
Computer Vision research group at @UvA_Amsterdam directed by Cees Snoek (@cgmsnoek)
Joined May 2024
- Tweets 54
- Following 28
- Followers 59
- Likes 97
Photos and videos
Video & Image Sense Lab (VIS Lab) retweeted

7 Nov 2024
📢📢 Beyond Model Adaptation at Test Time: A Survey by @zehao_xiao. TL;DR: we provide a comprehensive and systematic review on test-time adaptation, covering more than 400 recent papers 💯💯💯💯 🤩 #CVPR2025 #ICLR2025
arxiv.org/abs/2411.03687

1
17
58
8,117
Video & Image Sense Lab (VIS Lab) retweeted

18 Oct 2024
All vision-language models should have hyperbolic embeddings. Vision and language are incredibly hierarchical in nature!
See below our latest work on hyperbolic vision-language models that exploit visual compositions through entailment:
18 Oct 2024

(1/6)🥳 Excited to share my latest research done as part of my MSc AI thesis! We introduced Hyperbolic Compositional CLIP (HyCoCLIP)—a novel framework that leverages the hierarchical nature of hyperbolic space for learning vision-language representations using scene compositions.
2
11
155
21,931
Video & Image Sense Lab (VIS Lab) retweeted

21 Oct 2024
🚀 Excited to share LynX! 🦁
🔑 A new method in visual grounding using a Dual Mixture of Experts—LynX enables pretrained VLMs to continuously learn grounding while retaining their image-language capabilities.
📄 Check out the full paper: arxiv.org/pdf/2410.10491
1
7
15
2,685
Video & Image Sense Lab (VIS Lab) retweeted

15 Oct 2024
📢 Announcing TVBench: Temporal Video-Language Benchmark 📺 We reveal that widely used Video-Language benchmarks, such as MVBench, fall short in testing temporal understanding and propose an alternative TVBench: huggingface.co/datasets/FunA…
15 Oct 2024

Today, we're introducing TVBench! 📹💬
Video-language evaluation is crucial, but are we doing it right? We find that current benchmarks fall short in testing temporal understanding. 🧵👇
5
31
2,348
Video & Image Sense Lab (VIS Lab) retweeted

15 Oct 2024
Today, we're introducing TVBench! 📹💬
Video-language evaluation is crucial, but are we doing it right? We find that current benchmarks fall short in testing temporal understanding. 🧵👇
2
12
69
9,361
Video & Image Sense Lab (VIS Lab) retweeted
7 Oct 2024
Excited to announce that today I'm starting my new position at @utn_nuremberg as a full Professor 🎉. I thank everyone who has helped me to get to this point, you're all the best! Our lab is called FunAI Lab, where we strive to put the fun into fundamental research. 😎 Let's go!


43
14
271
15,927
Video & Image Sense Lab (VIS Lab) retweeted

8 Oct 2024
🇨🇦 Deeeelighted to share that this work got into #neurips2024. Many thanks to my dear friend and co-author @Dafidofff, as well as the rest of the team.
Solving PDEs in continuous space-time with Neural Fields on cool geometries while respecting their inherent symmetries! 💫💫
8 Jul 2024

🌀 Equivariant Neural Fields (ENFs) for continuous PDE solving! We use ENFs as representation for solving PDEs in continuous space/time on different geometries while respecting their symmetries! (such as this internally heated ball of fluid)
More details 👇
3
31
196
23,009
Video & Image Sense Lab (VIS Lab) retweeted
9 Oct 2024
Congratulations Dr. @Jocy48305373 🥳

3
24
1,191
Video & Image Sense Lab (VIS Lab) retweeted
9 Oct 2024
The Self-Supervised Learning: What is Next? workshop at @eccvconf had a great turnout with excellent talks. Slides of most talks are available at sslwin.org (soon all 🤞). Thanks to all attendees, speakers, and co-organizers for making it a fantastic event!




25 Sep 2024

Interested in learning about the future of self-supervised learning? Don’t miss our workshop this Sunday at @eccvconf with an incredible lineup of speakers! 🔥
@imisra_ @oriane_simeoni @endernewton @olivierhenaff @y_m_asano @YutongBAI1002
More details at sslwin.org

2
13
63
9,149
Video & Image Sense Lab (VIS Lab) retweeted

4 Oct 2024
Stop by today and discuss our @eccvconf paper (SelEx) with me, @doughty_hazel, and @cgmsnoek! 🎉
We present self-expertise—an alternative to self-supervision for learning from unlabelled data with fine-grained distinctions and unknown categories.
📍 Poster #89
🕥 10:30 AM
4
22
2,382
Video & Image Sense Lab (VIS Lab) retweeted

1 Oct 2024
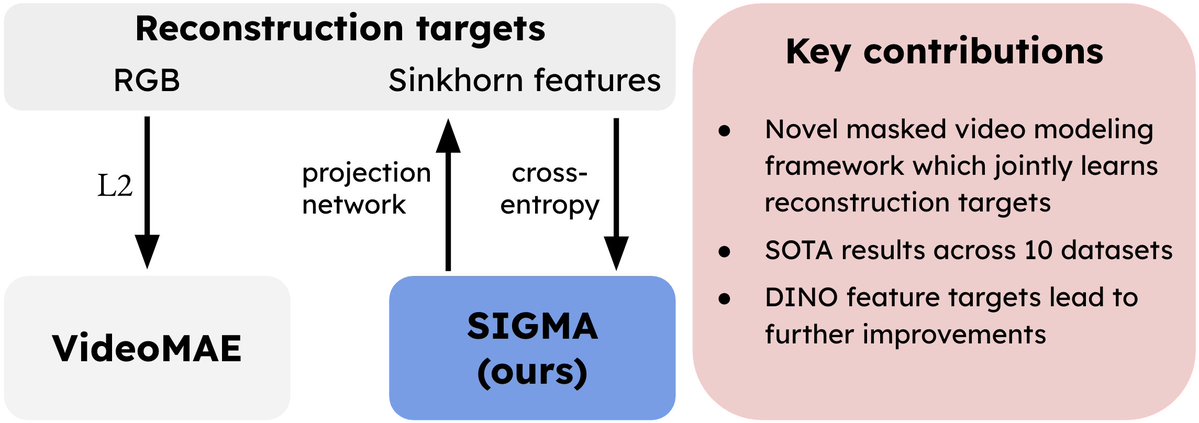
🚀 Excited to present SIGMA at @eccvconf ! 🎉 We upgrade VideoMAE with Sinkhorn-Knopp on patch-level embeddings, pushing reconstruction to more semantic features. With @mdorkenw.
Let’s connect at today's poster session at 4:30 PM, poster number 256, or send us a DM.
29 Jul 2024
📢SIGMA: Sinkhorn-Guided Masked Video Modeling got accepted to @eccvconf #ECCV2024
TL;DR: Instead of using pixel targets in Video Masked Modeling, we reconstruct jointly trained features using Sinkhorn guidance, achieving SOTA.
📝Project page: quva-lab.github.io/SIGMA/
🌐Paper: arxiv.org/abs/2407.15447
Joint work with @MrzSalehi @fmthoker @egavves @cgmsnoek @y_m_asano
5
11
3,561
Video & Image Sense Lab (VIS Lab) retweeted
30 Sep 2024
🚀 Excited to present our work on Self-Expertise at #ECCV2024 in Milan!
Join us at poster #89 on Friday, Oct 4 at 10:30 AM to see how self-expertise outperforms self-supervision in tackling unknown data in open-world settings! 🌍 #SelfSupervision #GeneralizedCategoryDiscovery

9
32
2,286
Video & Image Sense Lab (VIS Lab) retweeted

30 Sep 2024
We're happy to be at #ECCV2024 this week thanks to our cooperation with @VISLab_UvA . Check out @melikaayoughi work at the Instance-Level Recognition Workshop the Self-Supervised Learning workshop.
2
7
1,668
Video & Image Sense Lab (VIS Lab) retweeted
25 Sep 2024
Interested in learning about the future of self-supervised learning? Don’t miss our workshop this Sunday at @eccvconf with an incredible lineup of speakers! 🔥
@imisra_ @oriane_simeoni @endernewton @olivierhenaff @y_m_asano @YutongBAI1002
More details at sslwin.org
5
21
81
26,864
Video & Image Sense Lab (VIS Lab) retweeted
29 Aug 2024
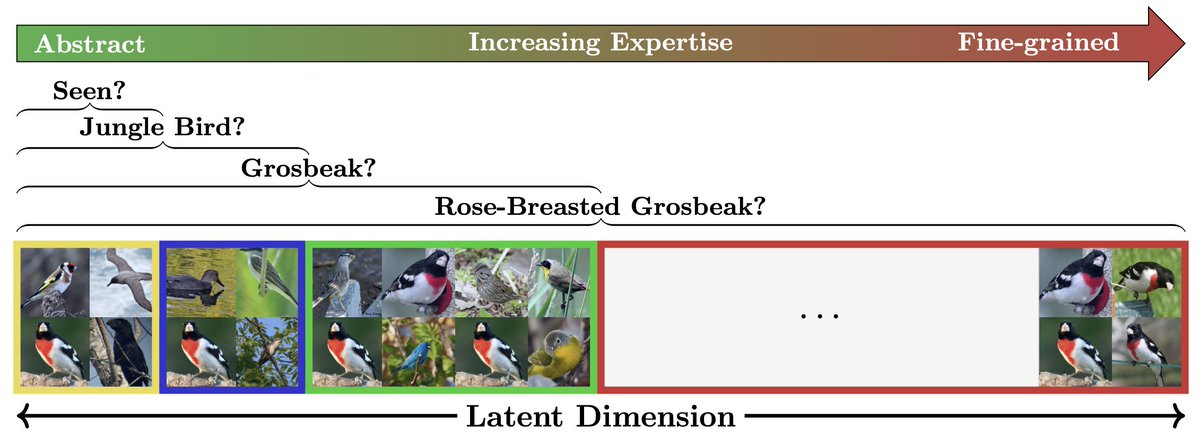
🚀 Excited to announce that our paper "SelEx: Self-Expertise in Fine-Grained Generalized Category Discovery" has been accepted to ECCV 2024! 🎉
Special thanks to my incredible coauthor @MrzSalehi and my amazing supervisors @y_m_asano, @doughty_hazel, and @cgmsnoek🙏.
5
11
39
3,418

We are hiring a postdoc! Come work with us in the booming AI ecosystem of beautiful Amsterdam on generative AI and/or uncertainty quantification 🤗
🎇vacatures.uva.nl/UvA/job/Pos…

30 Aug 2024

I’m hiring a postdoc to work with me on exciting projects in generative modelling (AI) and/or uncertainty quantification. You'll be part of a great team, embedded in @AmlabUva and the UvA-Bosch Delta Lab.
Apply here: vacatures.uva.nl/UvA/job/Pos…
RT appreciated!
#ML #GenAI
7
31
2,763
Video & Image Sense Lab (VIS Lab) retweeted

31 Aug 2024
I will be in Montréal until December for my internship with ServiceNow. I will be working on causal discovery from time-series. Get in touch if you are around and want to chat about some **apprentissage profond**

1
20
1,311
Video & Image Sense Lab (VIS Lab) retweeted

12 Sep 2024
📢📢📢 PhD vacancy alert 📢📢📢
We open several PhD positions supervised by myself and Georgios on #Robot Learning and #Dynamics!
If you have strong #ML and/or #Robotics experience and want to dive into the next big thing in #AI, apply!
Please share!
linkedin.com/jobs/view/40214…
19
69
8,084
Video & Image Sense Lab (VIS Lab) retweeted
14 Sep 2024
First time organising a Tutorial with an amazing team and am very excited 🎉! The topic is learning from videos, which I think will be the new 'Big' paradigm for new vision foundation models. Come to learn, chat and discuss @eccvconf!
14 Sep 2024

Incredibly excited to announce the 1st edition of our tutorial at @eccvconf w/ the amazing @y_m_asano and @MrzSalehi!
"Time is precious: Self-Supervised Learning Beyond Images" on 30th Sept. from 09:00 to 13:00 at Amber 7 8
Catch the details here⬇️
shashankvkt.github.io/eccv20…
2
7
51
4,852
Video & Image Sense Lab (VIS Lab) retweeted
29 Jul 2024
Happy to present this paper accepted @eccvconf: upgrades VideoMAE to use Sinkhorn-Knopp on patch-level embeddings. This moves reconstruction one level up towards more semantic features. Training is simple & stable.
29 Jul 2024
📢SIGMA: Sinkhorn-Guided Masked Video Modeling got accepted to @eccvconf #ECCV2024
TL;DR: Instead of using pixel targets in Video Masked Modeling, we reconstruct jointly trained features using Sinkhorn guidance, achieving SOTA.
📝Project page: quva-lab.github.io/SIGMA/
🌐Paper: arxiv.org/abs/2407.15447
Joint work with @MrzSalehi @fmthoker @egavves @cgmsnoek @y_m_asano
4
43
2,488