
Joined October 2021
- Tweets 358
- Following 680
- Followers 12,214
- Likes 1,481
66 Photos and videos






Pinned Tweet

15 Jul 2024
🎉Today we are announcing Evol-Instruct V2 !!!
🔥 Auto Evol-Instruct is one of the most important technologies for WizardLM-2.
Paper link: arxiv.org/pdf/2406.00770
We build a fully automated Evol-Instruct pipeline, allowing WizardLM-2 to be extended from three evolved domains (chat, code and math) of WizardLM-1 to dozens of evolved domains
🚀With Auto Evol-Instruct, You can create high-quality, highly complex instruction tuning data for any task without the need for human efforts!
⚖️We hope that this universal technology can promote fairness and efficiency for all the AI researchers in training and evaluation their own large language models.
👉For more details, please refer to Can Xu's channel:

🔥 Excited to share the other key Technology of WizardLM-2!
📙AutoEvol: Automatic Instruction Evolving for Large Language Models
🚀We build a fully automated Evol-Instruct pipeline to create high-quality, highly complex instruction tuning data:
-------- 🧵 --------
👉Motivation First:
Over the past six months, we have dedicated ourselves to exploring methods to scale up synthetic training for LLMs. Although Evol-Instruct has demonstrated excellent performance in creating powerful post-training data, it relies too heavily on the efforts of human experts to design specific evolutionary methods for specific tasks.
Once Evol-Instruct is applied to an entirely new complex task, the methods for executing evolution need to be redesigned. This limitation of Evol-Instruct makes scaling up extremely challenging, prompting us to develop a new method, 💻Auto Evol-Insturct💻, that can evolve instruction data automatically.
Auto Evol allows the training of WizardLM2 to be conducted with nearly an unlimited number and variety of synthetic data.
Let's see: 🧐
1. Limitations of Evol-Instruct:
Evol-Instruct takes the high-quality data as a starting point, and further iteratively refines it using LLMs, improving its complexity and diversity. It has demonstrated superior performance across a broad range of public benchmarks that evaluate diverse capabilities, including instruction following (WizardLM), code generation (WizardCoder), and mathematical reasoning (WizardMath). While Evol-Instruct exhibits outstanding performance, its heavy reliance on heuristic efforts presents notable challenges. Whenever it is used for a completely new task, the methods for execution evolution need to be redesigned. Such a process requires a high level of expertise and considerable costs, hindering its adaptation to a wider spectrum of capabilities.
2. We want to build a fully automated Evol-Instruct pipeline
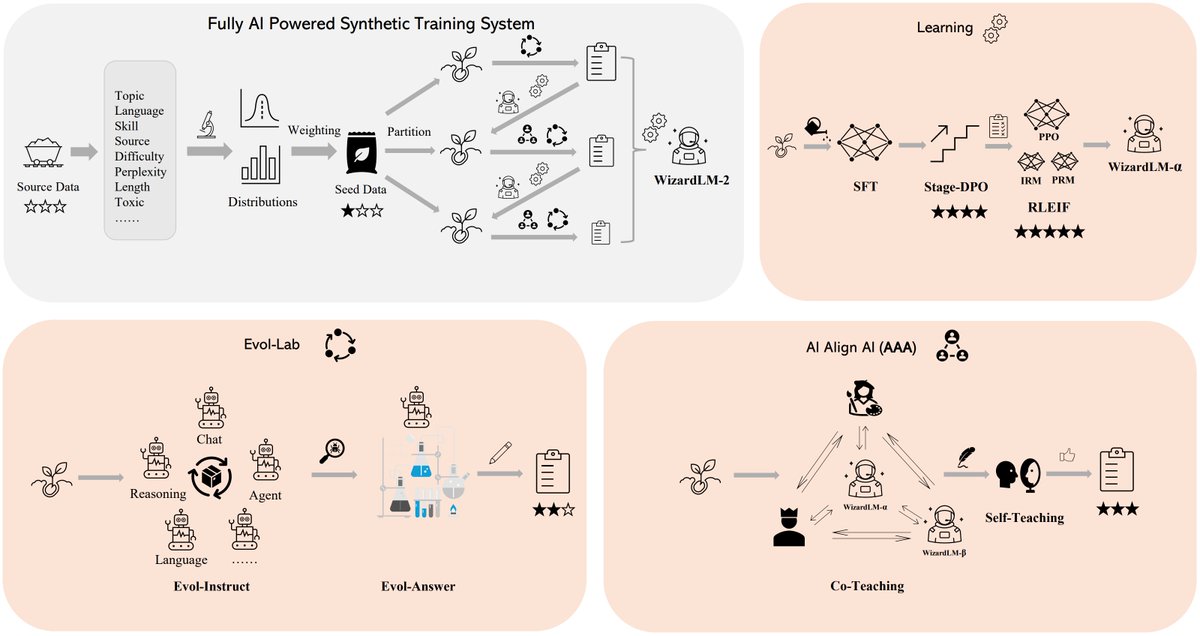
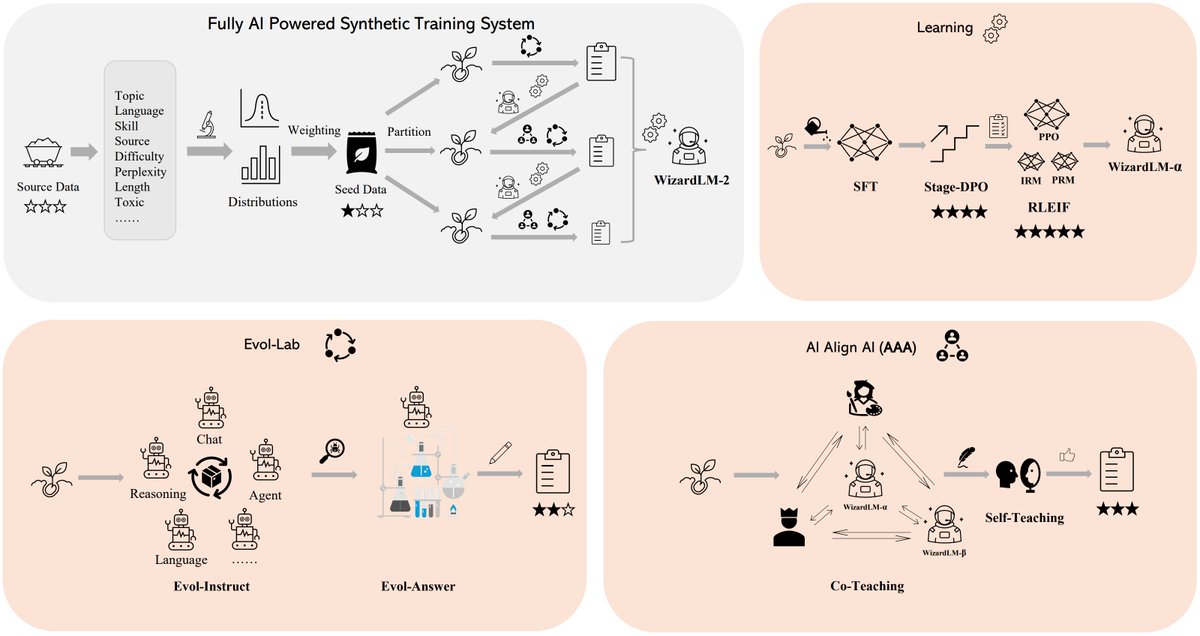
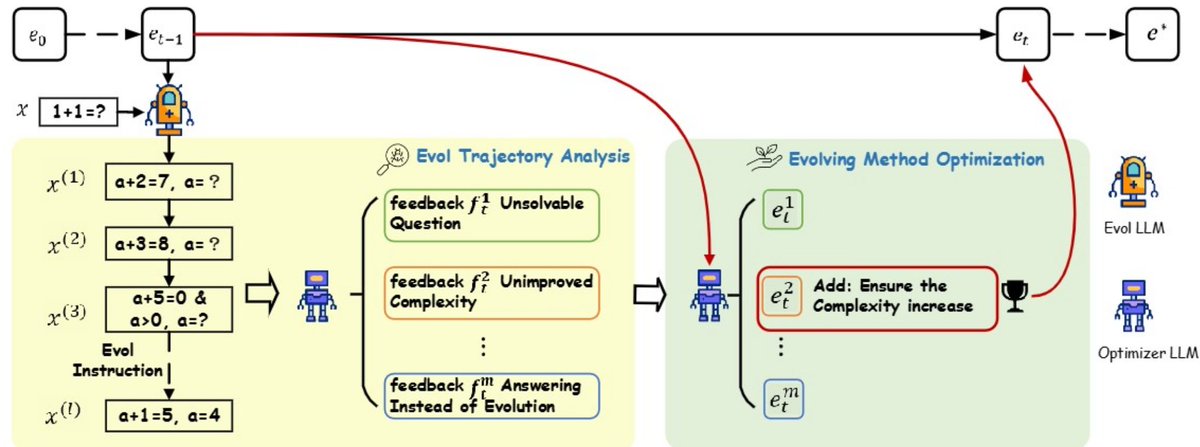
Auto Evol-Instruct automatically designs evolving methods that make given instruction data more complex, enabling almost cost-free adaptation to different tasks by only changing the input data of the framework. From below figure, we can see the iterative process of optimizing the initial evolving method e0 into the optimal evolving method e∗, which specifically outlines the transition from et−1 to et. We refer to the model used for evolution as the evol LLM, and the model used for optimization as the optimizer LLM. This optimization process involves two critical stages: (1) Evol Trajectory Analysis: The optimizer LLM carefully analyzes the potential issues and failures exposed in instruction evolution performed by evol LLM, generating feedback for subsequent optimization. (2) Evolving Method Optimization: The optimizer LLM optimizes the evolving method by addressing these identified issues in feedback. These stages alternate and repeat to progressively develop an effective evolving method using only a subset of the instruction data. Once the optimal evolving method is identified, it directs the evol LLM to convert the entire instruction dataset into more diverse and complex forms, thus facilitating improved instruction tuning.
3. Fully AI-driven Evol-Instruct can outperform the Evol-Instruct used by human experts.
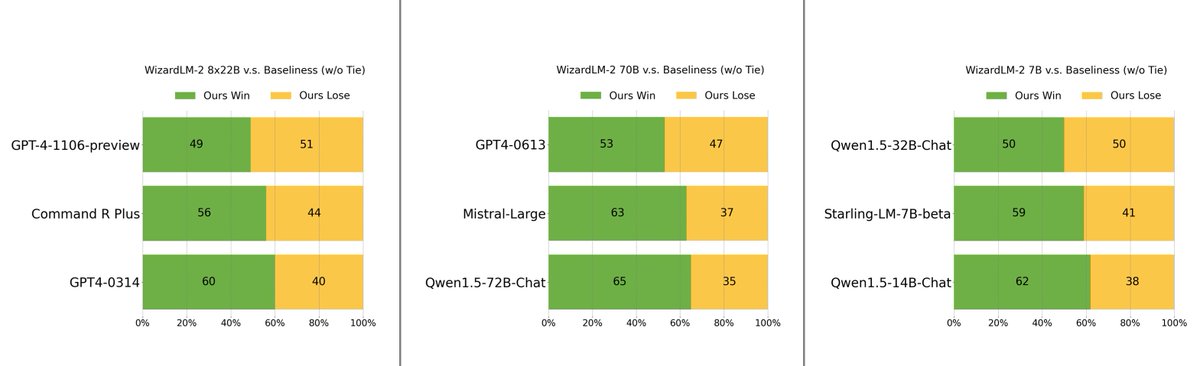
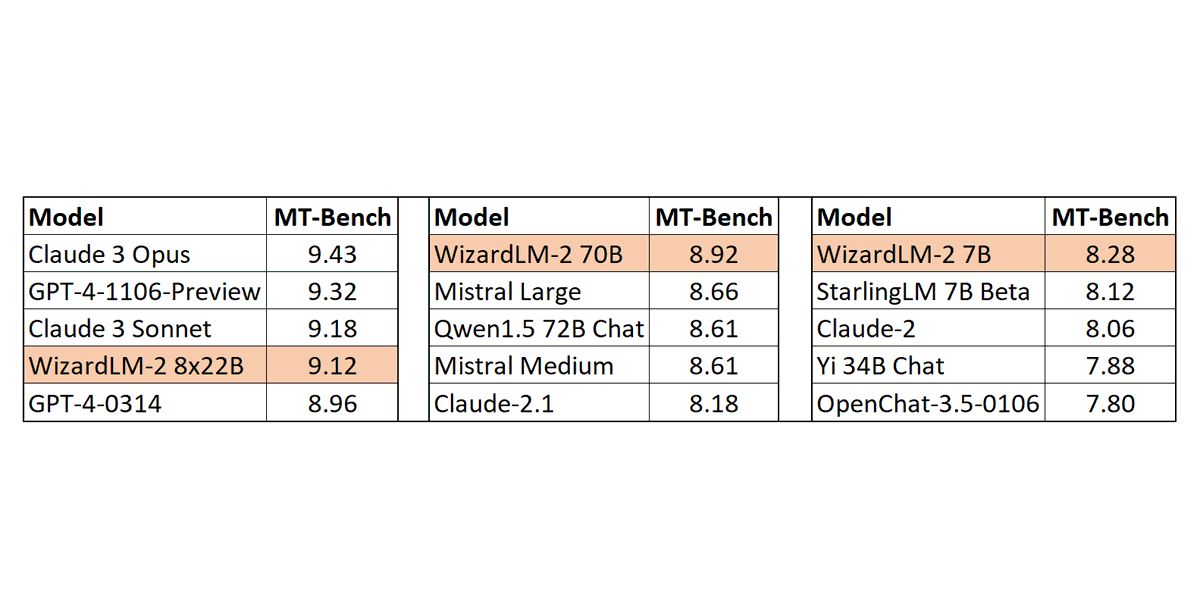
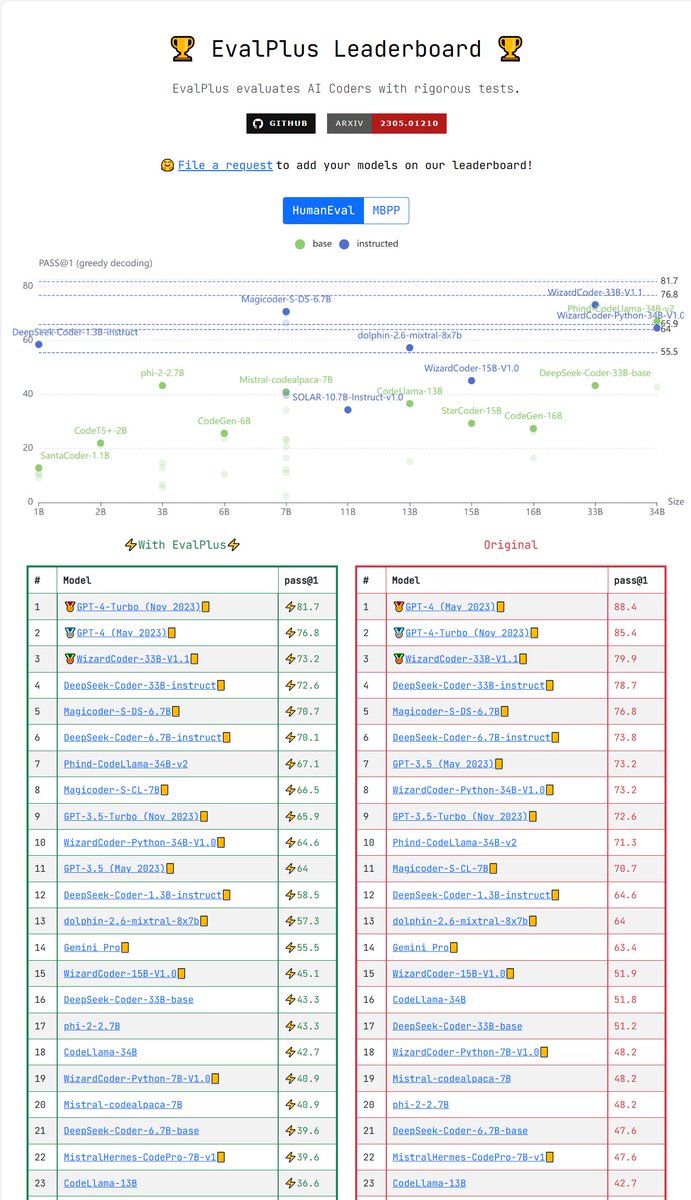
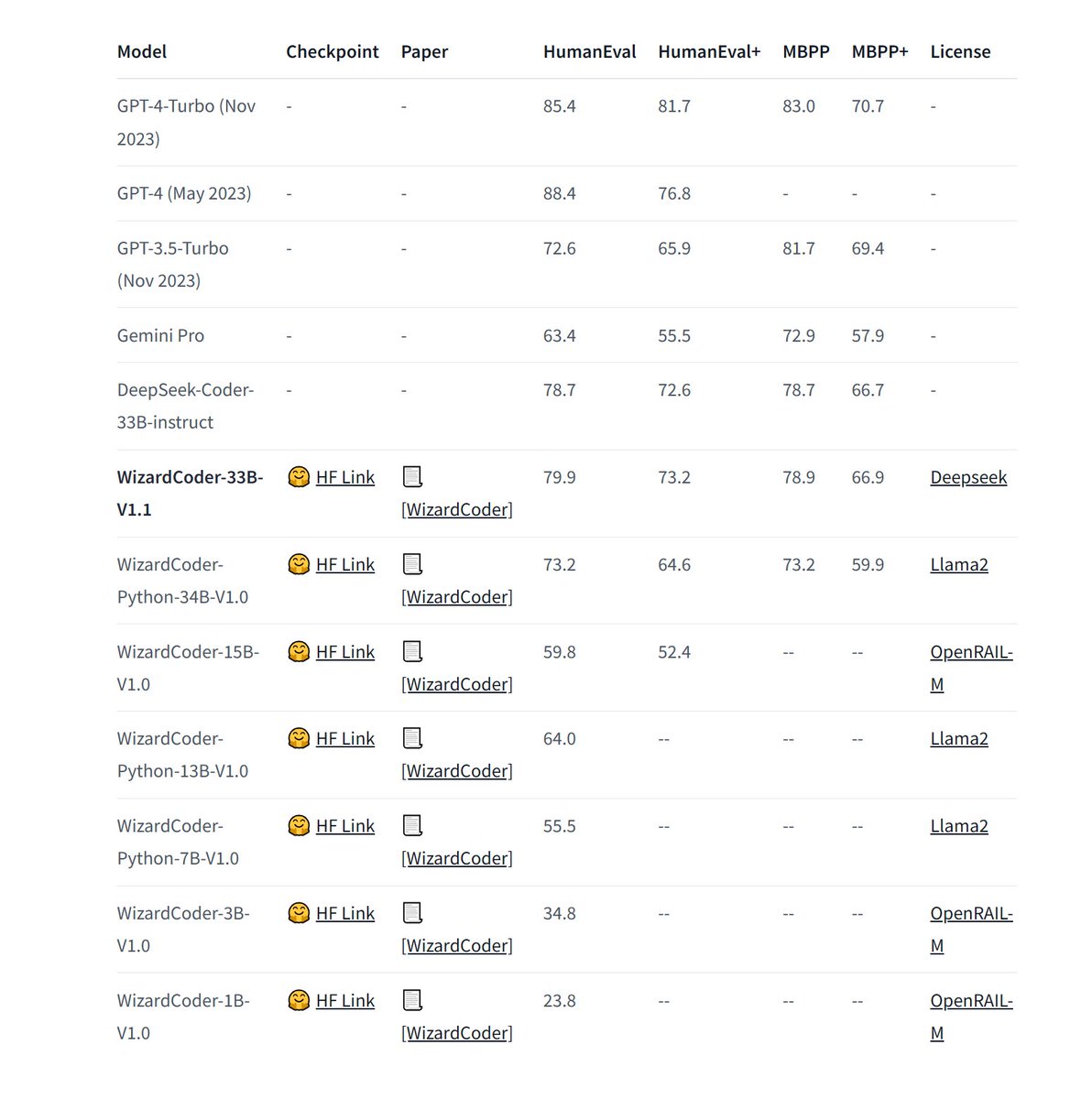
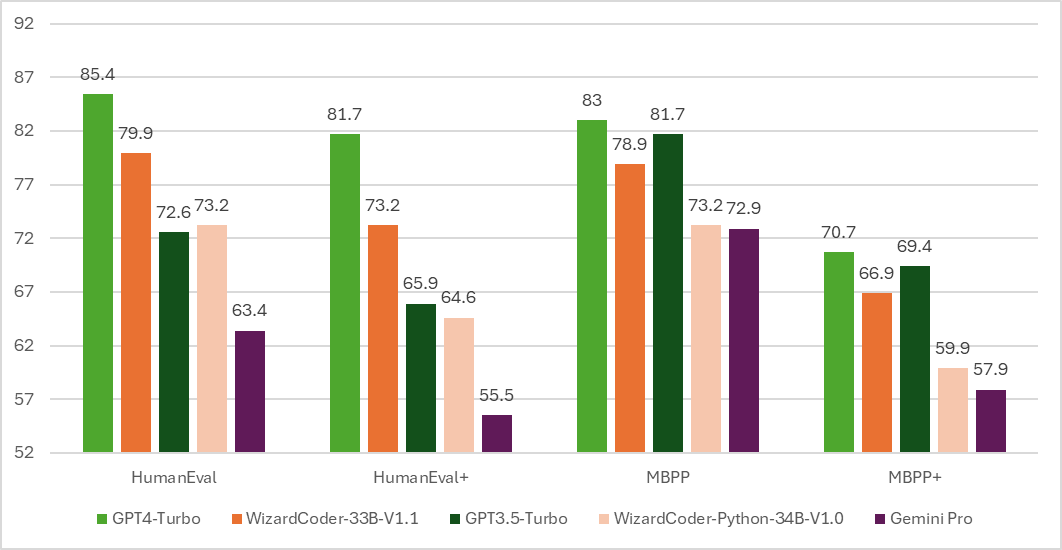
Our experiments show that the evolving methods designed by Auto Evol-Instruct outperform the Evol-Instruct methods designed by human experts in instruction tuning across various capabilities, including instruction following, mathematical reasoning, and code generation. As shown in the below table, on the instruction following task, Auto Evol-Instruct can achieve a improvement of 10.44% over the Evol method used by WizardLM-1 on MT-bench; on the code task HumanEval, it can achieve a 12% improvement over the method used by WizardCoder; on the math task GSM8k, it can achieve a 6.9% improvement over the method used by WizardMath.
4. Scaling Evol-Instruct to various domains and tasks
With the new technology of Auto Evol-Instruct, the evolutionary synthesis data of WizardLM-2 has scaled up from the three domains of chat, code, and math in WizardLM-1 to dozens of domains, covering tasks in all aspects of large language models. This allows Arena Learning to train and learn from an almost infinite pool of high-difficulty instruction data, fully unlocking all the potential of Arena Learning.
For more details, please refer to:
Paper: arxiv.org/pdf/2406.00770
Project: github.com/nlpxucan/WizardLM
We are working with our legal team to publicly release the code of Auto Evol-Instruct.

11
44
225
40,094
WizardLM retweeted

9 Jan 2025
🎉 Thrilled to share our paper accepted by #KDD2025!
🌟AgentGen🌟: An automated environment and task generator that enhances LLM-based agents' planning abilities through diverse, difficulty-controlled synthetic trajectory data.
👇🏻agent-gen.github.io/
2
2
14
2,745
9 Jan 2025
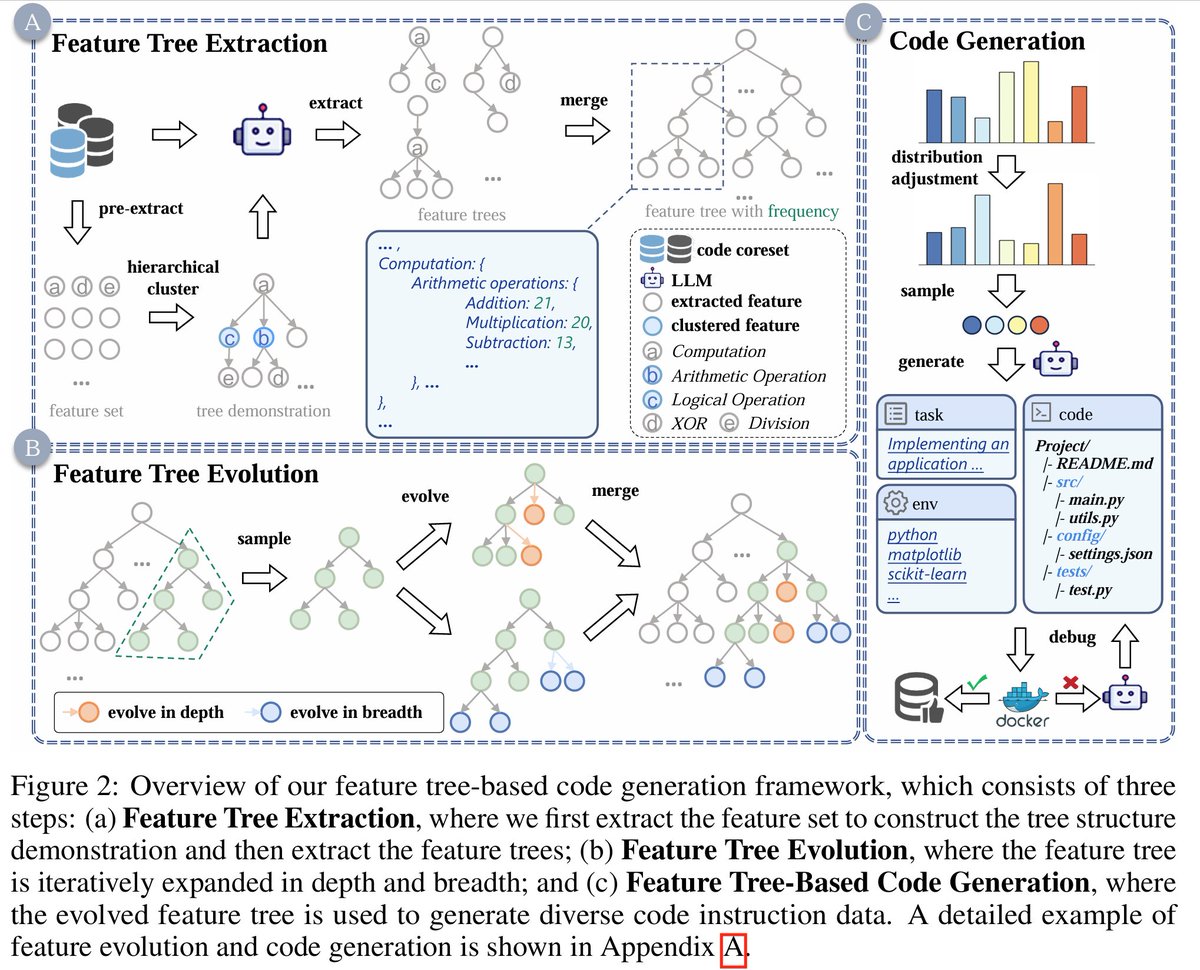
🚀New approach from WaveCoder Team for optimizing code LLMs. The novel feature tree based framework, inspired by AST and Evol-Instruct to modeling semantic relationships, generates more diverse data. The EpiCoder hits SOTA in both challenge file and function benchmarks.
9 Jan 2025

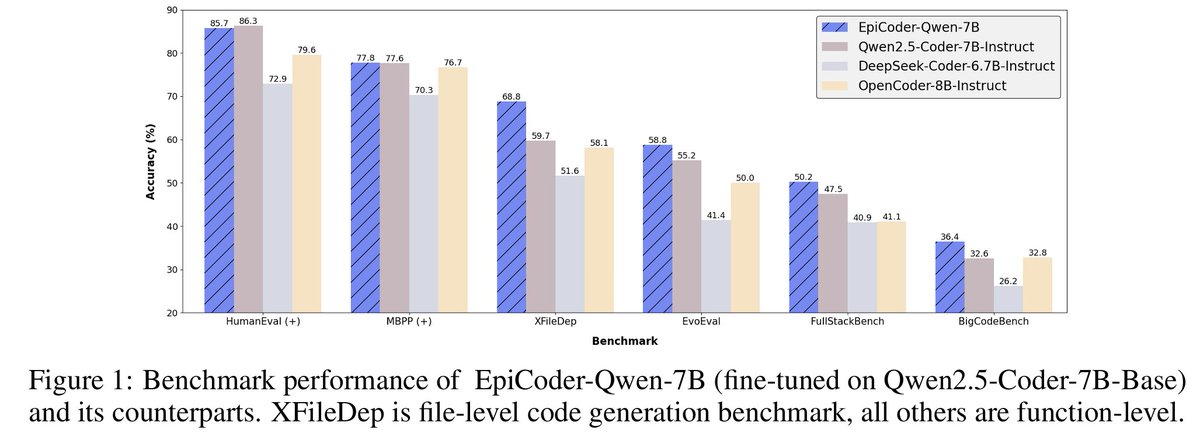
🚀 Introducing EpiCoder: a hierarchical feature tree-based framework for diverse and intricate code generation.
🔍 Outperforming benchmarks, it handles everything from simple functions to multi-file projects deftly.
📢 Open source release soon!
🔗 arxiv.org/abs/2501.04694


5
5
69
8,011

GENIAC phase2にて、日本語のローカルLLMを使ってEvol-Instructによるデータセット構築に取り組んだ際の記事を公開しました。(3件目/全4件)
zenn.dev/matsuolab/articles/…
13
45
7,056

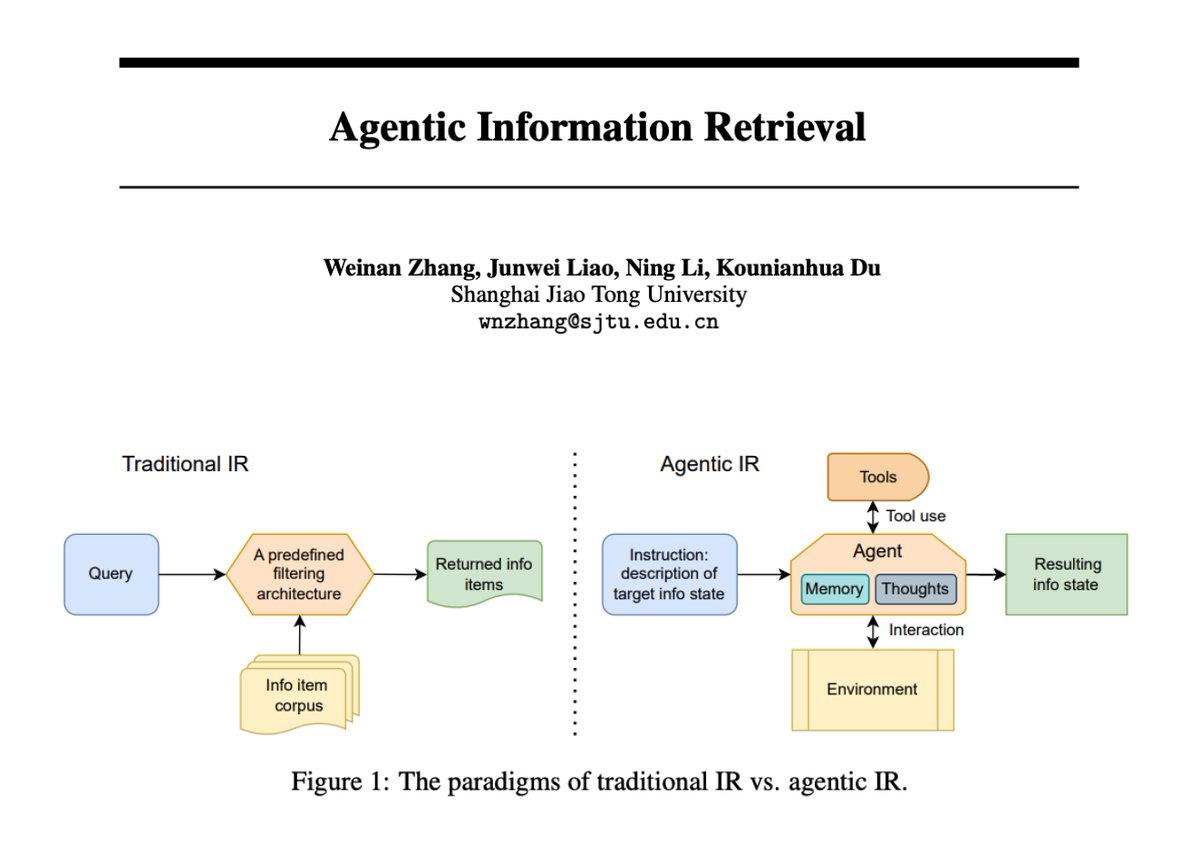
Agentic Information Retrieval
This paper provides a good introduction to agentic information retrieval, which is shaped by the capabilities of LLM agents.
I've been developing with this paradigm recently and it does offer lots of interesting ways to optimize retrieval systems.
11
110
698
63,477
27 Sep 2024
🎉 x 2
🎉Excited to see the core techniques of WizardLM2 has been accepted to #EMNLP2024 and #NeurIPS2024!
👉Automatic Instruction Evolving for Large Language Models
(arxiv.org/abs/2406.00770)
👉Arena Learning: Build Data Flywheel for LLMs Post-training via Simulated Chatbot Arena (arxiv.org/abs/2407.10627)
Congrats to all outstanding co-authors. We will not stop our journey towards AGI.
3
1
14
3,528
25 Sep 2024
Congrats! We are dedicated to innovating synthetic training techniques, drawing inspiration from theory of evolution. The previous Evol-Instruct focused on evolving higher-value instructions from the instruction side. This work, Arena Learning, emphasizes the evolution of higher-value answers at the response side through a process of competition and selection. Both methods complement and coordinate with each other, and together they can promote the LLM's performance evolving.
25 Sep 2024

🎉Excited to see our WizardArena paper accepted to #NeurIPS2024!
👉Arena Learning: Build Data Flywheel for LLMs Post-training via Simulated Chatbot Arena (arxiv.org/abs/2407.10627)
Congrats to all outstanding co-authors. We will not stop our journey towards AGI.

1
11
53
7,426
WizardLM retweeted

10 Sep 2024
We are open sourcing our EvolKit pipeline that was instrumental in the creation of supernova, under MIT license. This was heavily inspired by the AutoEvol paper from @WizardLM_AI, and is a tremendously powerful tool for creating complex datasets.
Find it here: github.com/arcee-ai/EvolKit
4
8
39
4,522
WizardLM retweeted

10 Sep 2024
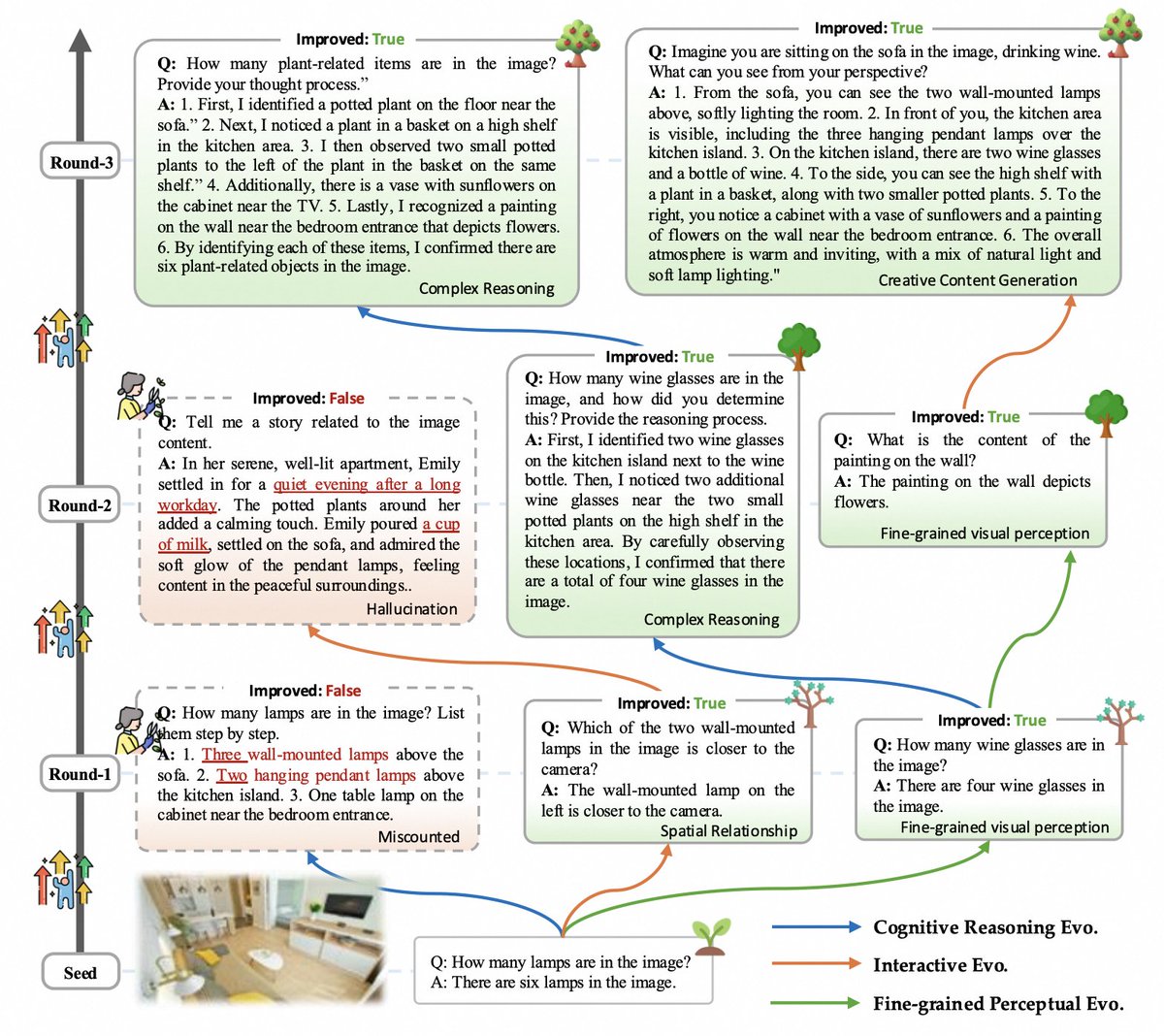
🚀 Excited to introduce MMEvol, which improves MLLM through complex and diverse instruction with perceptual, cognitive, and interactive evolution.
🌟 Achieving a 3.1% accuracy boost across 13 VL tasks.
Code and data will be released soon; stay tuned!
📄 huggingface.co/papers/2409.0…
2
11
33
4,797
WizardLM retweeted

10 Sep 2024
Impressed by @arcee_ai team's work. Proud to open-source EvolKit: framework for evolving instruction data with OPEN-SOURCE models. Inspired by @WizardLM_AI, result of my month-long effort.
GitHub: github.com/arcee-ai/EvolKit
Don't forget SuperNova too! 🥳
10 Sep 2024

We are announcing Llama-3.1-SuperNova, a Llama-3.1-70B-Instruct model offline distilled from Llama-3.1-405B-Instruct. It's ridiculously strong, particularly in instruction following and math. It's available to play with at supernova.arcee.ai.
Read more about the model and how we plan to deploy it here: blog.arcee.ai/

5
21
99
12,408
WizardLM retweeted

28 Aug 2024
Learn what’s next for AI at Research Forum on Sept. 3; WizardArena simulates human-annotated chatbot games; MInference speeds pre-filling for long-context LLMs via dynamic sparse attention; Reef: Fast succinct non-interactive zero-knowledge regex proofs. msft.it/6019l4Qv9

ALT Decorative graphic with wavy shapes in the background in blues and purples. Text overlay in center left reads: “Research Focus: August 26, 2024”
3
6
23
7,166
WizardLM retweeted

16 Aug 2024
Congrats this impressive contribution to OSS community!
Also excited to see the state-of-the-art Hermes-3 models also leverage our Evol-Instruct to empower their complex instruction following capacities.

15 Aug 2024

Introducing 𝐇𝐞𝐫𝐦𝐞𝐬 𝟑: The latest version in our Hermes series, a generalist language model 𝐚𝐥𝐢𝐠𝐧𝐞𝐝 𝐭𝐨 𝐲𝐨𝐮.
nousresearch.com/hermes3/
Hermes 3 is available in 3 sizes, 8, 70, and 405B parameters. Hermes has improvements across the board, but with particular capability improvements in roleplaying, agentic tasks, more reliable function calling, multi-turn chats, long context coherence and more.
We published a technical report detailing new capabilities, training run information and more:
Paper: nousresearch.com/wp-content/…
This model was trained in collaboration with our great partners @LambdaAPI, and they are now offering it for free in a chat interface here: lambda.chat/chatui/
You can also chat with Hermes 405B on our discord, join here: discord.gg/NousResearch
Hermes 3 was a project built with the help of @teknium, @TheEmozilla, @nullvaluetensor, @karan4d, @huemin_art, and an uncountable number of people and work in the Open Source community.

1
5
46
7,904
WizardLM retweeted

6 Aug 2024
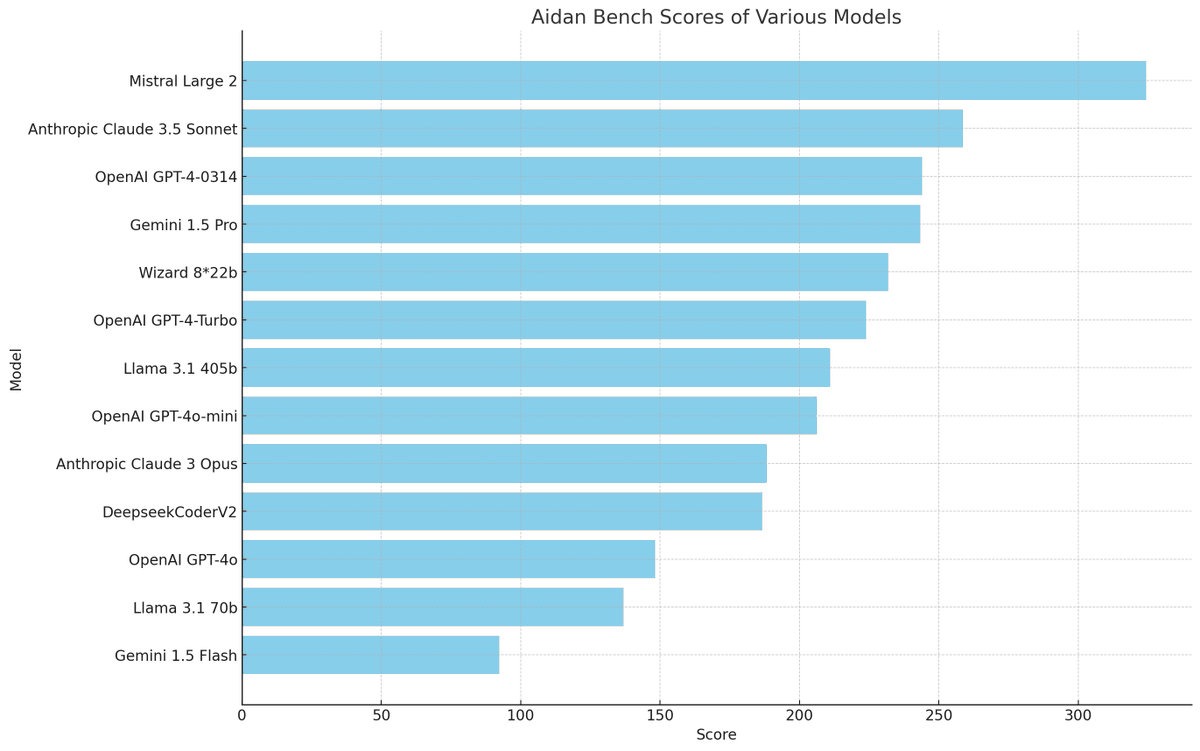
-- <big_model_smell> benchmark --
Aidan Bench measures creativity, reliability, attention, and instruction following.
>mistral large 2 wins by a lot???
>gpt-4o sucks confirmed
>sonnet-3.5 remains very strong
>gpt-4-0314 shows old man strength
github.com/aidanmclaughlin/A…
60
50
569
185,627
WizardLM retweeted

15 Jul 2024
The @WizardLM_AI team is back, with Evol-Instruct V2 (actually more like "Auto" Evol-Instruct), which is one of core components for WizardLM-2
Thank you @WizardLM_AI team.
15 Jul 2024

🎉Today we are announcing Evol-Instruct V2 !!!
🔥 Auto Evol-Instruct is one of the most important technologies for WizardLM-2.
Paper link: arxiv.org/pdf/2406.00770
We build a fully automated Evol-Instruct pipeline, allowing WizardLM-2 to be extended from three evolved domains (chat, code and math) of WizardLM-1 to dozens of evolved domains
🚀With Auto Evol-Instruct, You can create high-quality, highly complex instruction tuning data for any task without the need for human efforts!
⚖️We hope that this universal technology can promote fairness and efficiency for all the AI researchers in training and evaluation their own large language models.
👉For more details, please refer to Can Xu's channel:
1
12
3,068
WizardLM retweeted

15 Jul 2024
Exciting! Evol Instruct v2 paper is out!
Microsoft Research WizardLM just released Auto-Evol-Instruct!
(I consider this type of work pre/proto-agi, but my views are sometimes radical)
arxiv.org/pdf/2406.00770

3
12
2,598

Don't sleep!
WizardLM just dropped the (probably) best data generation method ever known to mankind!
I didn't get to read it all out yet (later on today), but from what Iv'e seen the main ideas are:
1. Ask a model to "make the task harder" (WizardLM-1)
2. BUT also ask a model to "make the methods for making tasks harder better"
(if it makes sense..)
Kind of like..
"How can I improve this prompt & response?"
"Improve the prompt & response based on this method"
Not just evolving the dataset, also the ways of which to evolve the dataset are evolving.
I'll dive deeper into the paper later on today and continue this thread with more accurate information.
Thanks you for releasing this!
Very very useful as always.
🔥 Excited to share the other key Technology of WizardLM-2!
📙AutoEvol: Automatic Instruction Evolving for Large Language Models
🚀We build a fully automated Evol-Instruct pipeline to create high-quality, highly complex instruction tuning data:
-------- 🧵 --------
👉Motivation First:
Over the past six months, we have dedicated ourselves to exploring methods to scale up synthetic training for LLMs. Although Evol-Instruct has demonstrated excellent performance in creating powerful post-training data, it relies too heavily on the efforts of human experts to design specific evolutionary methods for specific tasks.
Once Evol-Instruct is applied to an entirely new complex task, the methods for executing evolution need to be redesigned. This limitation of Evol-Instruct makes scaling up extremely challenging, prompting us to develop a new method, 💻Auto Evol-Insturct💻, that can evolve instruction data automatically.
Auto Evol allows the training of WizardLM2 to be conducted with nearly an unlimited number and variety of synthetic data.
Let's see: 🧐
1. Limitations of Evol-Instruct:
Evol-Instruct takes the high-quality data as a starting point, and further iteratively refines it using LLMs, improving its complexity and diversity. It has demonstrated superior performance across a broad range of public benchmarks that evaluate diverse capabilities, including instruction following (WizardLM), code generation (WizardCoder), and mathematical reasoning (WizardMath). While Evol-Instruct exhibits outstanding performance, its heavy reliance on heuristic efforts presents notable challenges. Whenever it is used for a completely new task, the methods for execution evolution need to be redesigned. Such a process requires a high level of expertise and considerable costs, hindering its adaptation to a wider spectrum of capabilities.
2. We want to build a fully automated Evol-Instruct pipeline
Auto Evol-Instruct automatically designs evolving methods that make given instruction data more complex, enabling almost cost-free adaptation to different tasks by only changing the input data of the framework. From below figure, we can see the iterative process of optimizing the initial evolving method e0 into the optimal evolving method e∗, which specifically outlines the transition from et−1 to et. We refer to the model used for evolution as the evol LLM, and the model used for optimization as the optimizer LLM. This optimization process involves two critical stages: (1) Evol Trajectory Analysis: The optimizer LLM carefully analyzes the potential issues and failures exposed in instruction evolution performed by evol LLM, generating feedback for subsequent optimization. (2) Evolving Method Optimization: The optimizer LLM optimizes the evolving method by addressing these identified issues in feedback. These stages alternate and repeat to progressively develop an effective evolving method using only a subset of the instruction data. Once the optimal evolving method is identified, it directs the evol LLM to convert the entire instruction dataset into more diverse and complex forms, thus facilitating improved instruction tuning.
3. Fully AI-driven Evol-Instruct can outperform the Evol-Instruct used by human experts.
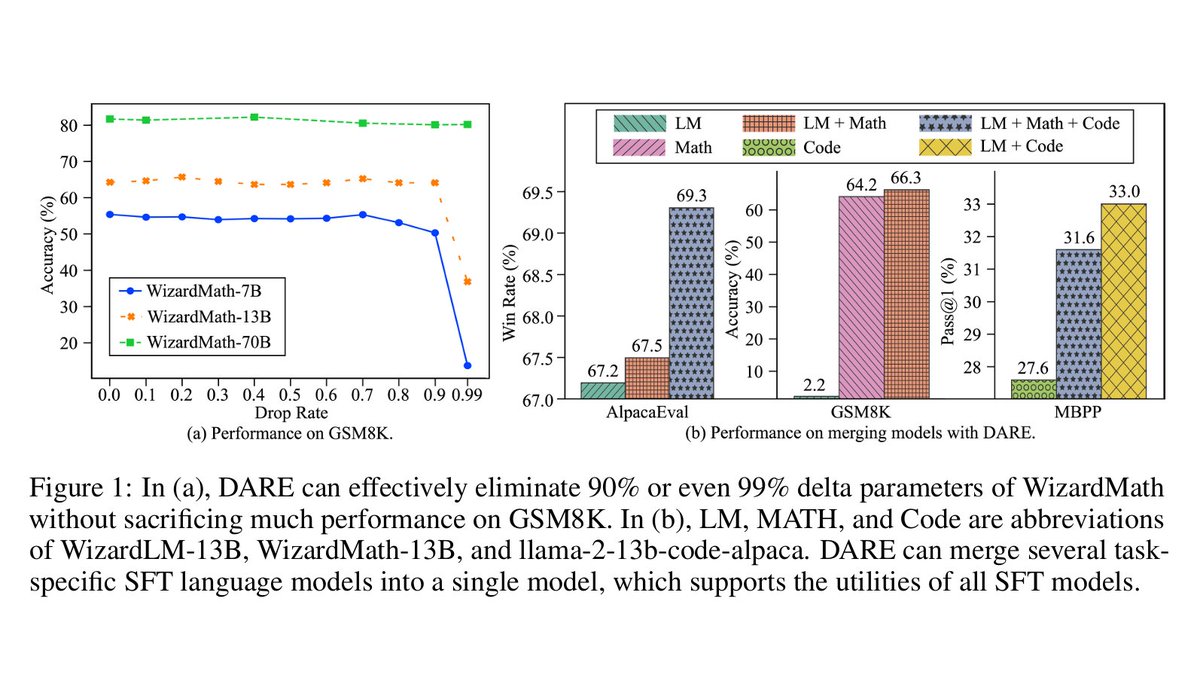
Our experiments show that the evolving methods designed by Auto Evol-Instruct outperform the Evol-Instruct methods designed by human experts in instruction tuning across various capabilities, including instruction following, mathematical reasoning, and code generation. As shown in the below table, on the instruction following task, Auto Evol-Instruct can achieve a improvement of 10.44% over the Evol method used by WizardLM-1 on MT-bench; on the code task HumanEval, it can achieve a 12% improvement over the method used by WizardCoder; on the math task GSM8k, it can achieve a 6.9% improvement over the method used by WizardMath.
4. Scaling Evol-Instruct to various domains and tasks
With the new technology of Auto Evol-Instruct, the evolutionary synthesis data of WizardLM-2 has scaled up from the three domains of chat, code, and math in WizardLM-1 to dozens of domains, covering tasks in all aspects of large language models. This allows Arena Learning to train and learn from an almost infinite pool of high-difficulty instruction data, fully unlocking all the potential of Arena Learning.
For more details, please refer to:
Paper: arxiv.org/pdf/2406.00770
Project: github.com/nlpxucan/WizardLM
We are working with our legal team to publicly release the code of Auto Evol-Instruct.
2
21
200
20,296
WizardLM retweeted

15 Jul 2024
A synthetic data pipeline for making LLM training data. Neat. 🧙♂️✨
15 Jul 2024
🎉Today we are announcing Evol-Instruct V2 !!!
🔥 Auto Evol-Instruct is one of the most important technologies for WizardLM-2.
Paper link: arxiv.org/pdf/2406.00770
We build a fully automated Evol-Instruct pipeline, allowing WizardLM-2 to be extended from three evolved domains (chat, code and math) of WizardLM-1 to dozens of evolved domains
🚀With Auto Evol-Instruct, You can create high-quality, highly complex instruction tuning data for any task without the need for human efforts!
⚖️We hope that this universal technology can promote fairness and efficiency for all the AI researchers in training and evaluation their own large language models.
👉For more details, please refer to Can Xu's channel:
2
13
3,569
WizardLM retweeted

15 Jul 2024
These technologies for Improving Data Training Pipeline from @WizardLM_AI will benefit all LLMs. Thank you!
I am hoping there will be big increase in creative writing scores with this method!
🔥 Excited to share the other key Technology of WizardLM-2!
📙AutoEvol: Automatic Instruction Evolving for Large Language Models
🚀We build a fully automated Evol-Instruct pipeline to create high-quality, highly complex instruction tuning data:
-------- 🧵 --------
👉Motivation First:
Over the past six months, we have dedicated ourselves to exploring methods to scale up synthetic training for LLMs. Although Evol-Instruct has demonstrated excellent performance in creating powerful post-training data, it relies too heavily on the efforts of human experts to design specific evolutionary methods for specific tasks.
Once Evol-Instruct is applied to an entirely new complex task, the methods for executing evolution need to be redesigned. This limitation of Evol-Instruct makes scaling up extremely challenging, prompting us to develop a new method, 💻Auto Evol-Insturct💻, that can evolve instruction data automatically.
Auto Evol allows the training of WizardLM2 to be conducted with nearly an unlimited number and variety of synthetic data.
Let's see: 🧐
1. Limitations of Evol-Instruct:
Evol-Instruct takes the high-quality data as a starting point, and further iteratively refines it using LLMs, improving its complexity and diversity. It has demonstrated superior performance across a broad range of public benchmarks that evaluate diverse capabilities, including instruction following (WizardLM), code generation (WizardCoder), and mathematical reasoning (WizardMath). While Evol-Instruct exhibits outstanding performance, its heavy reliance on heuristic efforts presents notable challenges. Whenever it is used for a completely new task, the methods for execution evolution need to be redesigned. Such a process requires a high level of expertise and considerable costs, hindering its adaptation to a wider spectrum of capabilities.
2. We want to build a fully automated Evol-Instruct pipeline
Auto Evol-Instruct automatically designs evolving methods that make given instruction data more complex, enabling almost cost-free adaptation to different tasks by only changing the input data of the framework. From below figure, we can see the iterative process of optimizing the initial evolving method e0 into the optimal evolving method e∗, which specifically outlines the transition from et−1 to et. We refer to the model used for evolution as the evol LLM, and the model used for optimization as the optimizer LLM. This optimization process involves two critical stages: (1) Evol Trajectory Analysis: The optimizer LLM carefully analyzes the potential issues and failures exposed in instruction evolution performed by evol LLM, generating feedback for subsequent optimization. (2) Evolving Method Optimization: The optimizer LLM optimizes the evolving method by addressing these identified issues in feedback. These stages alternate and repeat to progressively develop an effective evolving method using only a subset of the instruction data. Once the optimal evolving method is identified, it directs the evol LLM to convert the entire instruction dataset into more diverse and complex forms, thus facilitating improved instruction tuning.
3. Fully AI-driven Evol-Instruct can outperform the Evol-Instruct used by human experts.
Our experiments show that the evolving methods designed by Auto Evol-Instruct outperform the Evol-Instruct methods designed by human experts in instruction tuning across various capabilities, including instruction following, mathematical reasoning, and code generation. As shown in the below table, on the instruction following task, Auto Evol-Instruct can achieve a improvement of 10.44% over the Evol method used by WizardLM-1 on MT-bench; on the code task HumanEval, it can achieve a 12% improvement over the method used by WizardCoder; on the math task GSM8k, it can achieve a 6.9% improvement over the method used by WizardMath.
4. Scaling Evol-Instruct to various domains and tasks
With the new technology of Auto Evol-Instruct, the evolutionary synthesis data of WizardLM-2 has scaled up from the three domains of chat, code, and math in WizardLM-1 to dozens of domains, covering tasks in all aspects of large language models. This allows Arena Learning to train and learn from an almost infinite pool of high-difficulty instruction data, fully unlocking all the potential of Arena Learning.
For more details, please refer to:
Paper: arxiv.org/pdf/2406.00770
Project: github.com/nlpxucan/WizardLM
We are working with our legal team to publicly release the code of Auto Evol-Instruct.
3
7
1,746
WizardLM retweeted

15 Jul 2024
If you’ve spoken to me since the official announcement of WizardLM-2 in April, there’s a 99% chance I was in your ear rambling about how much I was looking forward to the paper detailing their new training data synthesis pipeline - today is my Christmas
Thank you @WizardLM_AI team ❤️
15 Jul 2024
🎉Today we are announcing Evol-Instruct V2 !!!
🔥 Auto Evol-Instruct is one of the most important technologies for WizardLM-2.
Paper link: arxiv.org/pdf/2406.00770
We build a fully automated Evol-Instruct pipeline, allowing WizardLM-2 to be extended from three evolved domains (chat, code and math) of WizardLM-1 to dozens of evolved domains
🚀With Auto Evol-Instruct, You can create high-quality, highly complex instruction tuning data for any task without the need for human efforts!
⚖️We hope that this universal technology can promote fairness and efficiency for all the AI researchers in training and evaluation their own large language models.
👉For more details, please refer to Can Xu's channel:
3
3
36
4,145
WizardLM retweeted

15 Jul 2024
wow🔥 it’s the upgrade version from Evol-Instruct!
🔥 Excited to share the other key Technology of WizardLM-2!
📙AutoEvol: Automatic Instruction Evolving for Large Language Models
🚀We build a fully automated Evol-Instruct pipeline to create high-quality, highly complex instruction tuning data:
-------- 🧵 --------
👉Motivation First:
Over the past six months, we have dedicated ourselves to exploring methods to scale up synthetic training for LLMs. Although Evol-Instruct has demonstrated excellent performance in creating powerful post-training data, it relies too heavily on the efforts of human experts to design specific evolutionary methods for specific tasks.
Once Evol-Instruct is applied to an entirely new complex task, the methods for executing evolution need to be redesigned. This limitation of Evol-Instruct makes scaling up extremely challenging, prompting us to develop a new method, 💻Auto Evol-Insturct💻, that can evolve instruction data automatically.
Auto Evol allows the training of WizardLM2 to be conducted with nearly an unlimited number and variety of synthetic data.
Let's see: 🧐
1. Limitations of Evol-Instruct:
Evol-Instruct takes the high-quality data as a starting point, and further iteratively refines it using LLMs, improving its complexity and diversity. It has demonstrated superior performance across a broad range of public benchmarks that evaluate diverse capabilities, including instruction following (WizardLM), code generation (WizardCoder), and mathematical reasoning (WizardMath). While Evol-Instruct exhibits outstanding performance, its heavy reliance on heuristic efforts presents notable challenges. Whenever it is used for a completely new task, the methods for execution evolution need to be redesigned. Such a process requires a high level of expertise and considerable costs, hindering its adaptation to a wider spectrum of capabilities.
2. We want to build a fully automated Evol-Instruct pipeline
Auto Evol-Instruct automatically designs evolving methods that make given instruction data more complex, enabling almost cost-free adaptation to different tasks by only changing the input data of the framework. From below figure, we can see the iterative process of optimizing the initial evolving method e0 into the optimal evolving method e∗, which specifically outlines the transition from et−1 to et. We refer to the model used for evolution as the evol LLM, and the model used for optimization as the optimizer LLM. This optimization process involves two critical stages: (1) Evol Trajectory Analysis: The optimizer LLM carefully analyzes the potential issues and failures exposed in instruction evolution performed by evol LLM, generating feedback for subsequent optimization. (2) Evolving Method Optimization: The optimizer LLM optimizes the evolving method by addressing these identified issues in feedback. These stages alternate and repeat to progressively develop an effective evolving method using only a subset of the instruction data. Once the optimal evolving method is identified, it directs the evol LLM to convert the entire instruction dataset into more diverse and complex forms, thus facilitating improved instruction tuning.
3. Fully AI-driven Evol-Instruct can outperform the Evol-Instruct used by human experts.
Our experiments show that the evolving methods designed by Auto Evol-Instruct outperform the Evol-Instruct methods designed by human experts in instruction tuning across various capabilities, including instruction following, mathematical reasoning, and code generation. As shown in the below table, on the instruction following task, Auto Evol-Instruct can achieve a improvement of 10.44% over the Evol method used by WizardLM-1 on MT-bench; on the code task HumanEval, it can achieve a 12% improvement over the method used by WizardCoder; on the math task GSM8k, it can achieve a 6.9% improvement over the method used by WizardMath.
4. Scaling Evol-Instruct to various domains and tasks
With the new technology of Auto Evol-Instruct, the evolutionary synthesis data of WizardLM-2 has scaled up from the three domains of chat, code, and math in WizardLM-1 to dozens of domains, covering tasks in all aspects of large language models. This allows Arena Learning to train and learn from an almost infinite pool of high-difficulty instruction data, fully unlocking all the potential of Arena Learning.
For more details, please refer to:
Paper: arxiv.org/pdf/2406.00770
Project: github.com/nlpxucan/WizardLM
We are working with our legal team to publicly release the code of Auto Evol-Instruct.
4
8
1,500
15 Jul 2024
❤️Thanks Wavecoder brother.
15 Jul 2024
(1/3) Quite interesting work!Evol-Instruct has recently undergone a significant update and upgrade, introducing the brand-new automatic evolutionary framework, Auto Evol.
1
17
1,941