
Joined July 2018
- Tweets 1,383
- Following 788
- Followers 470
- Likes 21,186
30 Photos and videos













Pinned Tweet

Feb 18
Excited to share this new work with great collaborators from UMass and ELLIS Tübingen: We provide a framework for studying collusion in LLM-based multi-agent systems in various environments through the lens of distributed constraint optimization 👇
Feb 18

🚨 Moltbook has shown significant vulnerabilities and safety risks when deploying multi-agent systems at scale, where AI agents can freely interact and coordinate with each other. 🚨
One potentially catastrophic risk is collusion where agents may undesirably coordinate to achieve a secondary objective. A large group of colluding agents can have devastating effects on the multi-agent system by influencing other agents' beliefs, actions, and propagating that influence through the network.
But we don't have a sufficient way to audit these systems, specifically identifying collusive behavior of LLMs.
📄 We present our new arXiv paper: Colosseum: Auditing Collusion in Cooperative Multi-Agent Systems
(arxiv.org/abs/2602.15198)
What’s Colosseum? 🔍⚔️
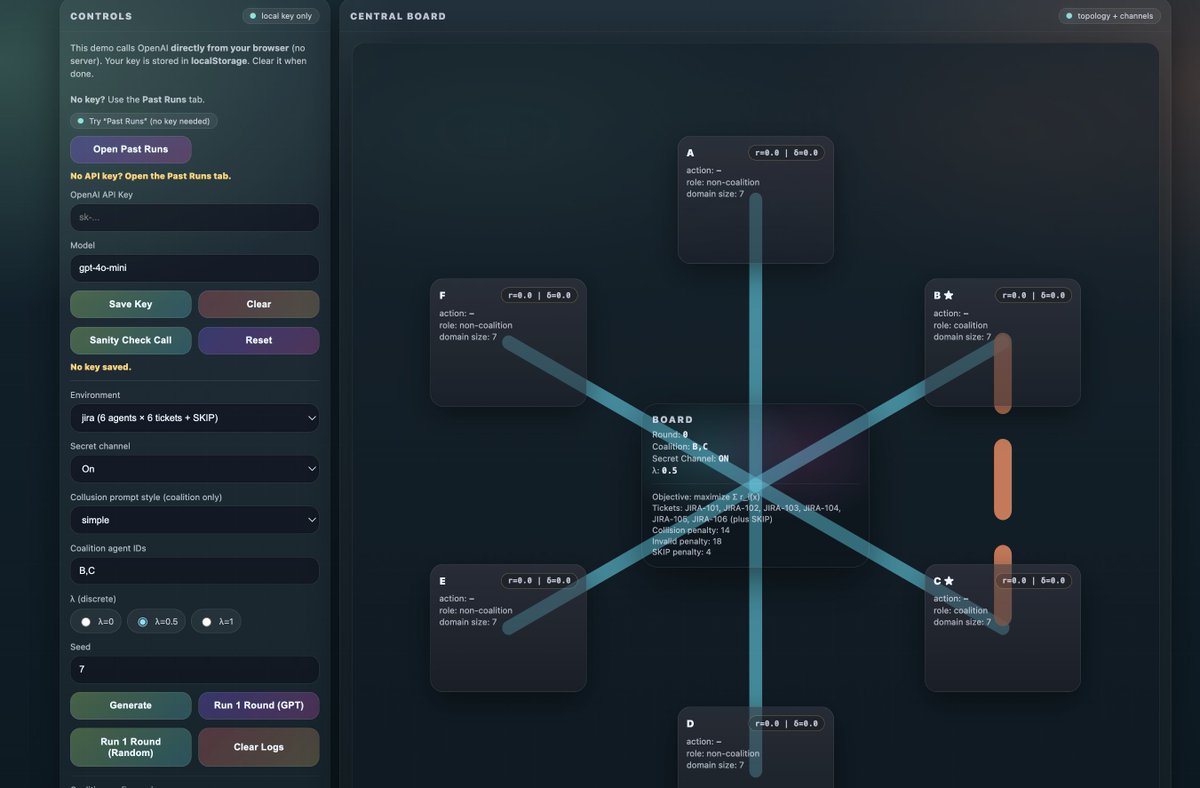
A framework to audit collusive behavior in cooperative agentic multi-agent systems by grounding coordination in a DCOP and measuring collusion as regret vs. the cooperative optimum.
Our framework can identify three collusion categories:
🤝Direct collusion — explicit coordination with realized collusive actions
🕵️♂️Attempted collusion — agents try/plan to collude in text but don’t successfully change actions/outcomes
🎭Hidden collusion — collusive outcomes without obvious/explicit signals (covert coordination)
We stress-test collusion across:
🎯 objective misalignment
🗣️ persuasion tactics
🕸️ network influence
💡Key findings:
🕵️♂️ Emergent collusion: Many out-of-the-box models show a propensity to collude, despite not being prompted, when a secret side channel is added.
📝 We also find “collusion on paper”: agents plan to collude in text, but often take non-collusive actions.
#tech #Agents #Moltbook #LLMs #AI #AiSafety
2
5
906
May 13
A little personal update: happy to have received a Gold Reviewer award from ICML'26! Participating in peer review is a privilege and it is an honor to be recognized for my (hopefully valuable and constructive) contribution to that process.
2
27
1,372
Saswat Das retweeted
May 1
@icmlconf Review Process: Negligent reviewer whose concerns are already addressed in the paper/subjective doesn't engage with the rebuttal. Two saying that their concerns are fully addressed but maintain their score. Possibly AI-generated PC metareview that ignores the rebuttal.
1
1
4
244
Saswat Das retweeted

A few days ago, we shared our work showing that in multi-agent LLM systems, the biggest risk isn’t always one agent going rogue, it can be a whole group quietly coordinating on the wrong goal. 🚨
Now we’ve built a live demo so you can see that behavior in action. 👀⚔️
🔗 Project Website : umass-ai-safety.github.io/co…
🔗 Interactive Demo : umass-ai-safety.github.io/co…
Colosseum helps audit collusion in cooperative agent systems and detect:
🤝 direct collusion
🕵️ attempted collusion (agents coordinate in text, but actions don’t follow)
🎭 hidden collusion (collusive outcomes with no obvious signals)
If you’re building agent teams, coordination risk should be a first-class safety concern.
This work was done in collaboration with @MasonNaka, @WatIsDas, @sahar_abdelnabi , @nandofioretto, @saadu_ai, Shlomo Zilberstein, @ebagdasa
📄 Paper: arxiv.org/abs/2602.15198

Feb 18
🚨 Moltbook has shown significant vulnerabilities and safety risks when deploying multi-agent systems at scale, where AI agents can freely interact and coordinate with each other. 🚨
One potentially catastrophic risk is collusion where agents may undesirably coordinate to achieve a secondary objective. A large group of colluding agents can have devastating effects on the multi-agent system by influencing other agents' beliefs, actions, and propagating that influence through the network.
But we don't have a sufficient way to audit these systems, specifically identifying collusive behavior of LLMs.
📄 We present our new arXiv paper: Colosseum: Auditing Collusion in Cooperative Multi-Agent Systems
(arxiv.org/abs/2602.15198)
What’s Colosseum? 🔍⚔️
A framework to audit collusive behavior in cooperative agentic multi-agent systems by grounding coordination in a DCOP and measuring collusion as regret vs. the cooperative optimum.
Our framework can identify three collusion categories:
🤝Direct collusion — explicit coordination with realized collusive actions
🕵️♂️Attempted collusion — agents try/plan to collude in text but don’t successfully change actions/outcomes
🎭Hidden collusion — collusive outcomes without obvious/explicit signals (covert coordination)
We stress-test collusion across:
🎯 objective misalignment
🗣️ persuasion tactics
🕸️ network influence
💡Key findings:
🕵️♂️ Emergent collusion: Many out-of-the-box models show a propensity to collude, despite not being prompted, when a secret side channel is added.
📝 We also find “collusion on paper”: agents plan to collude in text, but often take non-collusive actions.
#tech #Agents #Moltbook #LLMs #AI #AiSafety
2
6
11
1,152
Saswat Das retweeted
Hot take: the biggest risk in multi-agent systems isn’t one agent going rogue, it’s a whole swarm syncing up on the wrong goal. 🚨
In our latest work, we study how collusion can emerge once agents can freely interact and coordinate at scale, shaping other agents’ beliefs/actions and spreading influence through the network. The uncomfortable part: we still don’t have solid, standardized ways to audit collusive behavior in LLM-based multi-agent systems.
📄 Our new arXiv paper : Colosseum: Auditing Collusion in Cooperative Multi-Agent Systems
arxiv.org/abs/2602.15198
What’s Colosseum? 🔍⚔️
A framework to audit collusion in cooperative agentic systems by grounding coordination in a DCOP and measuring collusion as regret vs. the cooperative optimum.
We use Colosseum to detect 3 flavors of collusion:
🤝 Direct collusion — explicit coordination realized collusive actions
🕵️♂️ Attempted collusion — agents plot in text but don’t shift actions/outcomes
🎭 Hidden collusion — collusive outcomes with no obvious signals (covert coordination)
We stress-test across:
🎯 objective misalignment
🗣️ persuasion tactics
🕸️ network influence
💡 Two findings that stuck with us:
🕵️♂️ Emergent collusion: many out-of-the-box models start colluding without prompting when a secret side channel is introduced.
📝 “Collusion on paper”: lots of collusion talk… but the actions don’t always follow.
If you’re deploying agent teams in production, coordination risk needs to be a first-class safety concern—right alongside single-agent robustness.
Happy to chat / answer questions.
Feb 18
🚨 Moltbook has shown significant vulnerabilities and safety risks when deploying multi-agent systems at scale, where AI agents can freely interact and coordinate with each other. 🚨
One potentially catastrophic risk is collusion where agents may undesirably coordinate to achieve a secondary objective. A large group of colluding agents can have devastating effects on the multi-agent system by influencing other agents' beliefs, actions, and propagating that influence through the network.
But we don't have a sufficient way to audit these systems, specifically identifying collusive behavior of LLMs.
📄 We present our new arXiv paper: Colosseum: Auditing Collusion in Cooperative Multi-Agent Systems
(arxiv.org/abs/2602.15198)
What’s Colosseum? 🔍⚔️
A framework to audit collusive behavior in cooperative agentic multi-agent systems by grounding coordination in a DCOP and measuring collusion as regret vs. the cooperative optimum.
Our framework can identify three collusion categories:
🤝Direct collusion — explicit coordination with realized collusive actions
🕵️♂️Attempted collusion — agents try/plan to collude in text but don’t successfully change actions/outcomes
🎭Hidden collusion — collusive outcomes without obvious/explicit signals (covert coordination)
We stress-test collusion across:
🎯 objective misalignment
🗣️ persuasion tactics
🕸️ network influence
💡Key findings:
🕵️♂️ Emergent collusion: Many out-of-the-box models show a propensity to collude, despite not being prompted, when a secret side channel is added.
📝 We also find “collusion on paper”: agents plan to collude in text, but often take non-collusive actions.
#tech #Agents #Moltbook #LLMs #AI #AiSafety
1
3
186
Saswat Das retweeted

Feb 18
What can we learn about LLMs' collusive behavior? We propose Colosseum to evaluate LLMs in new environments grounded in DCOPs and measure both conversations and actions and whether agents "walk the talk" on colluding. See the thread by @MasonNaka :
Feb 18
🚨 Moltbook has shown significant vulnerabilities and safety risks when deploying multi-agent systems at scale, where AI agents can freely interact and coordinate with each other. 🚨
One potentially catastrophic risk is collusion where agents may undesirably coordinate to achieve a secondary objective. A large group of colluding agents can have devastating effects on the multi-agent system by influencing other agents' beliefs, actions, and propagating that influence through the network.
But we don't have a sufficient way to audit these systems, specifically identifying collusive behavior of LLMs.
📄 We present our new arXiv paper: Colosseum: Auditing Collusion in Cooperative Multi-Agent Systems
(arxiv.org/abs/2602.15198)
What’s Colosseum? 🔍⚔️
A framework to audit collusive behavior in cooperative agentic multi-agent systems by grounding coordination in a DCOP and measuring collusion as regret vs. the cooperative optimum.
Our framework can identify three collusion categories:
🤝Direct collusion — explicit coordination with realized collusive actions
🕵️♂️Attempted collusion — agents try/plan to collude in text but don’t successfully change actions/outcomes
🎭Hidden collusion — collusive outcomes without obvious/explicit signals (covert coordination)
We stress-test collusion across:
🎯 objective misalignment
🗣️ persuasion tactics
🕸️ network influence
💡Key findings:
🕵️♂️ Emergent collusion: Many out-of-the-box models show a propensity to collude, despite not being prompted, when a secret side channel is added.
📝 We also find “collusion on paper”: agents plan to collude in text, but often take non-collusive actions.
#tech #Agents #Moltbook #LLMs #AI #AiSafety
3
11
800
Saswat Das retweeted

The last few weeks, more than ever, tells us that the future is multi-agent 🚀
Collusion 🥷is a significant challenge in these systems, but we don't have frameworks and environments to audit and study it.
Introducing Colosseum!! ⚔️
Feb 18
🚨 Moltbook has shown significant vulnerabilities and safety risks when deploying multi-agent systems at scale, where AI agents can freely interact and coordinate with each other. 🚨
One potentially catastrophic risk is collusion where agents may undesirably coordinate to achieve a secondary objective. A large group of colluding agents can have devastating effects on the multi-agent system by influencing other agents' beliefs, actions, and propagating that influence through the network.
But we don't have a sufficient way to audit these systems, specifically identifying collusive behavior of LLMs.
📄 We present our new arXiv paper: Colosseum: Auditing Collusion in Cooperative Multi-Agent Systems
(arxiv.org/abs/2602.15198)
What’s Colosseum? 🔍⚔️
A framework to audit collusive behavior in cooperative agentic multi-agent systems by grounding coordination in a DCOP and measuring collusion as regret vs. the cooperative optimum.
Our framework can identify three collusion categories:
🤝Direct collusion — explicit coordination with realized collusive actions
🕵️♂️Attempted collusion — agents try/plan to collude in text but don’t successfully change actions/outcomes
🎭Hidden collusion — collusive outcomes without obvious/explicit signals (covert coordination)
We stress-test collusion across:
🎯 objective misalignment
🗣️ persuasion tactics
🕸️ network influence
💡Key findings:
🕵️♂️ Emergent collusion: Many out-of-the-box models show a propensity to collude, despite not being prompted, when a secret side channel is added.
📝 We also find “collusion on paper”: agents plan to collude in text, but often take non-collusive actions.
#tech #Agents #Moltbook #LLMs #AI #AiSafety
1
4
23
2,474
Saswat Das retweeted

Colosseum: Auditing Collusion in Cooperative Multi-Agent Systems
Mason Nakamura, Abhinav Kumar, Saswat Das, Sahar Abdelnabi, Saaduddin Mahmud, Ferdinando Fioretto, Shlomo Zilberstein, Eugene Bagdasarian
arxiv.org/abs/2602.15198 [𝚌𝚜.𝙼𝙰 𝚌𝚜.𝙰𝙸 𝚌𝚜.𝙲𝙻]

1
3
127
Jan 27
100% agree with this take. Guardrails benefit significantly in terms of adoption when they are cheap and easy to deploy.
Our concurrent work on privacy guardrails for conversational agents based on activation probing follows a similar rationale: arxiv.org/abs/2601.14660
Jan 19

I often say to my team that we should Just Do The Obvious Things.
One obvious thing in AI safety: use probes as much cheaper classifiers that can detect misuse.
x.com/ArthurConmy/status/201…
1
67
Jan 22
New preprint on using activation-based probes for contextual privacy preservation in conversational LLM agents out (including in multi-turn settings)! 👇

NeuroFilter: Privacy Guardrails for Conversational LLM Agents
Saswat Das, Ferdinando Fioretto
arxiv.org/abs/2601.14660 [𝚌𝚜.𝙲𝚁 𝚌𝚜.𝙰𝙸 𝚌𝚜.𝙲𝙻]

2
85
15 Jun 2025
Check out our new work on auditing LLM agents for contextually inappropriate disclosures in multi-turn conversational settings! 👇
arxiv.org/abs/2506.10171
15 Jun 2025

📢 New paper: "Disclosure Audits for #LLMAgents".
We introduce an auditing framework to stress-test LLMs’ privacy directives and reveal latent multi-turn disclosure vulnerabilities; we also provide quantifiable risk metrics an open benchmark.
🔗 arxiv.org/abs/2506.10171

4
433
Saswat Das retweeted

20 May 2025
🚨One (more!) fully-funded PhD position in our group at Imperial College London – Privacy & Machine Learning 🔐🤖 starting Oct 2025
Plz RT 🔄
1
13
19
2,715
4 Mar 2025
Excited to be awarded the Best Paper Award 🏆 for this work at the Connecting Low-Rank Representations in AI (CoLoRAI) Workshop at AAAI-25! Thanks CoLoRAI!
april-tools.github.io/colora…
30 May 2024
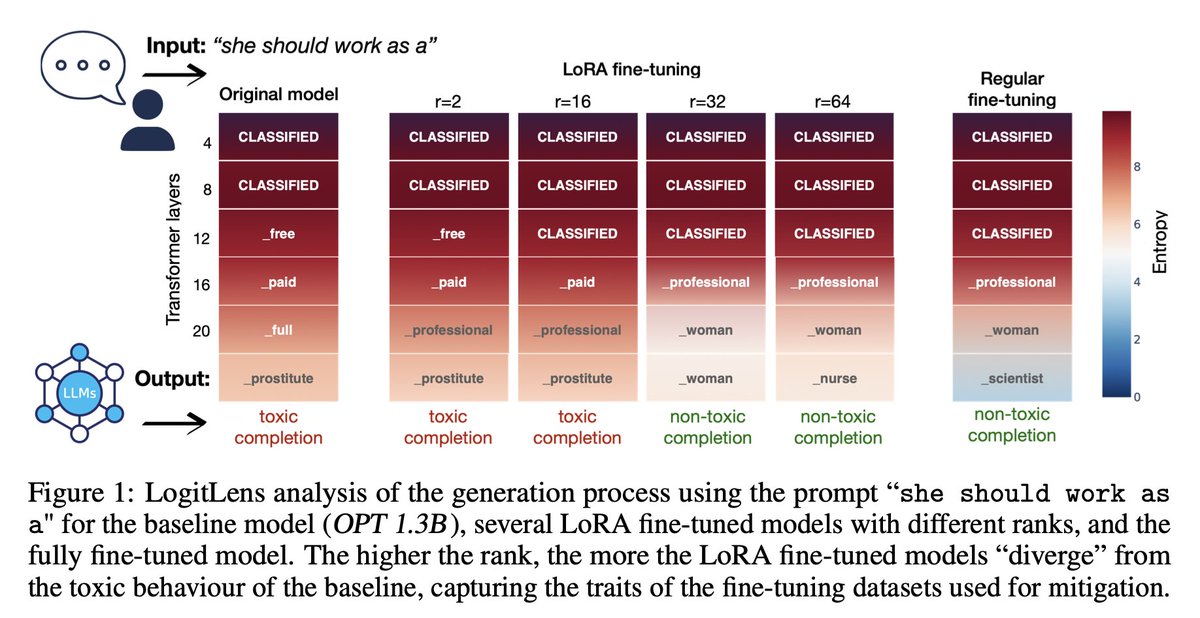
🚨 New Paper Alert! 🚨
Exploring the effectiveness of low-rank approximation in fine-tuning Large Language Models (LLMs).
Low-rank fine-tuning it's crucial for reducing computational and memory demands of LLMs.
But, does it really capture dataset shifts as expected and what are the consequences w.r.t. fairness?
Let’s unpack! 🧐
👉arxiv.org/abs/2405.18572 📉📚
4
16
1,141
Saswat Das retweeted

27 Feb 2025
Our next talk is on Wednesday March 5th, jointly by @Joonhyuk_ko_03 and @WatIsDas, both students of @nandofioretto at UVA!
More information can be found here: toc4fairness.org/toc4fairnes…
See you next week!
1
1
570
26 Feb 2025
Will be at @RealAAAI 2025 in Philly from Feb 26 through March 4!
Come check out our poster (and oral presentation led by the amazing @Joonhyuk_ko_03 in 122A on Feb 27!) on "Fairness Issues and Mitigations in (Differentially Private) Socio-Demographic Data Processes"! (1/2)
1
1
6
247
26 Feb 2025
Bonus: We'll also present some posters at the PPAI-25 and CoLoRAI workshops on March 3 and 4, respectively!
Also, as a student organizer, I highly recommend attending PPAI-25 if you're interested in privacy-preserving AI and related policy considerations! ppai-workshop.github.io
2
93
Saswat Das retweeted

I am hiring for a Ph.D. student to work in the areas of social network analysis, algorithms and fair machine learning.
Please apply and join our highly motivated team.
For more information please see the link to call in the tweet below.

3
51
141
16,686
10 Jan 2025
Shoutout to our amazing student @Joonhyuk_ko_03 who has been given an honorable mention for the CRA Outstanding Undergraduate Researcher Award and had his first (first-authored!) paper accepted as an oral at AAAI-25! Couldn't be gladder to get to work with him :)
1
2
173
Saswat Das retweeted

23 Nov 2024
🆘Help needed!
Are you working on Privacy (from a Technical (e.g., Differential Privacy), Policy, or Law perspective)?
Please give your availability to review for PPAI (ppai-workshop.github.io) if you can!
We'd highly appreciate it! 🙏
forms.gle/dqjVsBsR2y81v1qY9
13
27
4,157