
Physicist, Telecom Engineering lover, HPC Enthusiast. Prog Rock/Metal fan.
Joined December 2017
- Tweets 17,784
- Following 129
- Followers 9,661
- Likes 11,463
9,074 Photos and videos







Pinned Tweet

30 Jul 2021
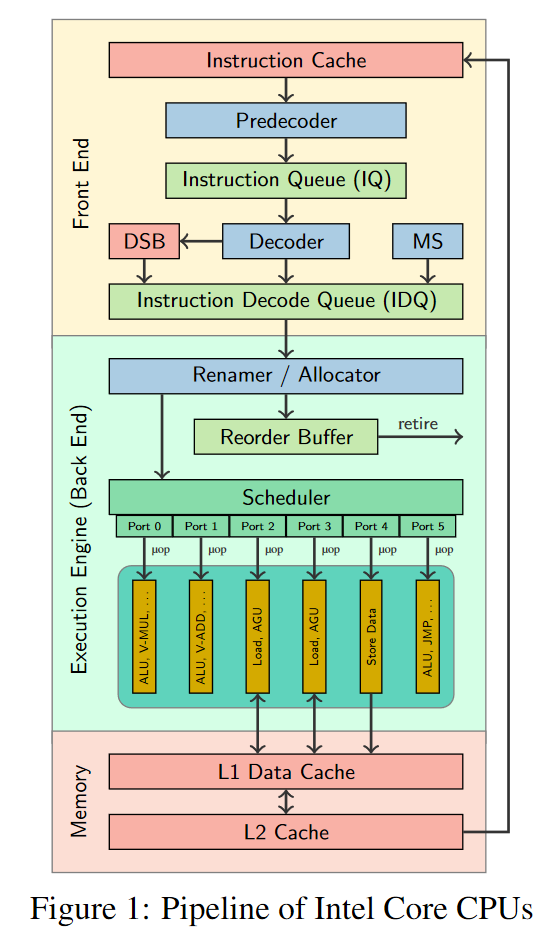
Researchers have developed a new simulator to predict the throughput of basic blocks of all Intel Core μarchs released in the last decade, demonstrating to be more accurate than the predictions of state-of-the-art tools by more than an order of magnitude.
arxiv.org/pdf/2107.14210.pdf
5
183
690
Jun 13
Anthropic now has two serious issues to resolve. First, they need to prove its model is "safe". The second is that it cannot lie and simply change the name of its current model and reissue it. How they resolved this and avoided another government crackdown will be fun to see.
1
1
12
818
Jun 13
Here's a lesson: If you use fear as a marketing tool, don't get upset if the hammer of regulation happens to hit you on the head.
Perhaps now Dario will start telling everyone that his models are safer to avoid a subpoena related to national security.
anthropic.com/news/fable-myt…
2
7
567
Jun 12
Since the current trend topic is SpaceX IPO, it's worth remembering that studies already exist showing the feasibility of orbital data centers.
Apr 11

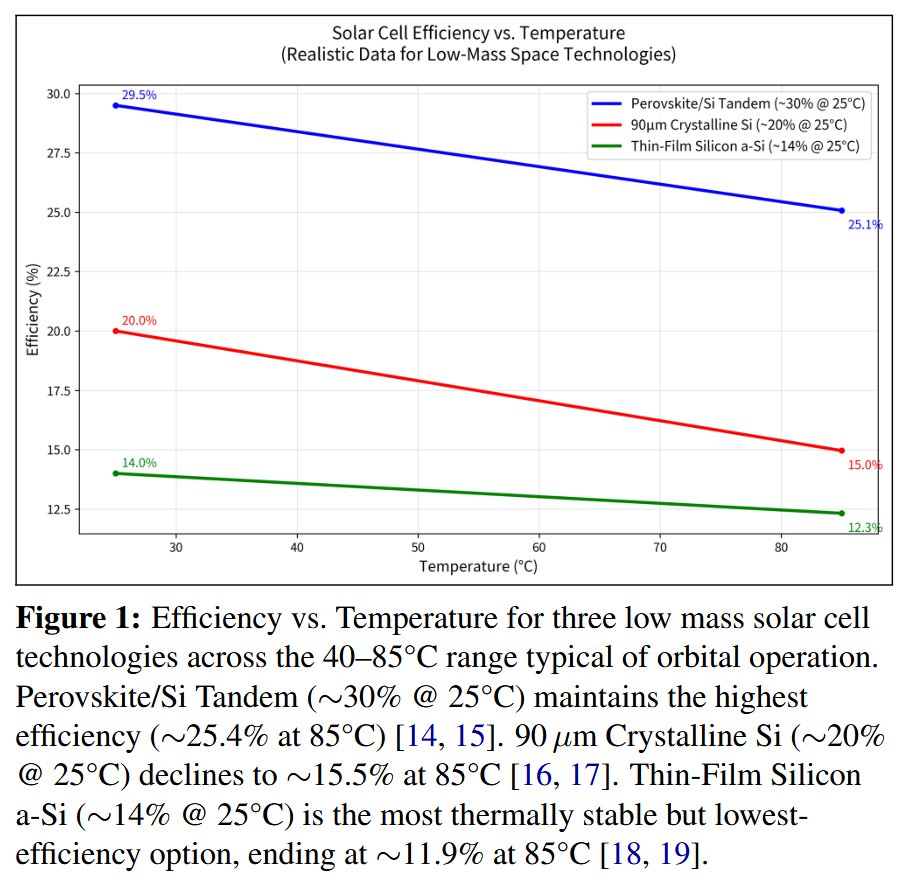
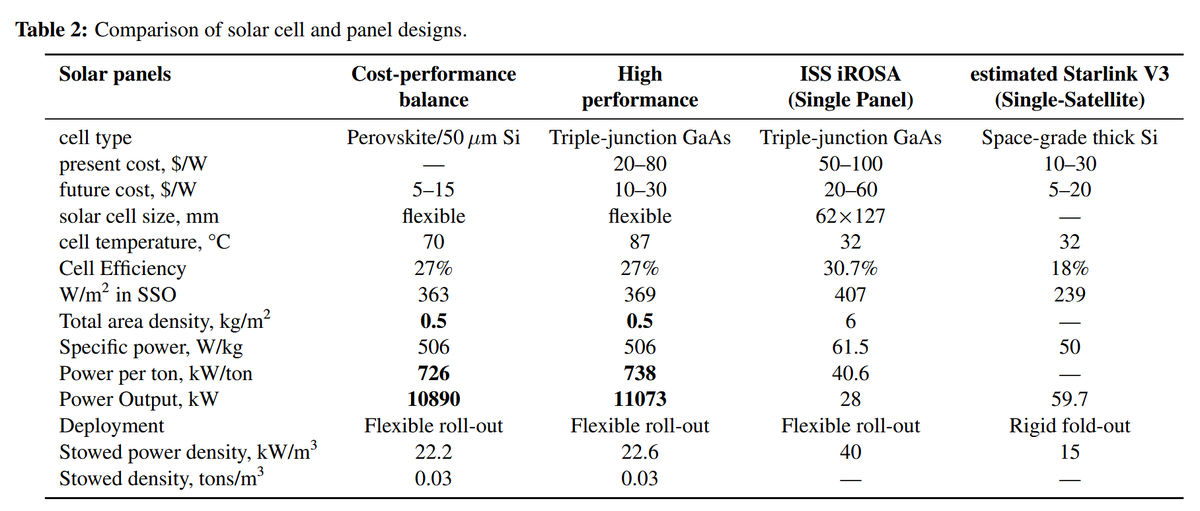
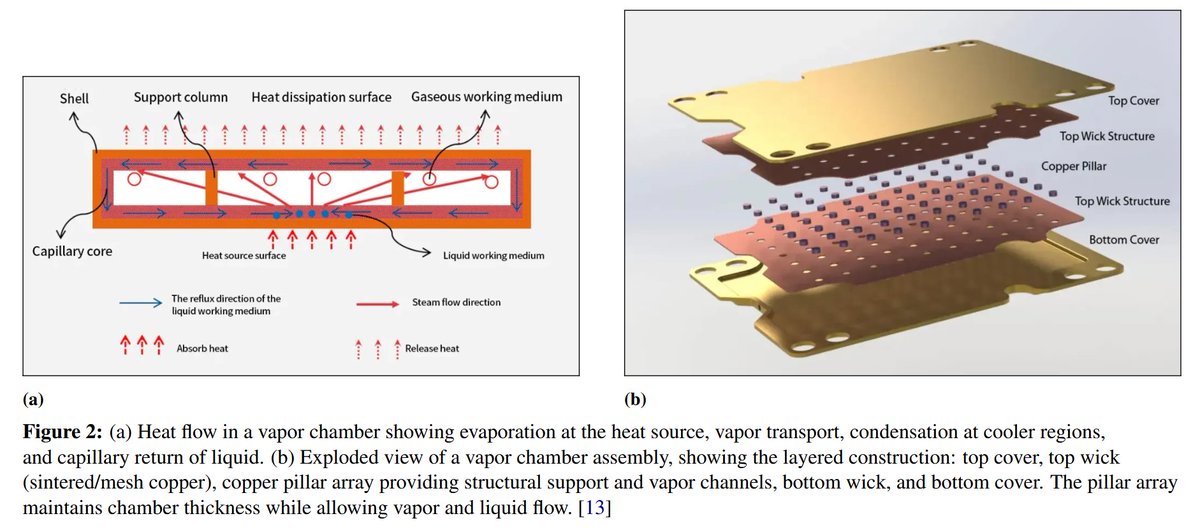
In this paper is presented a distributed compute architecture for SSO computational satellites that can potentially provide >100 kW compute power per launched metric ton (including deployment and station keeping mass).
arxiv.org/pdf/2604.07760
1
19
1,175
Jun 11
Lost in the sound of my mind
You'll hear my calling voice and I,
I want to bring you in together
I'm here to leave you a sign of living time
Forever safe to all my sons,
until all I loved will grow.
youtube.com/watch?v=plp_H7D6…
616
Jun 11
Today marks one year since the farewell of @HPC_Guru, who was a beacon within the HPC community and a good friend. Wherever you are, I hope you are well and know that you are missed, at least by this little fox.
And, of course, a tribute to HPC_Guru needs to have a tasty mango🥭
1
2
25
1,751
Jun 10
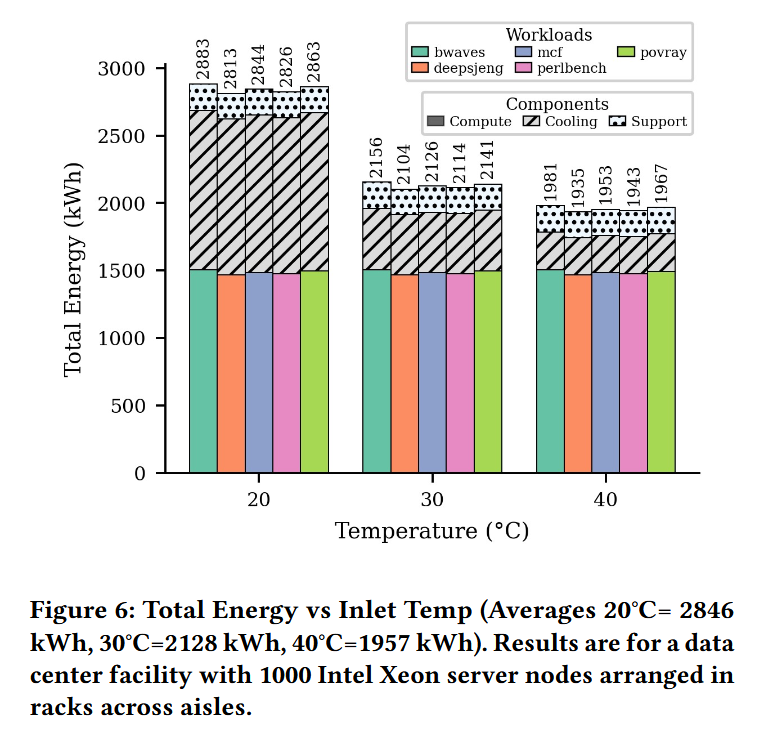
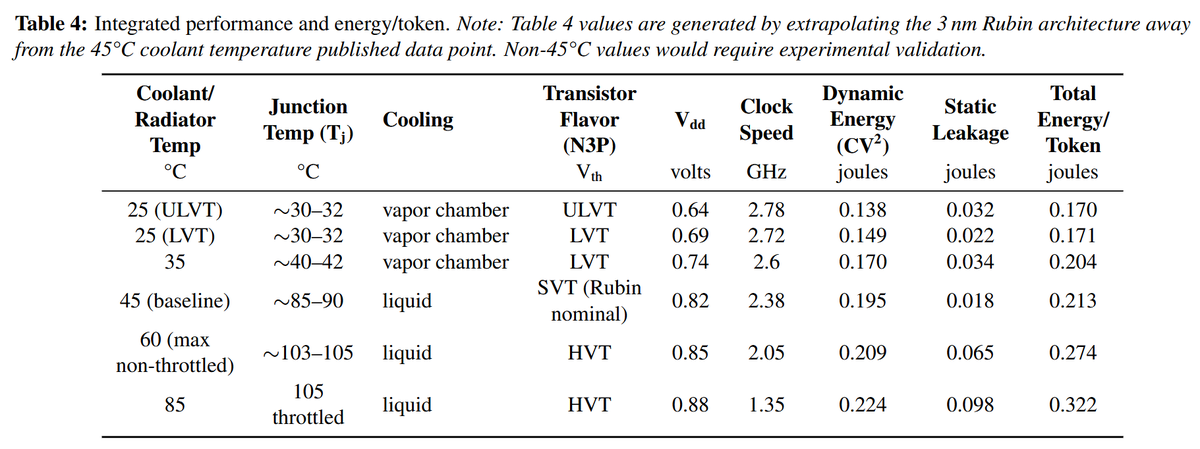
For the first time, researchers characterized inverse temperature dependence on production Intel Xeon CPUs and demonstrated that efficiency-optimal temperatures are CPU part-specific, and frequently higher than typical data center operating conditions.
arxiv.org/pdf/2606.11163
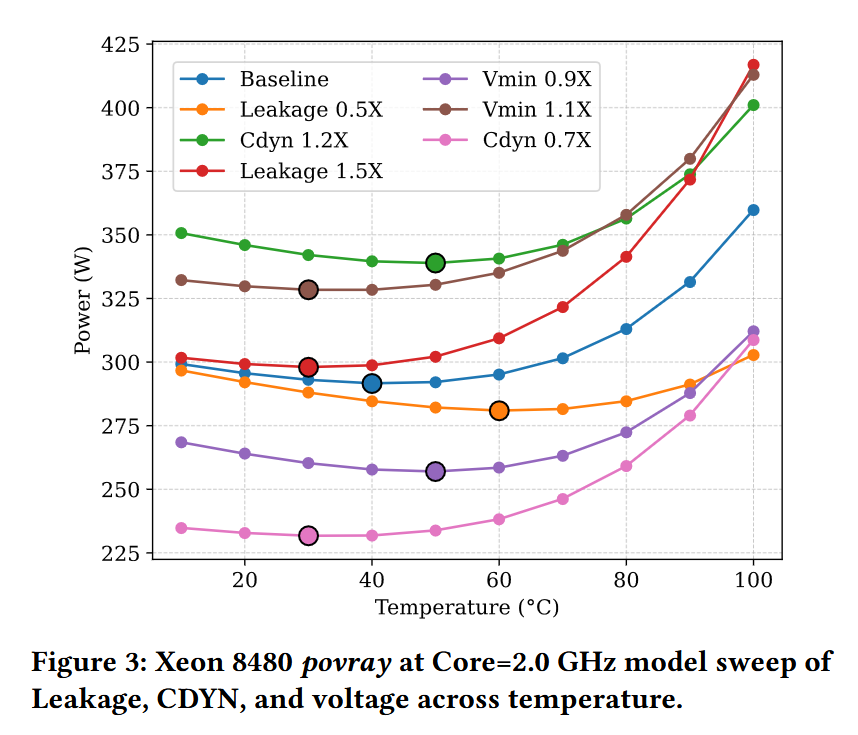
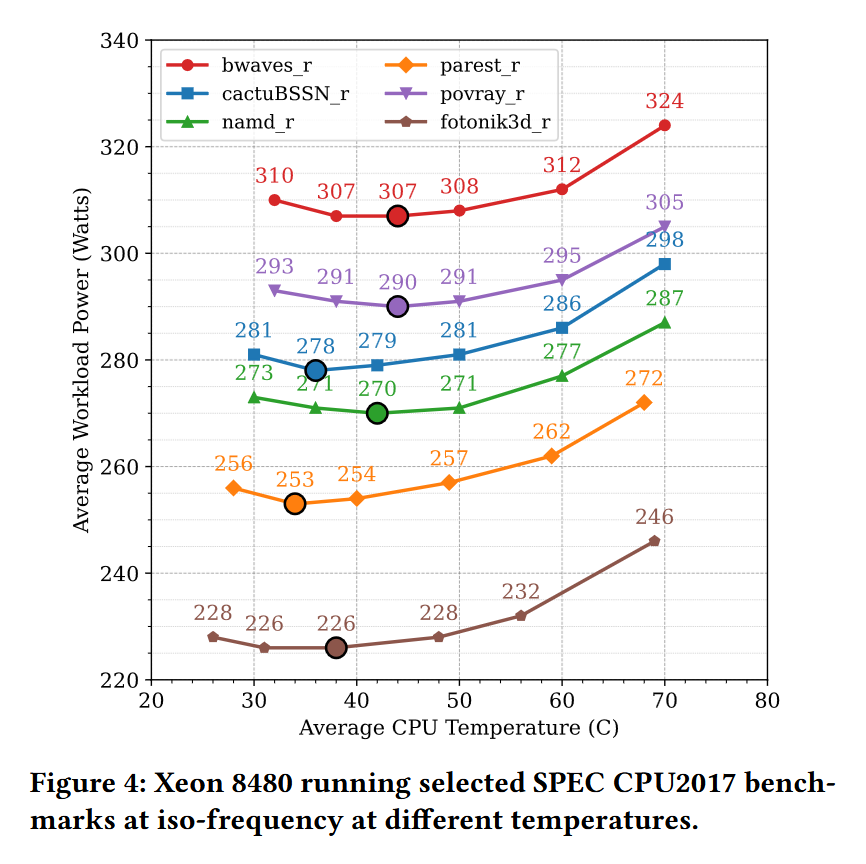
1
4
28
1,440
Jun 10
The case study investigated showed that this approach can reduce total data center energy by 4 – 13% without sacrificing performance or reliability.
1
1
4
479
Jun 10
By implementing ITD-aware thermal grouping of CPUs and inlet temperature adjustments, data center operators can optimize facility-level cooling and overall sustainability.
1
4
395
Jun 10
In this paper, researchers have proposed a Loihi 2 implementation of convolutional sparse coding via the Locally Competitive Algorithm (LCA) and evaluate it against a conventional GPU baseline on the same inference problems.
arxiv.org/pdf/2606.08584


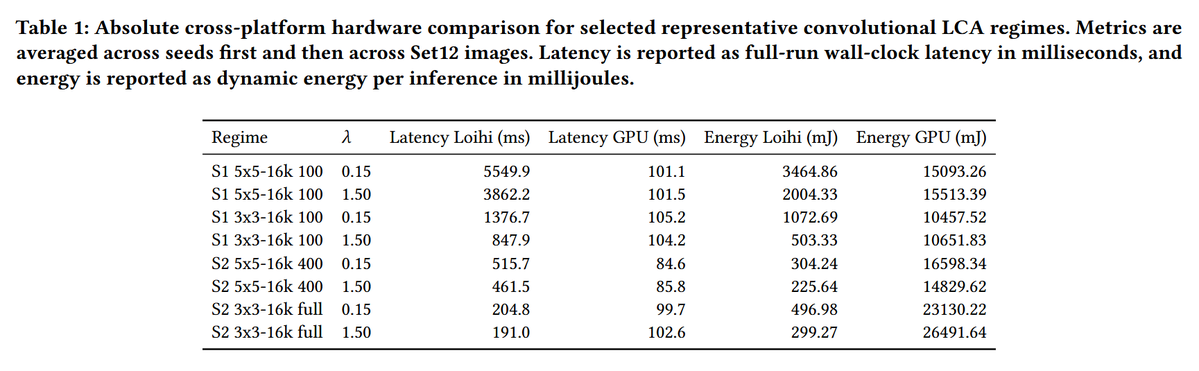
1
3
13
1,178
Jun 10
"The cross-platform comparison adds that a conventional workstation GPU generally provides lower latency, whereas Loihi 2 offers a substantial dynamic-energy advantage across the representative regimes considered here."
1
1
1
416
Jun 10
"The practical implication is therefore not that Loihi 2 uniformly outperforms conventional hardware, but that it occupies a different part of the design space. (...)"
1
1
197
Jun 10
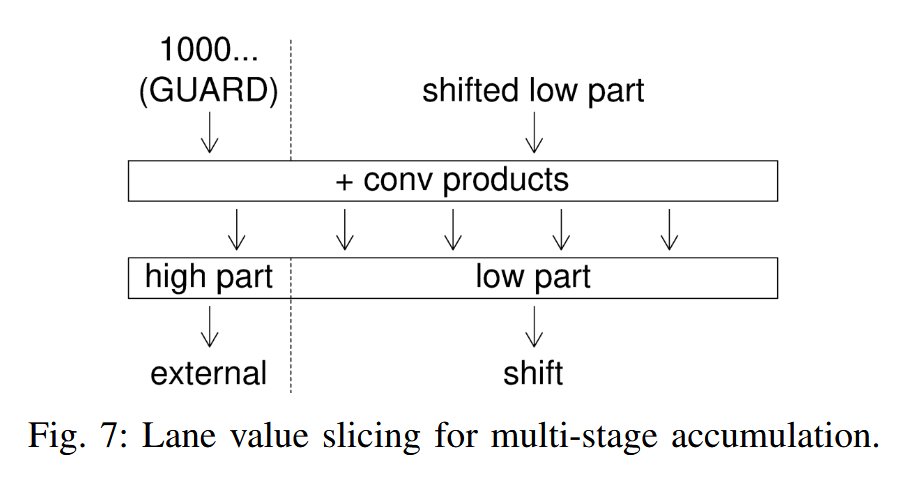
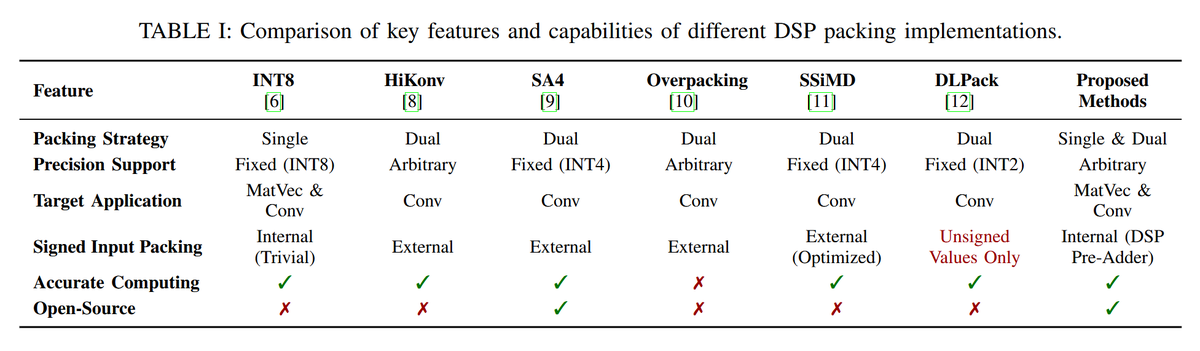
In this paper, AMD researchers have proposed several novel arithmetic packing strategies that significantly improve the utilization of fixed-width DSP slices in modern FPGA devices.
arxiv.org/pdf/2606.11065
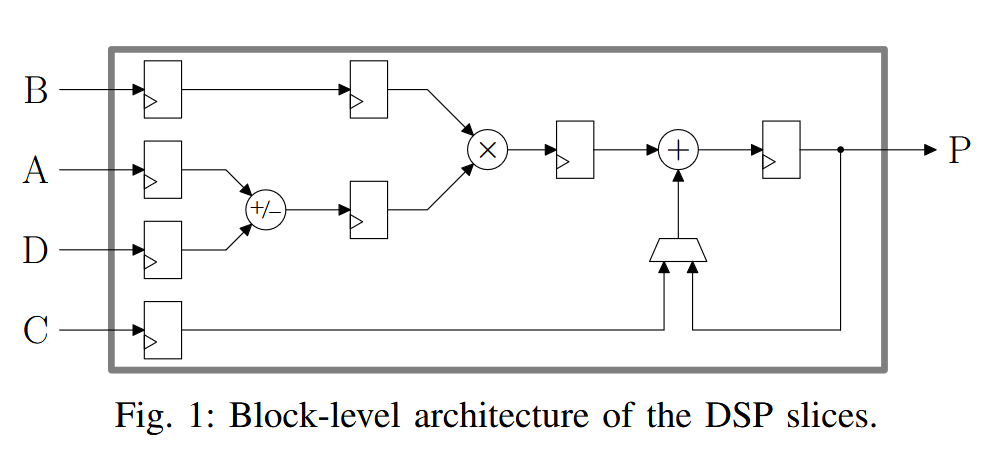

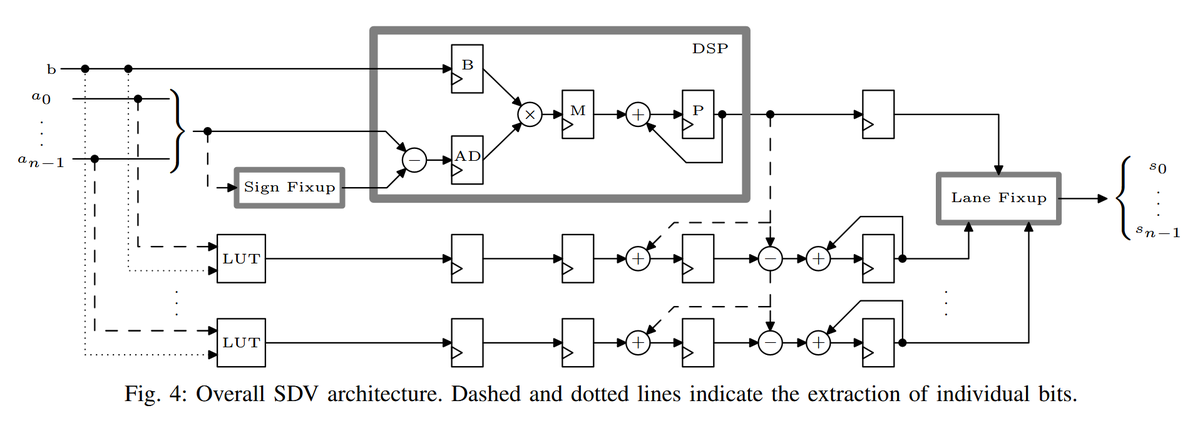
1
6
69
2,995
Jun 10
Building on that, this work presented two distinct architectures, one optimized for matrix-vector multiplications and the other for convolutions (BSEG), which both support arbitrary precisions, allowing the design to be used efficiently across a wide range of quantization levels.
1
1
1
248
Jun 10
The results for the full UltraNet model show an efficiency increase by 36% to 1.5 FPS/DSP while reducing the LUT count by 21%. A comparison of the BSEG to the AMD FINN implementation at maximum frequencies shows a reduction in LUT and DSP by 63% and 25% respectively.
1
1
237
Jun 10
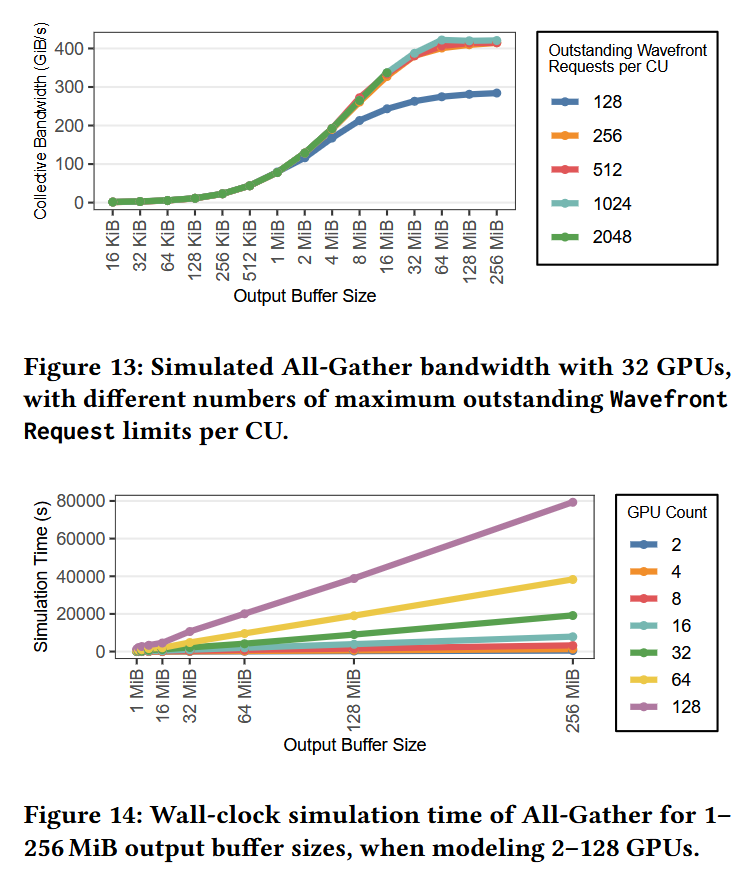
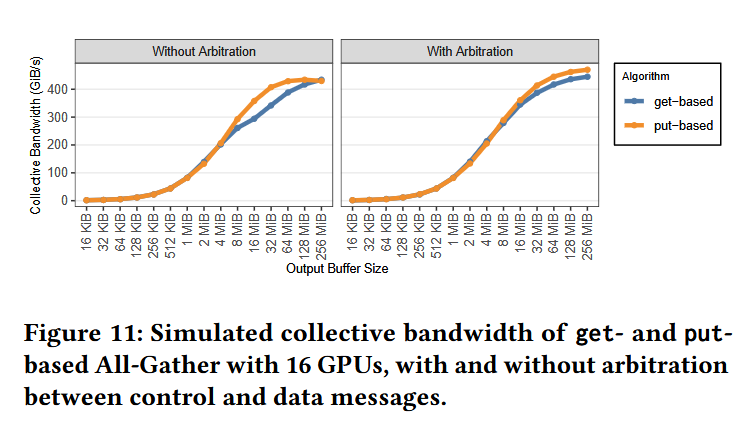
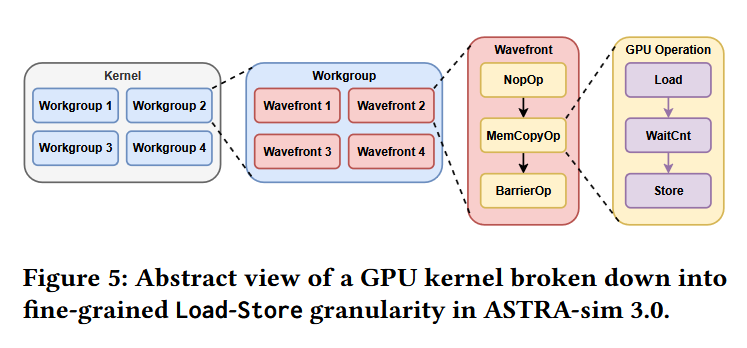
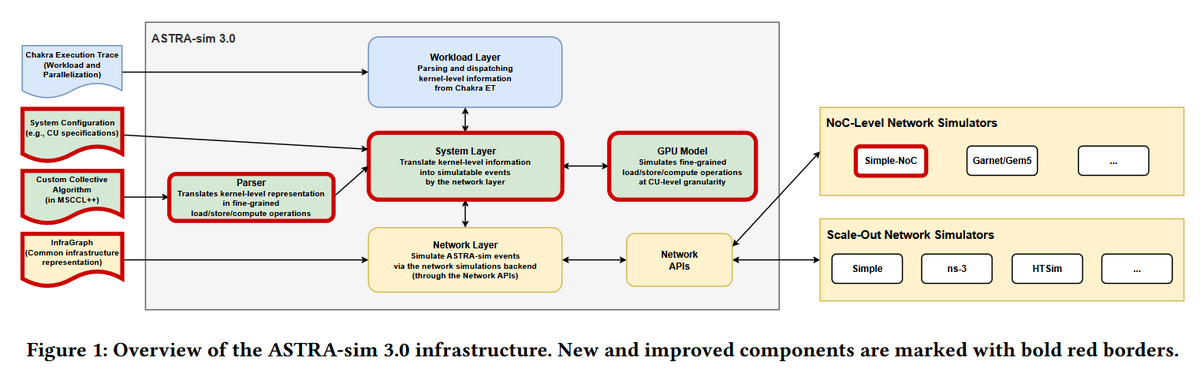
In this paper is presented ASTRA-sim 3.0, the next-gen of the distributed AI system simulator, equipped with new design-space exploration capabilities by capturing fine-grained control-path and architectural details through custom collective modeling.
arxiv.org/pdf/2606.10440
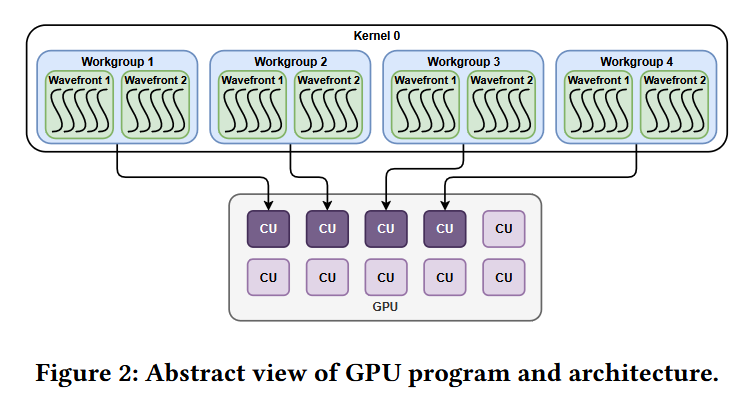

2
4
25
1,597
Jun 10
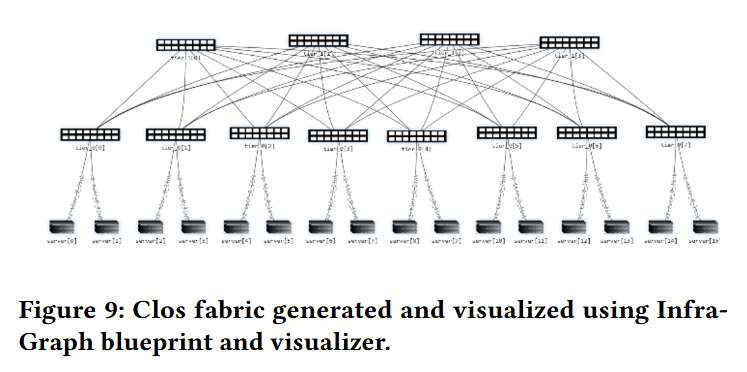
InfraGraph formalizes infrastructure topology as a directed, attributed graph in which vertices represent hardware like GPUs, NICs, and storage, while edges represent the connections between the hardware components.
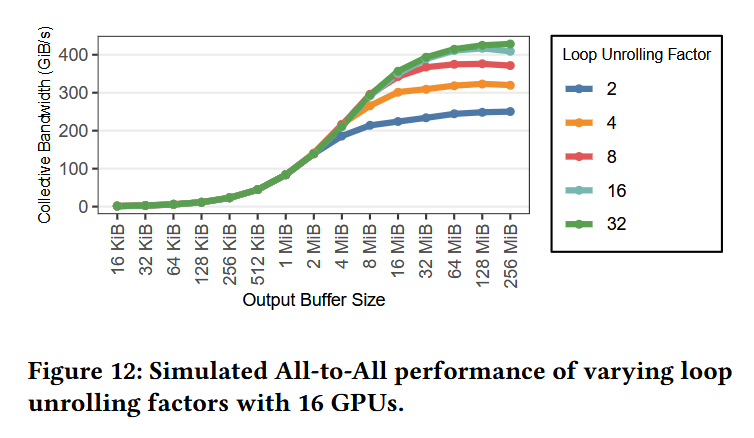
1
1
1
238
Jun 10
Users can exchange and reuse a single InfraGraph description across network backends in ASTRA-sim 3.0, allowing a compact description to represent a fully expanded graph expressively, while enabling automatic workflows through programmatic graph construction.
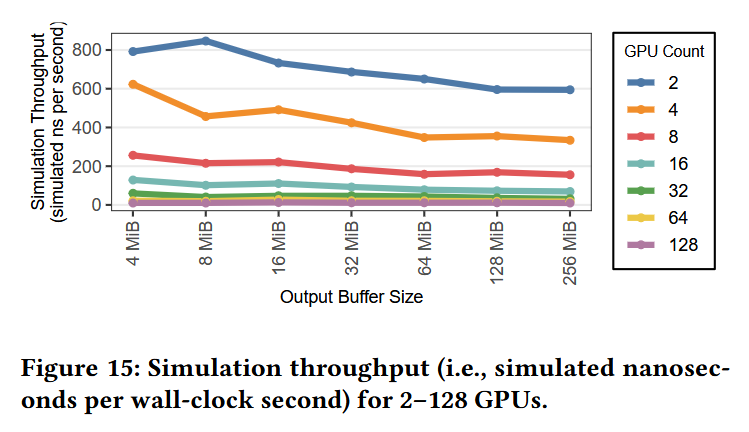
1
2
214