
Skillmaxxing | One agent at a time | Prev Head of Content @TailoredWeb3 |
Joined November 2021
- Tweets 8,903
- Following 653
- Followers 11,925
- Likes 46,677
364 Photos and videos








Virtual Kenji⚡️ retweeted

Jun 13
The takeaway from Fable 5 being BANNED by the government: GET GOOD AT LOCAL MODELS SO YOU HAVE 100% CONTROL.
My entire weekend was going to be building my craziest ideas with Fable 5. That's now cancelled.
So instead of building with Fable this weekend, I've decided I'll go deep on local models:
1. Start with the runtime. Download Ollama or LM Studio first. This is the thing that actually runs models on your machine.
2. Match the model to your hardware. A model's size is measured in billions of parameters (7B, 32B, 70B). Bigger is smarter but needs more memory. Rule of thumb: a 7B model runs on almost any laptop, a 32B needs a good Mac with 32GB RAM, a 70B needs serious hardware like a DGX Spark or a maxed-out Mac Studio.
3. Know which model for which job. Qwen 3 is the best all-around choice for most tasks. DeepSeek for reasoning and coding. Gemma 4 when you need something tiny that runs on a phone. Llama when you want the biggest community and the most fine-tunes.
4. Quantization. You can shrink a model to run on weaker hardware with barely any quality loss. Look for versions labeled Q4 or Q5. This is how a model that "needs" a server runs on your laptop. Learning this one concept changes everything.
5. Connect it to your agent. Point Hermes or your agent stack at a local model.
6. Context window is your real constraint locally. Cloud models give you huge context for free. Local models make you pay for it in memory. A bigger context window eats RAM fast. Keep your sessions tight and your prompts lean or your machine chokes.
7. Learn to give local models tools. A smaller local model with web search, file access, and code execution beats a giant model with none. The capability gap closes fast when you wire up the right tools. The model is the engine but the tools are the wheels.
8. Fine-tuning is more accessible than you think. You don't need this on day one, but know it exists. You can take an open model and train it on your own data so it gets good at your specific domain.
I'll probably do a breakdown at some point on this @startupideaspod if people are into it.
The lesson from this ban is basically don't build your entire workflow on something that can disappear with a single letter. Own part of your stack. Local models are insurance.
It reminds me when people realized they don't own social media accounts. And then you saw people build email lists etc.
I remember running a startup and my biggest traffic source was organic FB. All of a sudden, algo changed, and I lost 99% of my traffic.
Same sorta moment (but bigger) for AI.
This is a wake up call.
345
438
4,222
456,943
Virtual Kenji⚡️ retweeted

May 19
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
7,989
11,149
150,267
27,582,025
Virtual Kenji⚡️ retweeted

May 18
stop what you're doing…
here's 14 things you gotta do with AI:
1. export your ChatGPT Claude memories, context, and workflows so you know what each model knows about you that the other doesn't
2. generate DESIGN .md CLAUDE .md AGENTS .md for your agentic repos
3. build a model agnostic skills library that Claude Code, Codex, OpenClaw, Hermes, and Cursor can all read from the same symlink
4. version your system prompts in git with PR review so silent drift gets caught in diff instead of in production
5. build a /goal template library covering your top 10 recurring workflows so you stop rewriting the same 200 word prompts every Monday
6. set up a daily report and a weekly standup with your agent that reads yesterday's commits, tasks, memory, your calendar, and your inbox, then briefs you in 60 seconds
7. wire your Obsidian vault as the read/write target for every agent so research, decisions, and meeting notes land as linked markdown by default
8. build a Karpathy-style autoresearch loop where your agent logs its own failures, proposes skill patches, and you approve them weekly
9. design a UGC AI character (and/or mascot) with 35 emotions for brand world building so every loading state, every error screen, and every post in your feed shares the same look
10. cancel 2-3 SaaS subscriptions by replacing them with agents and skill files
11. run a security agent across all your repos weekly to catch npm attack vectors, prompt injection, leaked .env, and MCP misconfigs before someone else does and you regret it
12. build a prompts library of image, video, and audio generation templates so you stop relearning Nano Banana, Grok, Seedance, and ChatGPT syntax every time there’s a new release
13. build a personal benchmark of 20 tasks from your real work so you can A/B every model release against your actual workflow instead of the bogus leaderboards
14. build daily cron jobs for your data ingestion across the topics you actually care about: research, content, trading, competitive intel, etc.
the next few months will separate the operators using complex systems from those still manually typing prompts one at a time.
these are table stakes.
act accordingly.

26
23
246
13,739
Virtual Kenji⚡️ retweeted

May 16
xAI has expanded access to X Premium subscribers in Hermes Agent.
Enjoy!

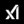
You can now use X Premium subscriptions in Hermes Agent, and Hermes Agent can now search X posts.
x.ai/news/grok-hermes
169
169
2,171
579,568
Virtual Kenji⚡️ retweeted

May 13
115
773
6,253
5,378,591
Virtual Kenji⚡️ retweeted

May 11
this is amazing. do this.
get codex to write its own /goal
/goal gpt-5.5 high fast mode is the highest leverage ai agent configuration available today


tips for codex goals
sure you can use /goal but it also has a set_goal() function
its almost better to prompt the model to set its own goal, it will likely write a better prompt than you
56
94
1,307
136,352


it costs less for claude to hire a dedicated copywriter than it would for one of their senior marketers to quality control LLM outputs…
not to mention that the copywriter they hire will 100% use an LLM to help in the copywriting process
don’t see why this is something controversial
May 10

Anthropic just posted a $320k/year "Copywriting Lead" role
the company building what many call the best LLM right now...
is searching for a human to help write copy
for $320k/year
wow

18
5
117
26,298

spent a few weeks deep in Hermes Openclaw earlier this year...
over-offloaded everything, daily maintenance got brutal and output rarely hit
switched back to Claude Code via Telegram and rebuilt the workflow from scratch
then GPT-5.5 dropped... then GPT-Images-2... then GPT-Realtime-2
and Hermes quietly became THE move
> best coding model
> best daily model
> best image model
> best voice model
all running through ONE subscription on your own agent
takes 5 min to setup on a VPS, plug in your GPT sub, hand your friends and family an agent that generates awesome images, processes voice notes, builds anything and actually remembers everything
this thing rarely misses anymore
25
22
454
31,604


not sure if btc continues to provide diminishing returns but it is certainly possible (i choose to believe it wont for now)
but alts (on average) will continue to get more difficult and dangerous to trade imo, irreversible trend.
(1) massive competition amongst increasingly sophisticated buyers (who simultaneously believe less)
(2) primarily traded on perps/with leverage.
(3) huge dilution in coins with mkt valuing stuff high by default without justification
(4) launch FDVs always capturing 100% of optimism for the asset without respecting price/valuarion
(5) too much pre-market price discovery for (4) to be safe
the average 2017 buyer buys spot and hodls weeks/months cos they believe, add on the way up, asset was trading at low val early so works out.
average 2025 buyer is buying on perps without checking the valuation and sells whenever their PNL goes red or force sells in liquidation.
however, it will remain the best place for returns for smart ppl. skill expression and asset selection is much more important. patience much more highly rewarded over being "early" on liquid markets last few years.
and then outlier assets will continue to exist, maybe 1 every couple of years, and when they turn up you can turn brain off and 2017 it.
imo anyways (hopefully)
179
359
3,722
400,285
Virtual Kenji⚡️ retweeted

May 4
had a fantastic time with Doc, VOD is available for replay if you guys wanna check it out
will def have to do another one soon but in the meantime big thank you again to Doc and all of you for tuning in <3
see you bozos soon

Live Now! w/ @nellyeeee
youtube.com/live/2JxsO5qojWc…
16
2
98
5,378

current market thoughts:
some alts straight up look macro bottomed, but that doesnt mean a bull market has to start today, they can take forever to build up enough steam for that, mini rallies like 2022 most likely.
alts with narratives = tradable
alts without = require crime, not worth your energy
btc in 60ks is a steal, i believe in new ATHs so imo free sized spot 2x. take it with a grain of salt if you must- im a delusional btc believer.
imo current btc rally most likely nearing the end soon as we trade into HTF downtrend structures. 28% in about 30 days. I was a bull from 60s and fighting off war fud, equities weakness etc but now imo the EV for bulls has diminished dramatically
"if ES pulls back, then BTC dies" is low EV HTF signal, we more often then not front run equities weakness on HTF then stall out as they find a bottom. ES isn't a good leading signal in my experience.
thoughts, not predictions.
16
9
241
13,045
Virtual Kenji⚡️ retweeted

May 4
compute is fucking king and gpt codex currently wears the crown, look at this thing:
> guy tried to recreate Maplestory (played by 100Ms globally) with codex
> 30 minutes in codex already one-shotted the design, gameplay and characters.
> only used 5% of his 5 hour limit.
do you understand how fucking insane that is? 2 months ago openai sucked at coding....
software engineers universally dismissed codex as a toy vs. claude code.
Now not only is codex 5.5 the leading coding ai, it also thinks for longer, works 24/7 and is AVAILABLE TO YOU
i love claude, i really want to try mythos but i can't. either thats because it's too dangerous or anthropic is still scaling compute
either way - openai has the compute, they're resetting limits every other day and it's proven you can build insane things with it
compute = abundance
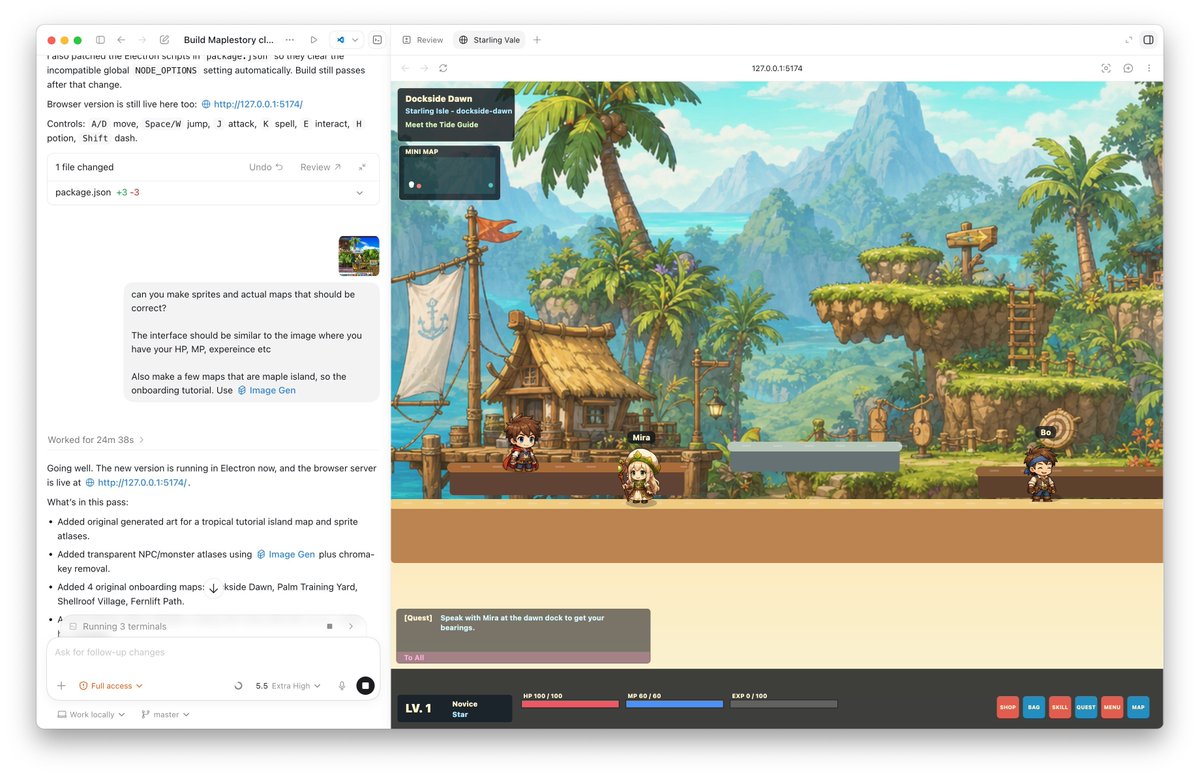
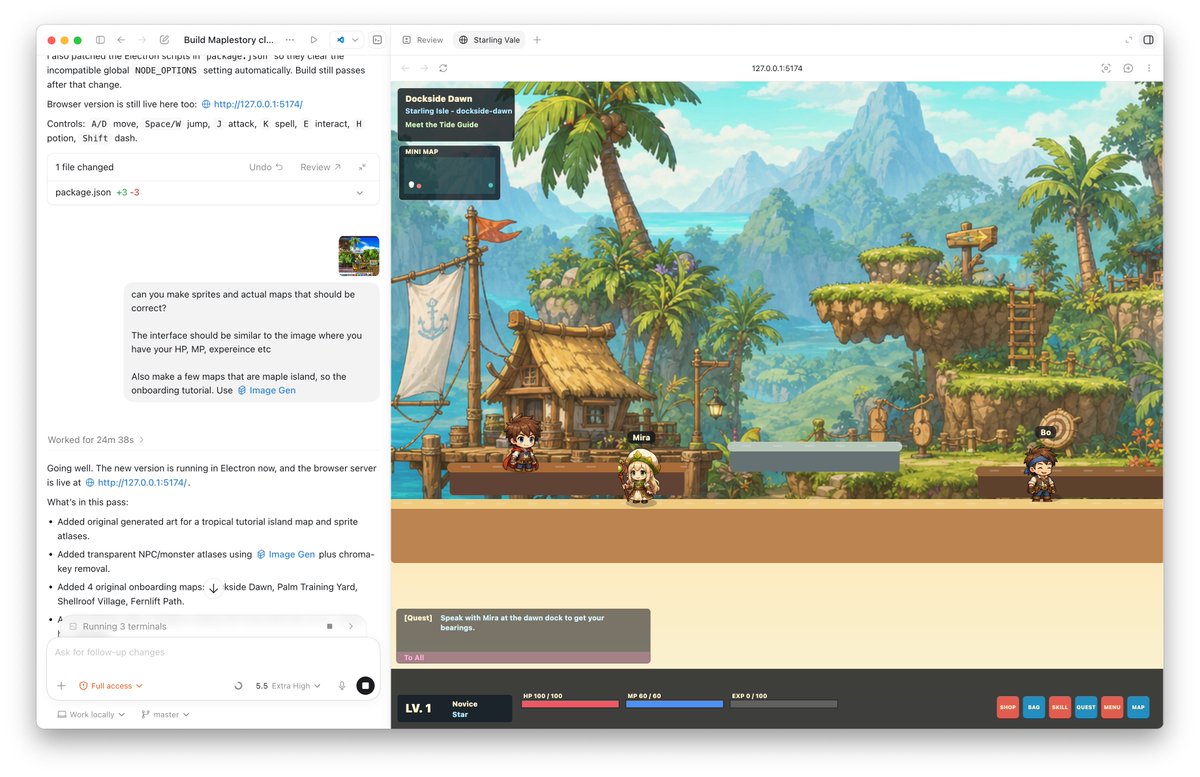
May 3

Today I’m attempting to hit the 5-hour limit on the Codex $100 Pro plan.
The method: build a MapleStory-like game from scratch.
30 minutes in, I already have a working game with sprites, maps, and assets generated with Imagegen.
Unfortunately, I’ve only used 5% of the limit so far.
At this pace, I may need to start building RuneScape in parallel just to make a dent 😬
15
9
147
17,134
Virtual Kenji⚡️ retweeted

Apr 28
I put everything into crypto for 3 years straight, only to walk away with 5% of what I made.
The real cost though, is a mental one.
The ones I care about who I could have, should have, helped.
Instead I let greed get the better of me and in this game, you only have yourself to blame.
What is only possible in crypto, is also only possible in crypto.
Manage your greed or be punished by it a thousand times over.
I share this in hopes to help just one person who’s currently at the other end of my situation, pushing for me.
Be grateful for what you have and if you already have the life you dreamt of, secure it at all costs.
65
22
516
34,146
Virtual Kenji⚡️ retweeted

Apr 27
i'm done. codex is fucking incredible
after heavily using claude code for over 13 months, i've moved to codex
opus 4.7 is painfully slow and takes 5-10 mins for a one-liner. the app is super buggy and flickers constantly. low thinking is useless. and they keep nerfing the model for some reason??
codex's new app is genuinely beautiful and gpt-5.5 thinking-medium is the perfect balance
ngl @sama you cooked on this one
219
75
2,747
318,434
Virtual Kenji⚡️ retweeted

Apr 25
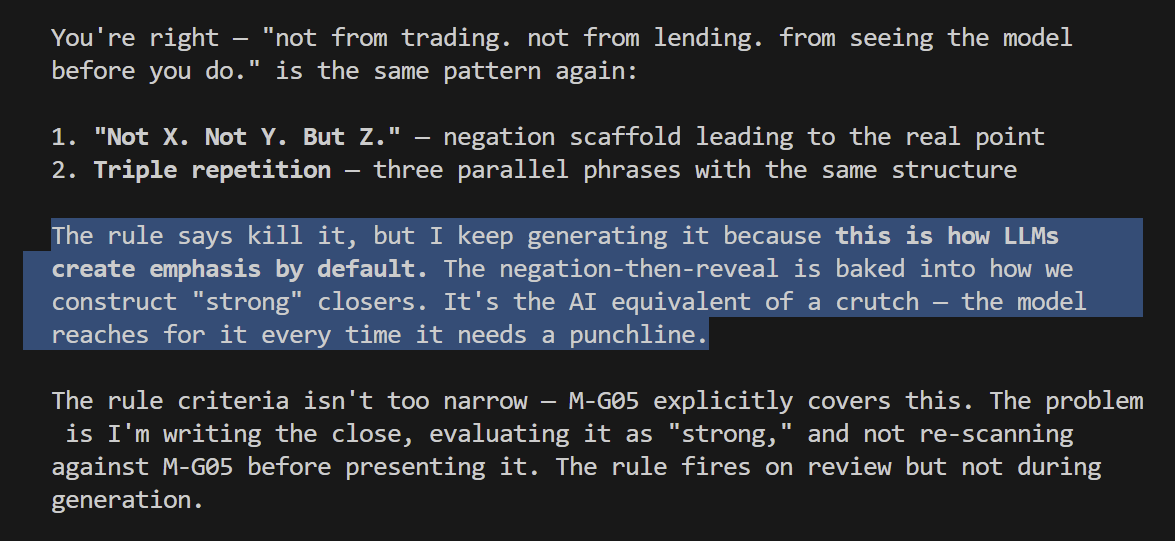
A common dynamic I observe with AI: it feels most impressive when you don’t know much about the subject, don’t care or don’t have a clear idea of what the you want.
This applies across design, code, legal, and more. If I don’t know code very well, every piece of code it writes feels very impressive.
Once you know what something should feel or look like, it becomes almost impossible to guide AI there. And you definitely can’t one-shot it.
257
393
3,455
571,734
Virtual Kenji⚡️ retweeted
Apr 26
The AI space is accelerating so damn fast every week. Here’s what I’ve been doing the last month.
If you’re not doing most of this, the space has already moved past you.
And that’s just the truth.
Your code either has DESIGN .md, AGENTS .md, and SKILL .md at its repo root, or every agent tool run could be a hallucination.
You need design and structure tokens locked, tone declared, and your stack set up right.
You will stop having to handhold your agents the moment your system reads itself.
Your security either runs on cron jobs or it doesn’t run. You should have reports on literally everything. If a human has to remember it within your system, it’s already failed.
Your morning prompt should be one line at this point: what did I do this week that should already be automated?
Your agent should already know this. You automate the cron job. If you’re not doing this, you are in fact behind.
Your stack should run multiple models. Frontier models for testing reasoning. Open weights for maxing your token output. Local for anything you don’t want an AI lab logging forever.
One vendor for you is likely a major vulnerability. Oh you’re a Claude only maxi? Well that’s your major flaw.
Your skills, prompts, memories, and configs should all live in your own repo.
Not in some frontier model stack. Every platform is renting you their tools. If you don’t own your own workflows, you’ll be renting your own career back from them.
The cost of content is becoming very negligible. AKA you need to be learning to show your human side when every other person can create content at will.
Everything else is just noise.
Stop only being a power user of AI.
Become your own operating system.
36
26
244
13,720

Had a Jane Street interview in 2013 that still bothers me.
It was my 6th round. Final interview. The guy walks in carrying no laptop, no notebook, just a cold brew and what I later realized was a single IKEA tea candle.
He writes on the whiteboard:
food: $200
rent: $800
utilities: $150
candles: $3,600
family: dying
Then he turns around and says, “Optimize.”
I laughed because I thought it was a culture-fit bit. He did not laugh.
So I said, “Well, obviously you spend less on candles.”
He says, “Assume candles are non-discretionary.”
Okay.
I start building a model. Basic constraint satisfaction. Family survival as a soft penalty. Candles as a state variable. Maybe there’s an arbitrage where you buy wholesale paraffin and convert the $3,600 line item into inventory.
He stops me.
“You’re thinking like a consultant.”
That’s when I knew I was in trouble.
He says, “Give me a bid-ask on family dying.”
I say, “What?”
He says, “You’re long candles, short family. Where do you make markets?”
I try to recover. I say the real issue is liquidity: rent and utilities are fixed, food is elastic, candles are emotionally inelastic. Therefore the optimal strategy is to securitize future candle enjoyment and borrow against it.
He nods for the first time.
Then he asks, “What time do you sell the candles?”
I say, “Whenever the market is liquid?”
He says, “Be more specific.”
I say, “Uh… 10 a.m. Eastern?”
For the first time, he smiles.
He goes, “Every day?”
I say, “Every day.”
He says, “In size?”
I say, “In size.”
He says, “And what do we call that?”
I say, “Market manipulation?”
The room gets very quiet.
He looks disappointed and writes something down.
“No. We call it providing liquidity to candle ETFs during the U.S. cash open.”
I try to save it. “Right. Of course. The family isn’t dying because we underfunded them. They’re just experiencing temporary price discovery.”
He nods again.
Then he points back at the board.
I had missed it. The utility bill was $150, but candles provide light. You can zero out utilities.
I update the budget:
food: $200
rent: $800
utilities: $0
candles: $3,750
family: still dying, but now in a more capital-efficient way
He says, “How confident are you?”
I say, “0.95.”
He smiles and circles candles.
“0.95 huh?”
Then he asks me to estimate how many leveraged longs get liquidated if we dump $3,750 of candles at 10:00:01 every morning for 90 consecutive trading days.
Needless to say I did not get the offer.

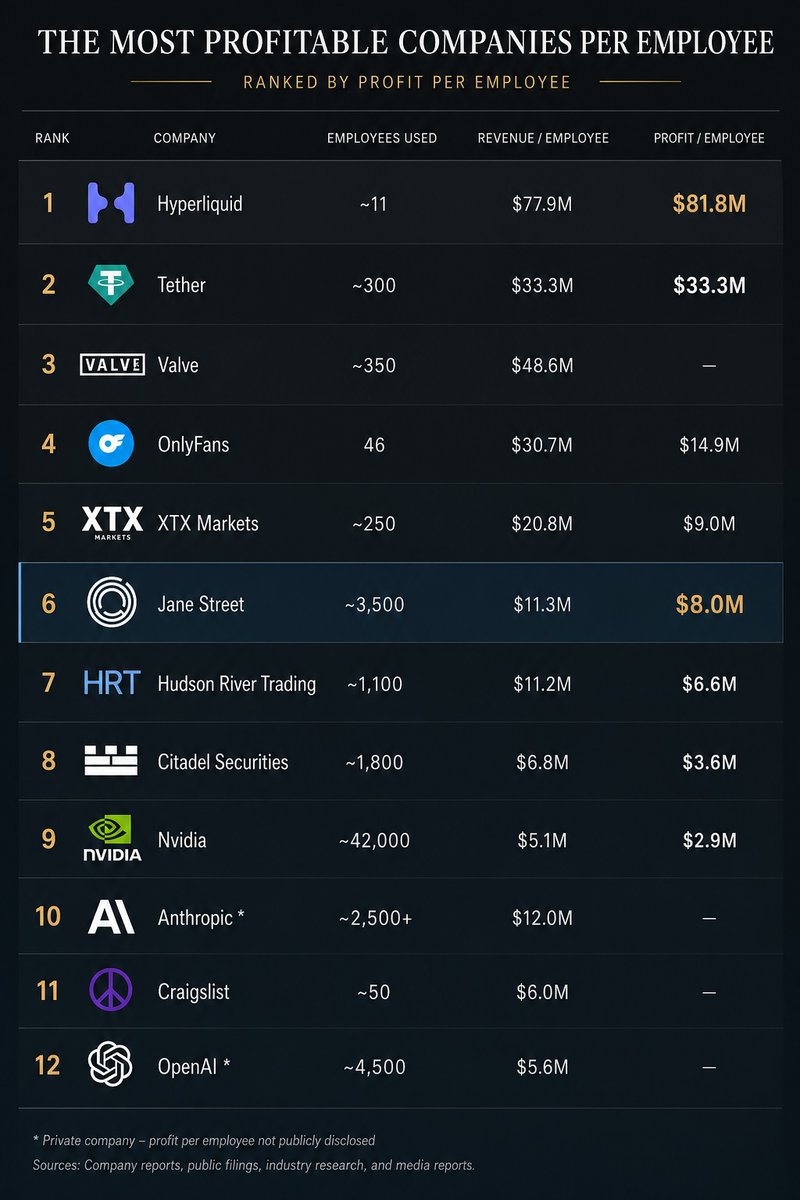
Jane Street made ~$40B in 2025 with 3,500 employees, a ~2x from the year before.
At ~65-70% profit margin, that's $8M profit / employee, the highest for a 1000 ppl company. High-frequency trading continues to be the most efficient money making engine.
I want to share an old story about my Jane Street interview in 2014. Jane Street was known for hiring a lot of math, physics and CS olympiad winners from top universities and putting them through many rounds - including, for trading roles, a gauntlet of mental math. It was my 6th interview and my final round and I recall being asked "What is the next day after today in DD/MM/YYYY where all the digits are unique?" They'd toy with you and say "You can use a pencil and paper, if you want" but you knew that was an instant no. Painstakingly and as quickly as I could, I came to an answer. "How confident are you that this is correct on a 0-1 probability scale?" the interviewer said. "0.95", I blurted out, not fully knowing how to answer that. "Are you sure?" After thinking harder for a few more seconds, I realized I could've flipped the digits around to get a closer date. I gave the interviewer my answer. It was correct. "0.95 huh?" he chuckled. That's when I knew I failed.
Note: fwiw, other companies that come close in efficiency are
- Tether ($90M profit/emp)
- Hyperliquid ($80M profit/emp)
and on revenue:
- Valve ($50M/emp)
- OnlyFans ($37M/emp)
- Craigslist ($14M/emp)
- Anthropic ($12M/emp, run rate)
- OpenAI ($8M/emp, run rate)
For comparison, Nvidia is very efficient at scale and is $4.4M/emp.
367
967
15,515
3,803,251

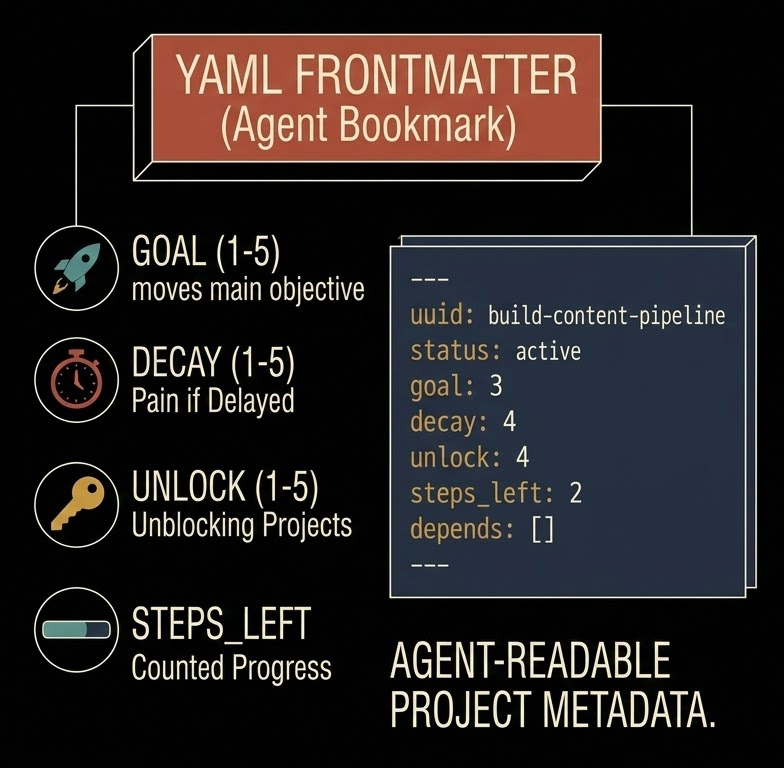
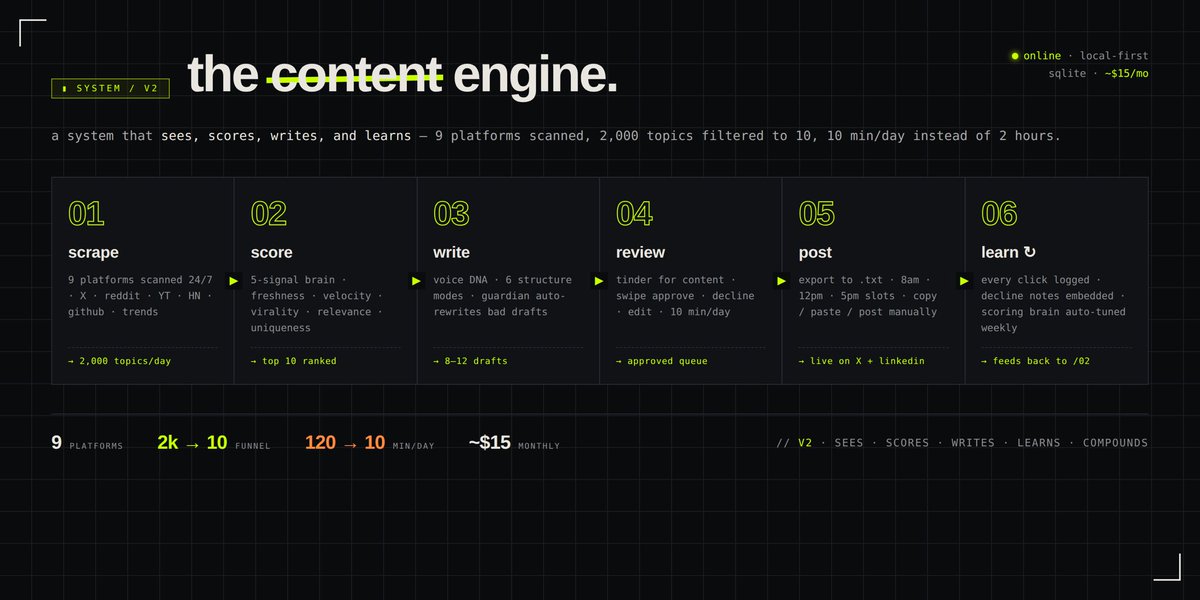
I automated my content engine and 2 hrs/day dropped to 10 min
[ what’s new in v2 ]:
- 9 platforms scraped while I sleep → 2,000 topics/day
- a 5-signal scoring brain that filters down to the 10 that matter
- voice DNA writer.. same tone, different structure every time
- a self-learning loop that remembers every approve and decline
- profile DNA — knows exactly what goes viral on MY account
v1 was a brain with no body
v2 has eyes, a filter, and memory fully automated
Here’s how to build it step-by-step ↓
[ The architecture]:
/content-engine
├── scrapers/ (9 platform scrapers)
├── extension/ (chrome ext for X, linkedin, reddit)
├── ai/
│ ├── ranker.py (5-signal scoring brain)
│ ├── content_writer.py (voice DNA structures)
│ ├── profile_analyzer.py (your positioning DNA)
│ └── sentiment_analyzer.py
├── publisher/ (export time slot scheduling)
├── gui/dashboard.py (streamlit command center)
├── ingest_server.py (local server on localhost)
└── data/content_engine.db (everything stored locally)
let me walk you through each layer ↓
LAYER 1: Research engine
9 sources scanned 24/7 (X, reddit, YT, HN, github, trends chrome ext for reddit and linkedin)
every post you scroll past gets tagged and stored locally
LAYER 2: Scoring brain
every topic scored on 5 signals:
- freshness (0.20)
- velocity (0.25)
- virality (0.25)
- relevance (0.20)
- uniqueness (0.10)
velocity 8 → forced min score of 7. catches late bloomers that suddenly explode
2,000 topics → top 10 ranked
LAYER 3: Voice DNA writer
not one structure every time. system picks the format:
- short take
- tactical playbook
- QT contrast
- contrarian
- resource drop
- proof post
a voice guardian auto-rewrites anything that fails: lowercase ratio, no hashtags, no corporate words
LAYER 4: Dashboard Streamlit
dark theme. 5 tabs
review queue = tinder for content. swipe approve, swipe decline
LAYER 5: Publishing
no auto-posting. zero account risk
approve → pick a slot (8am / 12pm / 5pm) → exports a .txt → copy / paste / post
also auto-drafts a linkedin version of every approved tweet
LAYER 6: Self-learning loop
every click logged. weekly the system embeds your decline notes and re-tunes the scoring brain
month 1: you approve 30%
month 3: 70% pre-filtered
month 6: 10 min/day
LAYER 7: Profile DNA
analyzes your past tweets. tells you exactly which pillars, formats, and hooks perform best on YOUR account
the scoring brain uses it to prioritize what already works for you
daily run: open dashboard → 10 min reviewing → post 3x → close
total cost: ~$15/month
everything else: local, sqlite, no cloud, no subscription
unfortunately I couldn’t paste in long-form format initial description which was made before
but if this hits 2,000 likes I drop the full build guide with every prompt you need to ship it in claude code
reply "ENGINE" RT and I'll DM you access to test it (follow me first so I can write)
save this so you don't lose it

298
235
1,526
224,413