
Bringing text data to life | Talk to your files: summarise, ask questions, extract insights, analyse emotions, generate question/answer pairs | ali@veracious.ai
Joined February 2023
- Tweets 39
- Following 37
- Followers 143
- Likes 46
14 Photos and videos













Veracious retweeted

30 Apr 2024
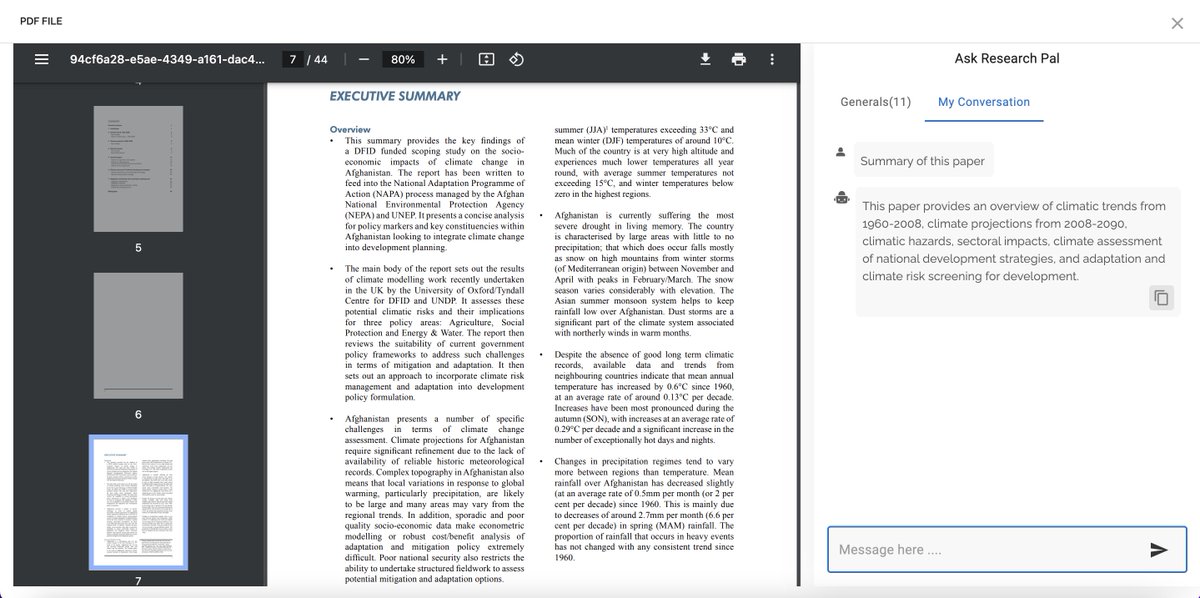
ResearchPal is loved by thousands of students, researchers and industry professionals for writing essays, reports and academic papers.
Use our new AI-powered text writer to write faster and save time with:
- Text Tuner
- Reference Generator
- PDF Chat
- Paper Insights

1
17
23
589
Veracious retweeted
24 Apr 2024
Honoured to have been accepted in the @msft4startups Founders Hub. Looking forward to building our upcoming tools and AI agents on the @Azure stack! Thank you @Microsoft!

1
13
25
423
Veracious retweeted

30 Mar 2024
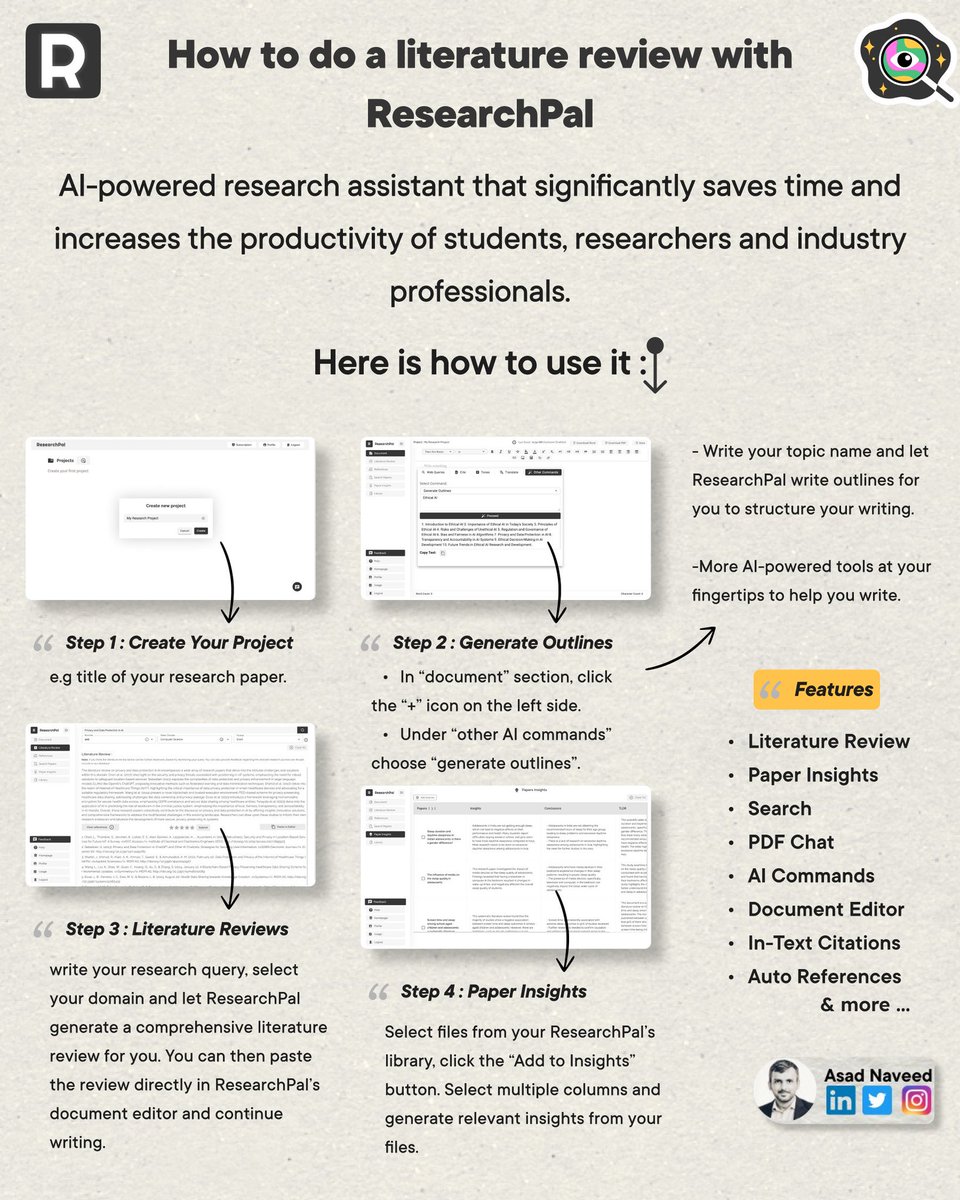
This week, I tried @ResearchPal_AI (researchpal.co) and here's my review on it:
It's a simple tool that quickly automates a lot of your research needs.
Here're some specific use cases:
10
103
316
31,388
Veracious retweeted

30 Mar 2024
❓What's next for AI agents
I was lucky enough to have the opportunity to talk at the recent @sequoia AI ascent on what was next for AI agents
I talked about three things:
🗺️Planning
🖥️UX
🧠Memory
Check out the full video here: youtube.com/watch?v=pBBe1pk8…
14
72
404
59,594
Veracious retweeted

21 Mar 2024
In ResearchPal now you can automatically generate references for your academic writing. Here's you can save time by generating references automatically for your research sources.
Option 1
1. Go to References section.
2. Click on Add Manual Reference button.
3. Add the title of an academic publication and ResearchPal will fetch the reference for you.
Option 2
1. Upload the pdf of an academic publication and ResearchPal will fetch the reference and save it in the References section.
You can also change the referencing format by selecting your preferred format from the dropdown menu in the References section.
Try now for Free and please give us feedback: researchpal.co/
1
11
35
726

18 Mar 2024
ResearchPal is now used by researchers, industry professionals and students in 20 countries around the globe!
Are you starting an essay, report or a research paper with a blank canvas and need some guidance? Type your heading and ask ResearchPal to generate an outline. Demo:
9
18
109
20 Feb 2024
Reading long research papers and looking for the relevant information is really a monotonous task. ResearchPal is here to help you out with this. Upload your research papers and get relevant content within minutes through pdf view.
Try now ResearchPal.co
7
19
296
Veracious retweeted
16 Feb 2024
@mendeley_com @zotero integration is what you all want when it comes to references. You can find seamless integration of Zotero and Mendeley in ResearchPal and generate as many literature reviews as you like along with amazing pdf chatting. Try now
Researchpal.co
8
15
258
Veracious retweeted

30 Nov 2023
ResearchPal is a new app designed especially for academic writing.
It has a built-in search engine. You can look up papers, save them to your library, and extract key insights.
It can also help you with literature review and drafting your paper.
Here's how to use it:
27
308
1,490
383,669
28 Nov 2023
Wondering how to generate quick content on relevant topics or write paragraphs on different queries. We have added in editor option to generate quick responses to your queries and moreover generate citations with relevant papers as well.😉 Try now Researchpal.co
1
7
11
206
23 Nov 2023
We are adding more features for you. You can generate literature with in text citations. Just put in your query and let it do the rest for you.
Along with this import your papers from @zotero and Mendley directly in library with complete source.
Researchpal.co
1
8
13
210
20 Nov 2023
Heads up! One more exciting feature is up and running. You can chat with your pdf with ease.
Save time and get relevant results even without reading whole paper.
Just upload paper in library click on it ask query and see the magic going 🚀
Login now Researchpal.co
8
11
212
17 Nov 2023
We have just added paper insights to allow you generate abstract, results, conclusions from any paper with just a single click. Simply upload your paper select it and add to paper insights.
Add your desired column and check the magic going 🚀🚀
Try now Researchpal.co
1
11
10
224
31 Oct 2023
Demo: Now you can automatically generate academic literature reviews from your research questions and Research Pal will save your citations along with their Abstracts for your review. #ResearchPal
Try our Beta: researchpal.co/
1
11
22
783
26 Sep 2023
We are releasing a python package ResearchPal that enables software engineers to instantly generate literature reviews by inputing a research question. Give it a try and share feedback: pypi.org/project/researchpal…
1
7
814
14 Sep 2023
We are honoured to receive the 'Outstanding Achievements and Research Contributions' award at the CogX Festival: one of the largest events on AI Applications and Research.
#CogXFestival23
1
8
327
12 Sep 2023
Thrilled to announce that! 🚀 We are selected for the AWS Loft Accelerator program! 🌟 We're excited to embark on this journey to supercharge our growth and innovation with the support of AWS. Stay tuned for incredible developments ahead! #AWSLoftAccelerator #VeraciousInnovates
8
201
8 Sep 2023
We are thrilled and honored to announce that our team's dedication to innovation and excellence has earned us a spot among the finalists at this year's CogX Awards. 🏆🎉
Thank you to everyone who has supported us on this journey! 🙏
4
9
746
5 Sep 2023
Searching for academic literature across different databases (arXiv, Semantic Scholar etc) can be hectic. We're sharing the search engine of ResearchPal.co so you can find all the top search results in one place. Contributions Welcome! github.com/VeraciousAI/Liter…
2
6
514
Veracious retweeted

31 Aug 2023
Speculative execution for LLMs is an excellent inference-time optimization.
It hinges on the following unintuitive observation: forwarding an LLM on a single input token takes about as much time as forwarding an LLM on K input tokens in a batch (for larger K than you might think). This unintuitive fact is because sampling is heavily memory bound: most of the "work" is not doing compute, it is reading in the weights of the transformer from VRAM into on-chip cache for processing. So if you're going to do all that work of reading in all those weights, you might as well apply them to a whole batch of input vectors. I went into more detail in an earlier thread:
twitter.com/karpathy/status/…
The reason we can't naively use this fact to sample in chunks of K tokens at a time is that every N-th token depends on what token we sample at time at step N-1. There is a serial dependency, so the baseline implementation just goes one by one left to right.
Now the clever idea is to use a small and cheap draft model to first generate a candidate sequence of K tokens - a "draft". Then we feed all of these together through the big model in a batch. This is almost as fast as feeding in just one token, per the above. Then we go from left to right over the logits predicted by the model and sample tokens. Any sample that agrees with the draft allows us to immediately skip forward to the next token. If there is a disagreement then we throw the draft away and eat the cost of doing some throwaway work (sampling the draft and the forward passing for all the later tokens).
The reason this works in practice is that most of the time the draft tokens get accepted, because they are easy, so even a much smaller draft model gets them. As these easy tokens get accepted, we skip through those parts in leaps. The hard tokens where the big model disagrees "fall back" to original speed, but actually a bit slower because of all the extra work.
So TLDR: this one weird trick works because LLMs are memory bound at inference time, in the "batch size 1" setting of sampling a single sequence of interest, that a large fraction of "local LLM" use cases fall into. And because most tokens are "easy".
References
arxiv.org/abs/2302.01318
arxiv.org/abs/1811.03115
arxiv.org/abs/2211.17192

101
589
3,737
799,291