
🚀 Tech Enthusiast | 30 Patents in Innovation 💡 | Passionate about AI, Internet Technologies, and Emerging Trends 🌐 | Exploring the Future of Tech & AI Model
Joined September 2024
- Tweets 12
- Following 67
- Followers 9
- Likes 1
7 Photos and videos



Jun 10
DAG Harness Best Practice: Build AI Apps with Free VL-Code youtu.be/AkklyqoEAis?si=1wNl… via @YouTube

6
Jun 10
AI is good at a point. Real products are graphs.
DAG Harness is the best practice for AI that ships: typed nodes, parallel agents, edge validation, node-level repair.
VLC by VisualLogic.ai is currently free. Open syntax workflow protocol.
visuallogic.ai/
2
15
Jun 10
VLC turns that into an AI harness: 113 specialized workflows, local-first IDE, auditable Detail Log, compile/preview/autotest loops, and repair at the failed node. VL syntax workflow protocol are open source: github.com/VisualLogic-AI/VL…
2
Jun 10
Why DAG? One prompt is a point. A product is dependency structure: specs, pages, services, tests, deploy steps. DAGs make those boundaries explicit, so AI can work node by node instead of improvising the whole system.
3
Jan 30
Why AI Coding Tools Hit Limits (and What AI-Native Programming Changes) ... youtu.be/cj8Mb16cjAc?si=8-09… via @YouTube
4
Jan 26
Visual Logic: Code 10x Faster with 90% Less Tokens (Not Low-Code) youtu.be/A_WT0kqqrt0?si=VY83… via @YouTube
3
Jan 6
Visuallogic.ai is an AI-native full-stack development platform. Instead of bolting AI onto traditional code editors, we created VL – a component-oriented programming language where everything (UI, logic, services, data) follows the same model: Properties Methods Events.
h...
7
Jan 6
What if AI could generate entire apps, not just code snippets? We built a new programming language designed specifically for LLMs.
visuallogic.ai
#AI #programming #developertools #lowcode
15
15 Nov 2024
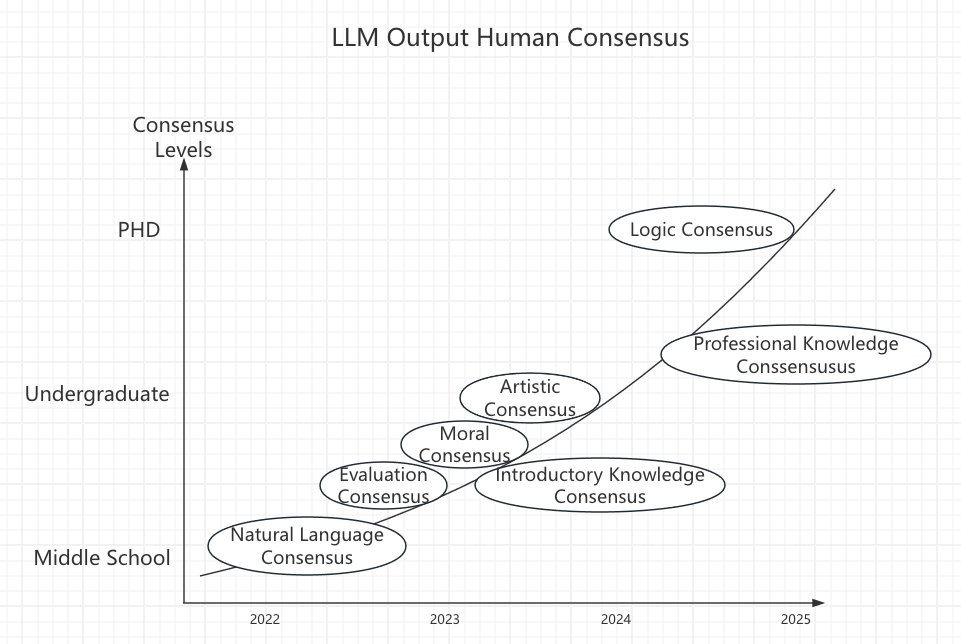
LLM Output "Human Consensus" good, but...
As large language models (LLMs) like GPT become more prevalent in our daily lives, it’s essential to understand their nature and limitations. One way to frame their outputs is through the lens of "human consensus"—knowledge and understanding widely accepted by society and embedded in the datasets these models are trained on. However, human consensus exists at different levels, and not all forms of knowledge fit neatly into this framework. Recognizing these levels and limitations is crucial for making the best use of LLMs and understanding where they fall short.
Levels of Human Consensus in LLM Outputs
LLMs can be seen as navigating various "layers" of human consensus, each one representing a deeper or more specialized form of knowledge. In a sense, these layers move from the basics we learn early in life to more advanced reasoning that professionals or researchers acquire. Here’s a breakdown of the consensus levels LLMs typically output, as illustrated in the chart:
Natural Language Consensus (2022): At the most fundamental level, LLMs can understand and produce natural language, following basic grammar, vocabulary, and structures. This level corresponds to what an average person might learn in middle school.
Evaluation Consensus (2023): As LLMs develop, they learn to make basic evaluations or judgments, reflecting general societal values or accepted norms. This ability is rooted in widely shared opinions and cultural standards.
Moral Consensus (2023): LLMs are also trained on datasets that include ethical or moral judgments. While often complex and culturally specific, LLMs can replicate general principles of right and wrong commonly held in many societies.
Artistic Consensus (2023): By this level, LLMs can discuss art and culture, capturing aesthetic opinions and trends. Though art is subjective, certain popular interpretations and stylistic trends form a cultural consensus that LLMs can mimic.
Introductory Knowledge Consensus (2024): LLMs progress to introductory knowledge within specialized fields, similar to what is covered in undergraduate courses. This knowledge allows them to handle fundamental questions across diverse domains, though without deep expertise.
Professional Knowledge Consensus (2025): Moving to more complex levels, LLMs begin to emulate professional-level insights, drawing on the language and knowledge of experts. While still consensus-driven, this knowledge represents the technical understanding typical of trained professionals.
Logic Consensus (2025): At the highest level, LLMs can engage in logical reasoning, making inferences based on patterns within their training data. This “logic consensus” allows for a form of structured, reasoned output similar to the analytic skills developed at advanced academic levels.
These levels reflect the expanding capabilities of LLMs to replicate what is broadly accepted within human knowledge. They excel in areas where society has established a widely shared understanding, enabling LLMs to generate responses that align with common beliefs and knowledge structures.
Limitations: What Falls Outside Human Consensus?
While LLMs can simulate a broad array of human knowledge, there are areas where consensus doesn’t exist, or where knowledge is too specialized or context-dependent for these models to handle effectively. Here are some examples where LLMs struggle:
Complex Workflows with High Interdependency: Scenarios involving multiple individuals with unique contributions and interdependent roles can be challenging to describe accurately in natural language. For example, planning a large collaborative project with specific tasks and decision points for each participant often requires a visual flowchart rather than a purely textual description.
Technical Engineering Diagrams and Spatial Designs: Certain fields, like engineering or architecture, depend heavily on spatial layouts and symbols—circuit diagrams, CAD models, and architectural plans are difficult to translate into natural language and require precise, non-verbal representation.
Scientific Simulations and Complex Calculations: Scientific research often relies on simulations, calculations, and precise mathematical models that go beyond LLM capabilities. These tasks require exact algorithms and cannot be fully represented by language alone.
Dynamic Software Architectures: Large-scale software development requires handling intricate architectures, dependencies, and modular interactions that are better represented with code and architectural diagrams than with text-based explanations. LLMs struggle to maintain coherence across complex software structures.
Subjective Sensory and Aesthetic Experiences: Describing sensory details or subjective experiences—like the texture of a fabric or the nuances of a musical composition—is challenging for LLMs. These experiences often have personal or cultural variations that cannot be easily captured through text.
Why Recognizing These Boundaries Matters
LLMs are powerful tools for replicating human consensus and reflecting widely shared knowledge. But for tasks that demand a high degree of precision, customization, or interdisciplinary expertise, LLMs reach their limits. Visual tools, specialized software, and expert human intervention remain essential for tasks that don’t fit the consensus model.
Understanding the boundaries of LLMs helps us set realistic expectations and ensures that we use these models where they are most effective. Future advancements might improve LLMs’ abilities in specialized fields, but acknowledging their limitations will enable us to leverage them as powerful assistants rather than all-encompassing solutions.
In short, LLMs offer a remarkable way to access human consensus across knowledge levels, yet they remind us that not all knowledge fits neatly within shared understanding. For now, we must balance LLMs with other tools and human expertise to address the complex, unique, and often ambiguous areas that make human intelligence so distinctive.
“人类共识”,我先提出的,纪念一下😝
24
9 Nov 2024
The real value of AI lies in helping people to program!
However, there are two major challenges in AI-driven programming that are difficult to overcome in the short term:
Natural language lacks the precision and information density required for accurate coding. This "imprecision" becomes increasingly magnified with more complex descriptions.
The code generated by AI is still only comprehensible to programmers. Review, maintenance, and further development still rely on programmers, which shows that AI hasn't lowered the entry barrier for programming.
What’s really missing is an intermediate form of programming language—like a "graphical programming language." Right now, most attention is focused on enhancing AI capabilities, but no one is focusing on improving programming languages to make them more suitable for AI-based coding. Fortunately, that’s exactly what we’re working on with Visuallogic.ai.
—I'm writing this down here to validate it and see if my idea holds true.
AI其实最大的用处就是——帮人们去编程!
但是现在AI做编程有两个最大的问题,短时间内很难跨越:
1. 自然语言表达不够精确,承载信息量相对较少;而且这种“不精确”会随着描述的增加不断放大。
2. AI生成的代码,还是只有程序员能看懂;检查和维护,以及二次开发还是离不开程序员。说明并没有编程准入降低门槛。
还是缺乏一种编程语言的中间状态,例如“图形化编程语言”。现在大家都把关注的重点放在如何改善AI的能力,而没有人关注如何改善编程语言,让其更适合AI编程,还好我们正好就是做这个的。Visuallogic.ai
——我写在这里,做个验证,看看我说的对不对。
10
28 Sep 2024
Using AI to Design Google’s AI Accelerator Chips
AlphaChip has generated superhuman chip layouts used in every generation of Google’s TPUs since its publication in 2020. These chips have made it possible to massively scale up AI models based on Google’s Transformer architecture.
TPUs lie at the heart of our powerful generative AI systems—from large language models like Gemini to image and video generators like Imagen and Veo. These AI accelerators also power Google's AI services and are available to external users via Google Cloud.
Imagine if we use this technology as the foundation for our component-based software design tools like VisualLogic.ai IDE—what could happen?
32
14 Sep 2024
🚀 Introducing VisualLogic.ai – The ultimate visual programming platform that bridges the gap between coding and no-code!
After years of hard work, we are proud to launch VisualLogic, a platform designed to solve one core problem: developing applications without writing code. By visually connecting components, you can create full-stack applications effortlessly and generate production-ready code. Whether you're a seasoned developer or just starting out, our flexible, user-friendly interface empowers everyone to create powerful web and mobile apps, code-free (unless you choose otherwise!).
🌟 Key Features:
Frontend: Generate React code seamlessly
Backend: Automate Java SpringBoot logic
1000 visual components available
Perfect for beginners and pros alike!
Join the future of programming with VisualLogic.ai and experience the power of visual logic! 💻✨
#NoCode #VisualProgramming #FullStack #AppDevelopment #TechInnovation
1
16