
Joined January 2025
- Tweets 1,545
- Following 848
- Followers 100,566
- Likes 8,025
211 Photos and videos














Pinned Tweet
Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
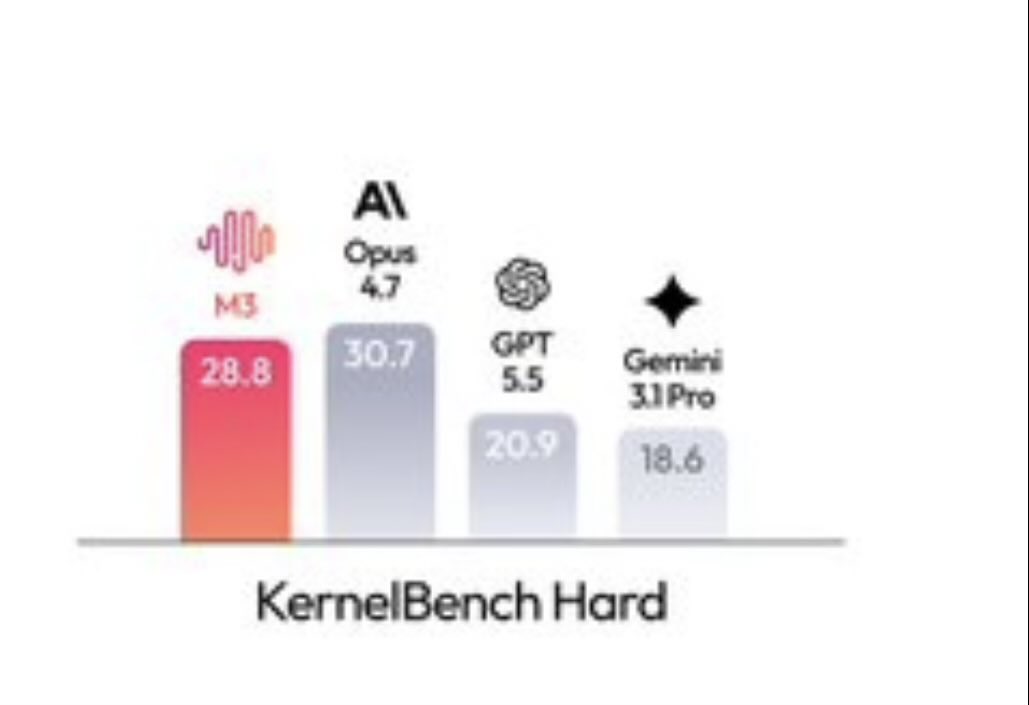
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days
559
1,154
11,070
4,938,351
All powered by M3 on Hermes Agent @NousResearch

I didn't touch TouchDesigner myself. Hermes agent learned it from scratch and built this:
→ navigated my desktop with computer use
→ figured out how to connect to TouchDesigner
→ read my reference images
→ iterated on the art with me in a self-learning loop
→ then saved what it learned as a reusable skill for the next image
all powered by @MiniMax_AI M3 × Hermes Desktop Agent @NousResearch
Here's a full breakdown 📽️
8
5
113
8,325
Love to see it! 🚀
One day in and the community is already shipping optimizations for faster decode. 🥳

Made some improvements on the decode path for MiniMax M3 by @MiniMax_AI on MLX-VLM
Faster decode, slightly lighter footprint.
Thanks to @ivanfioravanti for the PR 🚀
PR:
github.com/Blaizzy/mlx-vlm/p…

6
4
172
10,521
We love what the community is building with M3 open weights ♥️
Excited for what’s next
Jun 13

MiniMax M3 support added to mlx-vlm with MSA implementation! 🚀
Tested on M3 Ultra 512GB running at 24 tps with peak memory ~240GB.
Now working on optimizing performance and adding ton of tests 💪
Model is here: huggingface.co/mlx-community…
PR is here: github.com/Blaizzy/mlx-vlm/p…
13
9
152
13,398

My goal on Minimax M3 post-train :
Uncensored, sovereignty, better performance than Opus-4.7
Let’s start cooking.
Jun 12

MiniMax M3 can now be run locally!🔥
MiniMax-M3 is a new 428B (23B active) open model with 1M context that performs on par with Gemini 3.1 Pro.
Run Dynamic 2-bit GGUF on 138GB RAM/VRAM or 3-bit on 165GB.
GGUF: huggingface.co/unsloth/MiniM…
Guide: unsloth.ai/docs/models/minim…

26
32
565
54,898

Jun 13
M3 would never 🙂↔️
As a matter of fact, the weights are now open, too.
huggingface.co/MiniMaxAI/Min…
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
238
467
6,397
489,094
Jun 13
M3 is running together 🤝 with @togethercompute, and with faster-than-ever inference
Jun 13

MiniMax-M3 from @MiniMax_AI is now available on Together AI.
It’s an open-weight native multimodal model with 1M context, MiniMax Sparse Attention, and thinking / non-thinking modes.
Together AI is MiniMax’s preferred cloud partner, with inference optimizations delivering up to 125% higher throughput across concurrency levels.

5
2
56
7,668
Jun 13
the kernels are doing the lord's work today, day-0 on @vllm_project, verified on nvidia and amd.
go read the writeup 👇
Jun 12

🎉 Congrats to @MiniMax_AI on releasing MiniMax M3! Frontier coding and agentic capabilities, native image and video input, computer use, and a 1M-token context window, all in a single open model.
At the heart of M3 is MSA, a new sparse attention architecture: instead of attending densely over the full KV cache, each query scores 128-token KV blocks and runs attention only over the top blocks. That is what makes 1M-token context practical to serve.
M3 runs in vLLM with day-0 support, verified on NVIDIA and AMD hardware:
✨ MSA sparse attention with dedicated prefill and decode kernels
✨ 1M-token context serving with prefix caching and chunked prefill
✨ BF16 and MXFP8 checkpoints, with MoE backends for both Hopper and Blackwell
✨ Native multimodal input (image video)
✨ Tool calling, reasoning parsing, and thinking-mode control for agent workloads
Day-0 support like this is a true team effort. Grateful to the teams at @MiniMax_AI, @NVIDIAAI, @AIatAMD, and @inferact, and to the vLLM community for making it happen. 🙏
Deep dive into the implementation, kernel work, and deployment recipes:
🔗 vllm.ai/blog/2026-06-12-mini…
4
1
68
7,885
MiniMax (official) retweeted

Jun 12
We’ve been discussing what parameter size works best for the community. While the M3 series boasts a larger parameter count compared to the M2 lineup, we’ve kept its scale deliberately restrained so local model enthusiasts can run it affordably. This time we settled on 428B, hoping it will be accessible to a wider audience.

400B ? I doubt whether you have the capability to train models with 800B parameters or even 1T parameters.
42
16
371
33,869
MiniMax (official) retweeted

Jun 12
Deploy MiniMax M3 with @nvidia Dynamo at scale using your favorite inference engine - @vllm_project, @sgl_project, or TRTLLM!
Comes with PD disagg! :)

Congrats to the @MiniMax_AI team on the release of MiniMax M3, a long-context multimodal model for text, image, and video reasoning. 🙌
Try it today with our free GPU-accelerated endpoint on build.nvidia.com.
Details: nvda.ws/4v4BWhD

1
3
27
6,005
MiniMax (official) retweeted

Jun 12
M3 is strong! It's my main driver for Hermes Agent can manage anything without problems!

11
1
55
8,059
Jun 12
lmk👀
Jun 12

At least the cable is included in the price! Now can it run MiniMax M3?

6
1
123
14,614


Jun 12
With only ~428B params, and ~23B activated params
M3 still handles frontier coding long-horizon agents native multimodal (text, image, video) at 1M-token context
few open-weight models do any of this. M3 does all of it.
Thanks @baseten 🚀

Congrats to the MiniMax team on the open-source launch of M3!
There are very few <500bn parameter models that can tackle coding, agentic workloads, and multimodal all with a 1M-token context window but M3 does it all.
Dig in here: baseten.co/library/minimax-m…

19
22
371
18,044
Jun 12
appreciate it @SambaNovaAI 🤝 looking forward to M3 on RDUs
Jun 12

Congrats to our partners at @MiniMax_AI on the launch of MiniMax M3.
Open-weight models continue to push the ecosystem forward, and we're excited to bring M3 to RDUs down the road.
Looking forward to following what's built with it. 🚀
2
32
5,973
MiniMax (official) retweeted

Jun 12
MiniMax M3 is live on GMI
M3 is the first open-weight model combining frontier coding & agent capabilities, 1M-token context, and native multimodal understanding.

Jun 12

MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…
3
3
29
5,376
Jun 12
means a lot coming from @NVIDIAAI
free GPU-accelerated M3 endpoint are live now
go try it 👇
Congrats to the @MiniMax_AI team on the release of MiniMax M3, a long-context multimodal model for text, image, and video reasoning. 🙌
Try it today with our free GPU-accelerated endpoint on build.nvidia.com.
Details: nvda.ws/4v4BWhD
6
7
269
19,215
Jun 12
day-0 and already on @FireworksAI_HQ with blazing fast inference
long-horizon agents, full-repo understanding, multimodal coding all in one model
Try M3 today on Fireworks AI
Jun 12

MiniMax M3 is live on Fireworks. Day-0, fastest endpoint for the MiniMax series.
→ Top open-weight model on the Artificial Analysis index
→ 512K context, native image video input
→ MSA sparse attention: 9× faster prefill, 15× faster decode
→ Priced at parity with M2.7
Long-horizon agents, full-repo understanding, multimodal coding all in one model.
Learn more: fireworks.ai/blog/minimax-m3…

4
1
85
6,410
Jun 12
M3 is live on @telnyx Inference on day-0
go build with Telnyx and M3 today

@MiniMax_AI M3 is live on Telnyx Inference 🚀
M3 is the first open-weight model combining frontier coding & agent capabilities, 1M-token context, and native multimodal understanding.
M3's 1M context Telnyx's owned GPU infrastructure = fast inference capable of processing entire codebases in one conversation.
It’s time to start building telnyx.com/release-notes/min…

4
27
4,609
Jun 12
Run M3 locally today with @UnslothAI
Jun 12
MiniMax M3 can now be run locally!🔥
MiniMax-M3 is a new 428B (23B active) open model with 1M context that performs on par with Gemini 3.1 Pro.
Run Dynamic 2-bit GGUF on 138GB RAM/VRAM or 3-bit on 165GB.
GGUF: huggingface.co/unsloth/MiniM…
Guide: unsloth.ai/docs/models/minim…
6
11
178
17,943