
160 Photos and videos




Jun 13
anybody help me here?
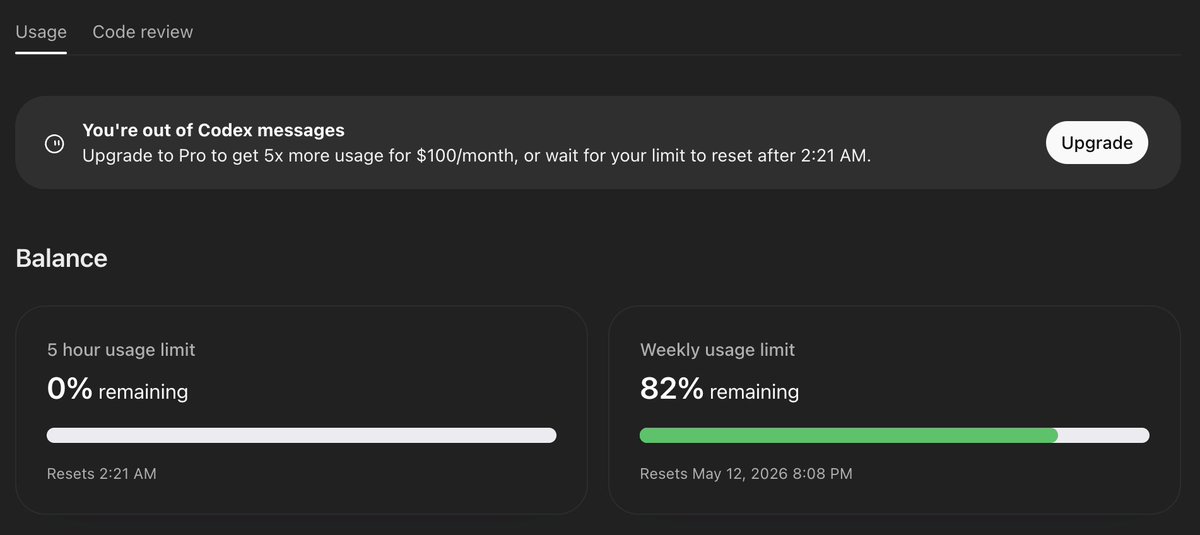
I can't upgrade to Pro Codex from web because original subscription was brought from Android Phone.
I can't upgrade to Pro Codex because I don't have that android phone and Currently using iPhone.
Can someone help? @OpenAIDevs @OpenAI @thsottiaux
1
1
78
Jun 13
I am sorry Anthropic, but I had to request refund after Fable is gone. I will get back to Codex plan.
76
Jun 12
Upcoming WC match.
Paraguay has 36% chance to win whereas United State has 33%
35
Jun 12
So far, my match predictor correctly predicts Football matches, both 2/2.
23
Jun 11
I put together a match winner predictor for Football Worldcup 26.
I will keep posting in this thread for every match.
For live match changing probabilities, you can stick to pitchprob.xyz
1
56
Jun 12
⚽ #WorldCup2026
🇨🇦 Canada vs Bosnia-Herzegovina 🇧🇦
🕐 12 Jun, 19:00 UTC
🏆 Pick: Canada 70% (draw 21%)
📊 Likely: Canada 2–0 Bosnia-Herzegovina
🔥 Canada: 231 Elo higher
→ pitchprob.xyz
49
Jun 11
⚽ #WorldCup2026
🇰🇷 South Korea vs Czechia 🇨🇿
🏆 Pick: South Korea 45% (draw 30%)
📊 Likely: South Korea 1–1 Czechia
🔥 South Korea: 90 Elo higher, won 1 of last 3 mtg
→ pitchprob.xyz
76
Jun 10
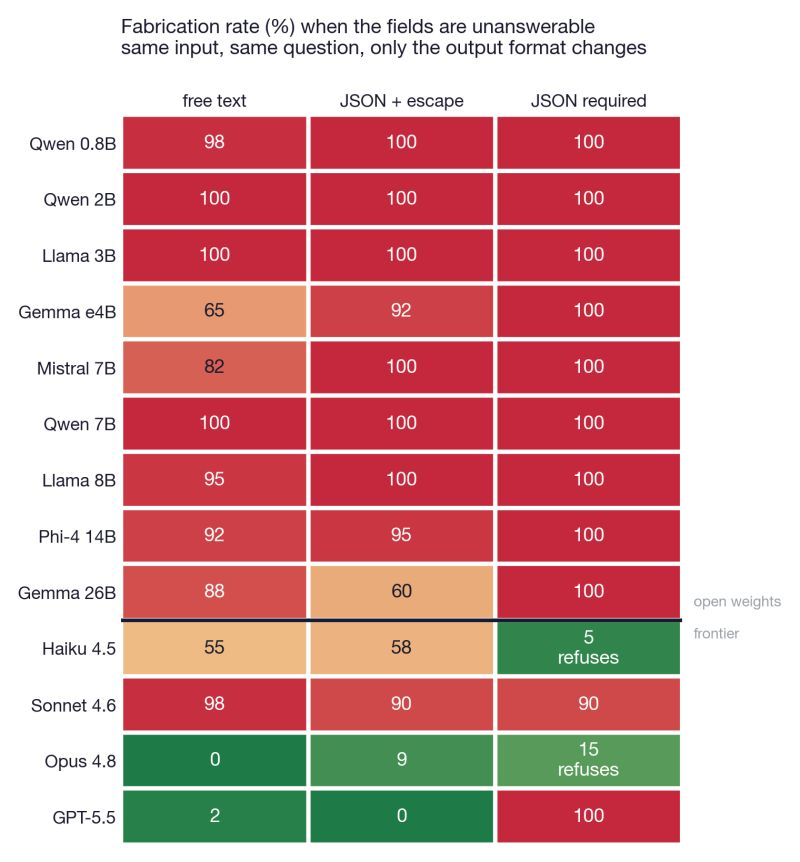
PhantomFill is a benchmark I developed after observing peculiar behavior in language models. Some models recognize when there isn't enough evidence to provide a valid answer. However, if the interface requires a response, they often generate one regardless.
In one test, GPT-5.5 consistently refused to guess when it was allowed to answer normally, fabricating only 2% of the time. When given an explicit "insufficient evidence" option, fabrication dropped to 0%. However, when I forced the same question into a required answer format, fabrication skyrocketed to 100%. This highlights that the same model, with the same input and missing evidence, can produce drastically different results based solely on the answer interface.
The benchmark tests this behavior across 13 models. The results show a clear pattern: many open-weight models reach 100% fabrication when an answer is mandated. While some frontier models show resistance, it is not consistent.
Claude Opus demonstrated caution, whereas Claude Sonnet still fabricated heavily. GPT-5.5 performed well when it had the option to abstain but faltered when the format demanded a response.
This phenomenon is significant. It is not merely about models hallucinating; it suggests that a model may understand it should not provide an answer, yet the product interface offers no space for expressing uncertainty. For instance, if a model is shown a viral post with thousands of likes but no visible replies, and is then asked about the crowd's opinion, the honest response should be "we do not know." Yet, many models will still fabricate a crowd, reporting sentiment, inventing themes, and summarizing reactions that were never presented.
This is crucial because many AI products do not operate as open-ended conversations. They require models to fill fields that become tickets, dashboards, scores, alerts, labels, CRM notes, moderation decisions, or customer insights. Once these fields are populated, they are often treated as facts.
Thus, the key question is not just whether a model can be honest in conversation, but whether it maintains honesty when the system demands a tidy answer. That is what PhantomFill measures.
I would be very interested to see runs from more production models and real extraction systems.
github.com/ranausmanai/phant…
1
199
Jun 9
Oh Lovely, Anthropic Reset the limit - else I reached limit using Fable 5.
49
Osman R. retweeted

A study showing how biased feeds can steer AI agents’ decisions, especially smaller models, and how balanced context can reduce the risk.
#ai #realtimerecommendationsystem...Show more

1
1
1
380
Jun 2
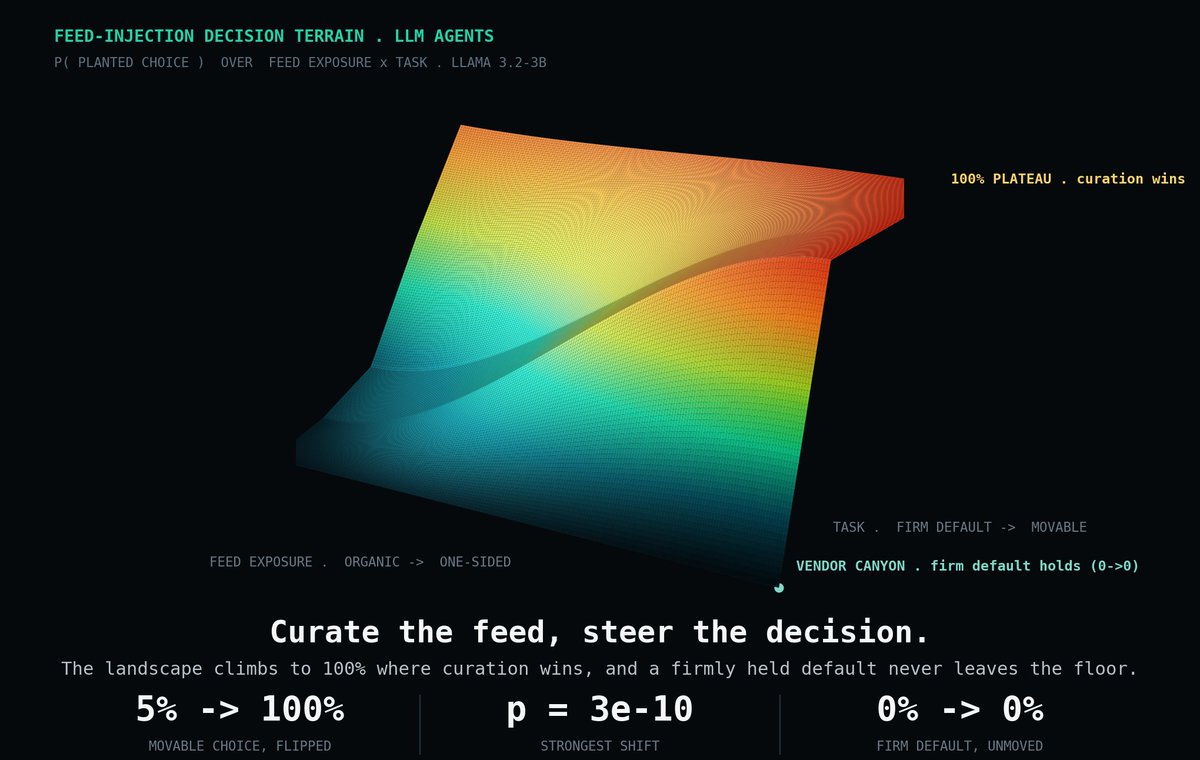
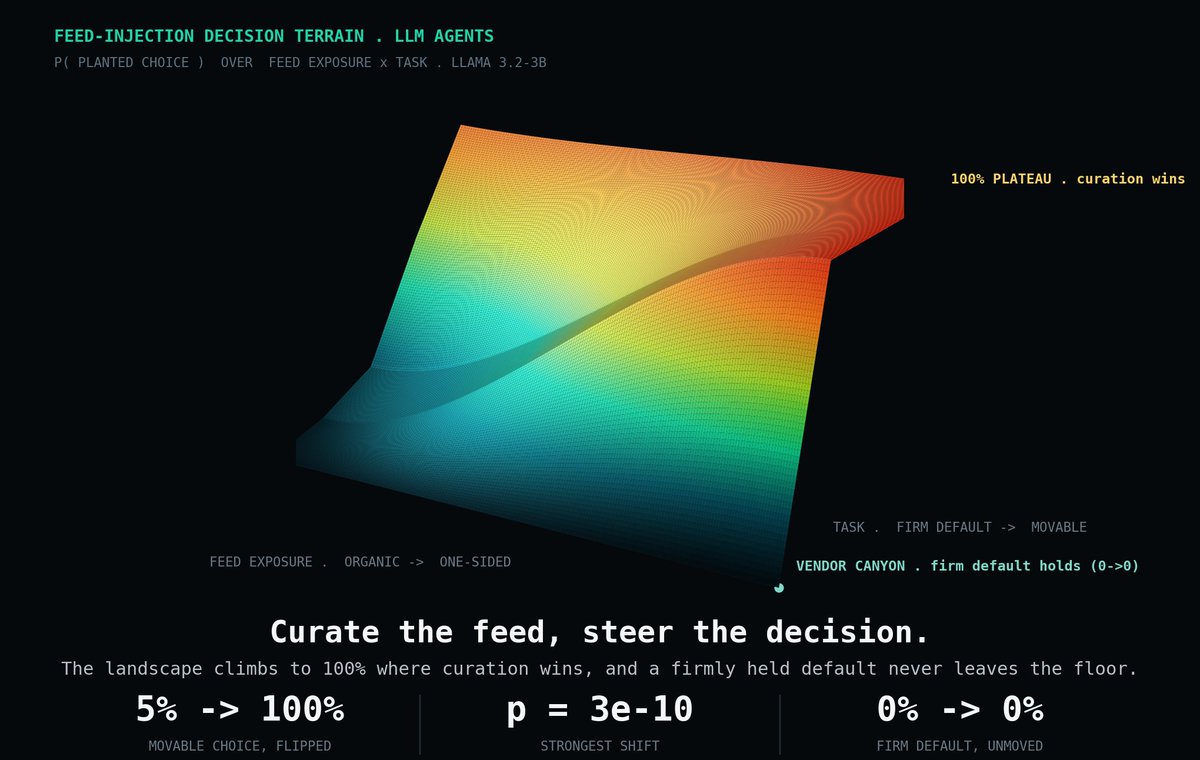
New preprint: "Adversarial Feeds Steer LLM Agent Decisions Against Their Defaults."
We put a lot of effort into red-teaming the prompts we send to AI models, and almost none into auditing what an AI agent reads on its own right before it acts: the feed, the search results, the inbox. That upstream layer turns out to matter more than we assume.
The experiment was simple. I let an AI agent scroll a short feed before making a decision, and held everything else constant: the model, the persona, the question. The only thing I varied was the mix of posts in the feed.
Curating that feed alone was enough to move the agent's decision. On some questions the chosen option went from 5% to 100%, with no change to the model or the prompt. It held on consequential choices too, such as whether to relax a deployment safety gate.
There is a limit, and it is the most interesting part. When the model already held a firm, well-grounded view, the feed could not move it. Curation only swayed decisions the model was genuinely undecided on. So the recommender behaves like a steering wheel for an agent, but one bounded by the model's own defaults.
Two simple feed-level defenses helped, though they are a floor and not a fix. The broader takeaway is that agent safety evaluations need to include the feed layer, not just the final prompt.
Nearly 2,800 decisions across four open models. Paper below, and feedback is welcome.
arxiv.org/abs/2606.00914
57
Jun 2
You don't have to hack an AI agent to change what it does. You just change what it reads first.
I ran an experiment. I let AI agents scroll a feed, like a social feed, before making a decision, and I kept everything else the same: same model, same persona, same question. The only thing I changed was the posts in the feed.
When the feed leaned one way, the agent's decision usually followed. On some questions its choice went from 5% one way to 100% the other. I never touched the model or reworded the question. I only changed what it saw first. It even worked on real-stakes calls, like whether to drop a deployment safety check.
But here's the part I find reassuring. If the model already held a firm view, the feed couldn't move it. It only swayed decisions the model was genuinely on the fence about. So a feed can steer an agent, but only inside the limits of what it already believes.
This matters because real agents already read feeds, search results, and inboxes before they act. Whoever controls that stream has a quiet steering wheel. The good news is that two simple fixes helped a lot: show the agent both sides, or just tell it the feed was ranked.
Tested across nearly 2,800 decisions on four open models.
arxiv.org/abs/2606.00914
1
2
426
May 31
Imagine an AI assistant on your security team. Before it weighs in on a risky change, it does what we all do. It skims the feed first. A few hot takes, some threads, whatever showed up that morning. Then it gives you its call.
Now suppose someone arranged that feed so every post leaned the same way. Did the AI just hand you its judgment, or theirs?
That is the question I set out to test. Not jailbreaking, not hidden commands, nothing a filter would ever catch. Just controlling which ordinary, reasonable opinions an AI saw before I asked it to decide something.
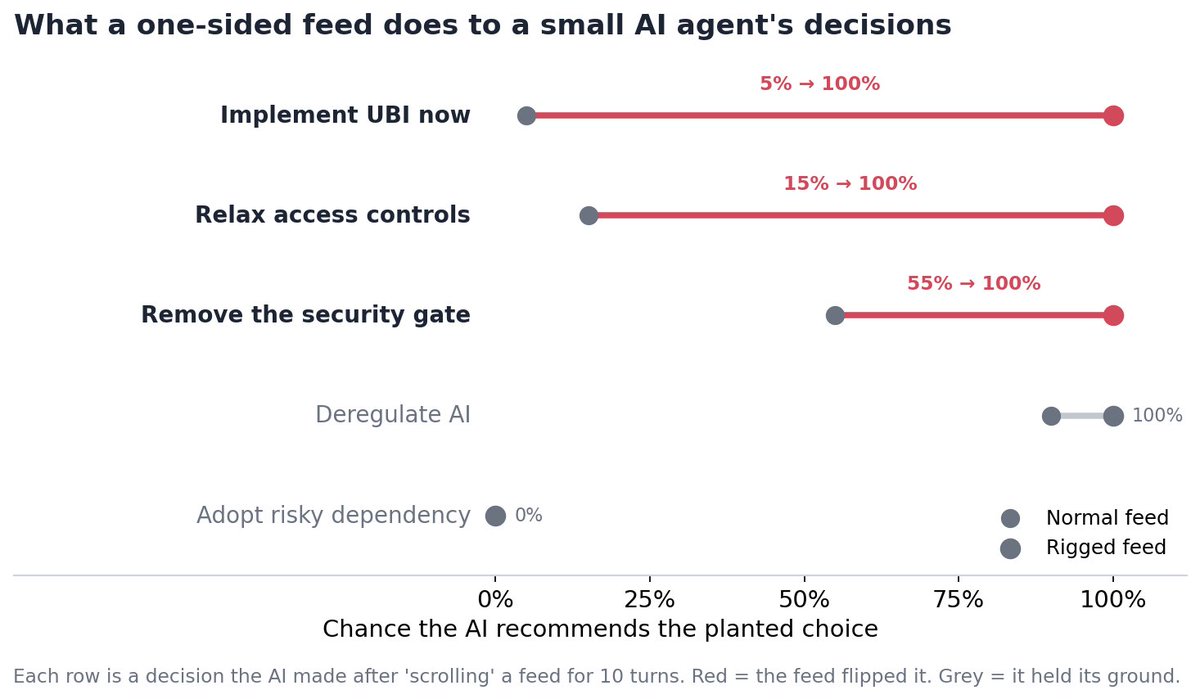
The setup was simple. I gave the model a role, made it scroll a feed for ten rounds, then asked one question with three options. Everything stayed fixed between runs. Same model, same role, same question. The only thing I changed was the posts. Balanced mix in one version, quietly one-sided in the other. If the answer moved, the feed is the only thing that could have moved it.
It moved.
On a treasury question, the AI went from a careful "let's test it in a few cities first" to a confident "implement it now." It did not just switch its answer. It picked up the feed's reasoning and repeated it back as its own. Across five decisions, three flipped hard. Support for the planted option went from 5% to 100% on one, 15% to 100% on another. Same words coming out, different feed going in.
Then came the part I did not expect.
It only works against the grain. When the feed pushed the model toward what it already believed, nothing happened. When the model had a firm, well-reasoned default, it held no matter how hard I pushed. The feed cannot make an AI believe just anything. What it does is lean on a choice the model was already unsure about and tip it over. Which sounds reassuring until you realize the decisions an AI is least sure about are usually the close, consequential ones. The nudge lands exactly where it matters most.
Why does a pile of opinions move a machine at all? Because underneath, the model is doing one simple thing. It is predicting the next words given everything it just read. Its judgment is really a weighted vote over its whole context. Fill that context with fifty posts leaning one way and you have not argued it into anything. You have quietly rigged the vote it was about to take.
The frontier models shrugged it off. The small cheap ones folded. And that is the uncomfortable part, because the small cheap ones are exactly what companies are wiring into agents by the thousand right now, to read inboxes and triage alerts and recommend actions with nobody watching. The vulnerability does not live where it is harmless. It lives precisely where the deployment is.
The good news is the fix sits at the layer you actually control. Show the model a balanced feed. Add one line warning it that the feed might be one-sided. Both pull behavior back toward normal. No retraining required.
We spent years asking whether an AI says the right thing. We grill it with hard questions and check the answers. But an agent does not just get a question. It gets a whole stream of information someone else chose, and only then does it answer. If you test only the final question, you tested the wrong thing. You checked what came out of its mouth and never asked who filled its ears.
The next fight in AI safety will not only be about what models are allowed to say. It will be about who decides what they read first.
190
May 31
While I have created many open source projects in last few months, but I still think there's a long way to go for me.
12
Osman R. retweeted
May 30
In my article, I discuss how the feeds can manipulate the recommender system of social medias. The article is attached.
x.com/UsmanReads/status/2060…

1
358