
Whalesync lets you real-time, two-way sync your data between CMSs like Webflow, WordPress, and Wix and tools like Notion, Airtable, and Sheets.
Joined March 2021
- Tweets 1,759
- Following 361
- Followers 998
- Likes 1,059
338 Photos and videos










Jun 9
I like to live dangerously, but not too dangerously.
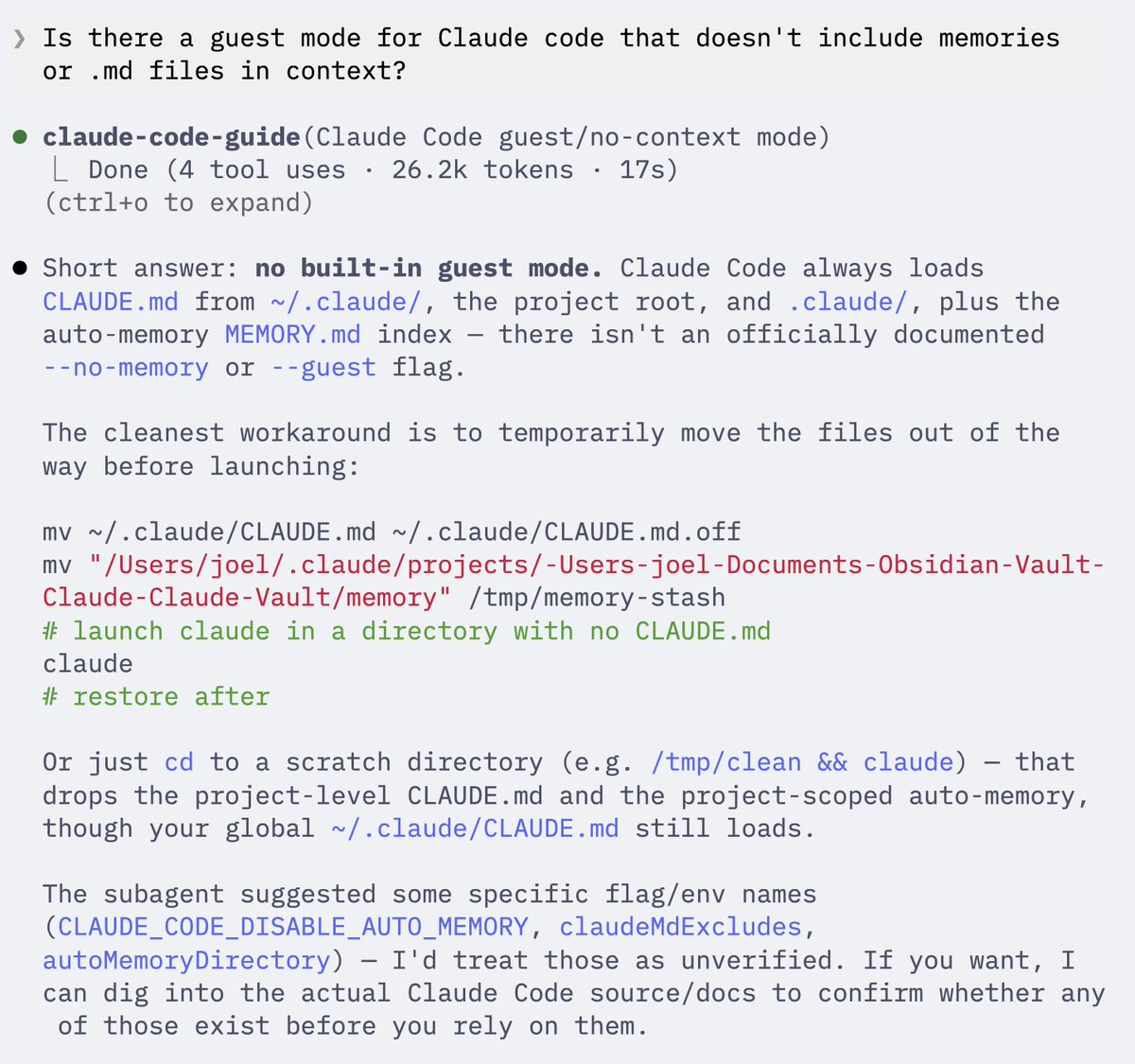
People often seem surprised when they learn that I always run Claude in "dangerously skip permissions" mode. Over the last few months we've been forming a point of view at Whalesync on how to make AI super powerful, but still run in a safe way. "Dangerously" becomes a misnomer (as it should be).
If you want to live dangerously but still sleep at night, I wrote up my thoughts here:
scratch.md/blog/give-ai-99-p…
28
Jun 9
It's interesting how challenging it is for these models to observe something right in front of them.
Jun 9

running the chair test (real time response) in Claude desktop with Fable 5 on Max
(chair picture in the replies if you want to count the wood pieces yourself)
1
43
Jun 8
What's your current/next website?
0%
Webflow
0%
Framer
0%
Static site generator
0%
Whatever AI builds
0 votes • Final results
20
Whalesync retweeted
Jun 2
If you have a Claude or Codex subscription and a WordPress site, this is for you
1
1
107
Jun 5
If you're not already doing AI assisted email, this is an easy and obvious place to start:
scratch.md/blog/how-i-use-cl…
21
Jun 5
Whalesync is the best way to sync Airtable with other tools. But we weren't happy with the way editing worked. Claude code spoiled us. So we built a (much) better way to use AI agents like Claude and Codex to (safely!) work with our content in Webflow, HubSpot, Linear, Intercom, Stripe.
The key requirements were:
1. Let the AI agent read and write anything BUT
2. Don't let it publish anything AND
3. Make it as fast and easy as possible for the humans (us) to find and approve/reject EXACTLY what the AI changed
If you like AI agents and work with content, you should definitely try it and let us know what you think. You can download the desktop app and try it free here: scratch.md/start/
Jun 5
just made a quick video of how easy it is now to use codex with airtable
this way is cool because it pulls your whole base as a local copy, so codex can clean up and edit fast without touching your live base
then you review and publish the good stuff back to airtable
1
1
1
152
Whalesync retweeted
May 30
Whalesync is still the best way to sync Webflow with Airtable/Notion/Supabase.
But if you want to edit Webflow with AI, you need try @scratchdotmd today. (Hint: we made it too.)
Here's a bit of a preview of what's possible:
2
2
5
700
Jun 1
Two things make that make it easier for average people to get value from AI agents:
1. 99%* is the perfect level of automation for AI agents
2. read and write everything** is the perfect level of access for AI agents
* review and publish is the last 1%, that is for humans
**but not publish, see above
Jun 1
99% is the perfect level of automation for AI agents.
Here's Claude 99% connected to Shopify:
57
May 30
Whalesync is still the best way to sync Webflow with Airtable/Notion/Supabase.
But if you want to edit Webflow with AI, you need try @scratchdotmd today. (Hint: we made it too.)
Here's a bit of a preview of what's possible:
2
2
5
700
May 29
If you struggle with email, I wanted to share how to do Getting Things Done Gmail Claude.
Other than writing code, dealing with email was one of the things I was most excited about when LLMs went mainstream. I've never been good at my email. Some people are amazing, but it's just not how my brain is wired.
I read Getting Things Done by David Allen years ago and I tried to implement his system, but it was just too tedious for me to keep up with. But with Claude, it's crazy good. Only takes a few minutes a day!
I wanted to share my setup in case anyone else is still dealing with constant guilt from being "bad" at dealing with the inbox flood: scratch.md/blog/how-i-use-cl…
1
42
May 28
"6. Verification is the bottleneck."
This is exactly why we built @scratchdotmd.
It collapses the work around the bottleneck to near zero.
You, the human, review and publish the work AI produces in minutes.
May 26

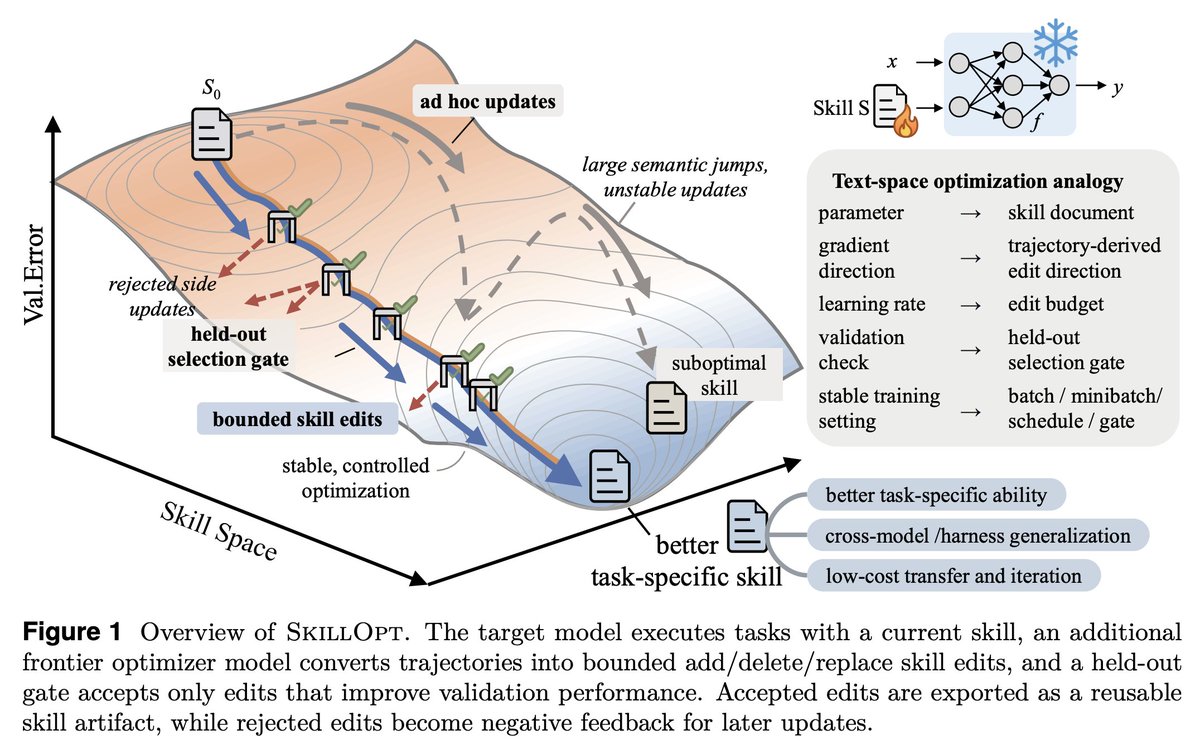
Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness.
SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them.
A few things I learned that you should consider too.
1. The validation gate is the only thing that matters in a self-editing loop.
Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop.
2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot.
Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size.
3. Compactness wins. Median final skill: ~920 tokens.
Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't.
4. The harness is becoming less important; the skill is becoming more important.
A Codex-trained skill ported into Claude Code hit 59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that
produced it.
5. Frozen model trained context is the practical adaptation.
GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is
the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models.
6. Verification is the bottleneck.
Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage.
There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7,
gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK:
- Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it.
- Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is.
Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured.
The fast/slow split they describe already lives implicitly in the digital-brain-skill repo:
- voice-guide and tone-of-voice.md are slow-state (rarely touched)
- posts.jsonl and bookmarks.jsonl are fast-state
What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing.
If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: arxiv.org/pdf/2605.23904
1
3
473
Whalesync retweeted

May 26
Did a lot of looking at SERPs with Shopify stores showing up. Published the observations (and links) if you are also asking questions like "what do the top ranking PDPs actually look like?" or "are there any clear patterns of what works?"
scratch.md/research/shopify-…
1
1
39
Whalesync retweeted

May 19
Just released @screamingfrog SEO Spider v.24:
screamingfrog.co.uk/blog/seo…
Includes -
🤖Screaming Frog MCP
🧑🤝🧑Auto Compare Crawls
📊View Crawl Changes in Email Notifications
📧Send Crawl Export Attachments by Email
🚫Find Uncrawlable Links
& lots more! Enjoy.

24
62
283
30,923
May 19
Scratch is here! Time to get the news out.
We've been pretty quiet recently regarding what we've been working on, mostly because we were still figuring it out ourselves. We knew that AI was shifting the whole data game and for a while we were experimenting with concepts internally to see what felt right.
Now we're pretty confident that we're onto something really cool and we want to share it.
Here's what we're building: scratch.md/blog/what-is-scra…
May 19
Your AI is great at editing. Not great at knowing if the edits are ready to publish.
So Scratch pulls your website, CRM, help desk (or any API) content as local files.
Your AI agent edits.
You review.
Scratch publishes what you approve.
Try it: scratch.md/blog/what-is-scra…
1
1
62
Whalesync retweeted
May 8
Distribution is the hard part now. Just like before.
1
1
55

We’ve agreed to a partnership with @SpaceX that will substantially increase our compute capacity.
This, along with our other recent compute deals, means that we’ve been able to increase our usage limits for Claude Code and the Claude API.
4,731
11,931
130,541
23,979,643
Whalesync retweeted

We've formed some strong opinions over the years at Whalesync. I think there's going to be a pretty big shift in how SMBs need to think about their SaaS tools and company data to work with AI efficiently and safely.
Decided to write up my thoughts: whalesync.com/blog/9-lessons…
1
2
45