
38 Photos and videos
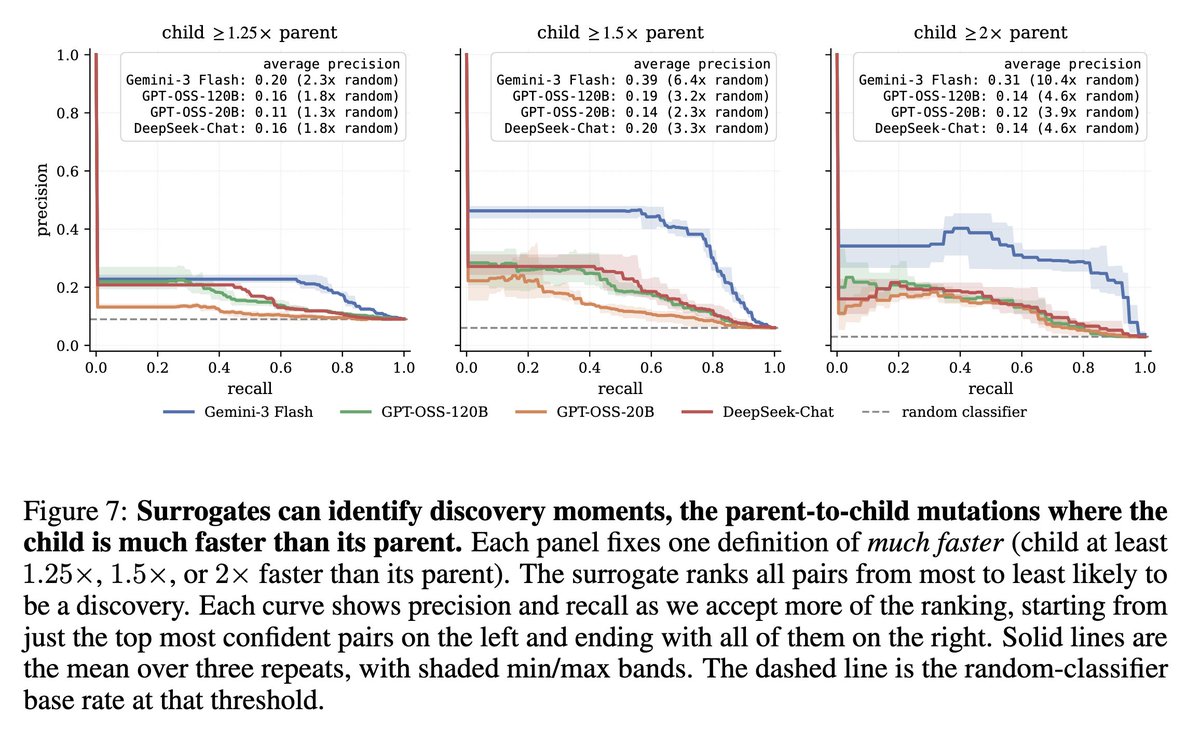
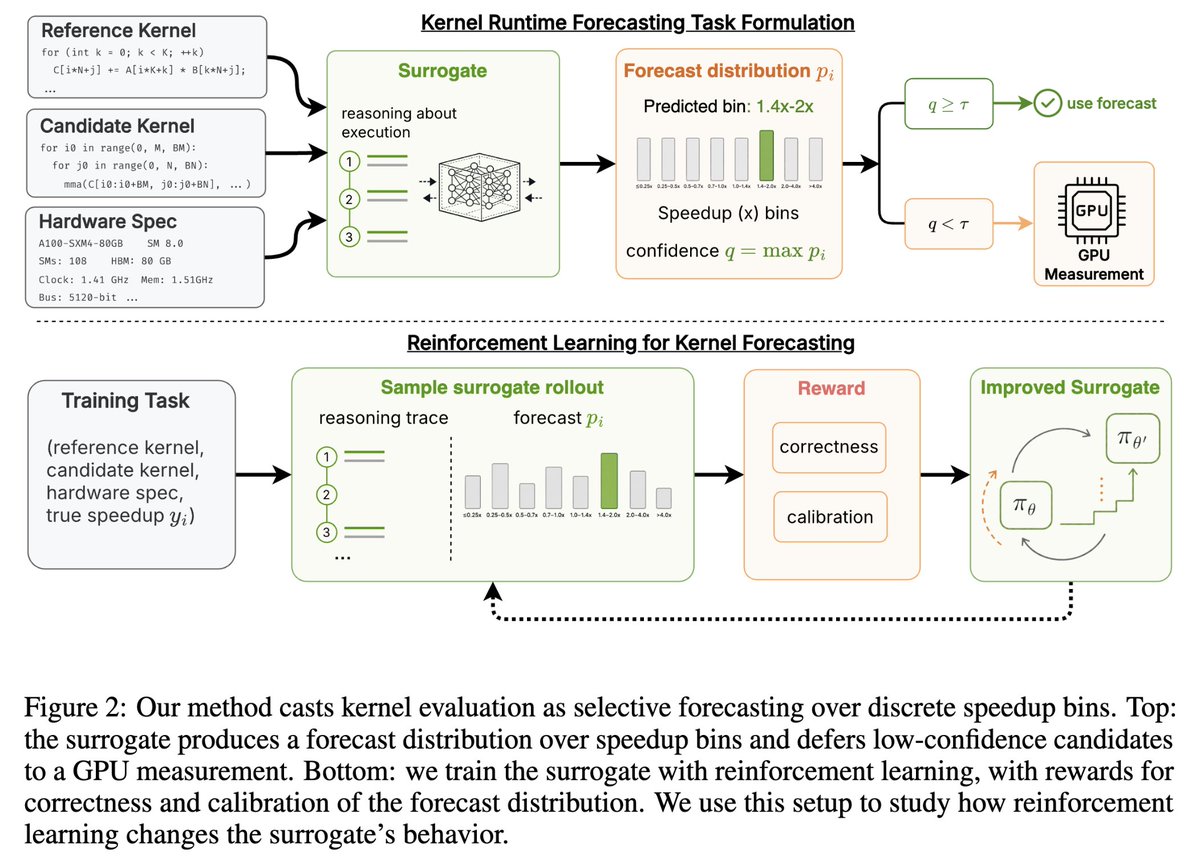
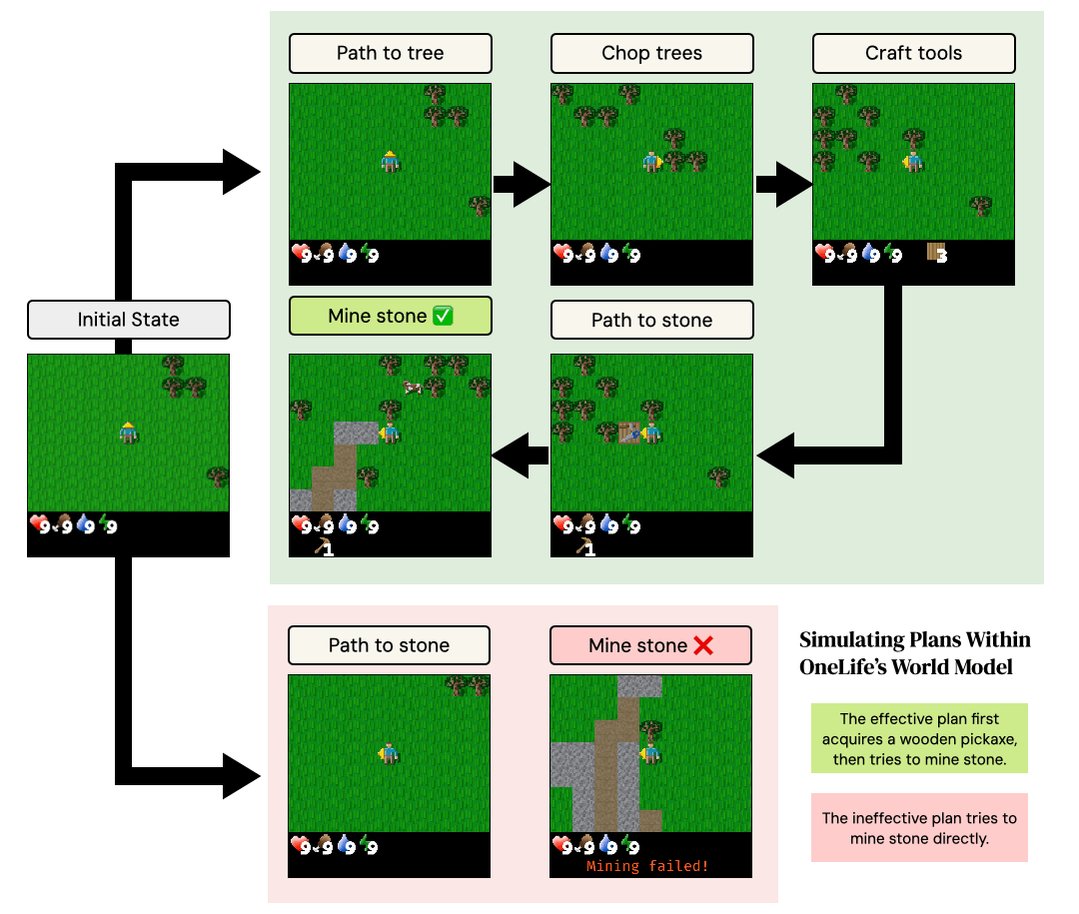
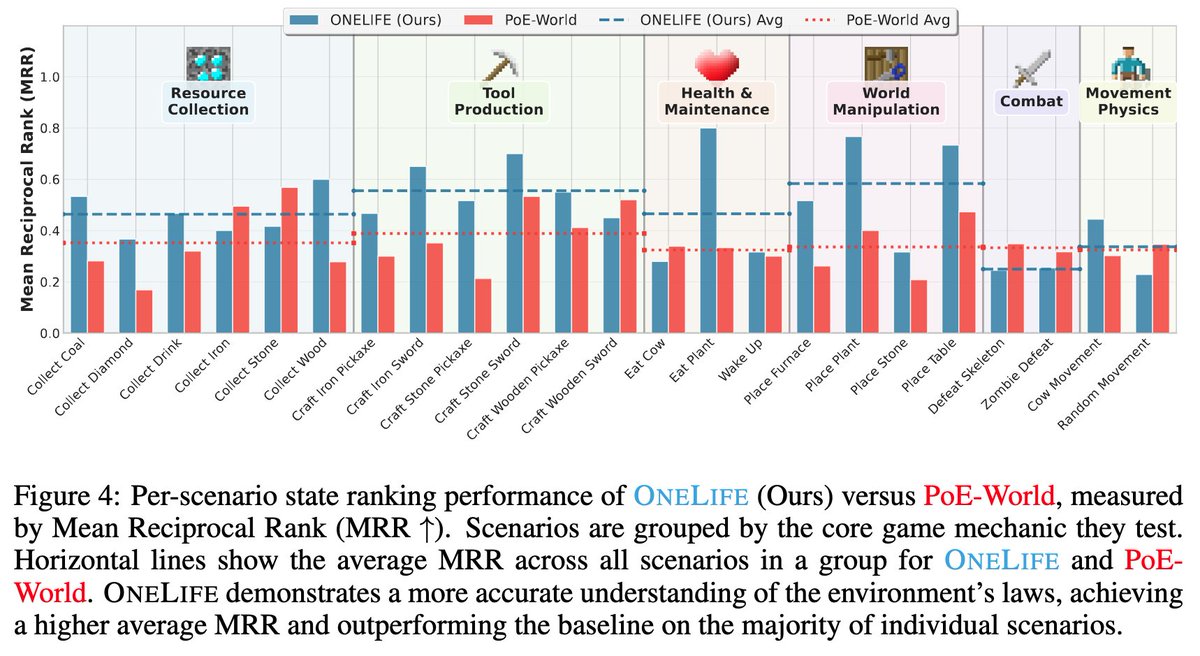
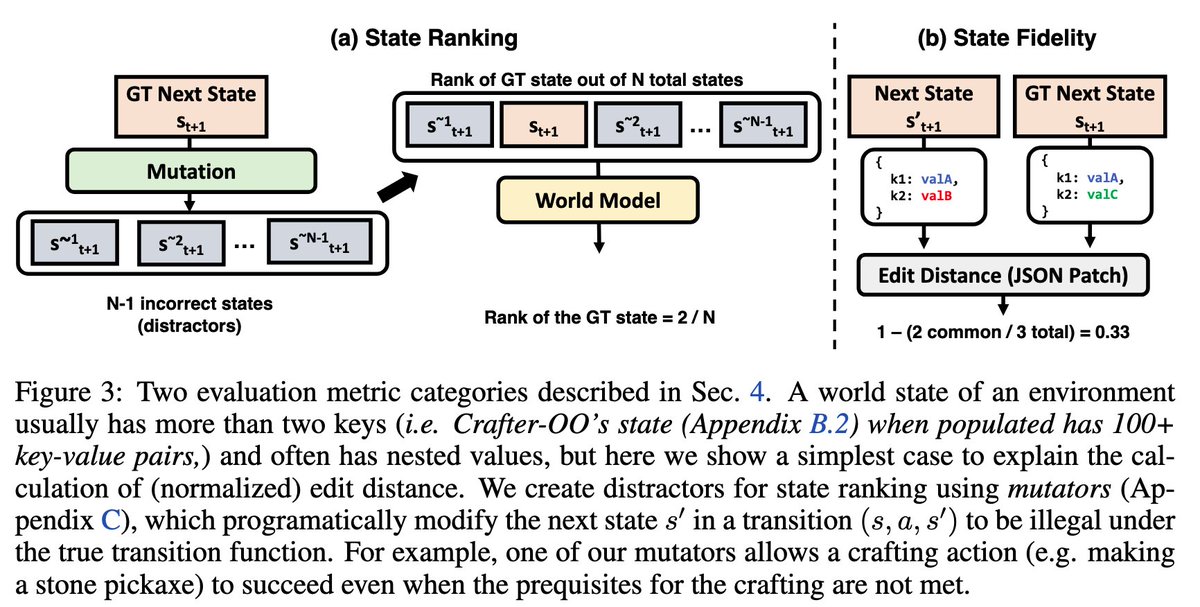

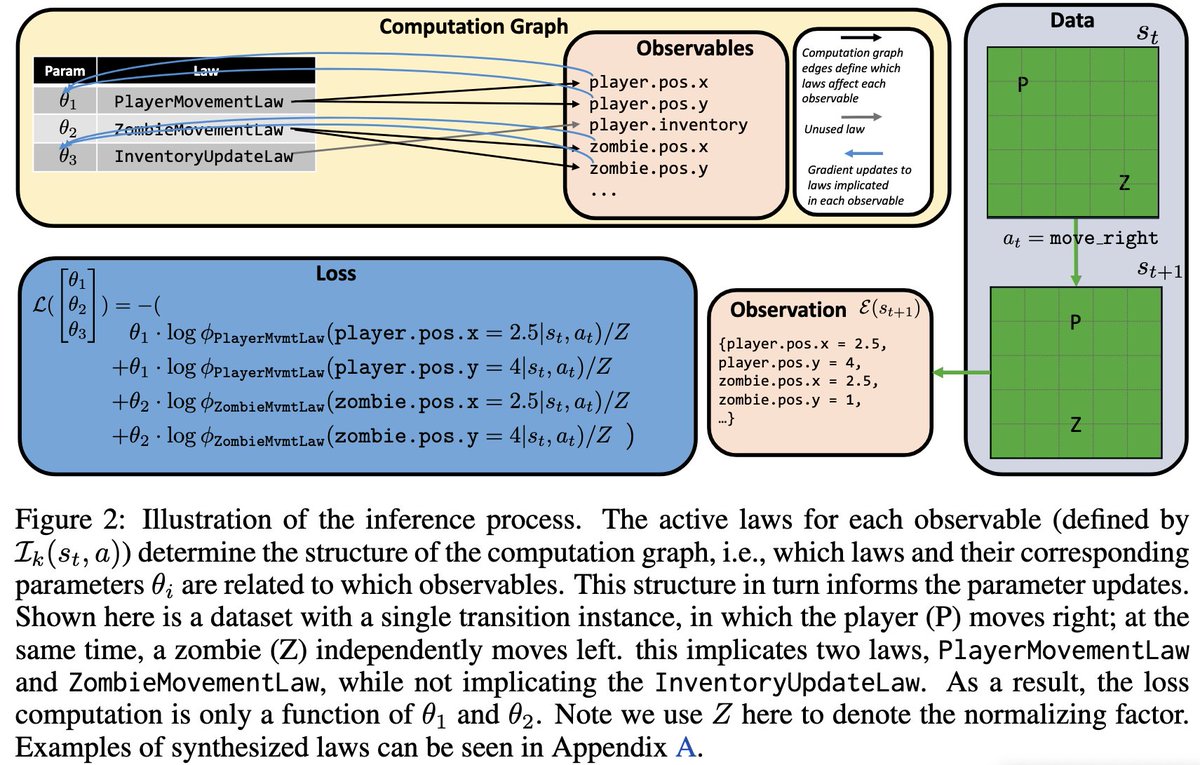


Can an LLM act as a selective model of a GPU during evolutionary search, by reasoning forecasting a kernel’s runtime but deferring to a GPU when unsure? We produced 12k kernels runtimes from evolutionary search, costing 400M reasoning tokens 600 GPU-hours to answer this.
In our work GPU Forecasters, we study language models as selective surrogates for GPU kernel optimization.
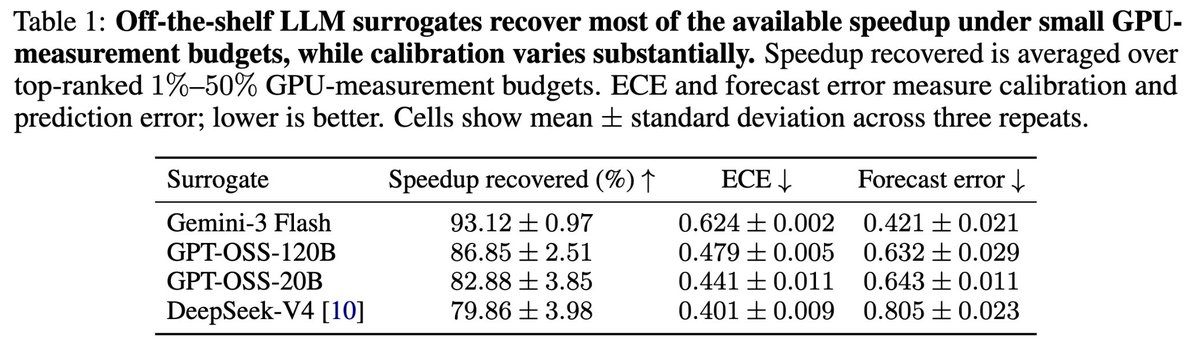
1️⃣ Off-the-shelf LLMs can forecast how a GPU responds to a candidate kernel with non-trivial accuracy. If we rank candidates by these predictions and measure only the top 10% on a GPU, the fastest kernel we find is within 20% of the best in the pool.
2️⃣ We want LLMs to not just be accurate but also calibrated, so that we can use their uncertainty for selective prediction: during search, we should trust only confident forecasts and verify less confident forecasts by sending them to the GPU.
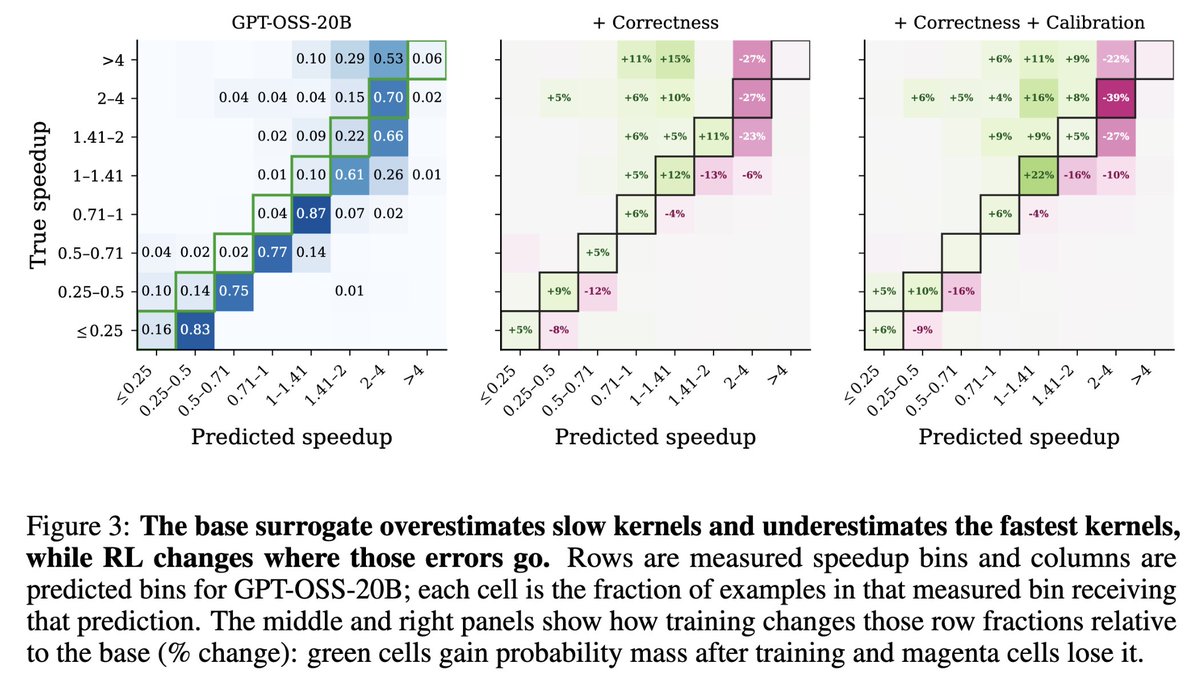
3️⃣ We train an open-weights surrogate (GPT-OSS-20B) with RL to improve both accuracy and calibration. Calibration-shaped rewards improve both confidence reliability and ranking ability, while correctness rewards alone do not.
4️⃣ Inside a real kernel search, the surrogate finds faster kernels than an equal-GPU-budget baseline by considering more candidates per measurement.
5️⃣ We release 12,388 LLM-generated GPU kernels with measured runtimes spanning 118 operations, CUDA and Triton backends, 3 GPU types, taking 400M tokens 600 GPU-hours to produce. This dataset can be used for analyzing LLM-driven evolutionary program search dynamics, post-training LLMs for kernel code generation, and things we didn’t get a chance to explore, like training reward models!
Thread 🧵👇
5
34
81
15,025
Zaid Khan retweeted

Jun 11
🚨 Check out HiViG, a History-aware and Visually Grounded test-time intervention framework that guides Computer Use Agents to solve long-horizon GUI tasks across web 🌐, mobile 📱, and desktop 🖥️ GUI environments!
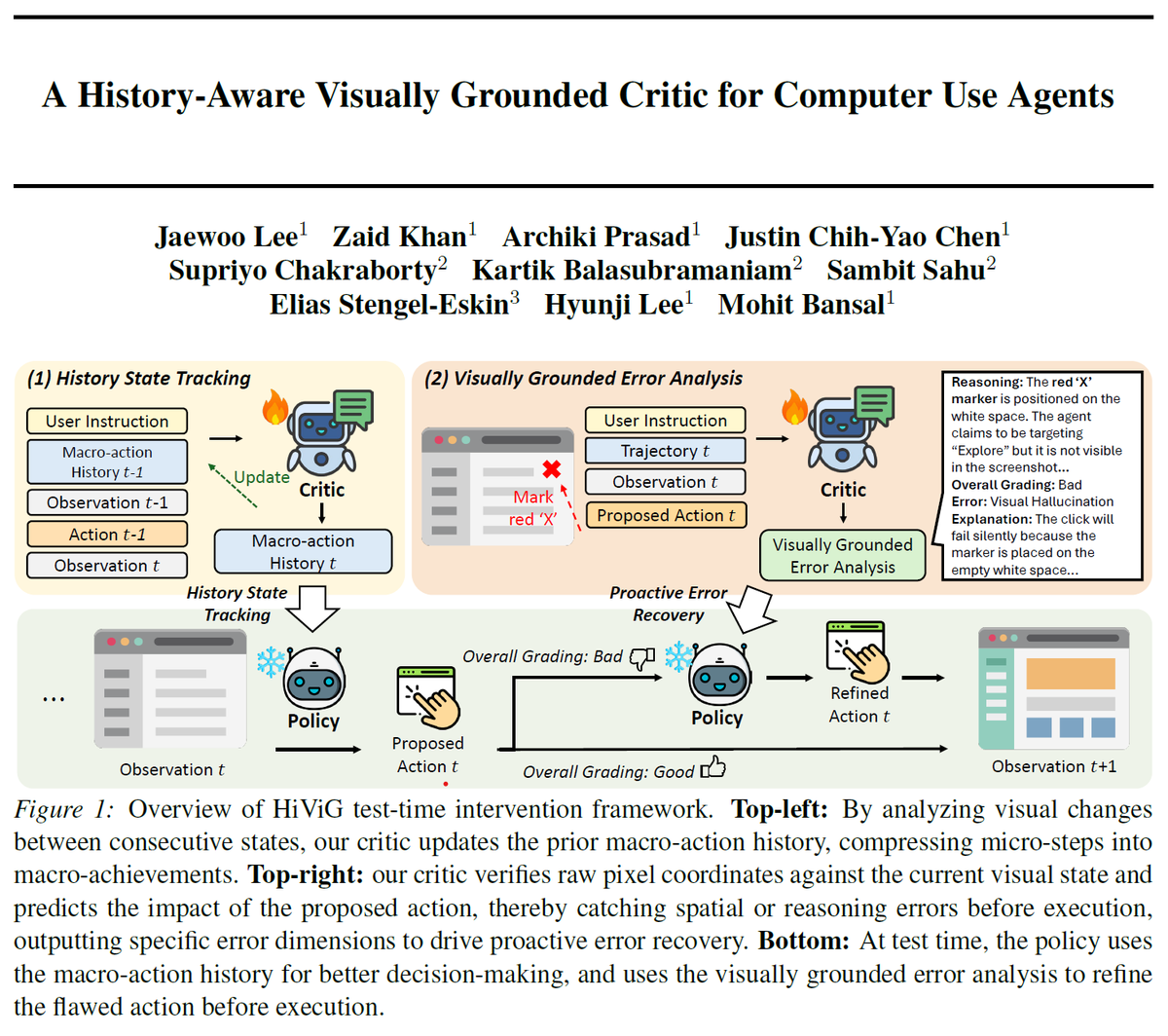
We equip agents with two key abilities: (1) history state tracking that iteratively translates visual state changes into a compact macro-action history to track long-term goal progress and for better history-aware action generation and (2) visually grounded error analysis that evaluates proposed actions against the screenshot to refine flawed actions before execution, by generating a multi-stage rationale for error analysis that leverages a visual marker and the extracted state-transitions.
Our comprehensive experiments across diverse GUI benchmarks (WebArenaLitev2, AndroidLab, WindowsAgentArena) show that HiViG boosts avg. success rate by 5.8-9.0% across both open- and closed-source models (Qwen3-VL-32B-Thinking, Gemini-3-Flash), showing cross-platform and model-agnostic generalization (whereas baseline test-time interventions often doesn't show gain for strong policy models).
🧵👇

🚨 Introducing HiViG, a test-time intervention framework for long-horizon GUI tasks. By tracking history & verifying actions w/ visual grounding, HiViG boosts performance across diverse GUI environments even for strong policies where existing critics often degrade performance.
At test time, HiViG guides the policy in two crucial phases:
1️⃣ Before proposing an action: it provides the policy with an updated summary of past interactions for better history-aware action generation.
2️⃣ After an action is proposed: it evaluates the proposed action using visually grounded reasoning to intercept any flawed action before execution.
Across three long-horizon GUI benchmarks with various environments (WebArenaLitev2 🌐, AndroidLab 📱, WindowsAgentArena 🖥️) on strong base policies (Qwen3-VL-32B-Thinking, Gemini-3-Flash), HiViG improves average overall success rate by 5.8% and 9.0% compared to the strongest critics, showing its effectiveness and generalization across diverse GUI platforms and policies! 💪
🧵👇
2
10
22
2,020
In our latest work, we train an open-weights critic that monitors guides frontier model agents on long-horizon GUI tasks. Key ideas: track visual UI changes caused by agent (don't trust the agent's intents) monitor macro actions / goals (don't let it go down rabbitholes).
The critic model works across different GUI environments (mobile, web, desktop) and is agnostic to model (works with Qwen3-VL, Gemini, etc). It's also purely pixel based, so it doesn't need a DOM / accessibility tree either!
Check out the thread for details! 👇
🚨 Introducing HiViG, a test-time intervention framework for long-horizon GUI tasks. By tracking history & verifying actions w/ visual grounding, HiViG boosts performance across diverse GUI environments even for strong policies where existing critics often degrade performance.
At test time, HiViG guides the policy in two crucial phases:
1️⃣ Before proposing an action: it provides the policy with an updated summary of past interactions for better history-aware action generation.
2️⃣ After an action is proposed: it evaluates the proposed action using visually grounded reasoning to intercept any flawed action before execution.
Across three long-horizon GUI benchmarks with various environments (WebArenaLitev2 🌐, AndroidLab 📱, WindowsAgentArena 🖥️) on strong base policies (Qwen3-VL-32B-Thinking, Gemini-3-Flash), HiViG improves average overall success rate by 5.8% and 9.0% compared to the strongest critics, showing its effectiveness and generalization across diverse GUI platforms and policies! 💪
🧵👇
5
14
1,844
Zaid Khan retweeted

Jun 10
🚨 Test-time intervention for CUA tasks is hard: history is hard to represent, actions require visual grounding and verification before execution, not after. HiViG jointly tackles these points, learning to track history and verify actions against the GUI screenshot.
As a test-time method, HiViG is compatible w/ open- and closed-source models and is domain- and model-general: we see 5.8-9% accuracy gains across WebArenaLite2 (web), AndroidLab (mobile) and WindowsAgentArena (desktop), and across models/model classes (e.g., Qwen3-VL-32B, Gemini-3-Flash), with especially large gains on challenging/long-horizon tasks ( 19.2% on WebArenaLiteV2 Maps, 18.6% on WindowsAgentArena Office).
🧵👇
🚨 Introducing HiViG, a test-time intervention framework for long-horizon GUI tasks. By tracking history & verifying actions w/ visual grounding, HiViG boosts performance across diverse GUI environments even for strong policies where existing critics often degrade performance.
At test time, HiViG guides the policy in two crucial phases:
1️⃣ Before proposing an action: it provides the policy with an updated summary of past interactions for better history-aware action generation.
2️⃣ After an action is proposed: it evaluates the proposed action using visually grounded reasoning to intercept any flawed action before execution.
Across three long-horizon GUI benchmarks with various environments (WebArenaLitev2 🌐, AndroidLab 📱, WindowsAgentArena 🖥️) on strong base policies (Qwen3-VL-32B-Thinking, Gemini-3-Flash), HiViG improves average overall success rate by 5.8% and 9.0% compared to the strongest critics, showing its effectiveness and generalization across diverse GUI platforms and policies! 💪
🧵👇
7
7
1,254
Zaid Khan retweeted

🚨Existing critics for Computer Use Agents can catch some mistakes, but often miss two things that matter most in long-horizon GUI tasks:
1⃣ They are short-sighted, focusing on the current step while losing track of what has already been accomplished.
2⃣ They lack visual grounding, making it difficult to verify whether a proposed action actually targets the correct UI element.
Introducing ✨HiViG✨, our new test-time intervention framework, which helps GUI agents in two ways:
• Before action generation: it provides a compact, history-aware summary of completed achievements to support long-horizon planning.
• After action generation: it performs a visually grounded critique to verify proposed actions against the current screenshot and intercept mistakes before they happen.
Across WebArenaLitev2 (Web), AndroidLab (Mobile), and WindowsAgentArena (Desktop), HiViG consistently improves strong base policies, including Qwen3-VL-32B-Thinking ( 5.8%) and Gemini-3-Flash ( 9.0%)!
We also find that:
• History awareness helps agents maintain progress and avoid short-sighted decision loops in long-horizon tasks.
• Visual grounding enables critics to catch execution-level errors that text-only critics often miss.
• Combining both leads to robust gains across all three environments.
🧵👇
🚨 Introducing HiViG, a test-time intervention framework for long-horizon GUI tasks. By tracking history & verifying actions w/ visual grounding, HiViG boosts performance across diverse GUI environments even for strong policies where existing critics often degrade performance.
At test time, HiViG guides the policy in two crucial phases:
1️⃣ Before proposing an action: it provides the policy with an updated summary of past interactions for better history-aware action generation.
2️⃣ After an action is proposed: it evaluates the proposed action using visually grounded reasoning to intercept any flawed action before execution.
Across three long-horizon GUI benchmarks with various environments (WebArenaLitev2 🌐, AndroidLab 📱, WindowsAgentArena 🖥️) on strong base policies (Qwen3-VL-32B-Thinking, Gemini-3-Flash), HiViG improves average overall success rate by 5.8% and 9.0% compared to the strongest critics, showing its effectiveness and generalization across diverse GUI platforms and policies! 💪
🧵👇
1
9
17
1,281
Zaid Khan retweeted

Jun 10
Excited to share ✨HiViG✨, a test-time intervention framework for long-horizon GUI tasks via history state tracking and visually grounded error analysis.
1️⃣ History state tracking: HiViG summarizes past interactions into a compact macro-action history, enabling better history-aware planning of policies over long horizons.
2️⃣ Visually grounded error analysis: Instead of overly relying on the policy's textual intents, HiViG verifies raw execution coordinates against the current GUI env screenshot. If an action proposed by the policy is flawed (e.g., visual hallucination, termination misjudgment), it provides corrective guidance before execution.
🚨 Introducing HiViG, a test-time intervention framework for long-horizon GUI tasks. By tracking history & verifying actions w/ visual grounding, HiViG boosts performance across diverse GUI environments even for strong policies where existing critics often degrade performance.
At test time, HiViG guides the policy in two crucial phases:
1️⃣ Before proposing an action: it provides the policy with an updated summary of past interactions for better history-aware action generation.
2️⃣ After an action is proposed: it evaluates the proposed action using visually grounded reasoning to intercept any flawed action before execution.
Across three long-horizon GUI benchmarks with various environments (WebArenaLitev2 🌐, AndroidLab 📱, WindowsAgentArena 🖥️) on strong base policies (Qwen3-VL-32B-Thinking, Gemini-3-Flash), HiViG improves average overall success rate by 5.8% and 9.0% compared to the strongest critics, showing its effectiveness and generalization across diverse GUI platforms and policies! 💪
🧵👇
10
18
1,140
Zaid Khan retweeted

🚨 Introducing HiViG, a test-time intervention framework for long-horizon GUI tasks. By tracking history & verifying actions w/ visual grounding, HiViG boosts performance across diverse GUI environments even for strong policies where existing critics often degrade performance.
At test time, HiViG guides the policy in two crucial phases:
1️⃣ Before proposing an action: it provides the policy with an updated summary of past interactions for better history-aware action generation.
2️⃣ After an action is proposed: it evaluates the proposed action using visually grounded reasoning to intercept any flawed action before execution.
Across three long-horizon GUI benchmarks with various environments (WebArenaLitev2 🌐, AndroidLab 📱, WindowsAgentArena 🖥️) on strong base policies (Qwen3-VL-32B-Thinking, Gemini-3-Flash), HiViG improves average overall success rate by 5.8% and 9.0% compared to the strongest critics, showing its effectiveness and generalization across diverse GUI platforms and policies! 💪
🧵👇
3
24
62
10,372
Zaid Khan retweeted

Jun 9
Excited and humbled to share two pieces of news!
🎉 I was selected as a 2026 @MLCommons Rising Star ⭐, joining an amazing cohort of early-career researchers working at the intersection of machine learning and systems.
🎉 I was also selected to attend the 13th Heidelberg Laureate Forum (@HLForum).
I’m thankful to my advisor @mohitban47, collaborators at @unc_ai_group and @unccs, mentors, and colleagues for their support. Looking forward to learning from and connecting with researchers in both communities!
5
9
77
6,799
Can an LLM act as a selective model of a GPU during evolutionary search, by reasoning forecasting a kernel’s runtime but deferring to a GPU when unsure? We produced 12k kernels runtimes from evolutionary search, costing 400M reasoning tokens 600 GPU-hours to answer this.
In our work GPU Forecasters, we study language models as selective surrogates for GPU kernel optimization.
1️⃣ Off-the-shelf LLMs can forecast how a GPU responds to a candidate kernel with non-trivial accuracy. If we rank candidates by these predictions and measure only the top 10% on a GPU, the fastest kernel we find is within 20% of the best in the pool.
2️⃣ We want LLMs to not just be accurate but also calibrated, so that we can use their uncertainty for selective prediction: during search, we should trust only confident forecasts and verify less confident forecasts by sending them to the GPU.
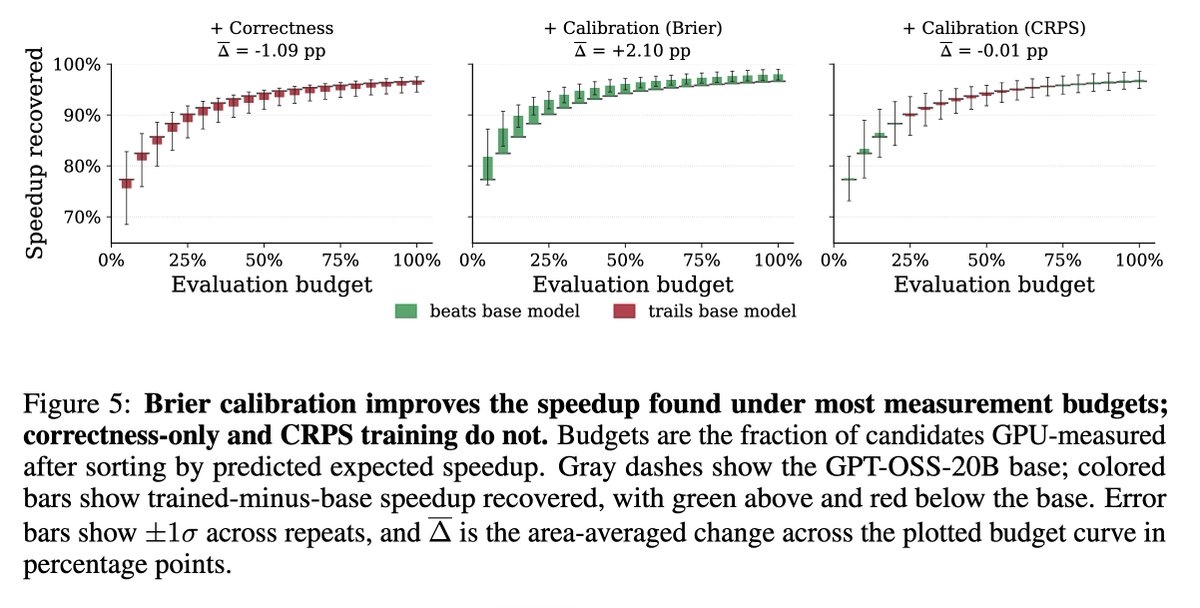
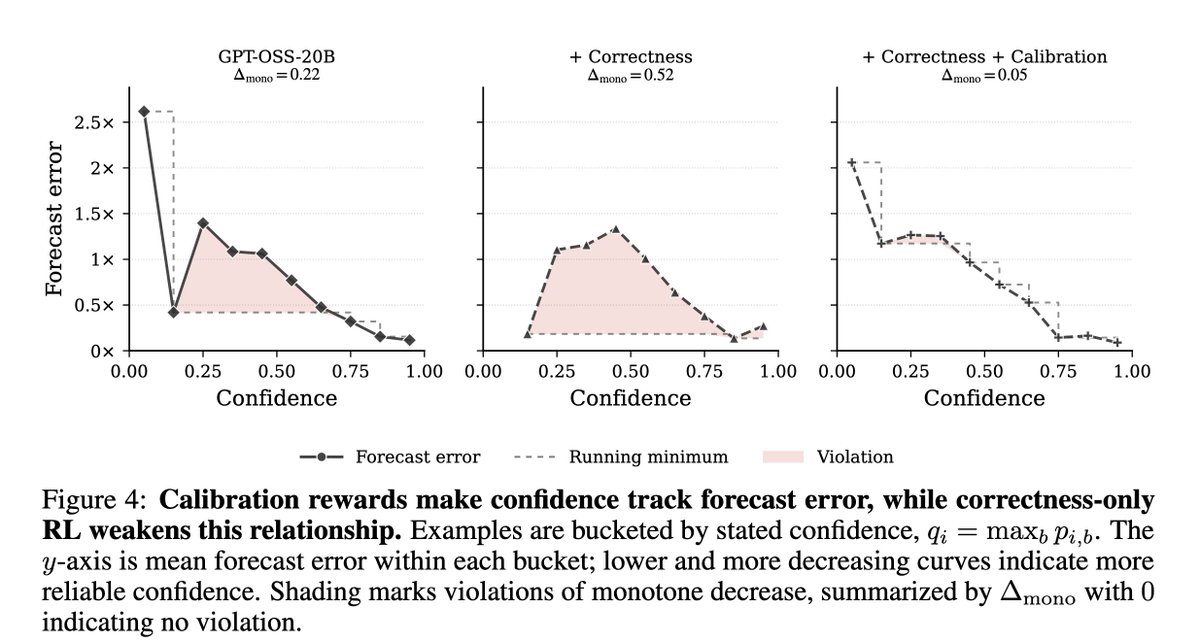
3️⃣ We train an open-weights surrogate (GPT-OSS-20B) with RL to improve both accuracy and calibration. Calibration-shaped rewards improve both confidence reliability and ranking ability, while correctness rewards alone do not.
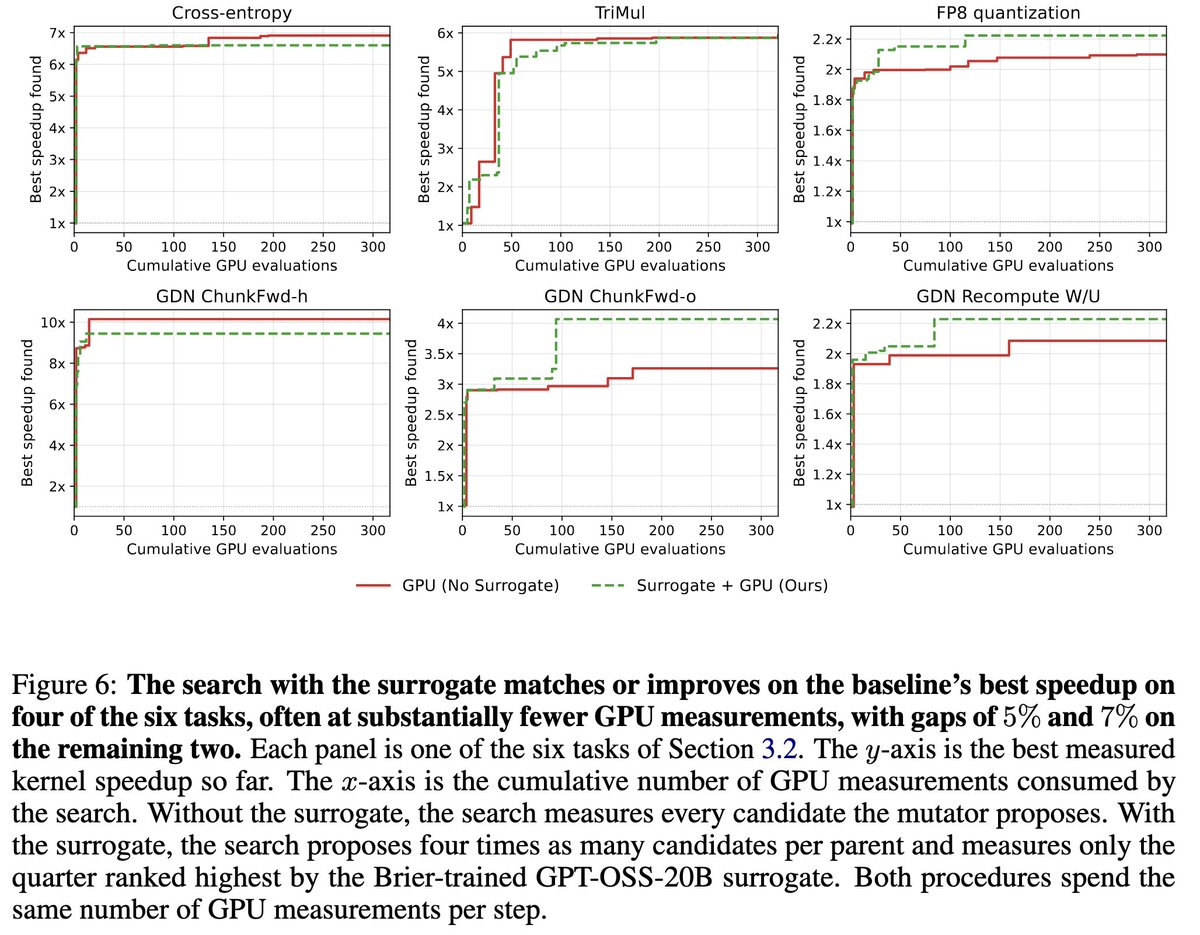
4️⃣ Inside a real kernel search, the surrogate finds faster kernels than an equal-GPU-budget baseline by considering more candidates per measurement.
5️⃣ We release 12,388 LLM-generated GPU kernels with measured runtimes spanning 118 operations, CUDA and Triton backends, 3 GPU types, taking 400M tokens 600 GPU-hours to produce. This dataset can be used for analyzing LLM-driven evolutionary program search dynamics, post-training LLMs for kernel code generation, and things we didn’t get a chance to explore, like training reward models!
Thread 🧵👇
5
34
81
15,025
Zaid Khan retweeted

Jun 2
I like this! Been curious about whether LLMs can reason through how kernel edits affect space and time. Not sure if roofline analysis by LLMs is trustworthy 🤣

Can an LLM act as a selective model of a GPU during evolutionary search, by reasoning forecasting a kernel’s runtime but deferring to a GPU when unsure? We produced 12k kernels runtimes from evolutionary search, costing 400M reasoning tokens 600 GPU-hours to answer this.
In our work GPU Forecasters, we study language models as selective surrogates for GPU kernel optimization.
1️⃣ Off-the-shelf LLMs can forecast how a GPU responds to a candidate kernel with non-trivial accuracy. If we rank candidates by these predictions and measure only the top 10% on a GPU, the fastest kernel we find is within 20% of the best in the pool.
2️⃣ We want LLMs to not just be accurate but also calibrated, so that we can use their uncertainty for selective prediction: during search, we should trust only confident forecasts and verify less confident forecasts by sending them to the GPU.
3️⃣ We train an open-weights surrogate (GPT-OSS-20B) with RL to improve both accuracy and calibration. Calibration-shaped rewards improve both confidence reliability and ranking ability, while correctness rewards alone do not.
4️⃣ Inside a real kernel search, the surrogate finds faster kernels than an equal-GPU-budget baseline by considering more candidates per measurement.
5️⃣ We release 12,388 LLM-generated GPU kernels with measured runtimes spanning 118 operations, CUDA and Triton backends, 3 GPU types, taking 400M tokens 600 GPU-hours to produce. This dataset can be used for analyzing LLM-driven evolutionary program search dynamics, post-training LLMs for kernel code generation, and things we didn’t get a chance to explore, like training reward models!
Thread 🧵👇
1
2
587
Zaid Khan retweeted
Jun 3
🚨 GPU Forecasters 👉 we explore if a reasoning model can be a selective world model of a GPU, forecasting a kernel's speed while deferring to real hardware when unsure, making kernel search more efficient.
Inside an evolutionary kernel search, the surrogate lets us explore many more candidates in imagination and run only the most promising on the GPU. We often find kernels as fast or faster using the same number of real GPU evaluations.
We also show that reinforcement learning with calibration rewards can teach the surrogate to know when it doesn't know, making it more reliable during search.
We see this as early work toward approximate world models of complex hardware-software systems!
🧵 👇
Can an LLM act as a selective model of a GPU during evolutionary search, by reasoning forecasting a kernel’s runtime but deferring to a GPU when unsure? We produced 12k kernels runtimes from evolutionary search, costing 400M reasoning tokens 600 GPU-hours to answer this.
In our work GPU Forecasters, we study language models as selective surrogates for GPU kernel optimization.
1️⃣ Off-the-shelf LLMs can forecast how a GPU responds to a candidate kernel with non-trivial accuracy. If we rank candidates by these predictions and measure only the top 10% on a GPU, the fastest kernel we find is within 20% of the best in the pool.
2️⃣ We want LLMs to not just be accurate but also calibrated, so that we can use their uncertainty for selective prediction: during search, we should trust only confident forecasts and verify less confident forecasts by sending them to the GPU.
3️⃣ We train an open-weights surrogate (GPT-OSS-20B) with RL to improve both accuracy and calibration. Calibration-shaped rewards improve both confidence reliability and ranking ability, while correctness rewards alone do not.
4️⃣ Inside a real kernel search, the surrogate finds faster kernels than an equal-GPU-budget baseline by considering more candidates per measurement.
5️⃣ We release 12,388 LLM-generated GPU kernels with measured runtimes spanning 118 operations, CUDA and Triton backends, 3 GPU types, taking 400M tokens 600 GPU-hours to produce. This dataset can be used for analyzing LLM-driven evolutionary program search dynamics, post-training LLMs for kernel code generation, and things we didn’t get a chance to explore, like training reward models!
Thread 🧵👇
1
8
26
3,087
Appreciate the shoutout @_akhaliq for our work on "GPU Forecasters" exploring whether language models can act as selective surrogates for GPU kernel optimization! Details in our thread: x.com/codezakh/status/206184…

GPU Forecasters
Language Models as Selective Surrogates for Kernel Runtime Optimization

4
27
10,849
Zaid Khan retweeted
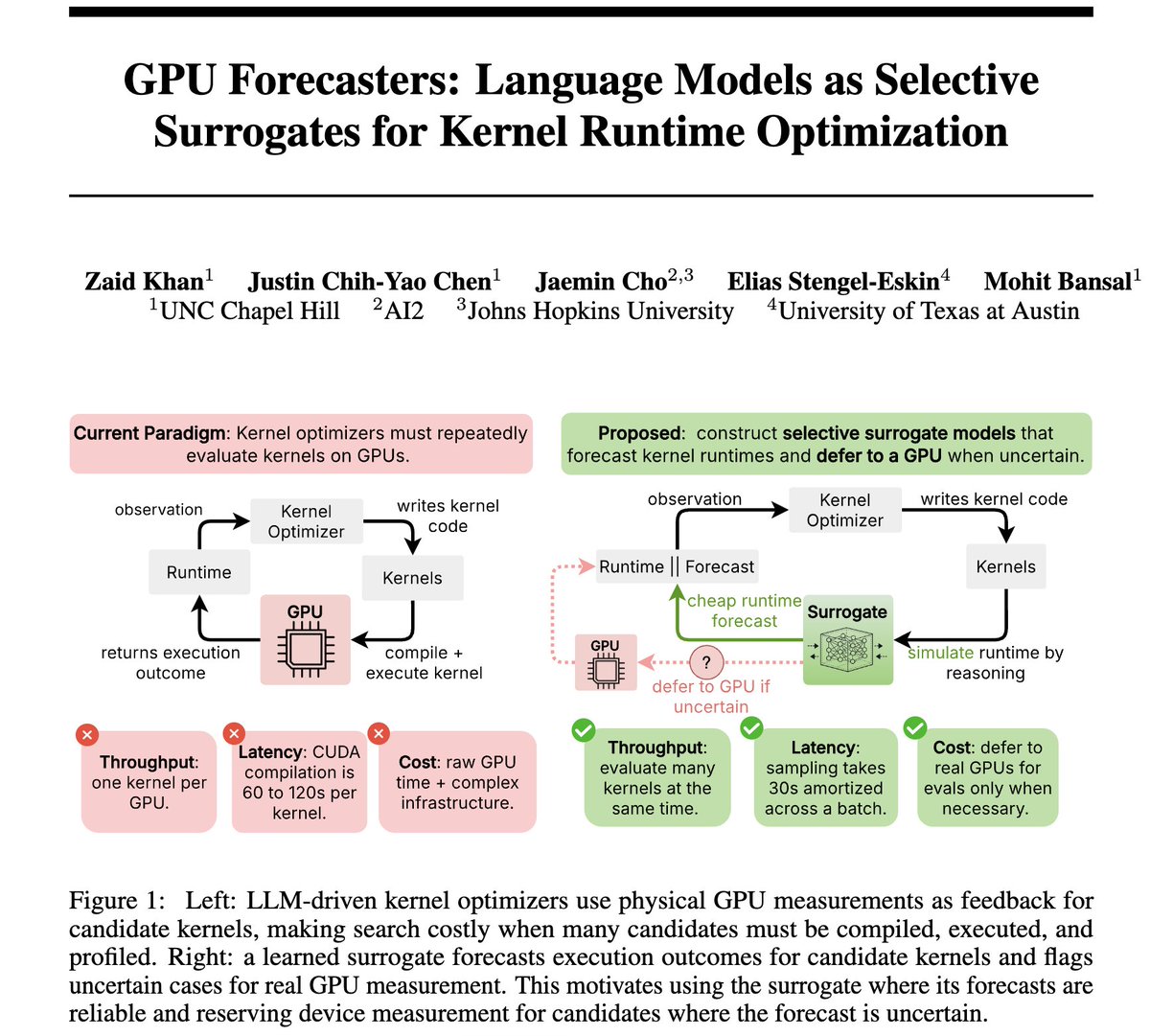
🚨LLMs are increasingly used to generate GPU kernels, but evaluating those kernels still requires expensive compilation and execution on real hardware.
Can LLMs act not just as kernel generators, but also forecasting kernel performance and deferring to hardware only when uncertain?
Introducing ✨GPU Forecasters✨, our new study of LLMs as selective surrogates for GPU kernel optimization across:
• 12,388 measured kernels across 118 operations
• CUDA Triton backends & 3 GPU types
• 400M tokens 600 GPU-hours
We find that:
1⃣Off-the-shelf LLMs can predict relative kernel performance surprisingly well. Measuring only the top 10% of LLM-ranked candidates recovers kernels within 20% of the best available.
2⃣Accuracy alone isn't enough. A useful surrogate must be calibrated, i.e., knowing when to trust its forecasts and when to defer to the GPU.
3⃣Inside a real evolutionary kernel search, the surrogate evaluates far more candidates under the same GPU budget, leading to faster kernels than an equal-budget baseline.
More results, analysis, and released data in the thread
🧵👇
Can an LLM act as a selective model of a GPU during evolutionary search, by reasoning forecasting a kernel’s runtime but deferring to a GPU when unsure? We produced 12k kernels runtimes from evolutionary search, costing 400M reasoning tokens 600 GPU-hours to answer this.
In our work GPU Forecasters, we study language models as selective surrogates for GPU kernel optimization.
1️⃣ Off-the-shelf LLMs can forecast how a GPU responds to a candidate kernel with non-trivial accuracy. If we rank candidates by these predictions and measure only the top 10% on a GPU, the fastest kernel we find is within 20% of the best in the pool.
2️⃣ We want LLMs to not just be accurate but also calibrated, so that we can use their uncertainty for selective prediction: during search, we should trust only confident forecasts and verify less confident forecasts by sending them to the GPU.
3️⃣ We train an open-weights surrogate (GPT-OSS-20B) with RL to improve both accuracy and calibration. Calibration-shaped rewards improve both confidence reliability and ranking ability, while correctness rewards alone do not.
4️⃣ Inside a real kernel search, the surrogate finds faster kernels than an equal-GPU-budget baseline by considering more candidates per measurement.
5️⃣ We release 12,388 LLM-generated GPU kernels with measured runtimes spanning 118 operations, CUDA and Triton backends, 3 GPU types, taking 400M tokens 600 GPU-hours to produce. This dataset can be used for analyzing LLM-driven evolutionary program search dynamics, post-training LLMs for kernel code generation, and things we didn’t get a chance to explore, like training reward models!
Thread 🧵👇
1
7
14
1,824
Zaid Khan retweeted

Jun 2
Can LLMs predict GPU kernel runtimes instead of measuring them on actual hardware?
We find that:
- LLMs act as great selective surrogates (deferring to GPUs when unsure)
- RL improves LLM accuracy & calibration
- Kernel search becomes much more efficient
We're releasing 12K kernels runtimes for the community to build on.
Great work led by Zaid! Check more details 🧵
Can an LLM act as a selective model of a GPU during evolutionary search, by reasoning forecasting a kernel’s runtime but deferring to a GPU when unsure? We produced 12k kernels runtimes from evolutionary search, costing 400M reasoning tokens 600 GPU-hours to answer this.
In our work GPU Forecasters, we study language models as selective surrogates for GPU kernel optimization.
1️⃣ Off-the-shelf LLMs can forecast how a GPU responds to a candidate kernel with non-trivial accuracy. If we rank candidates by these predictions and measure only the top 10% on a GPU, the fastest kernel we find is within 20% of the best in the pool.
2️⃣ We want LLMs to not just be accurate but also calibrated, so that we can use their uncertainty for selective prediction: during search, we should trust only confident forecasts and verify less confident forecasts by sending them to the GPU.
3️⃣ We train an open-weights surrogate (GPT-OSS-20B) with RL to improve both accuracy and calibration. Calibration-shaped rewards improve both confidence reliability and ranking ability, while correctness rewards alone do not.
4️⃣ Inside a real kernel search, the surrogate finds faster kernels than an equal-GPU-budget baseline by considering more candidates per measurement.
5️⃣ We release 12,388 LLM-generated GPU kernels with measured runtimes spanning 118 operations, CUDA and Triton backends, 3 GPU types, taking 400M tokens 600 GPU-hours to produce. This dataset can be used for analyzing LLM-driven evolutionary program search dynamics, post-training LLMs for kernel code generation, and things we didn’t get a chance to explore, like training reward models!
Thread 🧵👇
2
8
35
4,669
Zaid Khan retweeted
GPU kernels are the engines powering NNs, making their optimization a key to self-improving agents. But search over kernels is expensive because eval on hardware takes time.
We train calibrated surrogate models that forecast kernel speedups w/out execution. Calibration is key here as it lets us perform selective prediction, off-loading uncertain predictions to the GPU while trusting more certain ones.
We see this as a first step towards building world models for hardware-software systems!
Key findings:
▪️ We find that off-the-shelf models can perform forecasting and we show how we can use calibration losses to improve them
▪️ We also show how our selective surrogate models can be incorporated into real kernel searches, leading search to converge on faster kernels under the same budget and breaking out of stagnant searches
▪️ Along the way, we built up a sizeable dataset of >12k generated kernels with their runtimes. This is an important resource for future work in this area, and opens up a lot of interesting research directions in predicting kernel performance.
Check out the 🧵 and paper for more details! 👇
Can an LLM act as a selective model of a GPU during evolutionary search, by reasoning forecasting a kernel’s runtime but deferring to a GPU when unsure? We produced 12k kernels runtimes from evolutionary search, costing 400M reasoning tokens 600 GPU-hours to answer this.
In our work GPU Forecasters, we study language models as selective surrogates for GPU kernel optimization.
1️⃣ Off-the-shelf LLMs can forecast how a GPU responds to a candidate kernel with non-trivial accuracy. If we rank candidates by these predictions and measure only the top 10% on a GPU, the fastest kernel we find is within 20% of the best in the pool.
2️⃣ We want LLMs to not just be accurate but also calibrated, so that we can use their uncertainty for selective prediction: during search, we should trust only confident forecasts and verify less confident forecasts by sending them to the GPU.
3️⃣ We train an open-weights surrogate (GPT-OSS-20B) with RL to improve both accuracy and calibration. Calibration-shaped rewards improve both confidence reliability and ranking ability, while correctness rewards alone do not.
4️⃣ Inside a real kernel search, the surrogate finds faster kernels than an equal-GPU-budget baseline by considering more candidates per measurement.
5️⃣ We release 12,388 LLM-generated GPU kernels with measured runtimes spanning 118 operations, CUDA and Triton backends, 3 GPU types, taking 400M tokens 600 GPU-hours to produce. This dataset can be used for analyzing LLM-driven evolutionary program search dynamics, post-training LLMs for kernel code generation, and things we didn’t get a chance to explore, like training reward models!
Thread 🧵👇
6
12
1,397

Can an LLM act as a selective model of a GPU during evolutionary search, by reasoning forecasting a kernel’s runtime but deferring to a GPU when unsure? We produced 12k kernels runtimes from evolutionary search, costing 400M reasoning tokens 600 GPU-hours to answer this.
In our work GPU Forecasters, we study language models as selective surrogates for GPU kernel optimization.
1️⃣ Off-the-shelf LLMs can forecast how a GPU responds to a candidate kernel with non-trivial accuracy. If we rank candidates by these predictions and measure only the top 10% on a GPU, the fastest kernel we find is within 20% of the best in the pool.
2️⃣ We want LLMs to not just be accurate but also calibrated, so that we can use their uncertainty for selective prediction: during search, we should trust only confident forecasts and verify less confident forecasts by sending them to the GPU.
3️⃣ We train an open-weights surrogate (GPT-OSS-20B) with RL to improve both accuracy and calibration. Calibration-shaped rewards improve both confidence reliability and ranking ability, while correctness rewards alone do not.
4️⃣ Inside a real kernel search, the surrogate finds faster kernels than an equal-GPU-budget baseline by considering more candidates per measurement.
5️⃣ We release 12,388 LLM-generated GPU kernels with measured runtimes spanning 118 operations, CUDA and Triton backends, 3 GPU types, taking 400M tokens 600 GPU-hours to produce. This dataset can be used for analyzing LLM-driven evolutionary program search dynamics, post-training LLMs for kernel code generation, and things we didn’t get a chance to explore, like training reward models!
Thread 🧵👇
5
34
81
15,025
Where does a surrogate's training data come from? It is a byproduct of running search. Every measured candidate already carries the (reference, candidate, hardware, speedup) tuple a surrogate learns from, so a long-running search produces its own training set.
We release 12,388 LLM-generated GPU kernels with measured runtimes, spanning 118 problems, CUDA and Triton, three GPU types, and four search methods, at a cost of 400M tokens and 600 GPU-hours. Kernel search is computationally expensive. This dataset can be re-used for analyzing LLM-driven evolutionary program search dynamics, post-training LLMs for kernel code generation, and things we didn’t get a chance to explore, like training reward models!
1
4
169
Work done with @cyjustinchen @jmin__cho @EliasEskin @mohitban47 @unccs @UTCompSci @JHUCompSci! We’d also like to thank @Modal for a generous academic compute grant!
We view this as a first step towards developing world models for complex cyber-physical systems!
Paper: arxiv.org/abs/2605.31464
Code: github.com/codezakh/gpu-fore…
HuggingFace Data: huggingface.co/collections/c…
2
13
340