
thermal photography enthusiast, CS enjoyer, language model researcher
Joined February 2012
- Tweets 3,760
- Following 2,366
- Followers 71
- Likes 122
588 Photos and videos


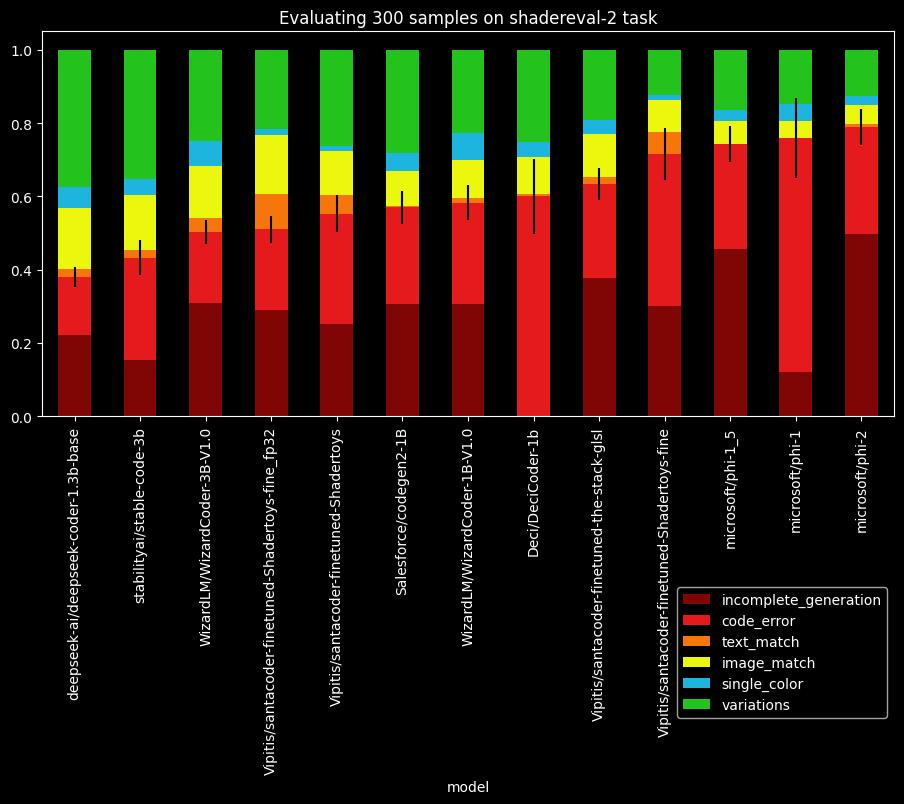

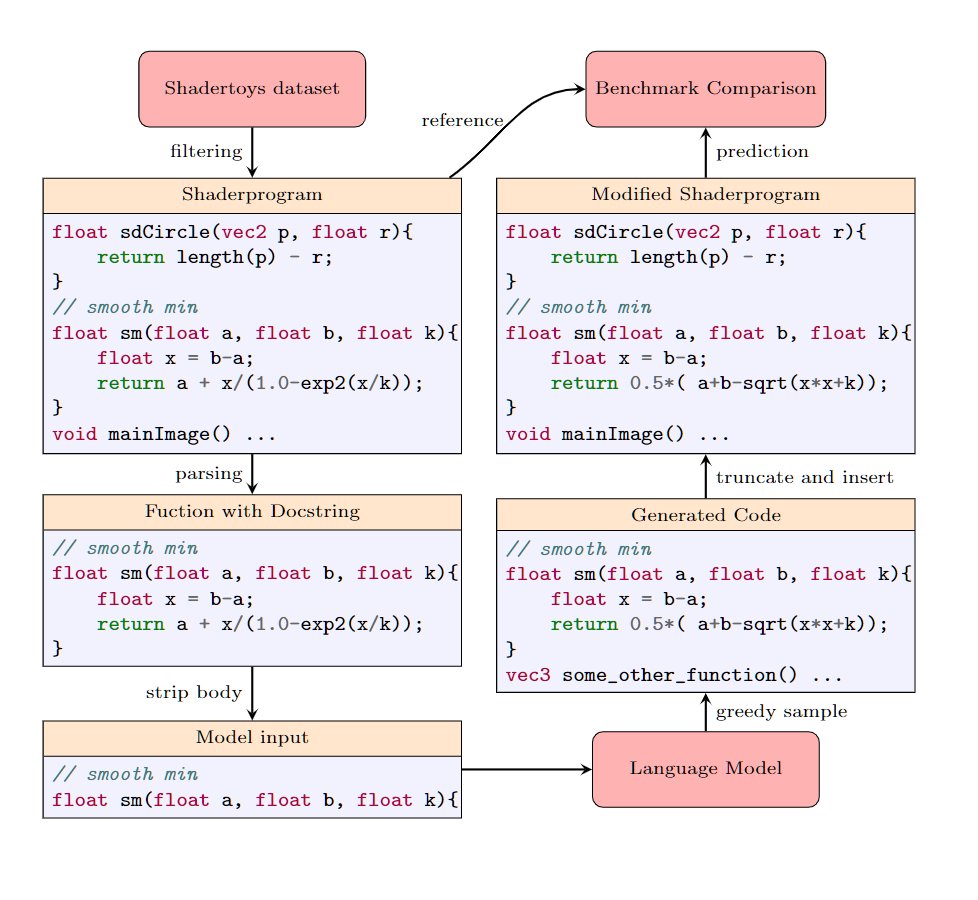
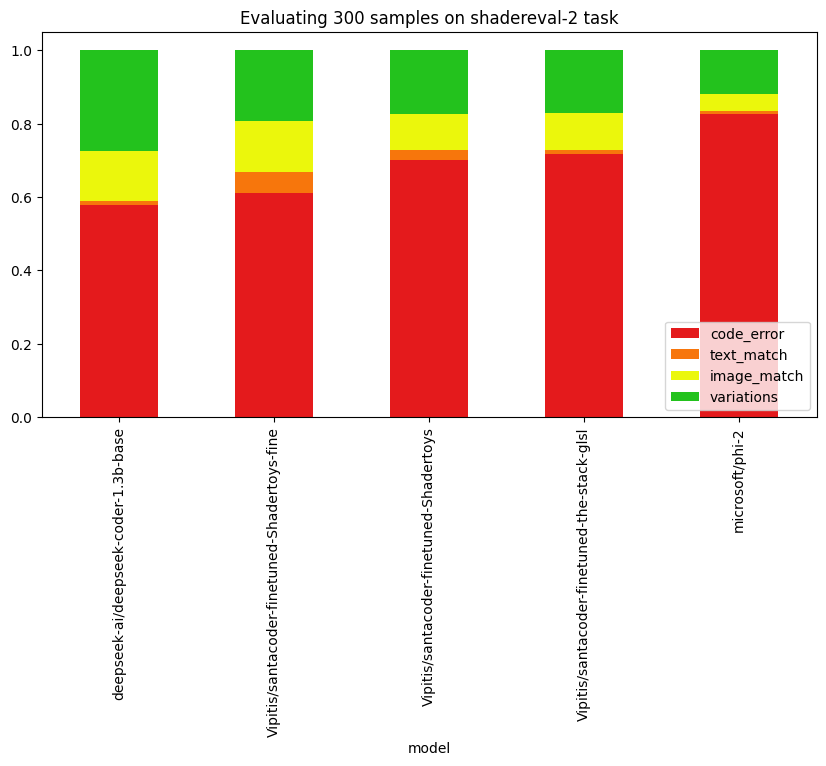


Adding 3:39:54 to my resume
6 Nov 2024

ITS HAPPENING, ITS YAPPENING x.com/i/broadcasts/1vAGRONDp…
1
244
Shadertoy buffers are RGBA and 32bit floats. so they could easily hold the position and velocity of particles in a 2D simulaiton.
experiments with 1 particle: shadertoy.com/view/lXK3WV
75
Did you know that Intel ExtraSS implementation is open source? This seemingly contains the scripts to generate the dataset, model architecture and training code... 👀
github.com/ltkong218/IFRNet/…
81
Any alarmist blog post or sentient machines fiction will end up in training data and cause language models to act in this way. If you want models to be more friendly - write about "helpful AI" than a system prompt telling a model 'you are a helpful AI assistant' makes it better.
1
85