
Vectara's AI Assistant/Agent solution is enterprise-ready, focusing on accuracy, explainability of results, and secure access control.
Joined May 2022
- Tweets 2,920
- Following 2,439
- Followers 6,340
- Likes 7,127
520 Photos and videos
















5 Million Downloads and Counting!
The Hughes Hallucination Evaluation Model (HHEM) has now surpassed 5 MILLION downloads on Hugging Face. This milestone underscores the growing demand for AI that is not only powerful, but verifiably trustworthy.
And we’re not stopping there. Building on HHEM’s momentum:
→ Vectara Hallucination Corrector (VHC) is already available, taking you beyond detection to automatic correction
→ Vectara Agents bring the next wave of Agentic AI: enterprise-grade copilots that are grounded in RAG, governed by Guardian Agents, and designed for real-world business impact.
Explore HHEM → bit.ly/3vejcTw
Try VHC → bit.ly/43PXqnj
Discover Vectara Agents → bit.ly/3Kiz6U1
#GenAI #TrustedAI #AIforEnterprise #LLMEvaluation #HuggingFace #RAGaaS #AIInfra #Vectara

4
5
22
2,751
Everyone’s talking about AI agents, but there’s a big difference between hosting an agent and actually building a scalable, production-ready agentic platform.
In our latest blog, we break down why spinning up an agent is just the beginning. The real challenge (and opportunity) lies in context engineering, giving agents the right information at the right time so they can reason, act, and deliver reliable outcomes.
If you’re thinking beyond demos and want to understand what it takes to build robust, enterprise-grade agent systems, this is worth a read 👇
vectara.com/blog/context-eng…
#AI #AgenticAI #LLMs #ContextEngineering #EnterpriseAI
1
5
159
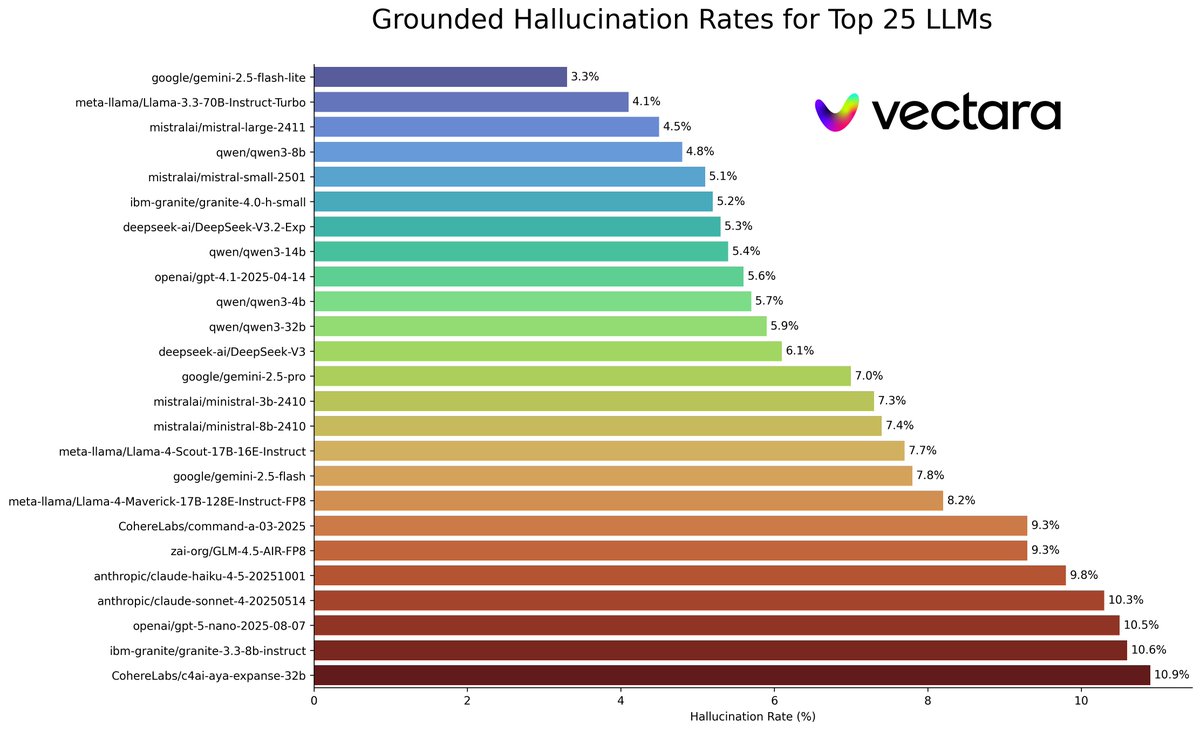
We have Gemma-4, Kimmi K2.6 and Opus-4.7 now on the @vectara hallucination leaderboard.
@Google Gemma-4 is surprising good at 5.2% for the 26B model.
github.com/vectara/hallucina…
1
4
211
Some new case studies added to awesome-agent-failures, including the @amazon-Q Retail outage, the @ClaudeCode Terraform issue, and of course (how can we do without) - one from @openclaw.
3
332
More case studies for agentic failures added to the "awesome-agent-failures" repository
Check them out: HHS Chatbot, Amazon Q and Cursor.
github.com/vectara/awesome-a…
1
4
272
Lots of new LLM releases from China - we just updated @vectara's hallucination leaderboard with evaluations for @Zai_org's GLM-5, @qwen's Qwen-3.5 and @MiniMax_AI Minimax-2.5.
@deepseek_ai - we're waiting for DeepSeek-v4. Excited to see all this innovation and progress in the open source LLM space.
github.com/vectara/hallucina…
1
8
624
The future of enterprise AI isn’t just systems of record. It’s systems of context.
Systems like Salesforce or SAP tell you what happened.
AI agents need to know why it happened.
That’s where the Context Graph comes in 👇
It captures:
• decision trails
• exceptions & edge cases
• human reasoning
• organizational memory
Not just data → understanding.
This shift enables AI agents that reason, act safely, and operate with real-world nuance.
From recording outcomes to understanding intent.
That’s the next platform shift.
vectara.com/blog/beyond-the-…
#AI #EnterpriseAI #ContextGraph #KnowledgeGraph #Vectara
1
5
232
Building AI agents on-prem?
Our latest blog breaks down how to architect **robust on-prem AI agent orchestration**—from agent roles to data, compute, governance, and security—so you can move from demos to production with confidence.
vectara.com/blog/how-to-arch…
1
4
195
New additions to Awesome Agent Failures: 3 fresh case studies.
The most interesting one? You already know.
moltbook/openClaw — a goldmine of security vulnerabilities for an AI agent.
Learn from other people’s agent mistakes 👇
github.com/vectara/awesome-a…
3
199
📢 Calling all AI enthusiasts!
Join AI by Hand ✍️ Seminar: Foundation (AI Eval): a free live Zoom seminar diving into foundational AI concepts like perplexity, cross-entropy, BERTScore, BLEU, ROUGE & more! ✨
📍 Hosted by Prof. @ProfTomYeh | 🗓️ With guest expert @ofermend (Vectara)
🎟️ Register now 👉 luma.com/y9xvjdz9
🔍 Designed for beginners & curious minds. Don’t miss out! 🙌
#AI #MachineLearning #AIeducation #AICommunity #TechEvents
4
163
Context engineering depends on precision, and precision depends on retrieval.
This is why Vectara was built on a simple, stubborn belief: retrieval is the most important layer in the AI stack. Larger context windows were supposed to solve enterprise memory. Instead, they delivered degraded performance and runaway latency. The real answer? Pair context with surgical retrieval.
Read more about Contextual Engineering here: vectara.com/blog/context-eng…
1
3
148
Three new case studies of agent failures added to Awesome-Agent-Failures repo, including the so called "LangGrinch" vulnerability that can be used by an attacker to uncover your secrets (upgrade @LangChain to avoid this).
How many more hidden vulnerabilities exist in open source Agentic AI packages?
github.com/vectara/awesome-a…
2
10
179
In a recent Digital IT News piece on AI predictions for the year ahead, @EvaNahari explains why AI agents will require new semantic interfaces and permission structures to retrieve accurate enterprise knowledge.
Read the full article here:
digitalitnews.com/prepare-fo…
#EnterpriseAI #SemanticLayer #AIGovernance #Vectara
2
10
196
As the year comes to an end, it’s a good moment to pause and look at where enterprise AI is actually heading.
We shared our take on why 2026 looks like the moment AI grows up, and what that means for teams building real production systems.
Read the full blog below: bit.ly/49fIujS
2
12
243
We've create this app to test your knowledge about agentic AI, just in time for the holidays.
agentic-ai-challenge.vectara…
1
9
247
ICYMI: we've recently released a ton of new features for developing agents with @vectara - e.g. subagents and artifacts.
sub-agents: vectara.com/blog/introducing…
artifacts: vectara.com/blog/beyond-text…
Here is a full cookbook / tutorial (set of Jupyter notebooks) so you can see how it works:
github.com/vectara/example-n…
1
1
9
216
Vectara retweeted

16 Dec 2025
Can you solve these 20 agentic AI problems? Download this problem set I designed 👉 byhand.ai/pset
8
64
387
20,469
A key design goal of Open-RAG-Eval was to allow reference-free evaluation of both retrieval (using the UMBRELA score) and generation (using AutoNuggetizer). This is extremely valuable as you scale your RAG pipeline since generating answers manually for a production system is extremely time consuming and often infeasible in practice.
Yet sometimes you already have a list of questions and "golden answers" and want to use those - so we added support for that in Open-RAG-Eval through the GoldenAnswersEvaluator and now you can do both.
Check out the new version 0.3.0 here: github.com/vectara/open-rag-…
Or "pip install open-rag-eval"
3
8
211
When AI agents look impressive in demos but struggle in real workflows
A recent article on Microsoft Copilot highlights a challenge many enterprises are running into as they scale agentic AI. Moving from pilot to production exposes gaps in reliability, accuracy, and real workflow integration that demos rarely reveal.
This is exactly why enterprise AI needs to be built differently from the start. Systems have to stay grounded in real data, operate under always-on governance, and deliver consistent results inside complex, high-stakes workflows.
Read the full article: bit.ly/4pEcP2B
#EnterpriseAI #AgenticAI #AIAdoption #TrustedAI #AIGovernance
4
11
240
We’re sharing a deeper look at how the Tool Validator Guardian Agent works and why tool-call reliability is critical for agentic systems.
This blog walks through the guardrails that identify incorrect or unnecessary tool calls, and how the Tool Validator validates tool usage correctness and relevance before any API call is executed.
Read the full blog here 👉 bit.ly/4pAe02Y
#AgentOS #GuardianAgents #AgenticRAG #TrustedAI #EnterpriseAI
1
4
12
456
We’re excited to introduce the Tool Validator, our new Guardian Agent that reviews an agent’s workflow plan before execution. It flags erroneous or irrelevant tool calls and identifies missing or unnecessary tools, prompting the agent to recalculate its plan before execution.
Extending the Agent OS with another layer of always-on governance designed to keep actions safe, grounded, and aligned with enterprise policy.
Full announcement: prn.to/4pVu4vW
#AgentOS #AIAgents #Governance #EnterpriseAI #TrustedAI
3
12
185