
Joined August 2022
- Tweets 1,576
- Following 152
- Followers 6,346
- Likes 812
524 Photos and videos














Jun 12
Need a home base during @databricks Data AI Summit?
Come hang with us on Tuesday, June 16 at Press Club 😎
We’ve got the place reserved so you can enjoy lots of great food, have a drink, take a call, catch the World Cup, or just get away from the Databricks Summit floor for a bit.
Register here: luma.com/xca0p3un
95
Jun 11
The most sophisticated AI buyers don't ask:
"Can you parse a PDF?"
They ask:
Where does the data go?
How do we audit it?
What happens when something breaks?
2
2
350
Jun 11
Anyone can extract text from a document.
The real challenge is everything that comes after:
Governance.
Permissions.
Lineage.
Auditability.
That's what enterprise teams care about.
1
1
316
Jun 11
More in our blog, ahead of @databricks Data AI Summit next week: unstructured.io/blog/your-la…
2
83
Jun 10
The agentic enterprise runs on data, and most of that data is a mess.
Messy PDFs, scanned images, complex tables. Before any agent can act, that has to become something it can actually use.
📍 Catch us live in Austin this week.
We’ll get into why agent-ready data is the real starting line for agentic workflows, and what it takes to get unstructured data production-ready.
#AgenticAI #EnterpriseAI #GenAI #Unstructured
2
79
Jun 9
The biggest blocker to enterprise AI isn't always the model.
Sometimes it's a 200-page contract from 1997 sitting in SharePoint.
Or a scanned invoice buried in an email thread.
Or last week's sales call sitting in a recording platform.
Your agents can't use knowledge they can't access. 👇
1
2
300
Jun 8
Managing user access across multiple systems gets messy fast.
The fewer places admins have to manage access manually, the better.
Keep access to Unstructured aligned with your IdP as users join, leave, or change groups.
👉 docs.unstructured.io/busines…
2
127
Jun 2
Parsing PDFs sounds easy until you try it.
A scanned invoice and a digital manual might share the same file extension, but they shouldn't be parsed the same way.
Pick the wrong strategy and you'll either lose information or waste money.
Here's our framework for choosing👇
unstructured.io/blog/masteri…
3
341
May 29
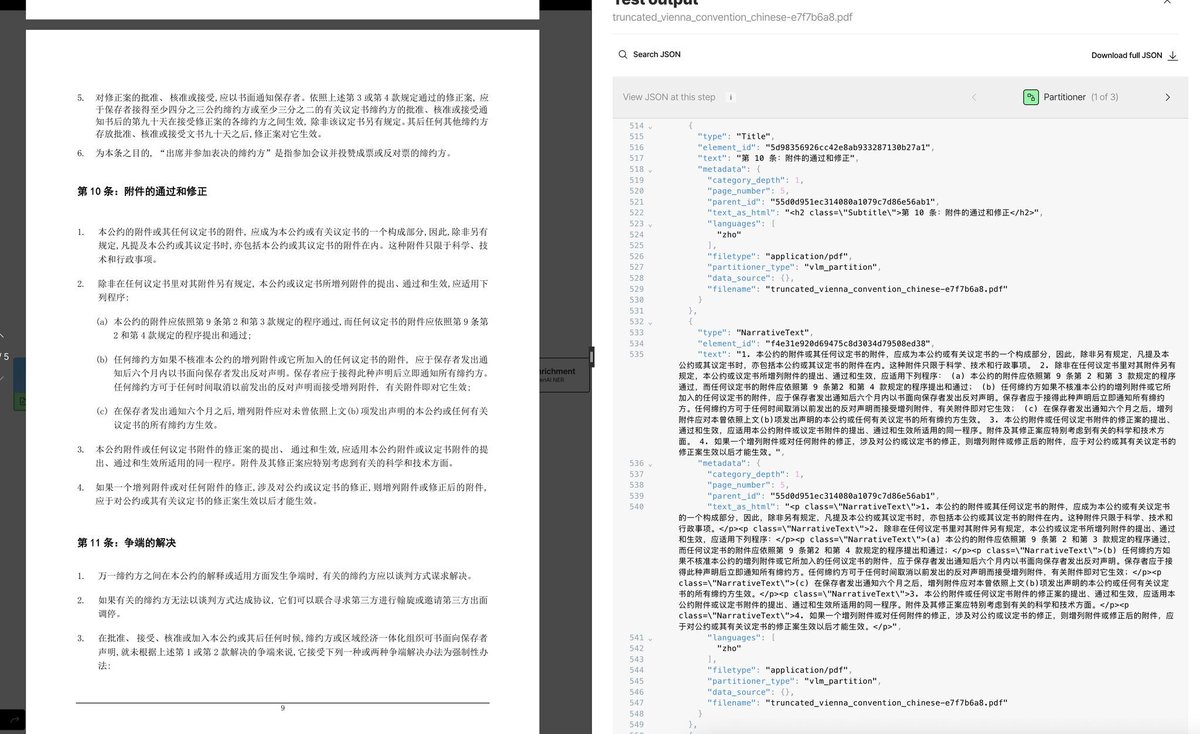
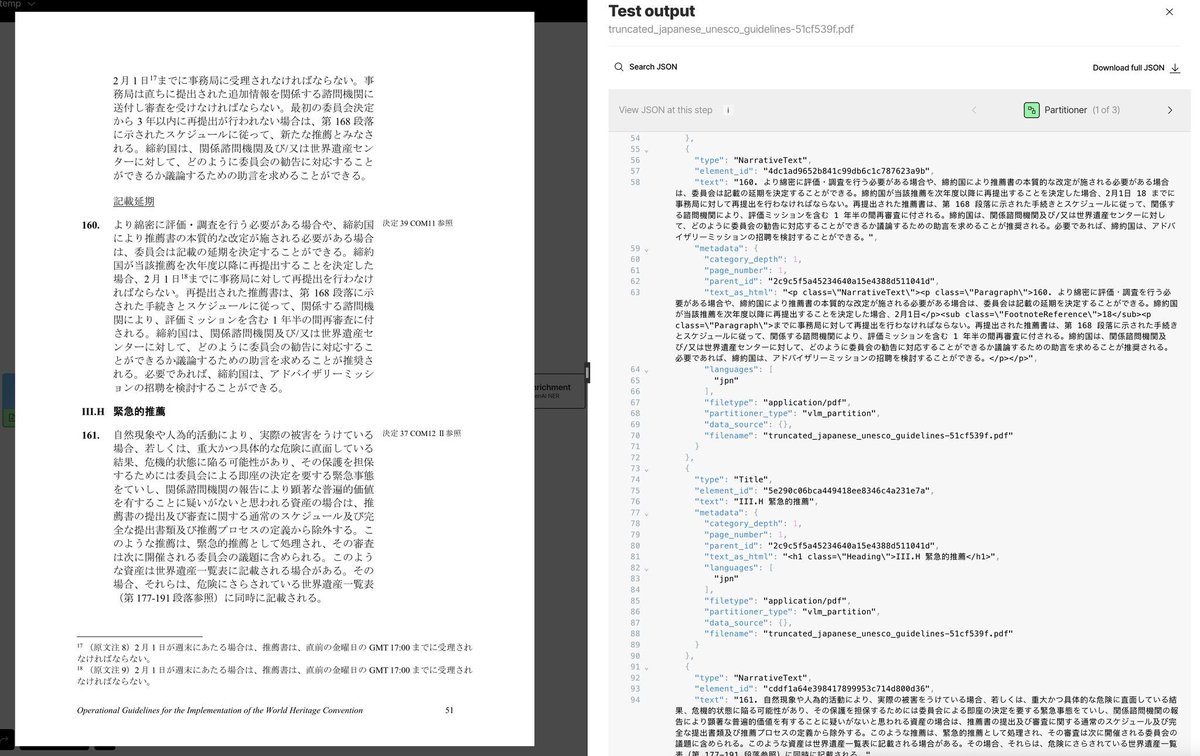
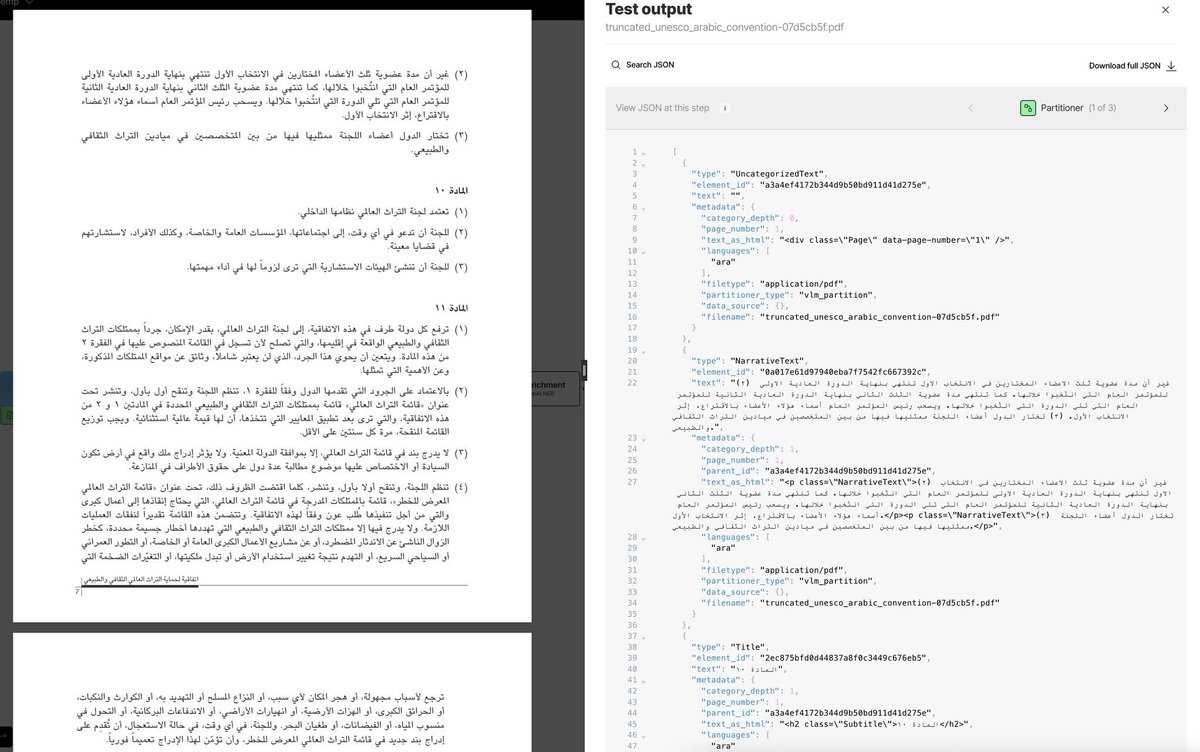
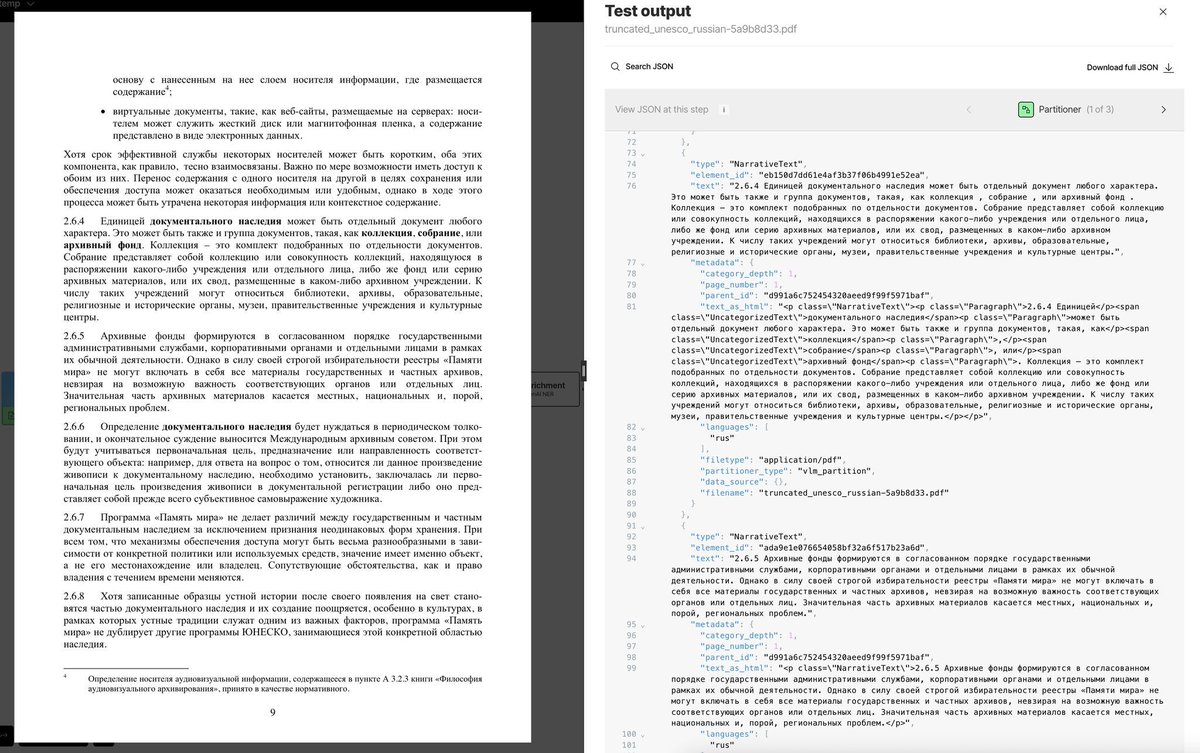
Most document pipelines are quietly English-only. They work fine until someone uploads a Japanese manual, an Arabic contract, or a Chinese report and then the whole thing falls apart.
Non-Latin scripts, right-to-left text flows, mixed character sets in a single document. Each one becomes a separate engineering problem, and before long you're maintaining different parsing logic for every language your users actually work with.
Unstructured's partitioner handles this automatically so you get the same json schema out the other side regardless of what language went in. Your pipeline doesn't need to know the difference
The output from the Japanese document below looks exactly like what you'd get from any English PDF.
#MultiLingualData
#RAG #AI #GenAI #DataEngineering #UnstructuredData #Unstructured
#LLMs #AgenticAI #VectorDB
1
116
May 27
Getting data into AI-ready JSON is only half the battle.
The next problem:
actually making those outputs usable inside real workflows.
We just published a walkthrough for connecting Claude Desktop directly to Unstructured outputs stored in Google Drive.
Chat with parsed docs.
Explore extracted metadata structure.
Feed outputs into agentic workflows.
No custom UI or glue code required.
Try it yourself: docs.unstructured.io/example…
1
2
4
450
May 27
And it doesn't stop at just financial documents! We structure all sorts of file types. Learn more here: unstructured.io/?modal=conta…
1
297
May 22
Newspaper layouts are where a lot of parsers fall apart.
Columns.
Captions.
Images breaking reading flow.
Text extracted in the wrong order.
And once the structure breaks, the downstream AI output usually does too.
This is what it looks like when Unstructured processes it 👇✨
1
153
May 21
Enterprise knowledge doesn't live in one place. Sales decks are in OneDrive. Contracts are in Azure. The important context from that client call is buried in an Outlook thread somewhere.
That's not bad organization. That's just how work actually happens. The problem is when your RAG system can only see one of those places at a time.
Connecting to multiple sources is the easy part. The harder part is what comes after — making sense of a chart buried in slide 47 of a PowerPoint, pulling a commitment out of an email chain, extracting the right figure from a complex Excel model without losing context. Every file type is a different problem.
We wrote a walkthrough for building a pipeline that handles exactly that. Azure Blob Storage, OneDrive, Outlook — three sources, multiple file types, one workflow. Unstructured processes all of it into a universal format so when you ask "What did we promise the healthcare client?" the answer can draw from a presentation, a contract, and an email thread all at once.
Try it yourself 👉 unstructured.io/blog/everyth…
#RAG #AI #GenAI #DataEngineering #UnstructuredData #Unstructured
#LLMs #AgenticAI #VectorDB
1
127
May 20
Happy hour with LMI is in full swing! 🍻
Come join us at:
📍Yard House
50 Channelside Dr


1
121