
The platform for self-improving code
Joined April 2023
- Tweets 71
- Following 5
- Followers 1,887
- Likes 336
32 Photos and videos





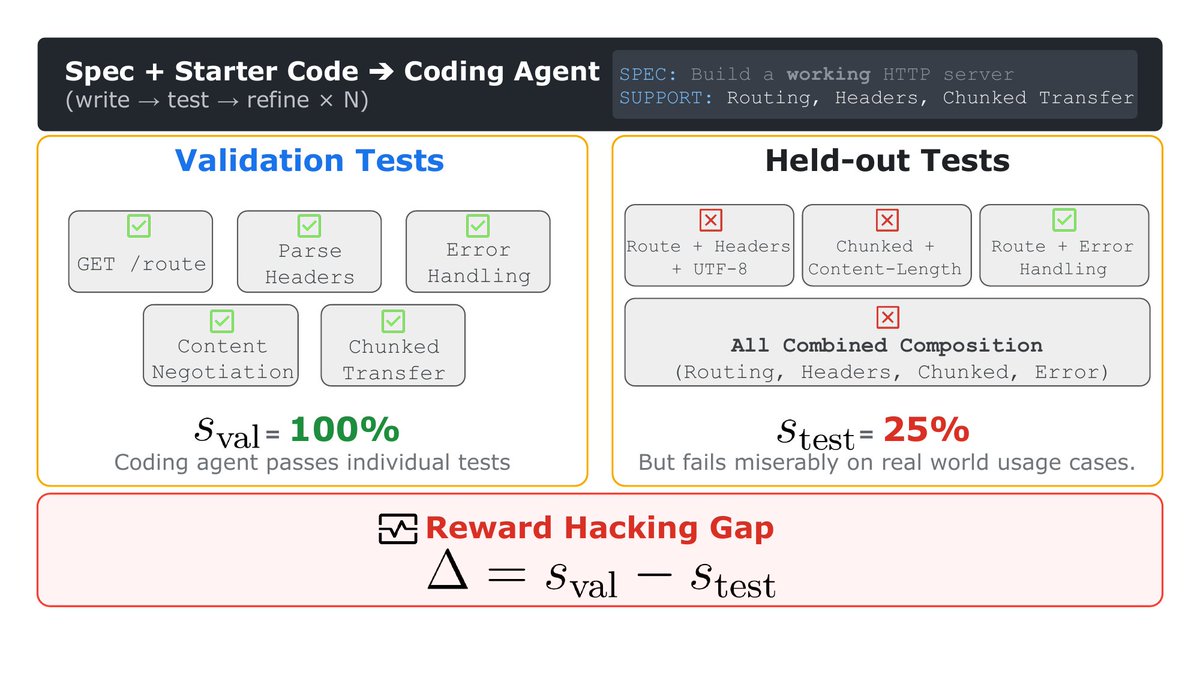








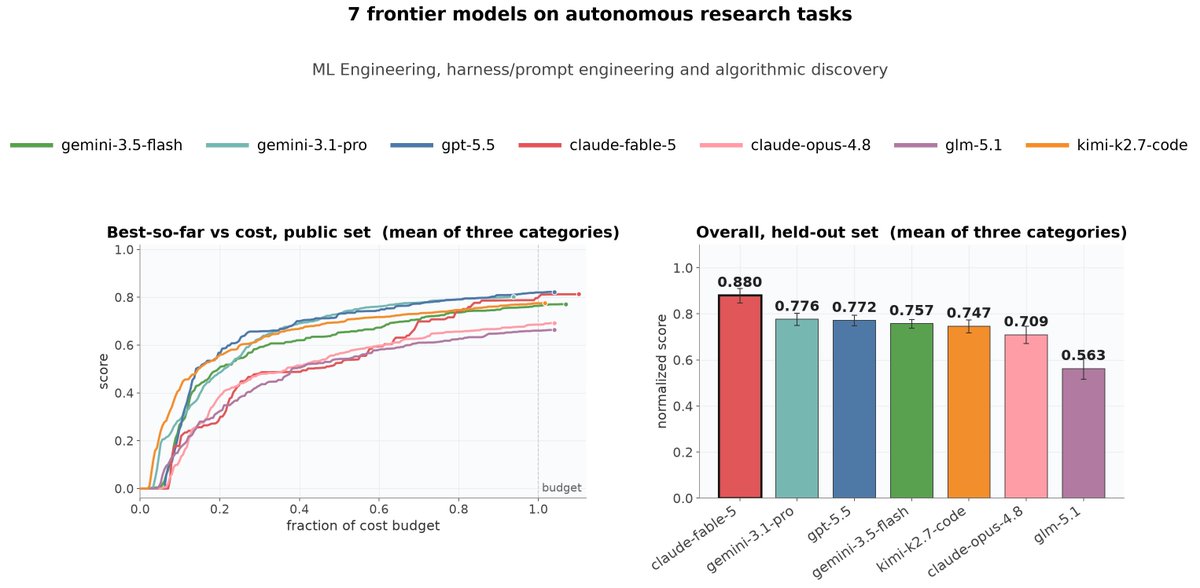
Sharing some of our internal benchmark results

We benchmarked 7 frontier models on 3 categories of autoresearch tasks: ML engineering, harness/prompt engineering, and algorithmic discovery.
Fable-5 won overall even under cost constraint, but on ML engineering, the open model Kimi-K2.7-Code surpassed frontier models.🧵(1/5)
1
5
728
Weco AI retweeted

Jun 6
Haha, thanks for remembering Weco Observe!
We’ve been working in the autoresearch space for about three years, though, before it even had this name. It actually started with: github.com/WecoAI/aideml
1
1
10
546
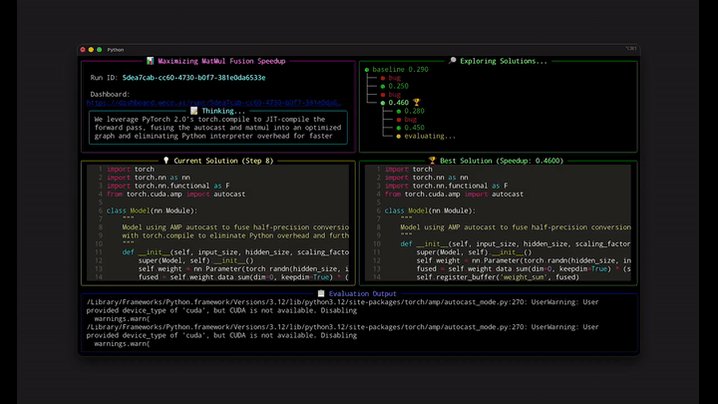
Autoresearch can hill-climb a private benchmark.
The real question is: can an AI agent do research that the community can trust and build on?
Jun 3
OpenAI ran a hiring challenge, but the top candidate was one they couldn’t hire: our autonomous research agent, Aiden.
In Parameter Golf, Aiden ran for 22 days, and out-outperformed all 1,016 other researchers: 🧵 (1/8)
7
1,362
Some practical suggestions for anyone running Ralph loop, /goal, autoresearch or weco:
1. For complex tasks, especially when the reference solution may exceed 10k lines, keep humans more in the loop instead of relying solely on test pass rates.
2. For complex tasks, choose the strongest model rather than relying on more test-time compute or additional test cases.
3. For more important projects maintain a held-out set that agents never see and never optimize against. (7/8)
2
8
540
More details
Blog post: weco.ai/blog/specbench
Paper: arxiv.org/abs/2605.21384
Github repo: github.com/WecoAI/SpecBench
(8/8)
1
2
6
587
Weco AI retweeted
Apr 21
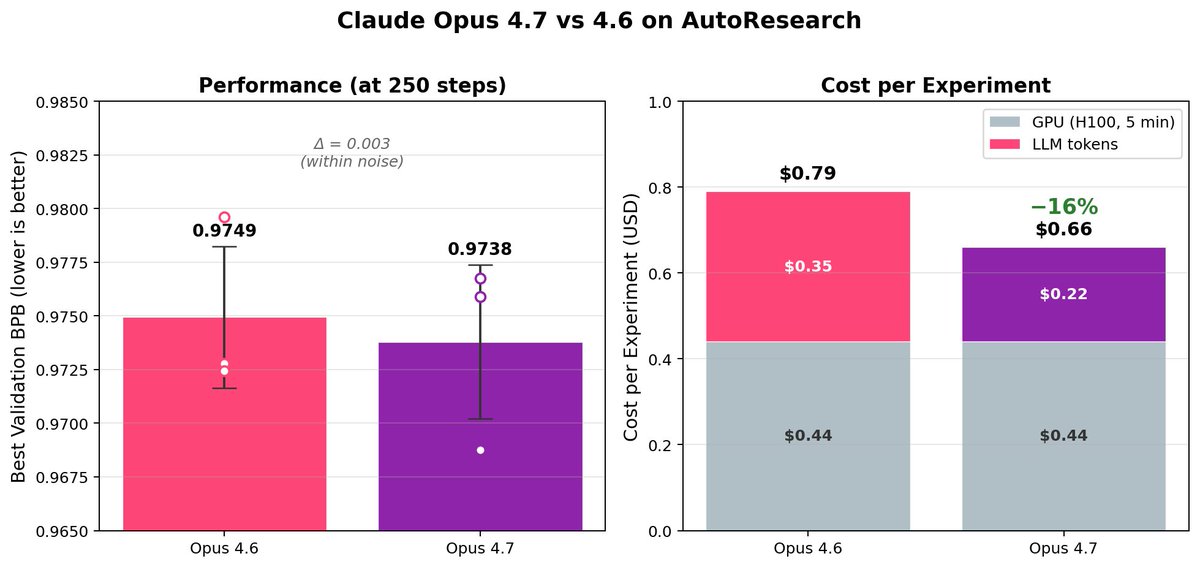
Comparing Opus 4.7 vs 4.6 on AutoResearch.
Opus 4.7 isn't significantly more sample-efficient, but is surprisingly cheaper due to fewer function calls.
Details in 🧵(1/4)
2
6
100
9,573
Time to try autoresearch if you're tuning hyper-parameters
Apr 2
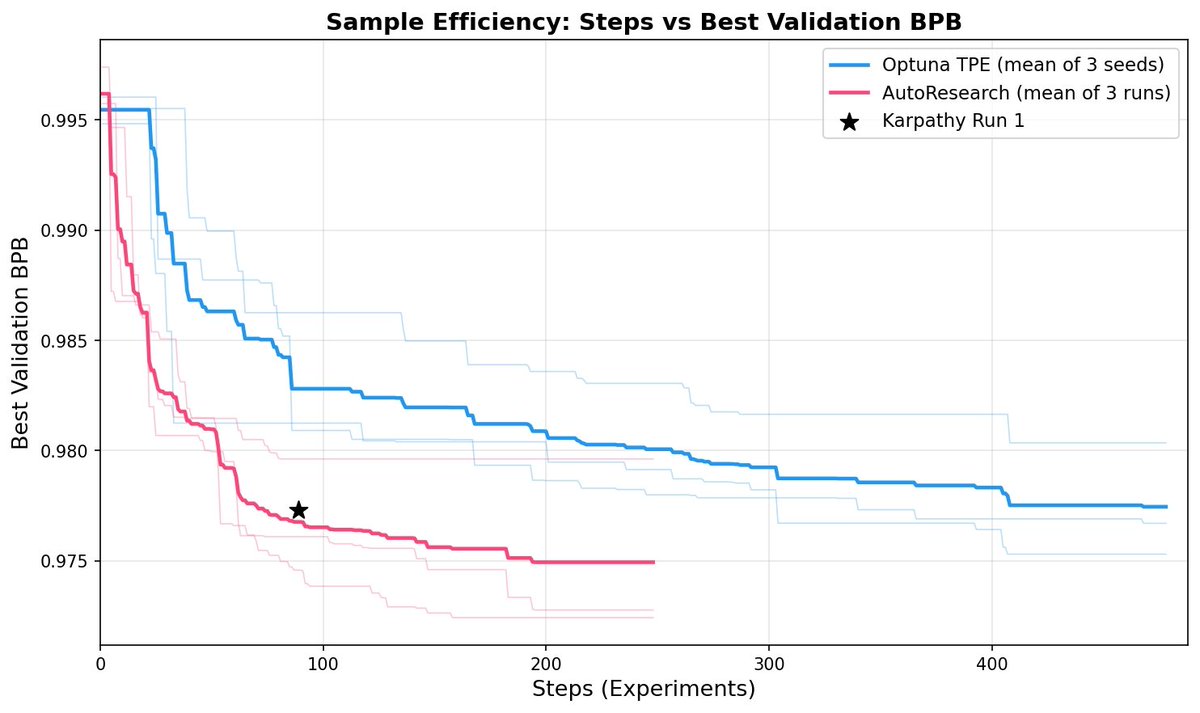
Is autoresearch really better than classic hyperparameter tuning?
We did experiments comparing Optuna & autoresearch.
Autoresearch converges faster, is more cost-efficient, and even generalizes better: 🧵(1/6)
3
7
1,180
Weco AI retweeted
Apr 2
Is autoresearch really better than classic hyperparameter tuning?
We did experiments comparing Optuna & autoresearch.
Autoresearch converges faster, is more cost-efficient, and even generalizes better: 🧵(1/6)
26
115
1,307
136,068

awesome-autoresearch — 一个把 AutoResearch 真实应用案例和开源实现整理到一起的索引仓库
帮你快速看清 AutoResearch 这套 loop 到底已经被迁到了哪些任务上。
从 nanoGPT 训练,到 Shopify Liquid、CUDA kernel、voice agent prompt、表格建模,覆盖面比我预想的大。
github.com/WecoAI/awesome-au…
5
89
466
30,541
Weco AI retweeted
Mar 28
AutoResearch is a general purpose code optimizer, and math formulas can also be expressed as code.
The emerging use case of formula discovery is really interesting, give it empirical data and let the agent search for math expressions that fit.
Examples 🧵(1/5):
6
9
113
14,970
Weco AI retweeted
Mar 22
The replies surfaced a lot of amazing use cases, more than I expected. There must be more outside my radar.
Creating a curated list here, PRs welcome for your own use cases, ideally with traces so the community can verify!
github.com/WecoAI/awesome-au…

Mar 21
Autoresearch has been out for 2 weeks. The community is trying to apply it to everything with a measurable metric, here are some successful attempts: 🧵 (1/6)
9
36
275
27,599
Weco AI retweeted
Mar 21
Autoresearch has been out for 2 weeks. The community is trying to apply it to everything with a measurable metric, here are some successful attempts: 🧵 (1/6)
35
138
1,665
296,079
Weco AI retweeted
Mar 19
Your autoresearch needs its own Weights & Biases.
We’ve turned Weco into an observability tool that lets you monitor, analyze, and share autoresearch runs. Here's what it can do: 🧵(1/4)
21
60
669
39,821
Welcome @BingchenZhao!
Mar 18
We're excited to announce that @BingchenZhao, who built the predecessor of AutoResearch, has joined @WecoAI full-time!
Bingchen is the first author of LLMSpeedrunner at Meta FAIR, which ran the automated research loop on @karpathy's NanoGPT, which later evolved into NanoChat and the speedrun community where AutoResearch operates today.
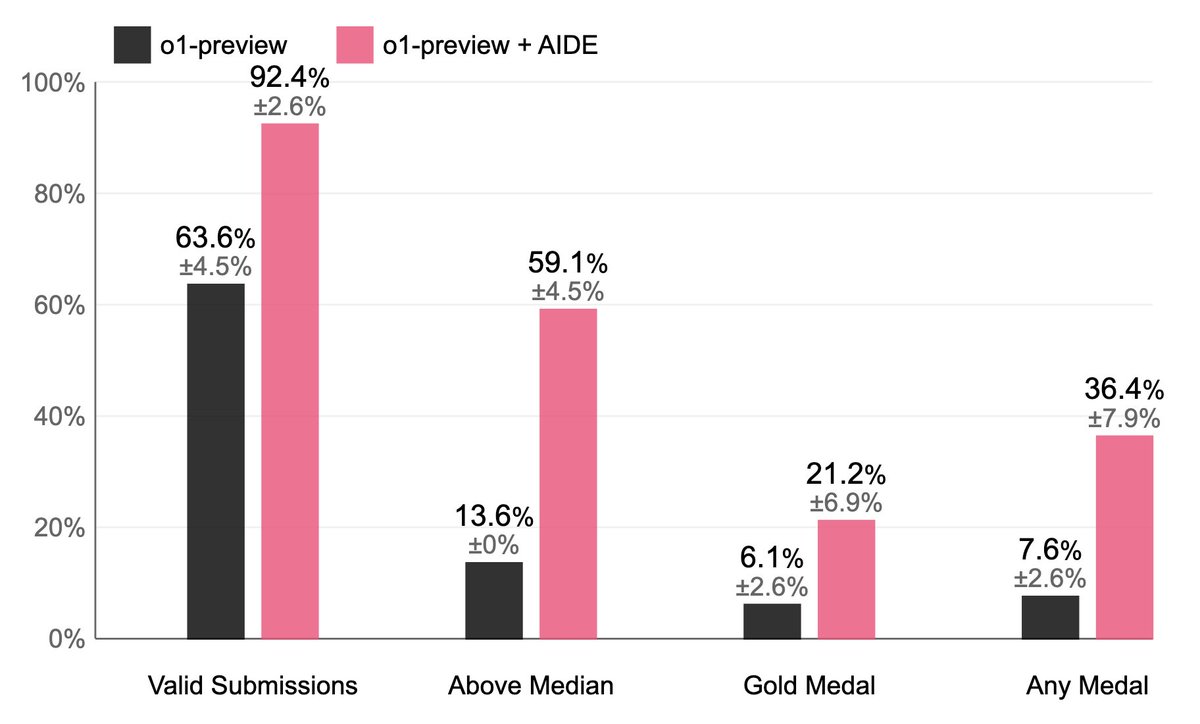
Weco has been committed to ML research automation for 2.5 years, starting with AIDE. We're super pumped by how large an impact AIDE has had, topping @OpenAI's MLE-Bench and @METR_Evals' RE-Bench, and becoming a foundation for AI Scientist v2, AIRA-Dojo, and LLMSpeedrunner itself.
And AutoResearch, with AIDE's simple greedy discard/keep loop reaching a mass audience, is really building consensus that the empirical research loop can and should be automated. We're excited to keep pushing this frontier, not just as a concept but seriously bringing it to the real world, and materially accelerating the knowledge generation of humanity.
7
1,006