
Moderator at @octra , @streamflow_fi @Inertia_fi, fullstack developer, crypto enthusiast, ambassador @PicWeGlobal Zpoineer @ZeusNetworkHQ,
Joined October 2013
- Tweets 7,621
- Following 2,148
- Followers 787
- Likes 7,649
1,484 Photos and videos












Pinned Tweet

Apr 15
📹 𝗩𝗶𝗱𝗲𝗼 𝗚𝘂𝗶𝗱𝗲: 𝗥𝘂𝗻𝗻𝗶𝗻𝗴 𝗢𝗰𝘁𝗿𝗮 𝗪𝗲𝗯𝗖𝗟𝗜 𝗼𝗻 𝗪𝗶𝗻𝗱𝗼𝘄𝘀
𝙌𝙪𝙞𝙘𝙠 𝙘𝙤𝙢𝙢𝙖𝙣𝙙𝙨 𝙨𝙝𝙤𝙬𝙣 𝙞𝙣 𝙩𝙝𝙚 𝙫𝙞𝙙𝙚𝙤:
⇒ 𝙑𝙞𝙨𝙞𝙩: github.com/octra-labs/webcli
⇒ 𝘾𝙡𝙤𝙣𝙚 𝙩𝙝𝙚 𝙧𝙚𝙥𝙤:
git clone github.com/octra-labs/webcli
⇒ 𝙋𝙪𝙡𝙡 𝙡𝙖𝙩𝙚𝙨𝙩 𝙪𝙥𝙙𝙖𝙩𝙚𝙨:
git pull
@octra @octralabs
Mar 15

𝐇𝐨𝐰 𝐭𝐨 𝐫𝐮𝐧 𝐨𝐜𝐭𝐫𝐚 𝐰𝐞𝐛𝐜𝐥𝐢 𝐨𝐧 𝐲𝐨𝐮𝐫 𝐦𝐨𝐛𝐢𝐥𝐞 𝐩𝐡𝐨𝐧𝐞 𝐮𝐬𝐢𝐧𝐠 𝐆𝐢𝐭𝐇𝐮𝐛 𝐜𝐨𝐝𝐞𝐬𝐩𝐚𝐜𝐞
🧵🧵🧵

7
2
26
1,355
VINTAGE_JAB retweeted

22h
lambda is referencing the early validator OCT claim: those who connected their devices and registered as a validator in december 2024 could claim their stake for free in june 2025 for testing at the time, it's not an airdrop and not related to individual holdings of validators
Jun 16

today was the final preparation phase for early validators, we took a snapshot of those who hadn't sold their dropped coins (held or encrypted them) - there are currently 69 of them
at the same time, 91 participants got rid of their coins (the latest case was noticed a few hours ago), we were expecting this given the activity, and as soon as everyone who wanted to get rid of their coins had done so, we took a snapshot at epoch 1118156
everyone who held and didn't sell will have great news for you before the launch of the validator program
thanks for your support
6
5
58
1,830
VINTAGE_JAB retweeted

Jun 16
today was the final preparation phase for early validators, we took a snapshot of those who hadn't sold their dropped coins (held or encrypted them) - there are currently 69 of them
at the same time, 91 participants got rid of their coins (the latest case was noticed a few hours ago), we were expecting this given the activity, and as soon as everyone who wanted to get rid of their coins had done so, we took a snapshot at epoch 1118156
everyone who held and didn't sell will have great news for you before the launch of the validator program
thanks for your support
39
27
177
8,274

every new passing day is an ad for a fast and reliable substrate built around general purpose encrypted compute
tor has 2.5 million daily users, how many would it have if it accessible like VPN, tokenized like web3, and programmable like a personal OS?
21
30
183
8,705
VINTAGE_JAB retweeted
Jun 14
some info about upcoming mini-updates and the mini-roadmap:
- a planned transition to a new proof format (TAPE verifier), natively supported by hfhe (field core), is scheduled for next week, it will lead to faster processing of heavy txs and increased security, however, this also has a trade off, as a migration to the new ct-format (client side manual re-encryption) will be prepared (stress free, one tx), details will be provided later, once we've completed this
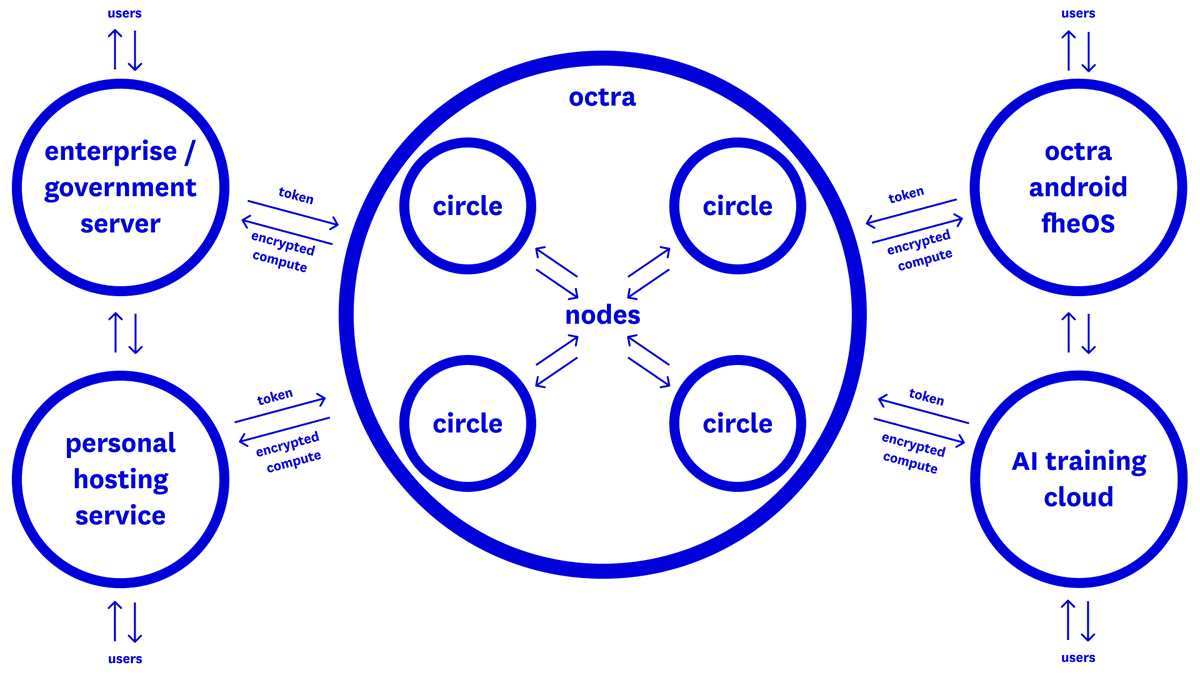
- expanded circle functionality and app launchpad directly within the network, minimal deployment at startup, and a flexible way to deploy code, debug, and configure security settings, circles from the examples are becoming a truly universal tool for running proprietary private computing.
- a small breakthrough in on-chain inference (a fully open LLM circle, optimized specifically for ML, has become even faster), in the app launchpad, you simply select the interface, an available model, and deploy with a customizable access level
- a small release of a private tx example on the EVM network (evm sepolia/octra devnet ), a non-blocking pool, etc
- bridge update and stealth bridge capability
- other minor thing 1: a lite node will be available any day in the next two weeks (along with a convenient launch container)
- other minor thing 2: mini-paper release
ps: we spent the last week working on security, so things have been a bit quiet
some ppl tried to sour the mood, but we’re not too bothered, work goes on
thanks for your support Chiefs and wish you a good start to the new week
53
43
180
18,828
VINTAGE_JAB retweeted
Jun 15
AI (ML) won't take over the world, it will simply render the real world and other ppl unnecessary and humanity will quietly die out from loneliness and a lack of meaning (a quiet, comfortable, lonely dystopia)
develop your brain yourself, read, solve problems, write the code yourself and don't be afraid to make mistakes (it's the same learning process)
May 24
Btw, a fun fact about ML and contex mixing - all the time at the end of school and the beginning of university, I was fascinated by data compression and algorithmic codecs. This is essentially how I started my career as a C developer. There's one fun fact about compression that just occurred to me: the legendary Matt Mahoney, who created the most powerful algorithmic coder and founded the PAQ family, variations of which constantly won the Hutter Prize for data compression, essentially laid the foundation for the concept of ML through data compression, since algorithmic codecs are built on predictive models and sigmoid functions for constructing frequency context models based on the data type. So, what I'm getting at is that in our "narrow" circle of those involved in this topic, there was a clear justification for what AGI is expressed through data compression. As you know - you can't bypass the Shannon limit, that's a hard math law. However, the Shannon limit is bound to a specific predictive model. If an algorithmic codec can build such a profound, context aware model of the world that its 'guessing' pushes the practical compression down to the data's absolute, intrinsic complexity, that might just be the key to unlocking AGI.
If you want to start approaching AGI, you need to pay attention to data compression, bc if a context codec model can "decompress" and predict and compress the full context of Wikipedia (which in a compressed format has entropy practically within the limits of Shannon), then this may mean that one of the most important steps towards AGI has been made.
PVAC-HFHE uses our own version of algorithmic mixing to compress public keys for the HFHE engine. You can see it here: github.com/octra-labs/webcli…
Now that we're head over heels in working on circles in @octra with the goal of bringing interesting use cases, this has made sense again and we've developed a passion for trying out new hypotheses. So yes, one of the new directions for octra is ML and contextual transformation, because the treechain structure and data model are perfectly compatible with the goals of ML inference. We'll continue working on this (I think every day now) and will report if we find anything interesting.
5
7
81
2,905
VINTAGE_JAB retweeted
Jun 12
a mini update, which actually turned out to be quite large, we updated the library and added the most important part - a recrypt that turns the HFHE (pvac ver) into a circuit with unlimited computation chain depth (we also added a bunch of examples of how to use it)
this is an important part and the penultimate one before the next final update,if you want to understand what this means, run benchmarks and review past results (hfhe against everything)
in the public test, 63 consecutive reset stages pass with support growing to 16 terms per stage and resetting back to 4 terms
run:
make test-hfhe-native
PVAC_HFHE_DEPTH_ROUNDS = 63 make test-hfhe-depth
github.com/octra-labs/pvac_h…
Jan 26
PoC HFHE against everything (benchmarks)
github.com/octra-labs/pvac_h…
19
29
145
18,702
thanks to the massive attention to the privacy sector and octra in recent weeks, we received a few credible bug reports and improvement suggestions from external researchers that have been implemented and will be published separately
we are finishing up all essential security updates and checks, and will be returning to regular product release schedule right after: node release, hyperevm integration, multi-ecosystem stealth bridge, hfhe-llm interface, etc
33
43
258
12,279
VINTAGE_JAB retweeted

Jun 13
after the last mini update, octra can now run arbitrarily deep encrypted computations
and i mean deep deep

3
2
54
929
VINTAGE_JAB retweeted
Jun 13
who cares about the fud when you’re literally posting straight from here

5
2
51
830
VINTAGE_JAB retweeted
Jun 12
nature is clearing up, ignore the slop-noise, let the speculators and gambling addicts be blown away, there's a lot of interesting things ahead
37
24
162
11,658
VINTAGE_JAB retweeted
Jun 11
the 5 stages of understanding FHE:
1. "computing on encrypted data without decrypting it is impossible"
2. "ok hypergraphs made it parallel and faster but it'll never run onchain"
3. "ok octra launches mainnet and runs it onchain but it's just transfers"
4. "ok you can actually deploy full apps in circles but nothing serious runs encrypted"
5. *watches a 135M param language model run inference on encrypted data onchain*
most people are on stage 1. you are here early
9
10
97
2,749
VINTAGE_JAB retweeted

Jun 10
🤔 someone is mass deploying encrypted circles, seemingly adding metadata for a game or NFT project:
octrascan.io/
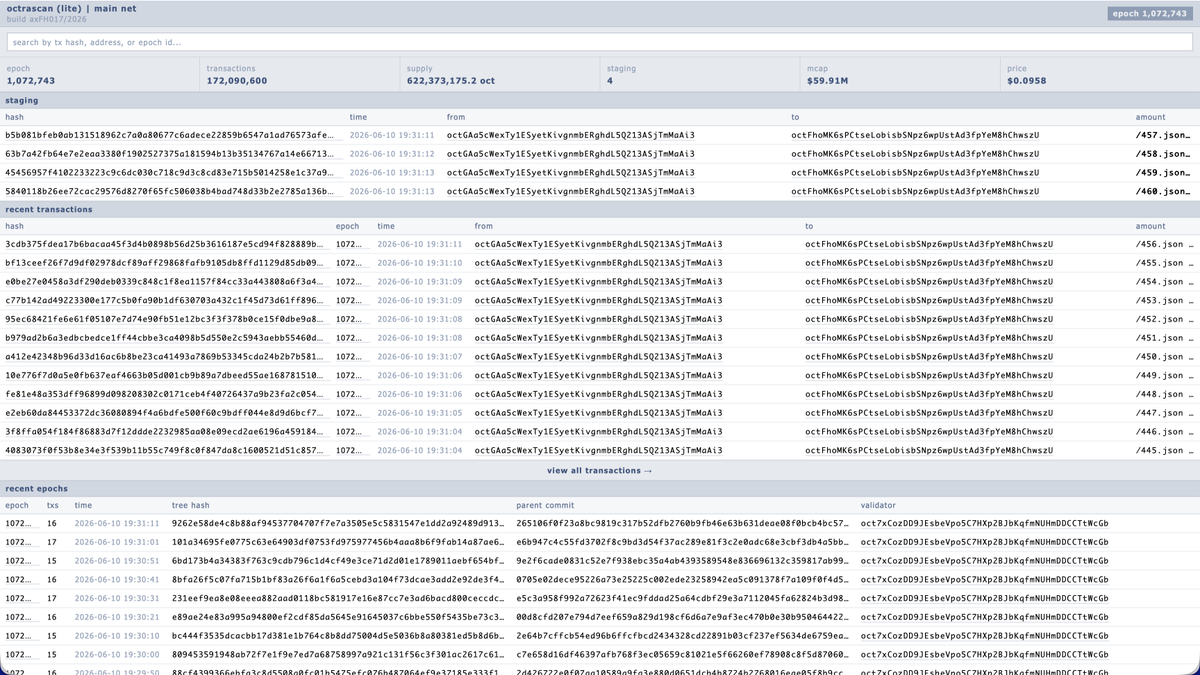
10
12
113
3,409

If you have ever watched a live football match at a local viewing center or a crowded sports bar, you have likely encountered the couch seers. These are the spectators who celebrate a goal or groan at a missed penalty seconds before the action actually unfolds on the main…

9
1
13
262
VINTAGE_JAB retweeted

Jun 8
an important security update has been released, please install the latest version of the web client:
1) export keys
2) delete old client folder
3) download new web client: github.com/octra-labs/webcli
4) rebuild
5) import keys
see instructions: docs.octra.org/user-docs/ins…
Jun 8
a mini update regarding webcli - many security improvements have been added that make it worth updating your version to the latest version (don't delay with the update)
we’re also reinstating the bounty program as an open portal with challenges after receiving good findings from researchers, we'll share more in the coming days once the concept is finalized
github.com/octra-labs/webcli
7
17
125
11,437
VINTAGE_JAB retweeted

Jun 7
Looking at what else is in the “privacy” category, I don’t see how $OCT isn’t worth 1B-2B if adoption and understanding of the use case show up among users and builders.
3
3
56
1,309
VINTAGE_JAB retweeted
Jun 8
a mini update regarding webcli - many security improvements have been added that make it worth updating your version to the latest version (don't delay with the update)
we’re also reinstating the bounty program as an open portal with challenges after receiving good findings from researchers, we'll share more in the coming days once the concept is finalized
github.com/octra-labs/webcli
29
23
148
26,379

$ZEC just got rekt. It's finally $OCT season? 👀
Still have some concerns. But, $140M FDV remains my target. Until then, I'll keep trying to be your liquidator.
😂


Jika $XMR adalah raja, dan $ZEC adalah putra mahkota, maka:
Hanya hanya masalah waktu perhatian pendukung keduanya beralih ke $OCT.
Hanya masalah waktu CEXs akan mendaftarkan nya.
Hanya masalah waktu CT akan membicarakan nya.
Bullish? Personally, yes. Saya lebih suka proyek yang launch dengan FDV rendah.
Takut? Juga iya, terutama soal keamanan bridge.
So, find your own conviction.

17
2
50
4,128
VINTAGE_JAB retweeted
Jun 6
"i'm thankful to my founder that he didn't get affected by this fud and we kept building throughout all these 5 years"
"we built through the literal bear market for privacy"
-our cofounder @octralex on building octra
7
5
88
2,092
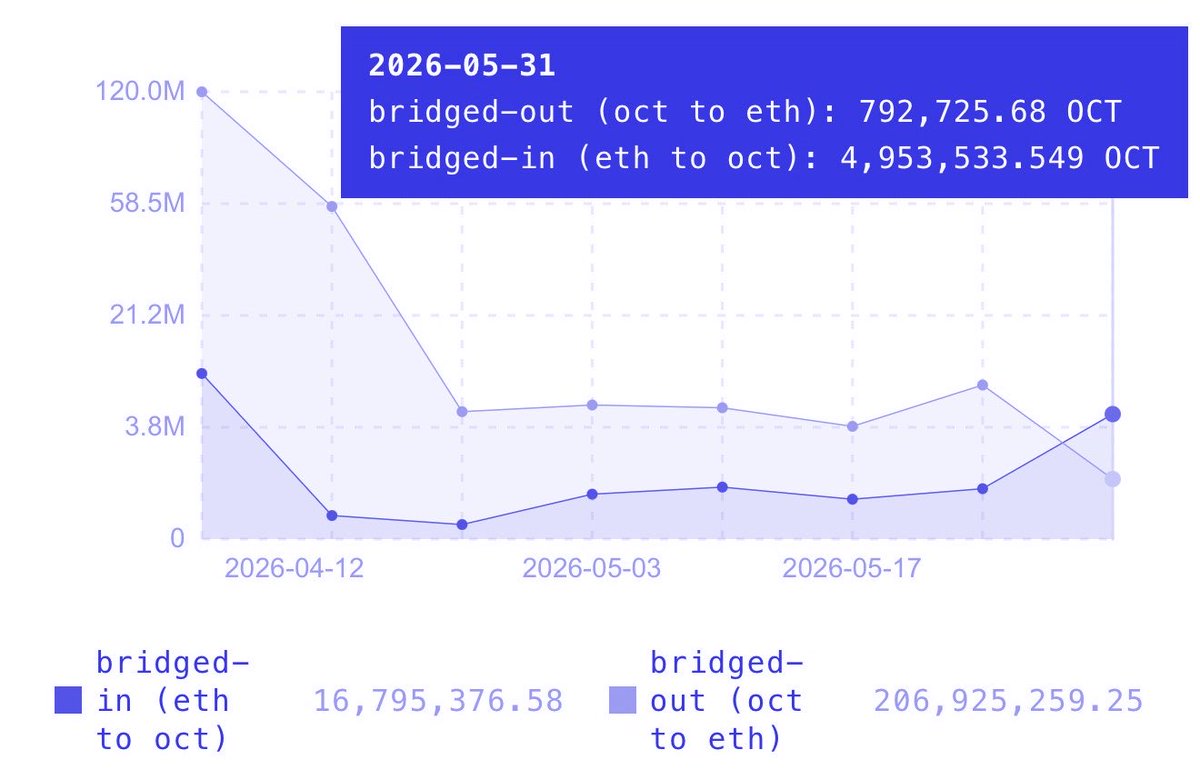
the bridge recorded the highest inflow of OCT to octra network this week
for the first time ever, the weekly bridged-in supply (4,953,533.549 OCT) exceeded the bridged-out supply (792,725.68)
most of the bridged-in supply was then encrypted
data from octra.online 💙
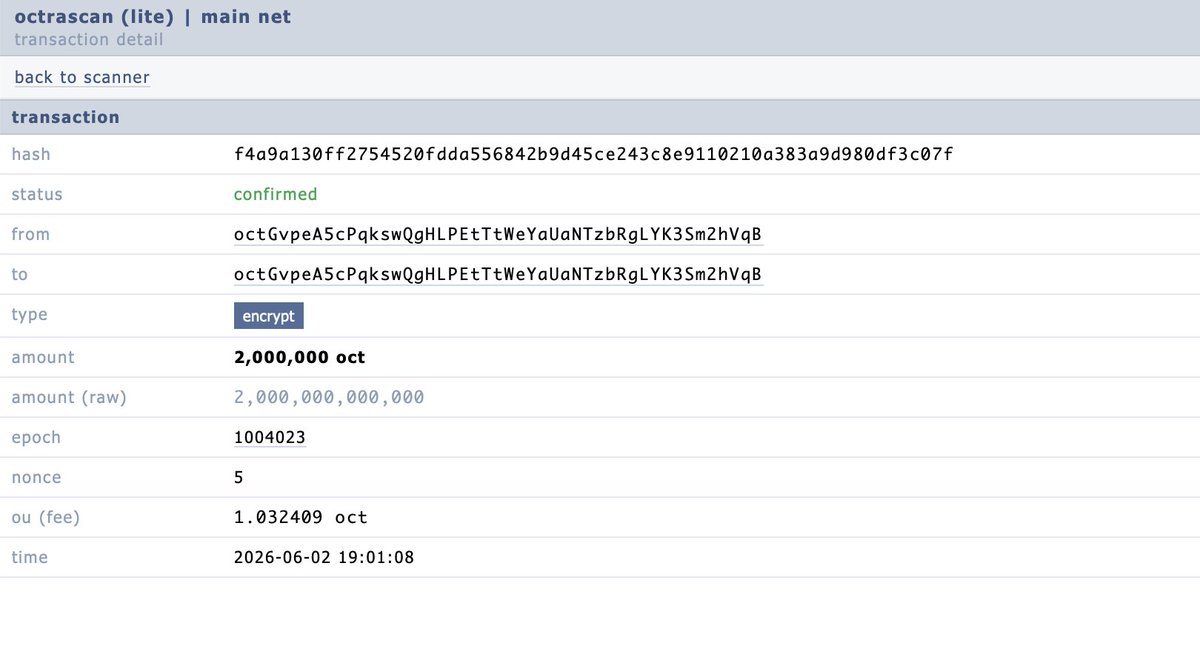
Jun 2

😅 update: someone just encrypted 2,000,000 oct more, which is definitely the largest encrypt transaction ever
octrascan.io/tx.html?hash=f4…
35
28
220
32,529

