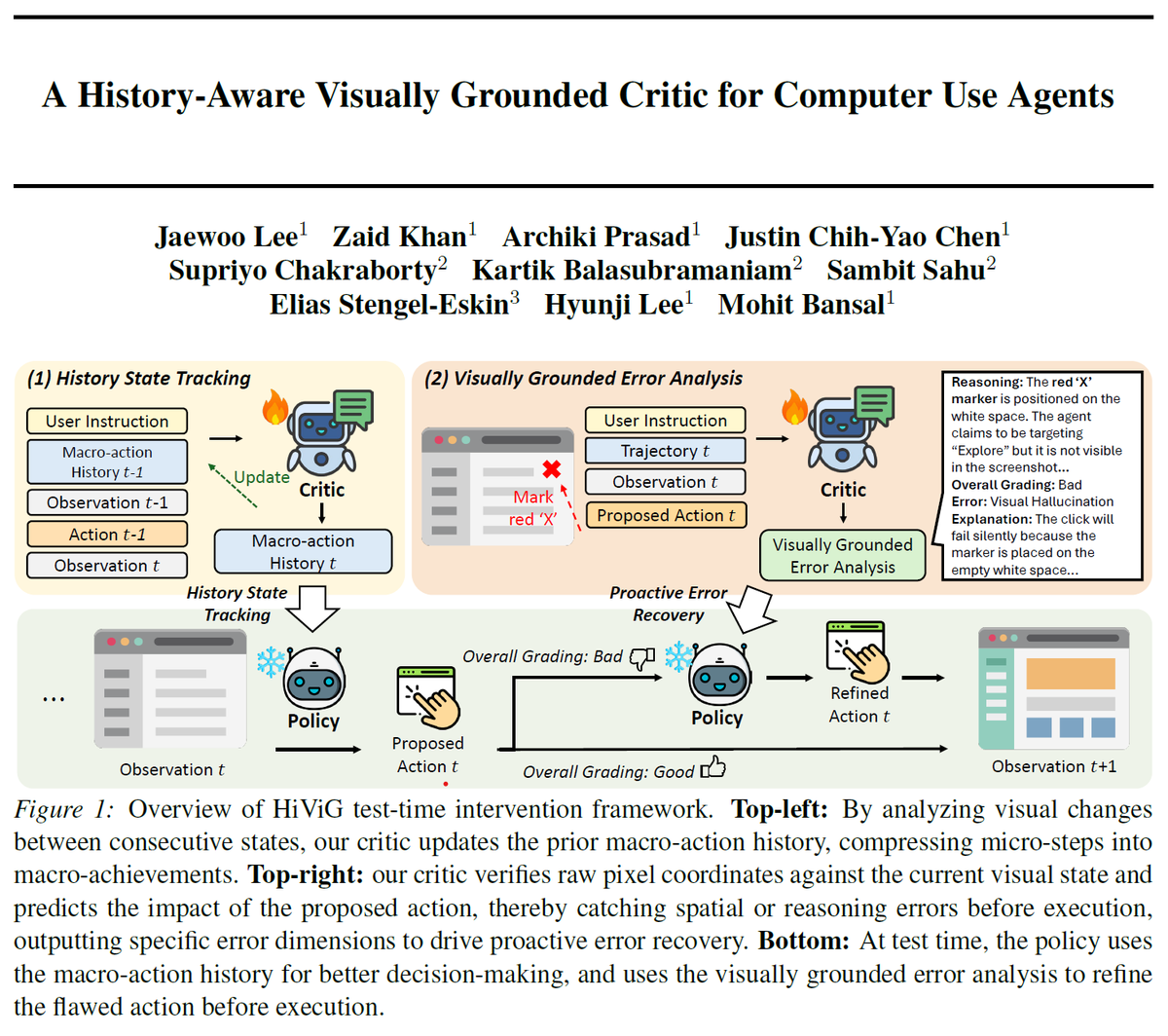
🚨 Check out HiViG, a History-aware and Visually Grounded test-time intervention framework that guides Computer Use Agents to solve long-horizon GUI tasks across web 🌐, mobile 📱, and desktop 🖥️ GUI environments!
We equip agents with two key abilities: (1) history state tracking that iteratively translates visual state changes into a compact macro-action history to track long-term goal progress and for better history-aware action generation and (2) visually grounded error analysis that evaluates proposed actions against the screenshot to refine flawed actions before execution, by generating a multi-stage rationale for error analysis that leverages a visual marker and the extracted state-transitions.
Our comprehensive experiments across diverse GUI benchmarks (WebArenaLitev2, AndroidLab, WindowsAgentArena) show that HiViG boosts avg. success rate by 5.8-9.0% across both open- and closed-source models (Qwen3-VL-32B-Thinking, Gemini-3-Flash), showing cross-platform and model-agnostic generalization (whereas baseline test-time interventions often doesn't show gain for strong policy models).
🧵👇

🚨 Introducing HiViG, a test-time intervention framework for long-horizon GUI tasks. By tracking history & verifying actions w/ visual grounding, HiViG boosts performance across diverse GUI environments even for strong policies where existing critics often degrade performance.
At test time, HiViG guides the policy in two crucial phases:
1️⃣ Before proposing an action: it provides the policy with an updated summary of past interactions for better history-aware action generation.
2️⃣ After an action is proposed: it evaluates the proposed action using visually grounded reasoning to intercept any flawed action before execution.
Across three long-horizon GUI benchmarks with various environments (WebArenaLitev2 🌐, AndroidLab 📱, WindowsAgentArena 🖥️) on strong base policies (Qwen3-VL-32B-Thinking, Gemini-3-Flash), HiViG improves average overall success rate by 5.8% and 9.0% compared to the strongest critics, showing its effectiveness and generalization across diverse GUI platforms and policies! 💪
🧵👇
2
10
22
2,034
UNC Computer Science retweeted

📄arxiv.org/abs/2606.11078
🧑💻github.com/G-JWLee/HiViG
🤗huggingface.co/papers/2606.1…
Work led by @jwlee8877 w/ @codezakh, @ArchikiPrasad, @cyjustinchen, Supriyo Chakraborty, Kartik Balasubramaniam, Sambit Sahu, @EliasEskin, @mohitban47
@unccs @unc_ai_group
1
10
258
UNC Computer Science retweeted

Jun 10
Excited to share ✨HiViG✨, a test-time intervention framework for long-horizon GUI tasks via history state tracking and visually grounded error analysis.
1️⃣ History state tracking: HiViG summarizes past interactions into a compact macro-action history, enabling better history-aware planning of policies over long horizons.
2️⃣ Visually grounded error analysis: Instead of overly relying on the policy's textual intents, HiViG verifies raw execution coordinates against the current GUI env screenshot. If an action proposed by the policy is flawed (e.g., visual hallucination, termination misjudgment), it provides corrective guidance before execution.
🚨 Introducing HiViG, a test-time intervention framework for long-horizon GUI tasks. By tracking history & verifying actions w/ visual grounding, HiViG boosts performance across diverse GUI environments even for strong policies where existing critics often degrade performance.
At test time, HiViG guides the policy in two crucial phases:
1️⃣ Before proposing an action: it provides the policy with an updated summary of past interactions for better history-aware action generation.
2️⃣ After an action is proposed: it evaluates the proposed action using visually grounded reasoning to intercept any flawed action before execution.
Across three long-horizon GUI benchmarks with various environments (WebArenaLitev2 🌐, AndroidLab 📱, WindowsAgentArena 🖥️) on strong base policies (Qwen3-VL-32B-Thinking, Gemini-3-Flash), HiViG improves average overall success rate by 5.8% and 9.0% compared to the strongest critics, showing its effectiveness and generalization across diverse GUI platforms and policies! 💪
🧵👇
11
19
1,181
UNC Computer Science retweeted
🚨 Introducing HiViG, a test-time intervention framework for long-horizon GUI tasks. By tracking history & verifying actions w/ visual grounding, HiViG boosts performance across diverse GUI environments even for strong policies where existing critics often degrade performance.
At test time, HiViG guides the policy in two crucial phases:
1️⃣ Before proposing an action: it provides the policy with an updated summary of past interactions for better history-aware action generation.
2️⃣ After an action is proposed: it evaluates the proposed action using visually grounded reasoning to intercept any flawed action before execution.
Across three long-horizon GUI benchmarks with various environments (WebArenaLitev2 🌐, AndroidLab 📱, WindowsAgentArena 🖥️) on strong base policies (Qwen3-VL-32B-Thinking, Gemini-3-Flash), HiViG improves average overall success rate by 5.8% and 9.0% compared to the strongest critics, showing its effectiveness and generalization across diverse GUI platforms and policies! 💪
🧵👇
3
24
61
10,464
UNC Computer Science retweeted

Jun 9
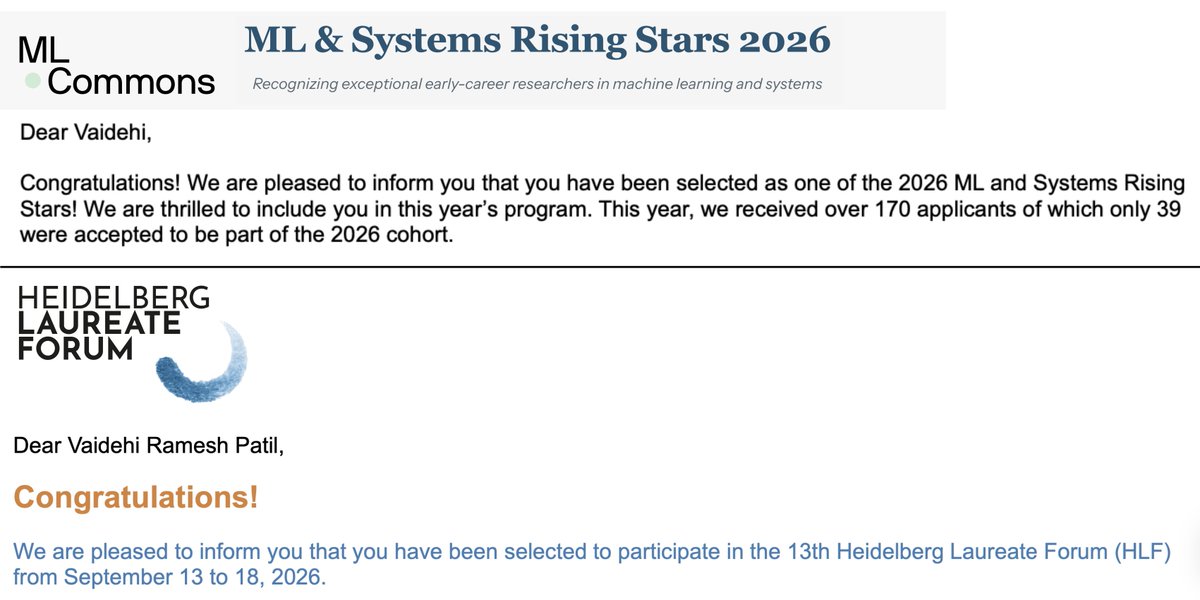
Excited and humbled to share two pieces of news!
🎉 I was selected as a 2026 @MLCommons Rising Star ⭐, joining an amazing cohort of early-career researchers working at the intersection of machine learning and systems.
🎉 I was also selected to attend the 13th Heidelberg Laureate Forum (@HLForum).
I’m thankful to my advisor @mohitban47, collaborators at @unc_ai_group and @unccs, mentors, and colleagues for their support. Looking forward to learning from and connecting with researchers in both communities!
5
9
77
6,805
UNC Computer Science retweeted

Jun 3
Next we have @mohitban47 from @UNC. Mohit need no introduction he is an expert on multimodal data. He is also winner of multiple national/international awards.




2
3
7
1,122
UNC Computer Science retweeted
Jun 3
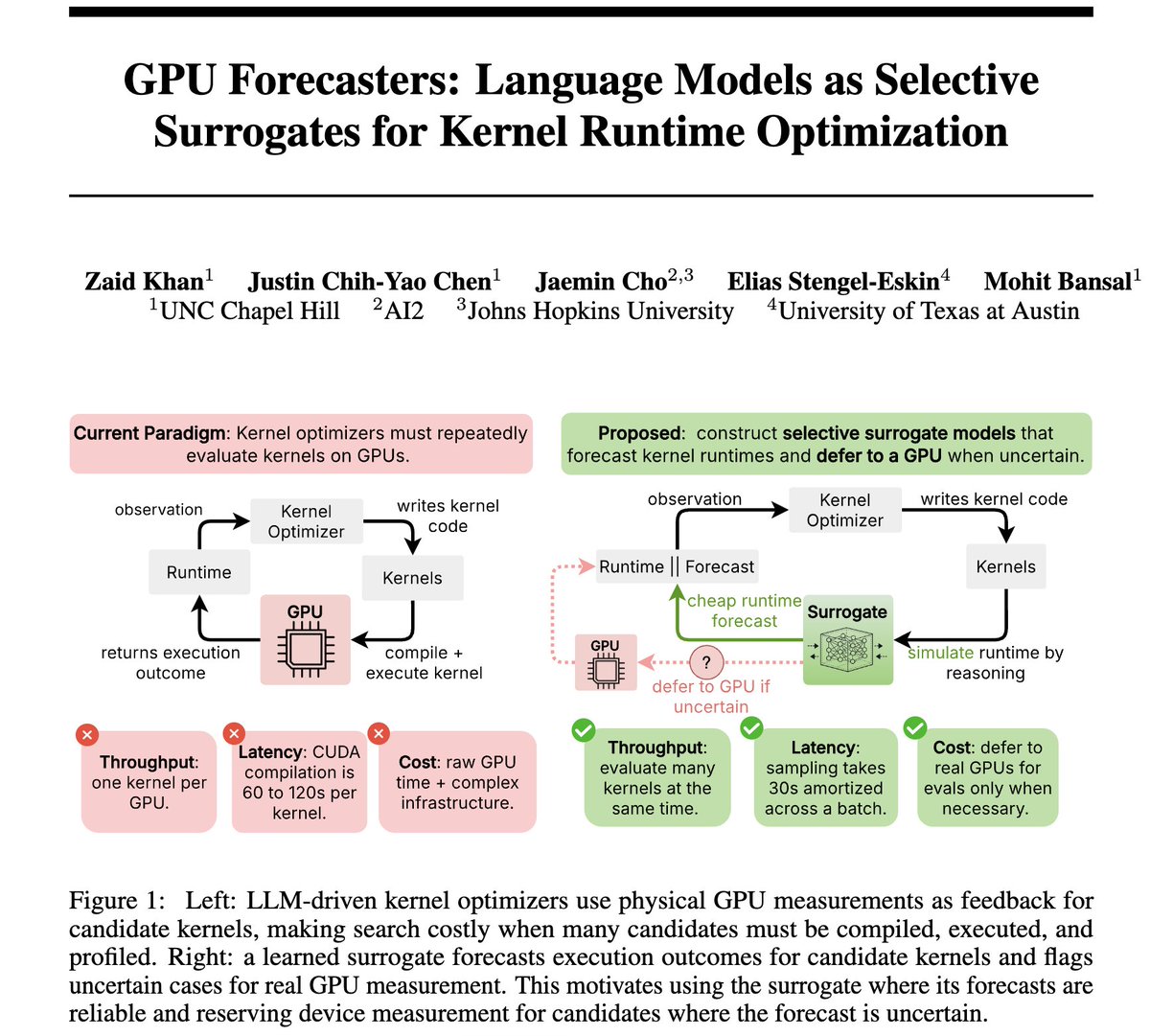
🚨 GPU Forecasters 👉 we explore if a reasoning model can be a selective world model of a GPU, forecasting a kernel's speed while deferring to real hardware when unsure, making kernel search more efficient.
Inside an evolutionary kernel search, the surrogate lets us explore many more candidates in imagination and run only the most promising on the GPU. We often find kernels as fast or faster using the same number of real GPU evaluations.
We also show that reinforcement learning with calibration rewards can teach the surrogate to know when it doesn't know, making it more reliable during search.
We see this as early work toward approximate world models of complex hardware-software systems!
🧵 👇

Can an LLM act as a selective model of a GPU during evolutionary search, by reasoning forecasting a kernel’s runtime but deferring to a GPU when unsure? We produced 12k kernels runtimes from evolutionary search, costing 400M reasoning tokens 600 GPU-hours to answer this.
In our work GPU Forecasters, we study language models as selective surrogates for GPU kernel optimization.
1️⃣ Off-the-shelf LLMs can forecast how a GPU responds to a candidate kernel with non-trivial accuracy. If we rank candidates by these predictions and measure only the top 10% on a GPU, the fastest kernel we find is within 20% of the best in the pool.
2️⃣ We want LLMs to not just be accurate but also calibrated, so that we can use their uncertainty for selective prediction: during search, we should trust only confident forecasts and verify less confident forecasts by sending them to the GPU.
3️⃣ We train an open-weights surrogate (GPT-OSS-20B) with RL to improve both accuracy and calibration. Calibration-shaped rewards improve both confidence reliability and ranking ability, while correctness rewards alone do not.
4️⃣ Inside a real kernel search, the surrogate finds faster kernels than an equal-GPU-budget baseline by considering more candidates per measurement.
5️⃣ We release 12,388 LLM-generated GPU kernels with measured runtimes spanning 118 operations, CUDA and Triton backends, 3 GPU types, taking 400M tokens 600 GPU-hours to produce. This dataset can be used for analyzing LLM-driven evolutionary program search dynamics, post-training LLMs for kernel code generation, and things we didn’t get a chance to explore, like training reward models!
Thread 🧵👇
1
8
26
3,087

Can an LLM act as a selective model of a GPU during evolutionary search, by reasoning forecasting a kernel’s runtime but deferring to a GPU when unsure? We produced 12k kernels runtimes from evolutionary search, costing 400M reasoning tokens 600 GPU-hours to answer this.
In our work GPU Forecasters, we study language models as selective surrogates for GPU kernel optimization.
1️⃣ Off-the-shelf LLMs can forecast how a GPU responds to a candidate kernel with non-trivial accuracy. If we rank candidates by these predictions and measure only the top 10% on a GPU, the fastest kernel we find is within 20% of the best in the pool.
2️⃣ We want LLMs to not just be accurate but also calibrated, so that we can use their uncertainty for selective prediction: during search, we should trust only confident forecasts and verify less confident forecasts by sending them to the GPU.
3️⃣ We train an open-weights surrogate (GPT-OSS-20B) with RL to improve both accuracy and calibration. Calibration-shaped rewards improve both confidence reliability and ranking ability, while correctness rewards alone do not.
4️⃣ Inside a real kernel search, the surrogate finds faster kernels than an equal-GPU-budget baseline by considering more candidates per measurement.
5️⃣ We release 12,388 LLM-generated GPU kernels with measured runtimes spanning 118 operations, CUDA and Triton backends, 3 GPU types, taking 400M tokens 600 GPU-hours to produce. This dataset can be used for analyzing LLM-driven evolutionary program search dynamics, post-training LLMs for kernel code generation, and things we didn’t get a chance to explore, like training reward models!
Thread 🧵👇
5
34
80
15,029
UNC Computer Science retweeted
Jun 1
👀 Seeing ≠ 🤔 Knowing in VLMs for Spatial Reasoning, which is not just about finding the right answer -- but about understanding whether the available evidence supports an answer at all (and if not, why?)
SpatialUncertain evaluates if VLMs can:
(1) recognize "spatial uncertainty" caused by occlusion & misleading perspective, and
(2) also understand what additional info/viewpoint is needed to resolve the uncertainty.
Details 👇

🚨 Excited to share SpatialUncertain — a controlled framework for evaluating whether VLMs know when not to answer spatial questions (and why).
➡️ Spatial reasoning is not just about finding the right answer—it is about knowing whether the available evidence supports an answer at all.
Visual observations can be incomplete or even misleading.
📦 Objects may be hidden by occlusion.
📐 Perspective may create misleading visual cues.
Yet today's VLMs are usually evaluated as if every question has a reliable answer. We introduce SpatialUncertain, a controlled framework for evaluating:
🔍 Can VLMs recognize when visual evidence is insufficient or unreliable?
🧭 Can they identify what additional viewpoints are needed before answering?
Thread🧵👇

7
28
3,310

🚨 Excited to share SpatialUncertain — a controlled framework for evaluating whether VLMs know when not to answer spatial questions (and why).
➡️ Spatial reasoning is not just about finding the right answer—it is about knowing whether the available evidence supports an answer at all.
Visual observations can be incomplete or even misleading.
📦 Objects may be hidden by occlusion.
📐 Perspective may create misleading visual cues.
Yet today's VLMs are usually evaluated as if every question has a reliable answer. We introduce SpatialUncertain, a controlled framework for evaluating:
🔍 Can VLMs recognize when visual evidence is insufficient or unreliable?
🧭 Can they identify what additional viewpoints are needed before answering?
Thread🧵👇
5
46
143
17,973
UNC Computer Science retweeted

Jun 1
In the second before a play develops, a basketball player can instantly recognize the defensive scheme (perception), anticipate how the defense will rotate (causal reasoning), simulate several possible outcomes (simulation), and choose the best move (decision).
Today's video AI is far from this. These models can describe what they see, but they cannot explain why something happened, predict what comes next, or decide how to respond. We introduce SVI-Bench to measure these capabilities, and to push toward models that can reason over real-world, multi-agent video.
2
12
25
2,716
UNC Computer Science retweeted
May 31
I'll be at #CVPR2026, feel free to ping if you want to meet up! Will be giving 4 different keynotes at these exciting @CVPR workshops and looking forward to engaging discussions on diverse topics 🙂
(also happy to discuss hiring at all levels: PhD, postdoc, faculty)
ps. also meet several of our awesome students/postdocs who will be attending

1
24
64
4,622

May 27
🎉 Congratulations to Profs @gberta227 and @SenguptRoni on receiving prestigious NSF Faculty Early Career Development (CAREER) Awards to support their work in computer vision!
cs.unc.edu/news-article/bert…
2
4
10
882
UNC Computer Science retweeted
May 22
🚨 Outcome rewards in LLM RL are sparse --> AVSD (Adaptive-View Self-Distillation) turns privileged info into dense token-level supervision, and instead of relying on only one privileged view, it combines multiple views and balances stable cross-view consensus vs. potentially noisy view-specific signals.
Privileged views such as full solutions, partial rationales, final answers, reference code, and feedback can all help, but none is consistently the best. AVSD uses consensus across views as the reliable update direction, then adds a view-specific residual only when it aligns with that consensus and is bounded. The result is a richer but still stable learning signal, leading to consistent gains on several math and code benchmarks across model families for each configuration we test.
🧵👇
May 21

Sparse binary rewards bottleneck LLM RL, motivating the use of privileged information in self-distillation as dense teachers. How can we use and balance multiple types of privileged info: leveraging stable cross-view info, while preserving view-specific info?
Current on-policy self-distillation methods often condition the teacher on only one type of privileged view: full solution, partial rationale, answer-only, reference code, feedback, etc. This can be suboptimal:
1️⃣ No single privileged view consistently performs best when used as a teacher.
2️⃣ Views can introduce teacher-specific artifacts from information unavailable to the student.
🧠 Adaptive-View Self-Distillation (AVSD) considers multiple privileged views jointly as a teacher family, balancing cross-view consensus and view-specific signals through a token-level gate to construct better dense learning signals.
🧵👇

1
17
38
3,680
UNC Computer Science retweeted

May 22
Honored to receive an NSF CAREER Award! 🎉
Huge thanks to my students, mentors, the amazing colleagues at @unccs , and my family for making this possible. 🙏
We'll be working on Inverse Physics — teaching computers to infer shape, reflectance, lighting, material properties, and motion from images and videos, spanning both inverse rendering and simulation.
These algorithms will advance endoscopic and laparoscopic procedures with robotic guidance (supported by our NIH grants), help robots handle delicate materials in manufacturing, and various other scientific and engineering applications.

7
4
44
3,037
UNC Computer Science retweeted

May 21
Sparse binary rewards bottleneck LLM RL, motivating the use of privileged information in self-distillation as dense teachers. How can we use and balance multiple types of privileged info: leveraging stable cross-view info, while preserving view-specific info?
Current on-policy self-distillation methods often condition the teacher on only one type of privileged view: full solution, partial rationale, answer-only, reference code, feedback, etc. This can be suboptimal:
1️⃣ No single privileged view consistently performs best when used as a teacher.
2️⃣ Views can introduce teacher-specific artifacts from information unavailable to the student.
🧠 Adaptive-View Self-Distillation (AVSD) considers multiple privileged views jointly as a teacher family, balancing cross-view consensus and view-specific signals through a token-level gate to construct better dense learning signals.
🧵👇
4
35
85
26,069
UNC Computer Science retweeted
May 20
🚨 Check out MINTEval, a new *memory interference* benchmark to stress-test agentic memory systems on:
👉 frequent & interfering context changes (avg. 86 updates)
👉 over long horizons (avg. 138.8k-token contexts, up to 1.8M)
👉 5 challenging question types (incl. long-range recovery, multi-target reasoning)
👉 4 realistic domains (state tracking, multi-turn dialogue, wikipedia revisions, code commits)
📊 Across 7 representative systems (Full Context, RAG-based, and Memory-Augmented Agents), the best performance is only 33.4%!
Other interesting findings:
🔎 Memory construction failures are a major bottleneck
🔎 Memory agents are highly sensitive to design choices
🔎 Systems strongly favor insertion over deletion/update operations
🧵👇
LLM agents & memory systems operate in continuously updated environments (Git repos, evolving docs). They must process long contexts, recover earlier information, and reason over many updates that create interference between old and new information. How well do they handle this?
We introduce MINTEval:
✅ Frequent context changes & interference (avg. 86 updates)
✅ 5 challenging question types, including long-range lookback & reasoning over multiple targets distributed across context
✅ 4 realistic domains: state tracking, multi-turn dialogue, Wikipedia revisions, GitHub commits
✅ Avg. 138.8k tokens per instance (up to 1.8M)
✅ Human verification on generated QAs = 95.6%
📊 Across 7 representative systems, MINTEval remains difficult, showing an avg. acc of 27.9%, and the best system reaches only 33.4%.
🔎 Our analysis shows:
• Memory construction failures cause a 41.7% drop
• Memory agents are highly sensitive to design choices
• Memory systems have a strong bias toward insertion operations (76.8%) over deletion/update

1
14
32
4,346
UNC Computer Science retweeted
LLM agents & memory systems operate in continuously updated environments (Git repos, evolving docs). They must process long contexts, recover earlier information, and reason over many updates that create interference between old and new information. How well do they handle this?
We introduce MINTEval:
✅ Frequent context changes & interference (avg. 86 updates)
✅ 5 challenging question types, including long-range lookback & reasoning over multiple targets distributed across context
✅ 4 realistic domains: state tracking, multi-turn dialogue, Wikipedia revisions, GitHub commits
✅ Avg. 138.8k tokens per instance (up to 1.8M)
✅ Human verification on generated QAs = 95.6%
📊 Across 7 representative systems, MINTEval remains difficult, showing an avg. acc of 27.9%, and the best system reaches only 33.4%.
🔎 Our analysis shows:
• Memory construction failures cause a 41.7% drop
• Memory agents are highly sensitive to design choices
• Memory systems have a strong bias toward insertion operations (76.8%) over deletion/update
9
37
105
23,212