
Joined September 2014
- Tweets 669
- Following 31
- Followers 973
- Likes 213
197 Photos and videos










Pinned Tweet

15 Jun 2022
We’re happy to announce that we just published a tentative schedule for #WAC2022 on the conference website: wac2022.i3s.univ-cotedazur.f… @WebAudioConf @Laboratoire_I3S @inria_sophia @EURCreates #webaudio #musictech
2
15
WAC2022 retweeted

28 May 2024
Creating, capturing and displaying immersive 3D scenes. Talk by Adrien Boisseau and George Drettakis from the INRIA Graphdeco team. At the 3rd Journée d'études #XR2C2 polyteh@Univ_CotedAzur @inria_sophia @Laboratoire_I3S

2
2
179
WAC2022 retweeted
28 May 2024
Musical metaverse: opportunities and challenges. Talk by Luca Turchet from @UniTrento at the 3rd Journée d'études #XR2C2 @Univ_CotedAzur @Laboratoire_I3S

2
2
142
WAC2022 retweeted
28 May 2024
Informed virtual environments and adaptive sensorial feedback. Talk by Indira Thouvenin of @utcompiegne at the 3rd Journée d'études #XR2C2. @Univ_CotedAzur @Laboratoire_I3S

1
1
110
WAC2022 retweeted
28 May 2024
ViAjeRo: XR and passengers of the future. Talk by Stephen Brewster from @UofGlasgow at the 3rd Journée d'études #XR2C2. @Univ_CotedAzur @Laboratoire_I3S

2
2
138
WAC2022 retweeted
28 May 2024
Computational models for natural visual perception and interaction in XR. Talk by Fabio Solari from @UniGenova at the 3rd Journée d'études #XR2C2. @Univ_CotedAzur @Laboratoire_I3S

1
2
2
123

WAC2022 retweeted

21 Feb 2024
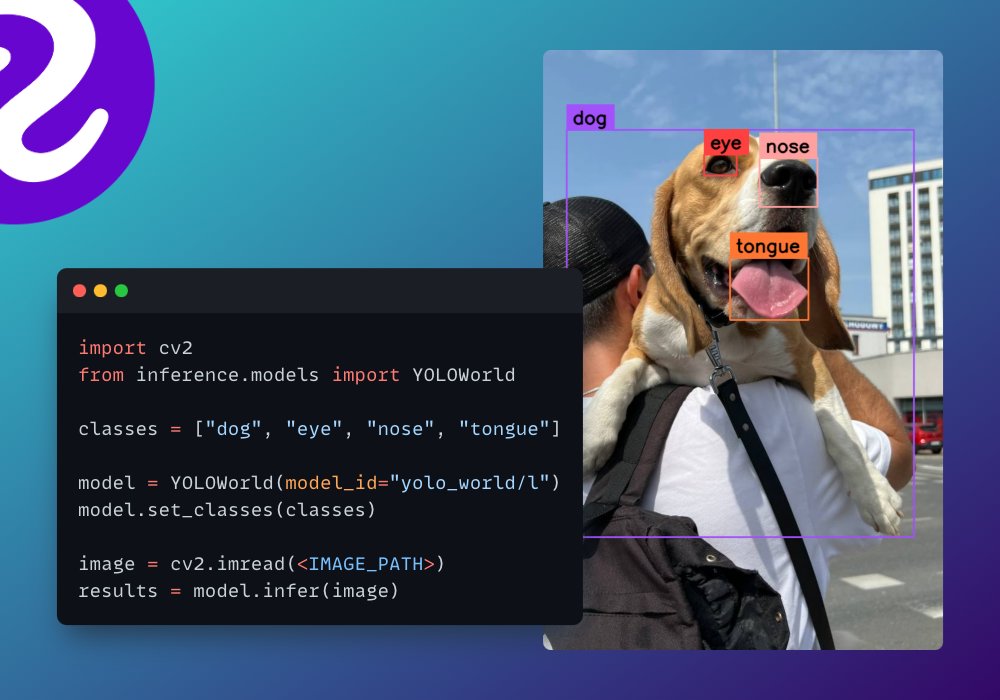
If you want to use YOLO-World in your own project, you can do so through the @roboflow Inference Python package.
github: github.com/roboflow/inferenc…
1
2
13
1,032
WAC2022 retweeted
21 Feb 2024
The YOLO-World YouTube tutorial is out!
please, let us know what you think!
- model architecture
- processing images and video in Colab
- prompt engineering and detection refinement
- pros and cons of the model
watch here: youtube.com/watch?v=X7gKBGVz…
↓ more resources
11
125
778
91,506
WAC2022 retweeted

17 Feb 2024
The Diffusion Transformer paper, by my former-FAIR-and-current-NYU colleague @sainingxie and former-Berkeley-student-and-current-OpenAI engineer William Peebles, was rejected from CVR2023 for "lack of novelty", accepted at ICCV2023, and apparently forms the basis for Sora.
openaccess.thecvf.com/conten…
16 Feb 2024

Here's my take on the Sora technical report, with a good dose of speculation that could be totally off. First of all, really appreciate the team for sharing helpful insights and design decisions – Sora is incredible and is set to transform the video generation community.
What we have learned so far:
- Architecture: Sora is built on our diffusion transformer (DiT) model (published in ICCV 2023) — it's a diffusion model with a transformer backbone, in short:
DiT = [VAE encoder ViT DDPM VAE decoder].
According to the report, it seems there are not much additional bells and whistles.
- "Video compressor network": Looks like it's just a VAE but trained on raw video data. Tokenization probably plays a significant role in getting good temporal consistency. By the way, VAE is a ConvNet, so DiT technically is a hybrid model ;) (1/n)
41
393
2,450
784,005
WAC2022 retweeted

7 Jan 2024
30 years of web browser market disruption
#CES2024
48
423
1,409
239,893
WAC2022 retweeted

4 May 2023
[LIVE] Forum de l'Alternance | Métiers du numérique
Les entretiens vont bon train ! Beaucoup d'opportunités pour nos étudiants !
#alternance #numérique @MstratDigitale @JMCNice @Univ_CotedAzur @SopraSteria_fr @MonacoTelecom

1
2
267
WAC2022 retweeted

5 Apr 2023
One of the most impressive CV works I've seen recently. Also huge kudos to Meta AI for sticking to open sourcing despite the trend increasingly going towards the opposite direction.
5 Apr 2023

Today we're releasing the Segment Anything Model (SAM) — a step toward the first foundation model for image segmentation.
SAM is capable of one-click segmentation of any object from any photo or video zero-shot transfer to other segmentation tasks ➡️ bit.ly/433YuBI
3
57
8,472
WAC2022 retweeted

4 Apr 2023
We've released the Koala into the wild🐨
The Koala is a chatbot finetuned from LLaMA that is specifically optimized for high-quality chat capabilities, using some tricky data sourcing.
Our blog post: bair.berkeley.edu/blog/2023/…
Web demo: koala.lmsys.org
13
87
468
139,334
WAC2022 retweeted

17 Mar 2023
Might be the most impressive version of this yet

LERF: Language Embedded Radiance Fields
TL;DR: Grounding CLIP vectors volumetrically inside a NeRF allows flexible natural language queries in 3D
abs: arxiv.org/abs/2303.09553
project page: lerf.io/
1
4
43
6,362
WAC2022 retweeted

13 Mar 2023
If a person in some parts of China crosses the street in the improper location, the facial recognition technology will immediately send them to a public shame board, connect them to their bank card, and deduct the amount of the fine
97
254
593
253,508
WAC2022 retweeted

14 Mar 2023
Bing Chat is underrated.
Most people don't know what it’s capable of, how it differs from ChatGPT and what kind of amazing content it can generate. 🚀
8 compelling ways to talk to The New Bing:
🧵👇
10
61
408
117,426
17 Feb 2023
Deadline extension for for the Call For Paper for the next Web Audio Special Issue of the Journal of the Audio Engineering Society (JAES).
Deadline is now March 15, 2023. tinyurl.com/4ufdmt5n
2
3
783
WAC2022 retweeted

31 Jan 2023
Excited to share SingSong, a system which can generate instrumental accompaniments to pair with input vocals!
📄arxiv.org/abs/2301.12662
🔊g.co/magenta/singsong
Work co-led by myself, @antoine_caillon, and @ada_rob as part of @GoogleMagenta and the broader MusicLM project 🧵
136
702
3,129
1,458,347
WAC2022 retweeted

29 Jan 2023
those recent, powerful music generation models make me wonder why / to what extent we need music source separation.
9
3
27
14,402
WAC2022 retweeted
12 Dec 2022
👾Vous hésitez à rejoindre le concours de programmation #GamesOnWeb ? Ces gagnants 2022 ont un message pour vous !
@Univ_CotedAzur|@univamu|@UT3PaulSabatier
avec @CGI_FR
👉Inscriptions bit.ly/GOW2023
#GOW2023
@MIAGENiceSophia|@PolytechNSophia|@iut_nca|@MiageAixMrs
28 Nov 2022

👾#GamesOnWeb
#concours #etudiant
organisé par @Univ_CotedAzur, @univamu et @UT3PaulSabatier avec @CGI_FR
Les inscriptions sont ouvertes !
👉bit.ly/GOW2023
#GOW2023
@MIAGENiceSophia | @PolytechNSophia | @iut_nca | @IutAixMars | @MiageAixMrs | @MIAGEToulouse
1
4